Command Palette
Search for a command to run...
阿斯翠三一大型技术报告
阿斯翠三一大型技术报告
摘要
我们发布Arcee Trinity Large大型稀疏专家混合模型(Mixture-of-Experts, MoE)的技术报告,该模型总参数量达4000亿,每 token 激活参数量为130亿。此外,我们还介绍了Trinity Nano与Trinity Mini两款模型:Trinity Nano总参数量为60亿,每 token 激活参数量为10亿;Trinity Mini总参数量为260亿,每 token 激活参数量为30亿。这些模型采用先进的架构设计,包含交错式局部与全局注意力机制、门控注意力(gated attention)、深度缩放的沙拉酱归一化(depth-scaled sandwich norm),以及用于MoE的Sigmoid路由机制。针对Trinity Large,我们提出了一种新型MoE负载均衡策略,命名为“软钳制动量专家偏置更新”(Soft-clamped Momentum Expert Bias Updates, SMEBU)。所有模型均采用Muon优化器进行训练,且在训练过程中均未出现任何损失突增(zero loss spikes)的情况。Trinity Nano与Trinity Mini在10万亿token上完成预训练,Trinity Large则在17万亿token上完成预训练。模型检查点已发布于Hugging Face:https://huggingface.co/arcee-ai。
一句话总结
Arcee AI 与 Prime Intellect 的研究人员推出了 Trinity Large、Nano 和 Mini —— 三款稀疏 MoE 模型,参数规模最高达 4000 亿,采用 SMEBU 负载均衡、Muon 优化器及现代注意力架构,可在万亿级 token 上实现稳定训练,支持可扩展且高效的推理。
主要贡献
- Trinity 系列引入三款开源权重的稀疏混合专家模型 —— Nano(总参数 60 亿,激活 10 亿)、Mini(总参数 260 亿,激活 30 亿)和 Large(总参数 4000 亿,激活 130 亿),专为高效训练与推理设计,架构创新包括交错式局部/全局注意力与门控注意力,支持长上下文推理。
- Trinity Large 引入软钳制动量专家偏置更新(SMEBU),这是一种新型 MoE 负载均衡策略,可提升训练期间专家利用率的稳定性,并搭配 Muon 优化器,使所有模型在扩展至 17 万亿 token 时仍可实现大批次训练且无损失尖峰。
- 所有模型均实现无损失尖峰的稳定训练 —— Nano 与 Mini 在 10 万亿 token 上训练,Large 在 17 万亿 token 上训练 —— 其检查点已公开,为企业部署提供开源权重基础,支持可验证的数据来源与司法管辖控制。
引言
作者利用市场对高效、可扩展且企业友好的大语言模型日益增长的需求,推出 Trinity Large —— 一款 4000 亿参数的开源权重混合专家模型,每 token 仅激活 130 亿参数。以往 MoE 与长上下文架构研究常在训练稳定性与推理效率方面面临挑战,尤其在数据主权与可审计性等现实约束下。Trinity 通过结合稀疏 MoE 层、交错式局部/全局注意力、门控注意力模块及 Muon 优化器,提升样本效率与训练稳定性 —— 同时在 17 万亿 token 上训练,并设计为支持完整组织控制。其贡献不仅包括大型模型,还包括 Trinity Nano 与 Mini 的扩展阶梯,验证了架构与训练管道,为未来高效扩展奠定基础。
数据集
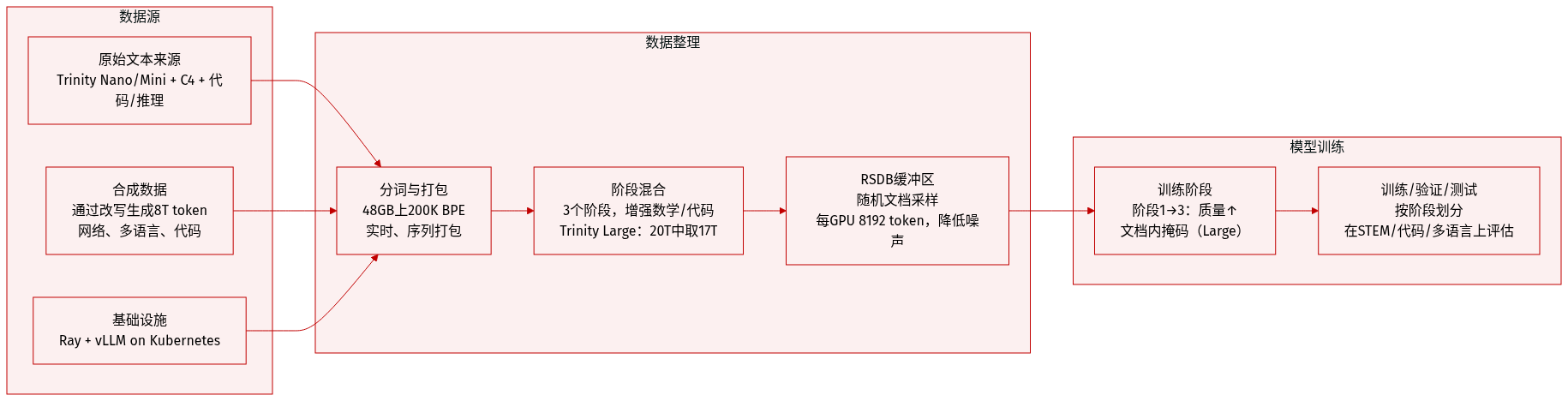
作者使用基于约 48GB 数据(约 100 亿 token)训练的自定义 20 万 token BPE 分词器,数据来源包括 Trinity Nano/Mini 预训练语料、多语言 C4 子集及指令/推理/代码数据。由于时间限制,非英语语言在最终训练数据中的占比相对偏低。
关键数据集子集与构成:
- Trinity Nano 与 Mini:在 10 万亿 token 混合数据上训练(第 1 阶段 7 万亿,第 2 阶段 1.8 万亿,第 3 阶段 1.2 万亿),复用 AFM-4.5B 并增加数学/代码数据。
- Trinity Large:在 17 万亿 token 上训练,按比例采样自 20 万亿混合数据(第 1 阶段 13 万亿,第 2 阶段 4 万亿,第 3 阶段 3 万亿),并增强编程、STEM、推理与多语言数据(阿拉伯语、中文、日语、西班牙语、德语、法语、意大利语、葡萄牙语、印尼语、俄语、越南语、印地语、韩语、孟加拉语)。
- 合成数据:通过重写高质量种子文档生成超 8 万亿 token(6.5 万亿网页、1 万亿多语言、8000 亿代码),使用风格/格式/内容变换提升多样性与相关性。
- 基础设施:合成数据生成通过 Ray 与 vLLM 在 Kubernetes 上跨异构 GPU 集群扩展。
数据使用与处理:
- 所有模型分三阶段训练,逐步增加数学/代码比例与数据质量。
- 分词实时进行并采用序列打包;Trinity Large 使用文档内注意力掩码。
- 对 Trinity Large 第 3 阶段,引入随机顺序文档缓冲区(RSDB)以减少批次间相关性:文档被缓冲,构建小批次时跨文档随机采样 token。
- RSDB 每 GPU 使用 8192 token 缓冲区(4096 为用户指定),分摊至 4 个工作者,采用批量填充与清理以提升效率。
- RSDB 与基线顺序打包相比,将批次异质性(BatchHet)降低 4.23 倍,步间损失方差降低 2.4 倍,提升梯度稳定性且不丢弃 token。
- BatchHet 指标追踪微批次损失方差,与训练不稳定性相关;RSDB 在小规模测试中将梯度范数峰度从 187 降至 14.6。
该数据集整理代表了 LLM 预训练中最大规模的合成数据努力之一,目标覆盖通用英语、编程、STEM 与多语言能力 —— 并通过下游强性能验证。
方法
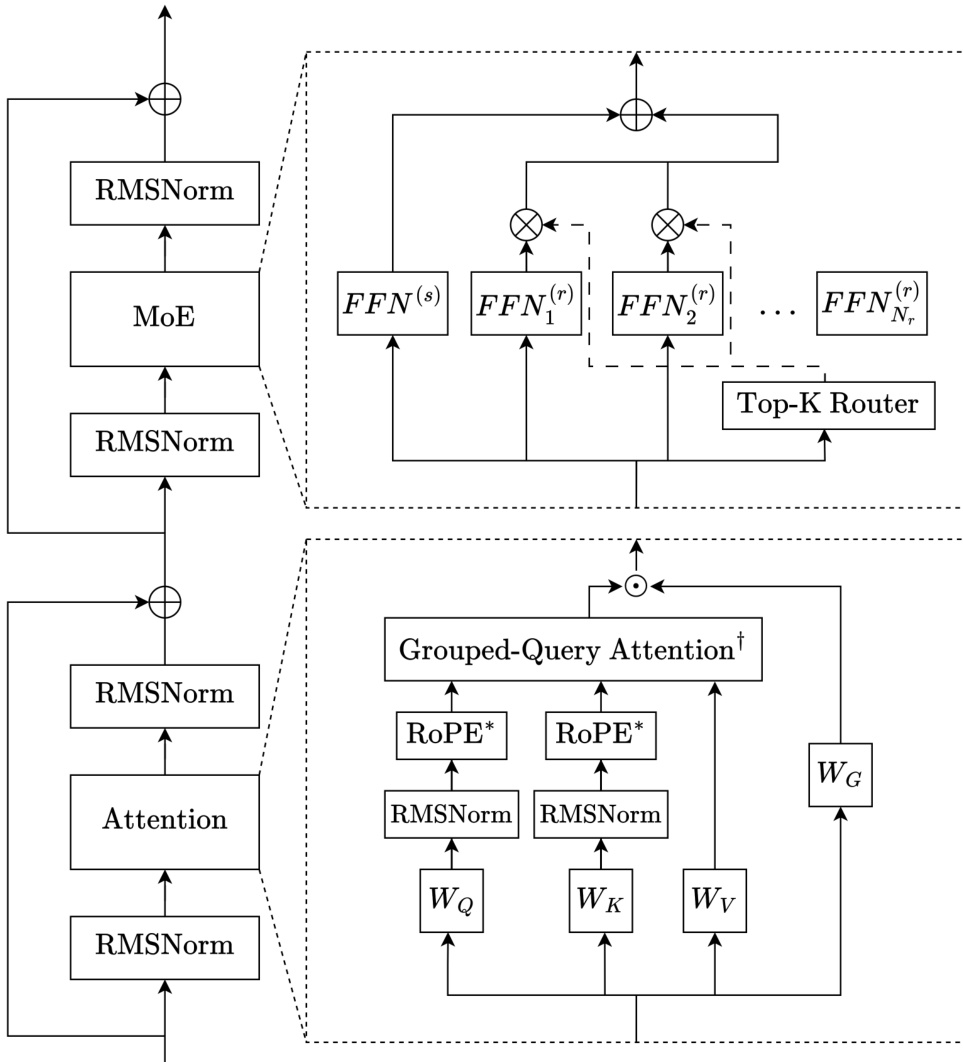
作者基于 Transformer 框架构建解码器专用稀疏混合专家(MoE)架构,形成 Trinity 系列模型。整体设计整合多项现代架构创新,以增强训练稳定性、长上下文性能与计算效率。核心模块结构如框架图所示,由交替的注意力与 MoE 块组成,每个块外包裹深度缩放的三明治归一化方案。
每个 Transformer 层以 RMSNorm 开始,作用于输入,后接注意力或 MoE 子层,最后以第二层 RMSNorm 结束,再连接残差。注意力子层采用分组查询注意力(GQA)与 QK 归一化,查询与键在缩放点积注意力前进行 RMSNorm。此归一化对稳定训练至关重要,尤其在 Muon 优化器下,通过约束注意力 logits 增长实现。注意力机制按 3:1 比例交替局部与全局层。局部层使用滑动窗口注意力与旋转位置嵌入(RoPE),全局层省略位置嵌入(NoPE),以支持高效长序列处理与观察到的长度外推。注意力后应用门控注意力,使用 sigmoid 门控线性变换调节注意力输出,缓解注意力沉降并提升泛化能力。
MoE 子层沿用 DeepSeekMoE 设计,包含一个始终激活的共享专家与多个路由专家,输出通过基于 sigmoid 的路由组合。路由器为每个专家计算归一化 sigmoid 分数,Top-K 选择由路由器分数与专家偏置之和决定。应用于专家输出的门控分数仅来自路由器分数,与偏置更新解耦。对于 Trinity Mini 与 Nano,负载均衡通过无辅助损失的更新与重中心化专家偏置实现。对于 Trinity Large,作者引入软钳制动量专家偏置更新(SMEBU),以连续 tanh 钳制、动量平滑变体替代离散符号更新,稳定收敛并减少训练振荡。此外,应用序列级辅助损失以促进序列内专家平衡。
模型采用深度缩放三明治归一化:每层第一层 RMSNorm 的增益初始化为 1,第二层 RMSNorm 的增益按 1/L 缩放,其中 L 为总层数。所有参数从零均值截断正态分布初始化,标准差为 0.5/d,嵌入激活在前向传播时按 d 缩放。Trinity Large 通过减少专家粒度(每 token 激活更少但更大的专家)进一步优化吞吐量,同时保持高总参数量与低激活参数量。
实验
- 分词器在英语与法语标准分词器中实现最高压缩效率,CJK 性能具竞争力但略逊,归因于训练数据限制;完整 Trinity Large 语料训练有望弥补差距。
- 基础设施利用 GPU 集群与定制框架及优化,包括 Trinity Large 的专家并行、针对 B300 硬件的动态 PyTorch 版本调优与鲁棒故障恢复机制。
- 训练超参数按模型规模精心调优,隐藏层使用 Muon,嵌入层使用 AdamW,学习率调整支持平滑扩展;上下文扩展采用余弦衰减,避免重新预热以提升效率。
- 上下文扩展效果显著,尤其对大模型,Trinity Large 在 256K 上实现近乎完美的 MK-NIAH 分数,且在 1M 上下文仍保持强泛化能力;直接在目标长度训练优于渐进扩展。
- Trinity Large Base 在更高稀疏度与更少激活参数下,仍匹配或超越同类开源权重模型,在编码、数学、知识与推理基准中表现强劲。
- 推理基准证实 FP8 量化下高效性能,vLLM 吞吐量反映稀疏性与注意力设计的架构优势。
- Trinity Large 的训练不稳定性通过结合六项稳定技术(包括 SMEBU 负载均衡、z-loss、辅助损失与文档内掩码)解决,但因时间限制未进行消融研究。
作者在多个基准上评估 Trinity Large Base,显示其在编码、数学、常识与知识任务中的强劲表现。结果表明,尽管激活参数显著更少,其得分仍与其他开源基础模型相当。模型在 HellaSwag 与 TriviaQA 等任务中表现突出,而 GPQA Diamond 仍是待改进的挑战领域。

作者使用的自定义分词器在英语与法语数据集上实现标准分词器中最高的字节/Token 压缩率,得益于更大词汇量。对于 CJK 语言,压缩率具竞争力但略低于专用分词器,作者归因于训练数据限制。结果表明,扩大训练语料有望弥补此差距。

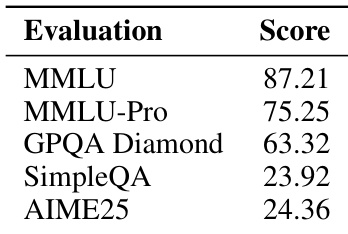
作者在 MMLU、MMLU-Pro、GPQA Diamond、SimpleQA 与 AIME25 等标准基准上评估其指令微调模型 Trinity Large Preview,报告得分反映其在知识、推理与指令遵循任务中的表现。结果表明,模型在 MMLU 与 MMLU-Pro 等知识密集型基准上表现强劲,而在 GPQA Diamond 与 AIME25 等更专业或更具挑战性的任务上得分表明仍有改进空间。其设计采用极端稀疏性与交错注意力,支持高效推理而不牺牲基准竞争力。