Command Palette
Search for a command to run...
面向查询聚焦与记忆感知的长上下文重排序模型
面向查询聚焦与记忆感知的长上下文重排序模型
Yuqing Li Jiangnan Li Mo Yu Guoxuan Ding Zheng Lin Weiping Wang Jie Zhou
摘要
在现有大语言模型中检索头(retrieval heads)分析的基础上,我们提出了一种替代性的重排序框架,该框架通过训练模型利用选定头的注意力得分来估计段落与查询之间的相关性。该方法提供了一种列表级(listwise)解决方案,在排序过程中能够充分利用整个候选短列表中的全局信息。同时,该方法自然地生成连续的相关性得分,从而可在任意检索数据集上进行训练,而无需依赖李克特量表(Likert-scale)形式的标注监督。我们的框架轻量高效,仅需小规模模型(如40亿参数)即可实现优异性能。大量实验表明,该方法在多个领域——包括维基百科数据集和长篇叙事数据集——上均超越了现有的最先进点对点(pointwise)与列表级(listwise)重排序器。此外,该方法在评估对话理解与记忆使用能力的LoCoMo基准测试中,进一步建立了新的最先进水平。我们还进一步证明,该框架具备良好的可扩展性:例如,通过引入上下文信息增强候选段落,可进一步提升排序准确性;而从中间层训练注意力头,则可在不损失性能的前提下显著提高计算效率。
一句话总结
来自中科院、国科大和腾讯的研究人员提出了一种轻量级重排序框架,通过从选定的大型语言模型(LLM)注意力头中提取注意力分数来估计段落与查询的相关性,从而实现连续评分的列表式排序,并在维基百科、叙事和对话基准(如 LoCoMo)上超越当前最优方法。
主要贡献
- 我们提出了 QRRanker,一种列表式重排序框架,通过训练 LLM 使用选定检索头的注意力分数来估计段落-查询相关性,无需 Likert 量表监督即可输出连续分数,并利用整个候选列表的全局上下文。
- 该方法在小规模模型(如 4B 参数)上表现优异,支持高效扩展,例如在候选文本前添加共享上下文或训练中间层注意力头——在保持准确性的同时降低推理延迟。
- 实验表明,QRRanker 在维基百科、长篇叙事和对话数据集上均优于当前最先进的点式和列表式重排序器,并在对话记忆与理解任务 LoCoMo 上设立了新基准。
引言
作者利用大型语言模型中自然表现出检索行为的注意力头——特别是“查询聚焦检索”(QR)头——构建了一个轻量级列表式重排序器 QRRanker。以往的重排序器要么依赖点式评分(丢失全局上下文),要么依赖列表式生成(需 Likert 量表标注且输出不稳定),而 QRRanker 训练 QR 头直接从注意力权重中输出连续相关性分数,从而可在任何检索数据集上训练而无需格式限制。它支持使用更小的骨干模型(如 4B 参数)进行高效推理,可选通过前置摘要注入全局上下文,并在训练中使用中间层头时仍保持鲁棒性——可通过剪枝顶层进一步降低延迟。在长上下文问答和对话任务中评估,QRRanker 在保持实用效率的同时,优于通用和领域专用重排序器。
数据集

- 作者使用 MuSiQue(Trivedi 等,2022)和 NarrativeQA(Kočiský 等,2018)构建统一训练集,两者均提供问题-证据对。
- 对于 MuSiQue,直接使用官方支持事实作为黄金证据;对于 NarrativeQA,由于未提供黄金片段,按 Li 等(2025a)方法构建银级证据块。
- 对于每个问题,使用 Qwen3-Embedding-8B 检索 top-50 候选集,并形成列表式训练实例:匹配预构建证据的候选标记为正,其余为负。
- 可选地,在候选块(C)前添加摘要前缀(M),形成输入 X = [M; C],摘要由检索到的块映射而来——增强模型的上下文感知能力。
- 两个数据集均采用相同的证据和块构建流程,NarrativeQA 的过程详见算法 1。
- QRRanker 模型使用此结构化输入,通过专用 QR 头对文档评分,支持无需复杂设计的叙事、对话和维基内容的排序-重排序流水线。
方法
作者提出了一种名为 QRRanker 的列表式重排序框架,通过提取并聚合大型语言模型中预定义的检索导向注意力头(称为 QR 头)的注意力分数进行操作。该方法避免自回归生成,仅依赖模型的预填充阶段计算相关性分数,从而实现计算高效。核心思想是将重排序任务视为整个候选列表上的对比学习问题,使模型能从检索文档的完整上下文中学习整体排序信号。
框架从构建列表式训练实例开始。对于每个问题,作者使用初始检索器(如 Qwen3-Embedding)检索 top-K 候选文档列表(通常 K=50)。通过 SILVEREVIDENCE 识别黄金文档,每个候选被标记为正或负。可选地,将记忆增强上下文(如摘要)前置到文档列表,提供粗粒度语义引导。采用两种摘要构建策略:针对叙事文本的块级摘要(将连续块分组并为每块生成一个摘要),以及针对对话数据的事件中心摘要(提取与源话语关联的结构化事件以实现可追溯性)。请参考框架图,了解这些记忆组件如何集成到流水线中。
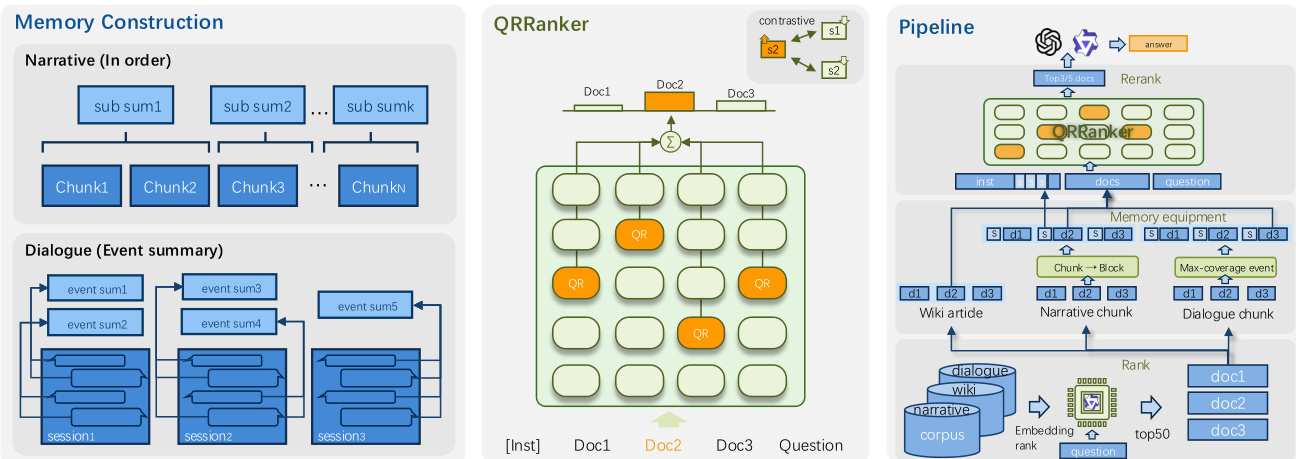
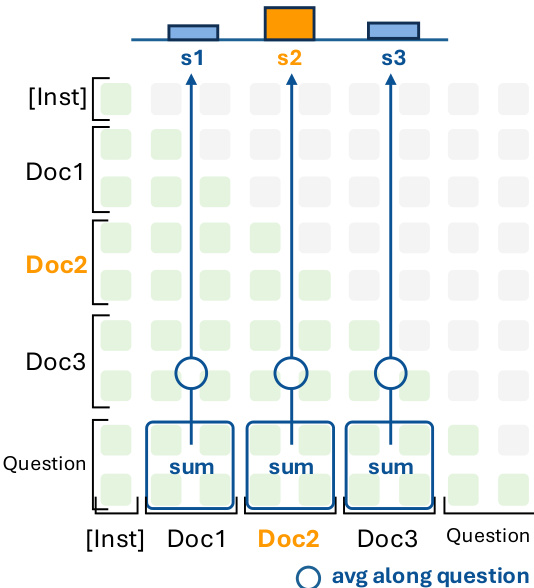
QRRanker 模型本身基于预选的一组 QR 头构建,这些头通过在种子数据集(如 NarrativeQA 的 1000 个样本)上计算 QR 分数识别。这些头选自 Qwen3-4B-Instruct-2507 模型(含 36 层、每层 32 头自注意力),保留 QR 分数最高的 16 个头用于重排序。推理时,模型接收由指令、候选文档和问题组成的提示。对于每个 QR 头 h,提取问题标记与每个候选块 ci 之间的注意力矩阵 AhQ→ci。块 ci 在头 h 下的检索分数计算为:
scih=∣Q∣1i∈ci∑j∈Q∑AhQ→ci[i,j],其中求和操作聚合问题与块之间所有标记对的注意力权重。如图所示,这涉及对每个文档沿问题维度平均注意力分数,然后对所有 QR 头求和,得到最终分数 sci=∑h∈HQRscih。
训练通过使用组对比损失优化这些分数进行。与传统对比损失每批次采样一个正样本不同,该变体通过在 top-K 列表中所有正样本上平均损失来处理多个正文档:
Lsample=∣G∣1cp∈G∑logτ(scp)+∑cn∈C∖Gτ(scn)τ(scp),其中 τ 表示指数函数。为稳定训练,分数使用最大-最小缩放归一化到固定范围 [0, scale],以缓解注意力沉降效应或指令诱导偏差带来的不稳定性。模型端到端训练以优化 QR 头区分相关与无关文档的能力,训练时可选加入记忆前缀以增强上下文感知。
框架的一个变体引入半自动头选择:不使用静态 QR 头集合,而是通过路由机制为每个样本从预定义层范围动态选择 16 个头。这通过门控网络实现,该网络基于重复问题标记序列的隐藏状态计算头分数,随后进行 softmax 和 top-k 选择。所选头根据其门控分数加权贡献最终分数,支持训练期间的梯度流动和自适应头选择。
实验
- QRRanker 在维基百科多跳问答、长上下文故事问答和对话记忆任务中,持续优于仅嵌入和强重排序基线,建立新的召回性能最先进水平。
- 它通过选择更符合推理需求的证据显著提升下游问答准确性,尤其在叙事和侦探故事基准中。
- 在对话记忆(LoCoMo)上,QRRanker 仅使用最小上下文(top-3 块)即取得最高 F1 分数,优于需要更大输入预算或复杂记忆结构的记忆增强框架。
- 添加摘要前缀在长上下文对话和故事任务中提升性能,但在维基百科问答中无益处——甚至可能降低效果,因为证据高度局部化。
- 中间到顶层模型层表现最优;使用中间层头(17–24)训练可匹配完整模型性能,支持在不牺牲准确性的前提下高效截断。
- 与基线相比,QRRanker 提供更优的推理效率——更低延迟、计算量和内存占用,截断中间层变体进一步提升速度和成本优势。
作者使用 QRRanker 对检索候选进行重排序,发现在相同设置下,其延迟更低,计算和内存使用更少,优于 Qwen3-Reranker-4B。截断模型中间层后效率进一步提升,提供最快响应时间和最低资源消耗。结果表明 QRRanker 提供更优的性能-成本权衡,尤其在轻量级中间层变体中。

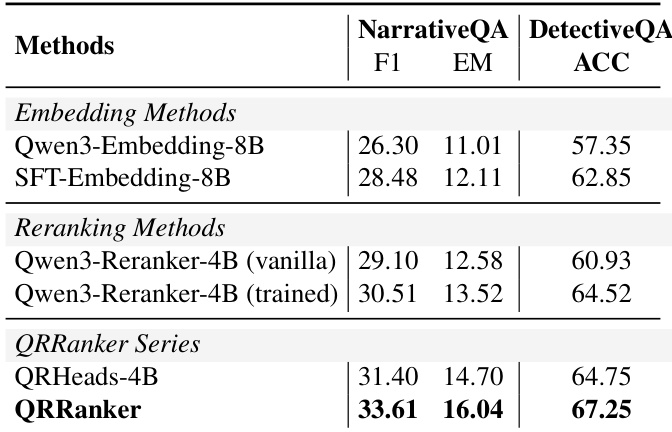
作者使用 QRRanker 对长上下文故事问答任务的检索段落进行重排序,观察到其持续优于仅嵌入和训练重排序基线。结果表明,QRRanker 在 NarrativeQA 上取得最高 F1 和精确匹配分数,在 DetectiveQA 上取得最高准确率,表明其在选择更支持下游答案生成的上下文方面有效。即使仅使用少量 top 排名块作为输入,该性能优势仍保持,突显其效率和与推理需求的对齐。
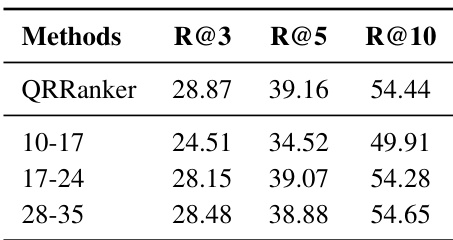
作者评估了使用不同 Transformer 层头的 QRRanker 变体,发现使用中间层(17-24)或顶层(28-35)训练的模型取得可比的检索性能,而较低层(10-17)显著表现不佳。这表明中间到顶层更适合检索任务,且该方法能有效激活这些层中非专用头的检索潜力。
作者使用 QRRanker 在多个长上下文基准上评估添加与不添加摘要前缀的检索性能。结果表明,添加摘要前缀在 LoCoMo、NarrativeQA 和 DetectiveQA 上提升 Recall@3,但在 HotpotQA 和 Musique 等基于维基百科的数据集上无益处或轻微降低性能。这表明全局摘要在对话和故事上下文中增强检索,但在证据局部化的事实段落中效果较差。

作者使用 QRRanker 在多个问答和对话基准上对 top-50 候选进行重排序,显示其持续优于仅嵌入和现有重排序方法。结果表明,它优于更大的模型如 GroupRank-32B 和专用系统如 HippoRAG,尤其在长上下文和多跳设置中。其有效性延伸至下游生成任务,表明检索证据与推理需求高度对齐。
