Command Palette
Search for a command to run...
VESPO:用于稳定离策略LLM训练的变分序列级软策略优化
VESPO:用于稳定离策略LLM训练的变分序列级软策略优化
Guobin Shen Chenxiao Zhao Xiang Cheng Lei Huang Xing Yu
摘要
训练稳定性仍是大规模语言模型(LLMs)强化学习(RL)中的核心挑战。策略滞后(policy staleness)、异步训练以及训练与推理引擎之间的不匹配,均会导致行为策略偏离当前策略,进而引发训练崩溃的风险。重要性采样(importance sampling)为这一分布偏移问题提供了理论上的修正方法,但其存在方差过高的问题;现有改进方法如基于token级别的截断(clipping)和序列级别的归一化,缺乏统一的理论基础。为此,我们提出变分序列级软策略优化(Variational sEquence-level Soft Policy Optimization, VESPO)。该方法通过在提议分布的变分框架中引入方差缩减机制,推导出一种闭式表达的重加权核函数,可直接作用于序列级别的重要性权重,无需进行长度归一化。在数学推理基准测试中的实验表明,VESPO在策略滞后比高达64倍且完全异步执行的情况下仍能保持训练稳定,并在密集模型与混合专家(Mixture-of-Experts)模型上均实现一致的性能提升。代码已开源,地址为:https://github.com/FloyedShen/VESPO
一句话总结
来自同一机构的研究人员提出了 VESPO,这是一种变分方法,通过闭式序列级核函数减少重要性采样的方差,从而稳定大语言模型(LLM)的强化学习训练,在极端陈旧性和异步条件下,其性能优于先前方法,适用于密集型和 MoE 模型。
主要贡献
- VESPO 引入了一种变分公式,显式降低大语言模型离策略强化学习中的方差,推导出一种无需依赖长度归一化或启发式裁剪的闭式序列级重要性权重重塑核。
- 该方法保留了 token 间的依赖关系,避免归一化引入的偏差,支持在极端陈旧性(最高达 64 倍)和完全异步执行下稳定训练,并兼容密集型和混合专家(MoE)架构。
- 在数学推理基准测试中,VESPO 持续优于现有的 token 级和序列级重要性采样基线,提供了一种理论基础扎实、替代启发式权重变换的方案。
引言
作者利用强化学习来稳定大语言模型的离策略训练,其中策略陈旧性和异步更新会导致分布偏移,进而引发训练崩溃。先前方法依赖启发式 token 级裁剪或序列级归一化来控制重要性采样方差,但这些方法引入偏差或无法保留序列结构。VESPO 引入一种变分框架,推导出直接作用于序列级权重的闭式重塑核,无需长度归一化或近似,从而在极端陈旧性和异步条件下实现稳定训练,并在密集型和 MoE 架构上均带来一致性能提升。
方法
作者利用变分框架推导出一种原则性的权重变换方法,用于自回归语言模型中的离策略策略梯度优化。他们的方法 VESPO(变分序列级软策略优化)将任意重塑函数 φ(W) 重新解释为诱导出一个隐式提议分布 Q,该分布介于行为策略 μ 与目标策略 π 之间,同时满足方差约束。
请参考框架图,该图可视化了变分目标:提议分布 Q* 被优化以位于一个平衡接近 μ 和 π 的区域,同时满足在 Q 下期望重要性权重的约束。对偶 KL 目标 (1−α)DKL(Q∥μ)+αDKL(Q∥π) 将 Q 向采样分布 μ 拉近以提高效率,同时向目标 π 拉近以减少偏差。约束 EQ[W]≤C 确保估计器方差保持有界,防止未校正的序列级重要性采样中常见的爆炸式增长。
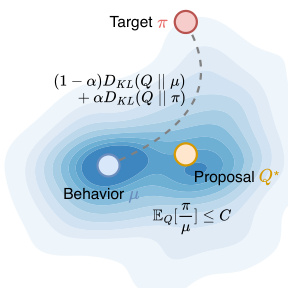
最优提议分布的闭式解给出重塑函数 ϕ(W)=Wαexp(−λW),该函数结合幂律缩放与指数抑制,平滑衰减极端权重。在实践中,作者采用一个偏移变体 ϕ(W)=Wc1exp(c2(1−W)),以确保 ϕ(1)=1,保留在线策略更新的尺度。该核函数被不对称应用:正负优势分别使用不同的超参数 (c1,c2),当优势为负时对低权重样本施加更强抑制,有助于防止过度惩罚策略本已不倾向的轨迹。
梯度估计器采用 REINFORCE 风格实现,重塑权重从计算图中分离,仅作为缩放因子。为确保数值稳定性,所有计算——包括序列级对数比 logW=∑t(logπθ(yt∣x,y<t)−logμ(yt∣x,y<t)) 和对数变换后的重塑项 c1logW+c2(1−W)——均在对数空间执行,指数运算推迟至最后一步。这避免了极端重要性权重导致的溢出,且无需额外内存,仅需存储每个 token 在两个策略下的对数概率。
实验
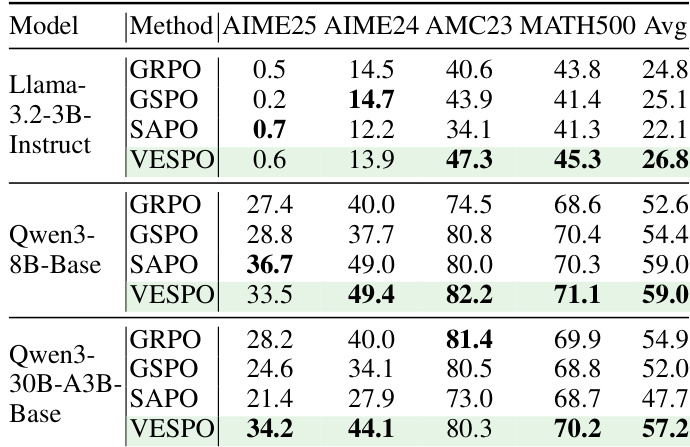
- VESPO 在多个模型规模和数学推理基准上持续优于基线,尤其在 MoE 模型上表现突出,因为此类模型中训练-推理不匹配和策略陈旧性被放大。
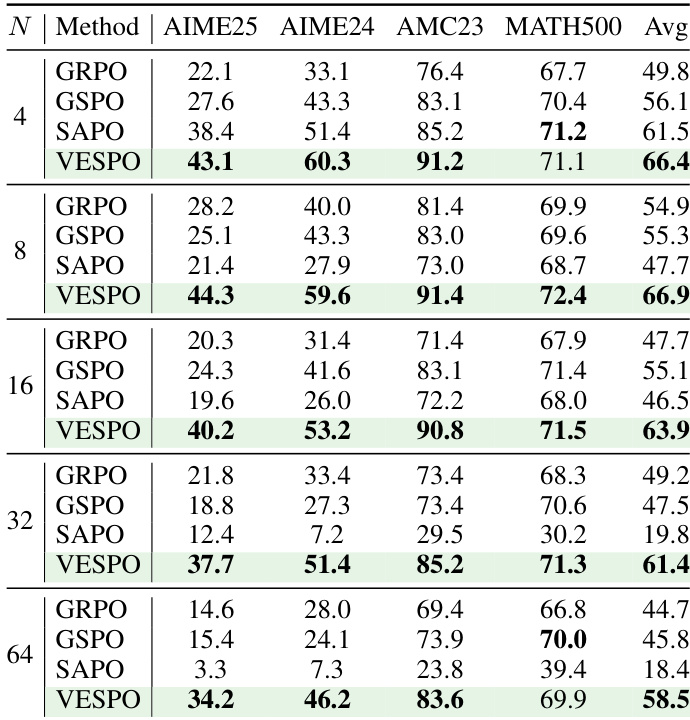
- 它在不同离策略更新程度(N=4 至 64)下展现出对策略陈旧性的卓越鲁棒性,在其他方法退化或崩溃时仍保持稳定训练动态和高准确率。
- 在完全异步训练下,VESPO 维持稳定收敛,而基线方法因陈旧 rollout 出现不稳定、奖励崩溃或次优表现。
- VESPO 无需特殊修复即可容忍训练-推理不匹配,其稳定性与采用工程解决方案(如 Routing Replay 或 Truncated Importance Sampling)增强的方法相当或更优。
- 消融实验证实,VESPO 的序列级设计无需长度归一化,可避免长度偏差和训练崩溃,而归一化变体则无法做到。
- 其针对正负优势的非对称超参数设计在抑制与学习信号间取得平衡,对稳定性和性能至关重要。
作者在不同策略陈旧性程度下评估 VESPO,发现其在所有陈旧性水平下均持续优于基线,即使在 N=64 等极端设置下仍保持稳定训练和强大的下游准确率。与在高陈旧性下退化或崩溃的 GRPO、GSPO 和 SAPO 不同,VESPO 的设计避免了长度偏差,并通过非对称重要性权重抑制稳定更新。结果证实 VESPO 对策略陈旧性和训练-推理不匹配导致的分布偏移具有鲁棒性,尤其在这些偏移被放大的 MoE 模型中受益显著。
作者在多个模型规模和数学推理基准上将 VESPO 与多个基线进行对比,发现 VESPO 在所有设置中均持续取得最高平均准确率。结果表明,VESPO 的性能优势在更大的 MoE 模型中最为显著,其缓解了由策略陈旧性和训练-推理不匹配引起的不稳定性。该方法的稳定性和有效性源于其序列级软抑制极端重要性权重和非对称超参数设计,可防止训练崩溃并维持一致的学习动态。