HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

dLLM:简单扩散语言建模
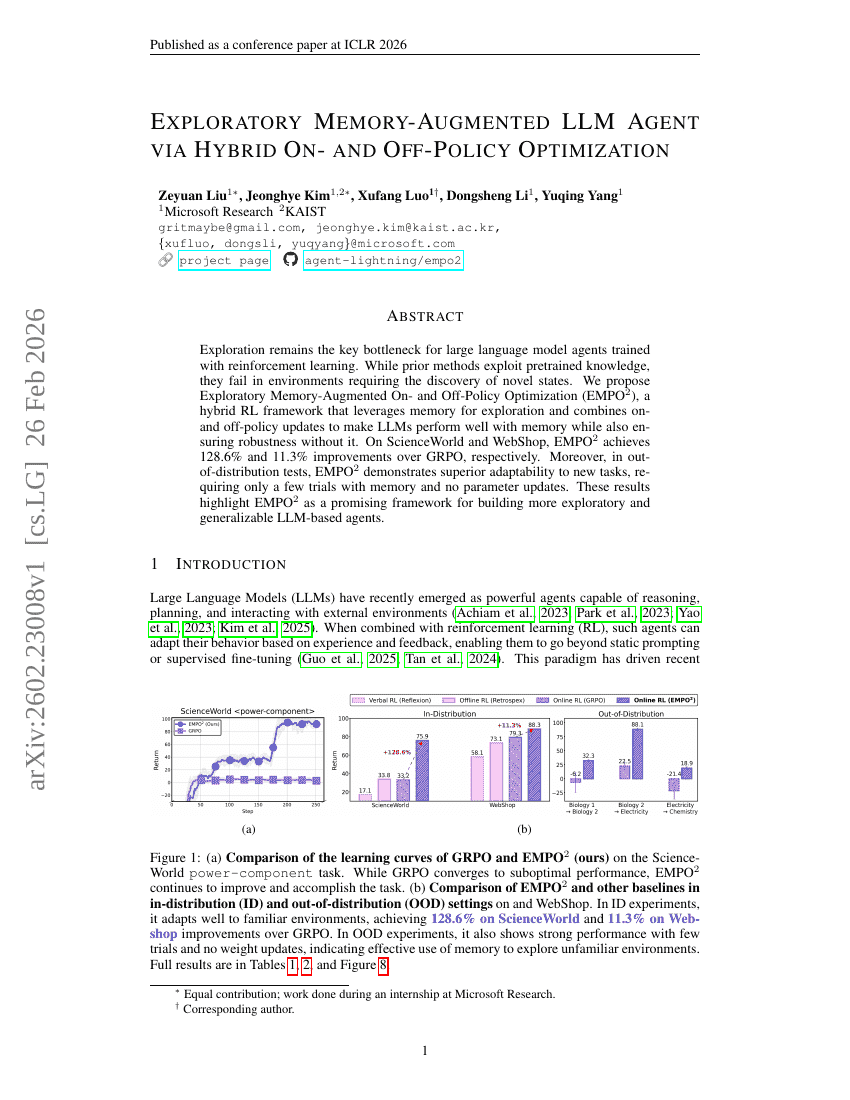
基于混合在线与离线策略优化的探索性记忆增强型LLM Agent









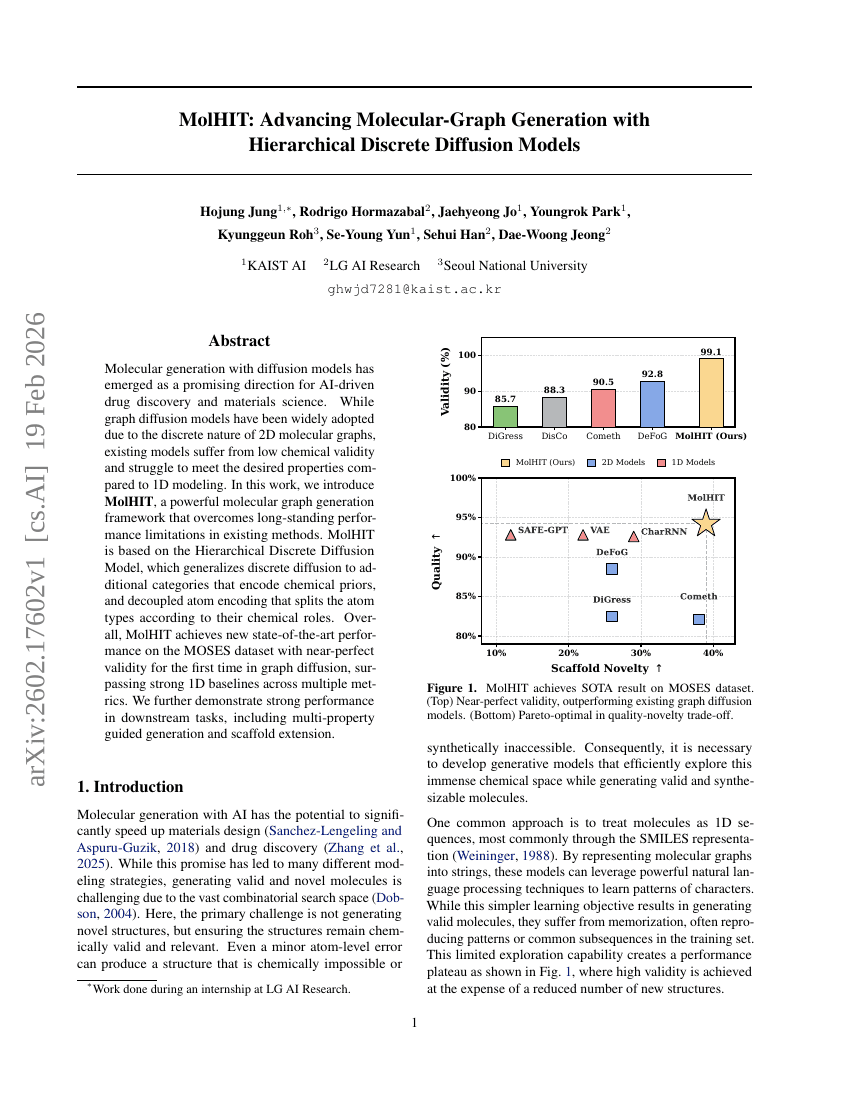

















dLLM:简单扩散语言建模
基于混合在线与离线策略优化的探索性记忆增强型LLM Agent
想象力有助于视觉推理,但在潜在空间中尚未实现
OmniGAIA:迈向原生全模态AI智能体
MobilityBench:面向真实世界出行场景中路径规划Agent的评估基准
从盲区到收益:基于诊断驱动的大型多模态模型迭代训练
一致性三元组作为通用世界模型的定义性原则
GUI-Libra:基于动作感知监督与部分可验证强化学习训练原生GUI智能体进行推理与行动
SkyReels-V4:多模态视频-音频生成、修复与编辑模型
ARLArena:一种用于稳定智能体强化学习的统一框架
DreamID-Omni:面向可控以人为中心的音视频生成统一框架
MolHIT:基于分层离散扩散模型推进分子图生成
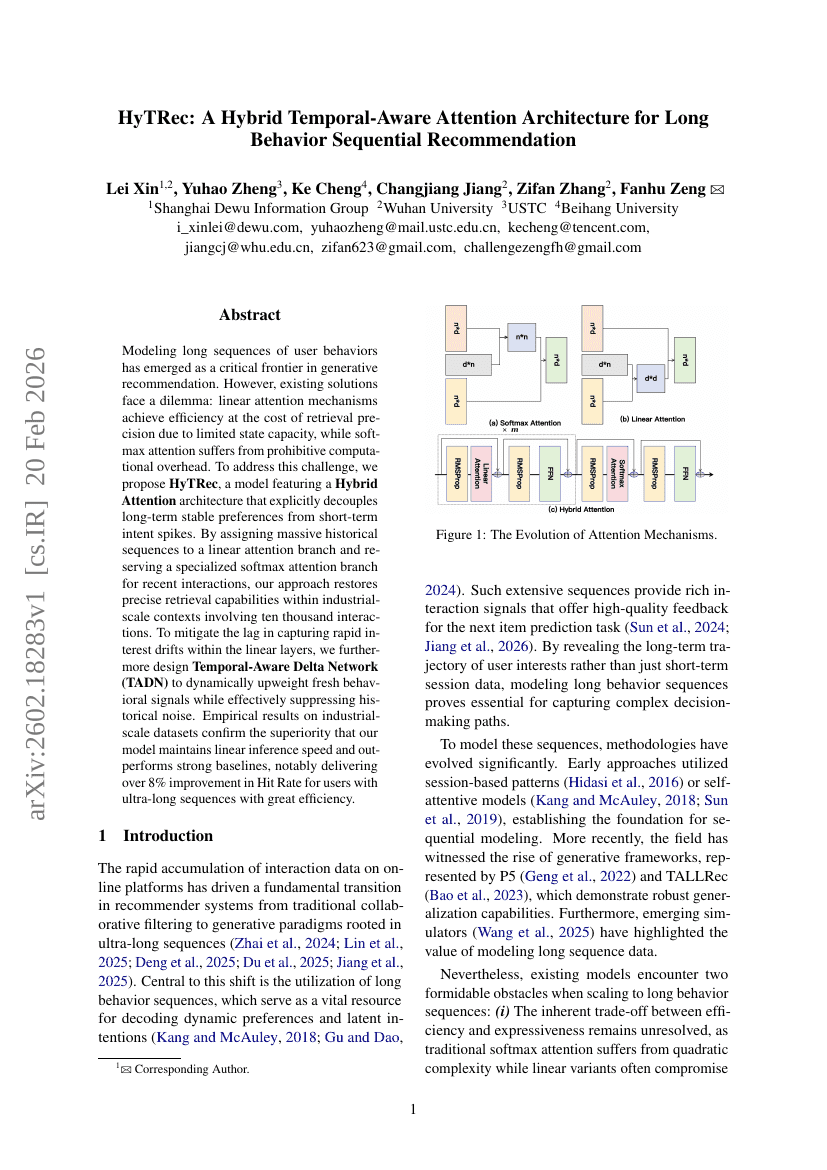
HyTRec:一种用于长行为序列推荐的混合时序感知注意力架构
DREAM:基于智能体度量的深度研究评估
LongCLI-Bench:面向命令行界面中长时程智能体编程的初步基准与研究
PyVision-RL:通过强化学习构建开放的智能体视觉模型
从感知到行动:面向视觉推理的交互式基准
面向查询聚焦与记忆感知的长上下文重排序模型
面向大规模语言模型终端能力扩展的数据工程
DSDR:用于LLM推理中探索的双尺度多样性正则化
Mobile-O:移动端的统一多模态理解与生成
TOPReward:作为机器人学中隐藏零样本奖励的Token概率
ManCAR:基于流形约束的潜在推理与自适应测试时计算的序列推荐
VLANeXt:构建强大VLA模型的配方
一个超大规模视频推理套件
基于视觉信息增益的大规模视觉语言模型选择性训练
DeepVision-103K:一个视觉多样、覆盖广泛且可验证的多模态推理数学数据集
SARAH:面向空间感知的实时智能体人类
EgoPush:面向移动机器人的端到端第一人称多物体重排学习
生成现实:基于手部与相机控制的交互式视频生成的人本世界模拟
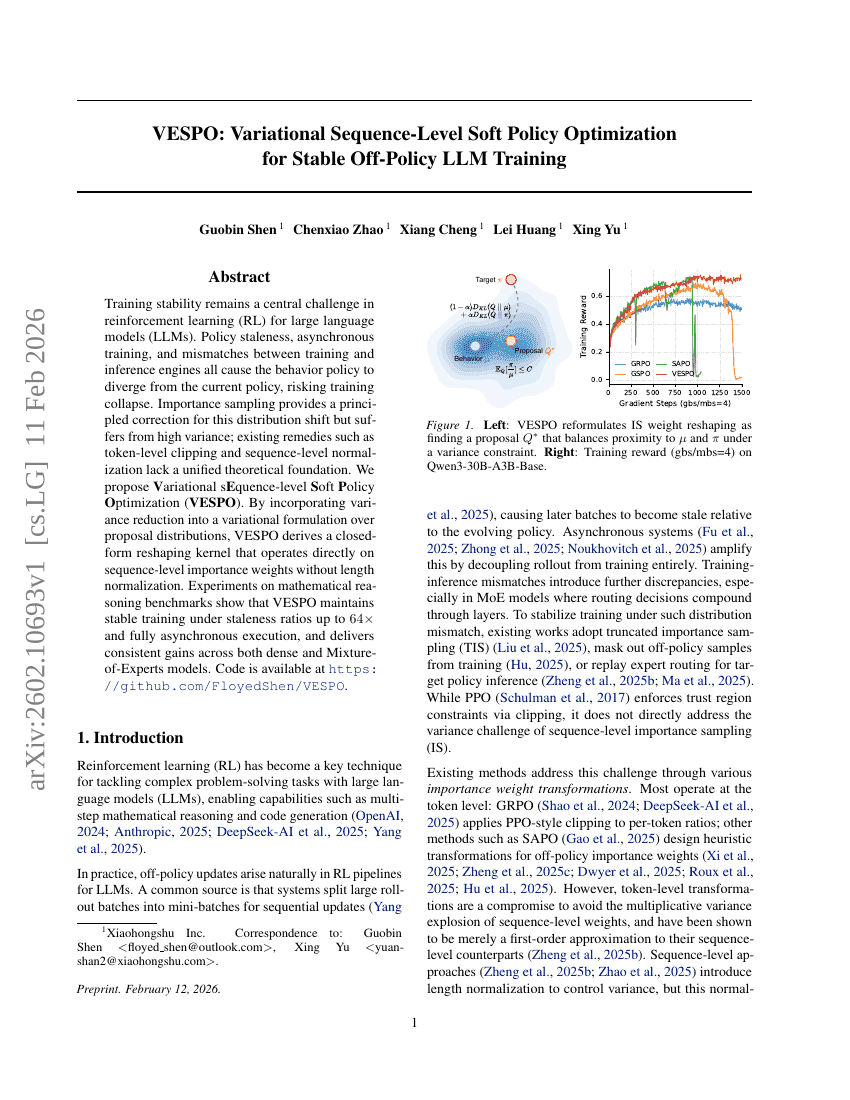
VESPO:用于稳定离策略LLM训练的变分序列级软策略优化
阿斯翠三一大型技术报告
想象力有助于视觉推理,但在潜在空间中尚未实现
OmniGAIA:迈向原生全模态AI智能体
MobilityBench:面向真实世界出行场景中路径规划Agent的评估基准
从盲区到收益:基于诊断驱动的大型多模态模型迭代训练
一致性三元组作为通用世界模型的定义性原则
GUI-Libra:基于动作感知监督与部分可验证强化学习训练原生GUI智能体进行推理与行动
SkyReels-V4:多模态视频-音频生成、修复与编辑模型
ARLArena:一种用于稳定智能体强化学习的统一框架
DreamID-Omni:面向可控以人为中心的音视频生成统一框架
MolHIT:基于分层离散扩散模型推进分子图生成
HyTRec:一种用于长行为序列推荐的混合时序感知注意力架构
DREAM:基于智能体度量的深度研究评估
LongCLI-Bench:面向命令行界面中长时程智能体编程的初步基准与研究
PyVision-RL:通过强化学习构建开放的智能体视觉模型
从感知到行动:面向视觉推理的交互式基准
面向查询聚焦与记忆感知的长上下文重排序模型
面向大规模语言模型终端能力扩展的数据工程
DSDR:用于LLM推理中探索的双尺度多样性正则化
Mobile-O:移动端的统一多模态理解与生成
TOPReward:作为机器人学中隐藏零样本奖励的Token概率
ManCAR:基于流形约束的潜在推理与自适应测试时计算的序列推荐
VLANeXt:构建强大VLA模型的配方
一个超大规模视频推理套件
基于视觉信息增益的大规模视觉语言模型选择性训练
DeepVision-103K:一个视觉多样、覆盖广泛且可验证的多模态推理数学数据集
SARAH:面向空间感知的实时智能体人类
EgoPush:面向移动机器人的端到端第一人称多物体重排学习
生成现实:基于手部与相机控制的交互式视频生成的人本世界模拟
VESPO:用于稳定离策略LLM训练的变分序列级软策略优化
阿斯翠三一大型技术报告