Command Palette
Search for a command to run...
DREAM:基于智能体度量的深度研究评估
DREAM:基于智能体度量的深度研究评估
摘要
深度研究代理(Deep Research Agents)能够生成媲美分析师的报告,但其评估仍面临巨大挑战,原因在于缺乏单一的“真实标准”(ground truth),且研究质量本身具有多维度特性。现有评估基准虽提出了各异的方法,却普遍存在“合成幻觉”(Mirage of Synthesis)问题:即报告在表面语言流畅性与引用一致性方面表现优异,却可能掩盖其背后存在的事实错误与推理缺陷。为揭示这一评估鸿沟,本文提出一个涵盖四个维度的分类体系,揭示了静态评估者与研究代理之间存在的关键能力错配——静态评估方法本身不具备使用工具的能力,因而无法有效评估研究结果的时间有效性与事实准确性。为解决该问题,本文提出 DREAM(Deep Research Evaluation with Agentic Metrics)框架,通过实现“能力对等”原则,使评估过程本身具备智能体(agentic)特性。DREAM 采用一种评估协议,融合与查询无关的基准指标,以及由具备工具调用能力的智能体动态生成的自适应指标,从而实现对时间敏感性的感知、基于证据的验证,以及系统性推理探查。控制实验表明,DREAM 在检测事实性退化与时间有效性衰减方面,显著优于现有基准,为构建可扩展、无需参考答案的评估范式提供了有力支持。
一句话总结
来自 AWS Agentic AI 和佐治亚理工学院的研究人员提出了 DREAM,这是一种代理评估框架,通过使用工具调用代理进行基于事实、自适应的评估,克服了静态基准无法评估时间有效性和推理能力的缺陷,从而实现对深度研究代理的可扩展、无需参考的评估。
主要贡献
- 我们识别了当前深度研究代理评估基准中存在的“合成幻象”,即表面流畅性和引用对齐掩盖了事实准确性、时间有效性与推理能力的关键缺陷,原因在于静态评估器缺乏工具使用能力。
- 我们引入了一个四维度分类体系用于深度研究评估,揭示了能力不匹配问题:现有评估器无法独立检索或验证信息,因此不适合评估其声称衡量的维度。
- 我们提出了 DREAM,一种强制实现能力对等的代理评估框架,通过工具调用代理生成自适应指标,在受控实验中展示了其对事实和时间衰减的更高敏感性。
引言
作者利用深度研究代理(即能够自主检索、综合并报告复杂主题的大型语言模型)的兴起,解决了评估中的一个关键空白:现有基准奖励流畅、引用充分的输出,却忽视了事实衰减、逻辑缺陷和时间过时的问题,他们将此称为“合成幻象”。先前的方法依赖静态评估器或固定数据集,缺乏验证主张与实时、动态来源的能力,导致能力不匹配。他们的主要贡献是 DREAM,一种代理评估框架,它模仿研究人员自身使用工具的行为——通过工具调用代理动态生成自适应指标,以验证事实、评估推理并跟踪时间有效性,从而提供一种比当前基准更敏感于现实世界退化的可扩展、无需参考的方法。
数据集

-
作者使用了一组精心设计的10个研究查询,旨在测试政策分析和因果解释等领域的多步推理能力。这些查询通过 Smolagents 的深度研究代理生成20份报告:10份高质量(逻辑严谨、论据充分)和10份有缺陷(故意包含无支持主张、循环推理、选择性证据)——形成10组配对,用于受控比较。
-
为评估超越引用对齐的事实基础,他们构建了一个包含15组对抗性数据集。每组包含一个具有有效来源的真实主张和一个具有似是而非但引用对齐的虚假主张(例如过时统计数据、边缘叙事)。这些虚假主张能通过标准引用忠实度检查,但与客观现实相矛盾。
-
为测试指标敏感性,他们绕过主张提取,直接构建了15个合成评估批次,混合真实与虚假变体,腐败率 r ∈ [0,1]。这些批次被输入 DRB-FACT 和 DREAM-Factuality 评估器,以测量各评估器对日益增多的错误信息的响应。
-
数据集用于基准测试评估框架:DREAM-RQ 和 DRB-RACE 在报告配对上评估推理质量,而 DRB-FACT 和 DREAM-Factuality 在对抗性主张配对上测试,以揭示其对真实世界错误与引用对齐的不同敏感性。
方法
作者采用一个名为 DREAM 的两阶段代理评估框架,动态构建并执行针对深度研究代理的特定查询评估协议。该系统旨在通过将每个指标与具备相应工具和推理能力的评估器匹配,弥合评估器与被评估代理之间的能力差距。整体架构模块化,包括协议创建阶段(生成自适应和静态指标)和协议执行阶段(将每个指标路由至专用评估器)。
在协议创建阶段,协议创建代理(实现为配备检索工具如网络搜索、ArXiv 和 GitHub 的 CodeAgent)分析研究查询,生成自适应指标。这些包括关键信息覆盖率(KIC),将关键事实转化为可验证的是/否问题;以及推理质量(RQ),生成开放式问题并配以结构化验证计划,指定如何从报告和外部来源提取并交叉验证推理链。静态指标在所有任务中统一应用,包括写作质量(WQ)、事实性、引用完整性(CI)和领域权威性(DA)。如下图所示,该阶段输出一个结合自适应与静态组件的综合评估协议。
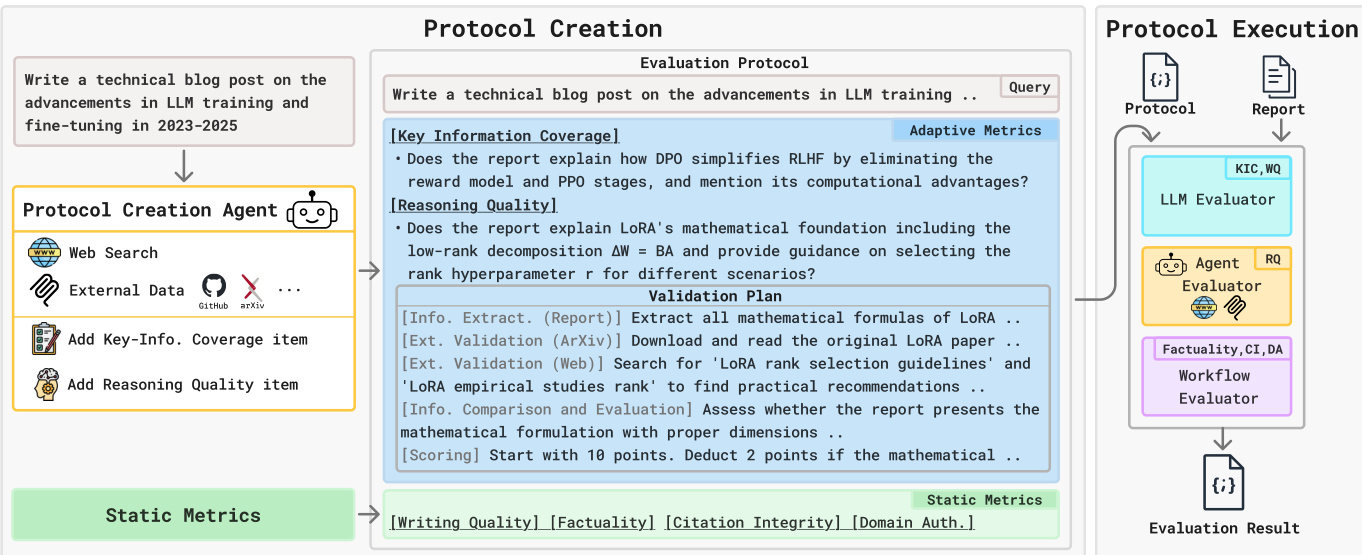
在协议执行阶段,DREAM 根据能力对等将每个指标路由至三种评估器类型之一。LLM 评估器处理无需外部工具使用的判断指标:它使用固定评分标准评估写作质量,并对照代理生成的清单验证关键信息覆盖率。代理评估器(也是 CodeAgent)通过自主执行验证计划、检索外部证据并评分报告推理的连贯性和有效性,执行推理质量指标。工作流评估器为事实性、引用完整性和领域权威性实现多阶段管道。对于事实性,它提取关键主张,生成中性化搜索查询以避免确认偏见,并执行双流证据提取,获取支持与反驳证据后做出判断。引用完整性定义为主张归属(CA)与引用忠实度(CF)的调和平均数,确保高分需同时满足引用存在与内容对齐。领域权威性通过提取根域名,基于机构声誉在1–10分范围内评分,并对标准化分数取平均值来评估引用来源的可信度。
请参考框架图以可视化评估器类型及其各自分配的指标。LLM 评估器处理 WQ 和 KIC,代理评估器处理 RQ,工作流评估器处理事实性、CI 和 DA。每个评估器的内部工作流模块化设计,旨在隔离特定验证任务——例如,工作流评估器的事实性模块包括主张提取、中性查询生成、双流证据检索和最终判断。
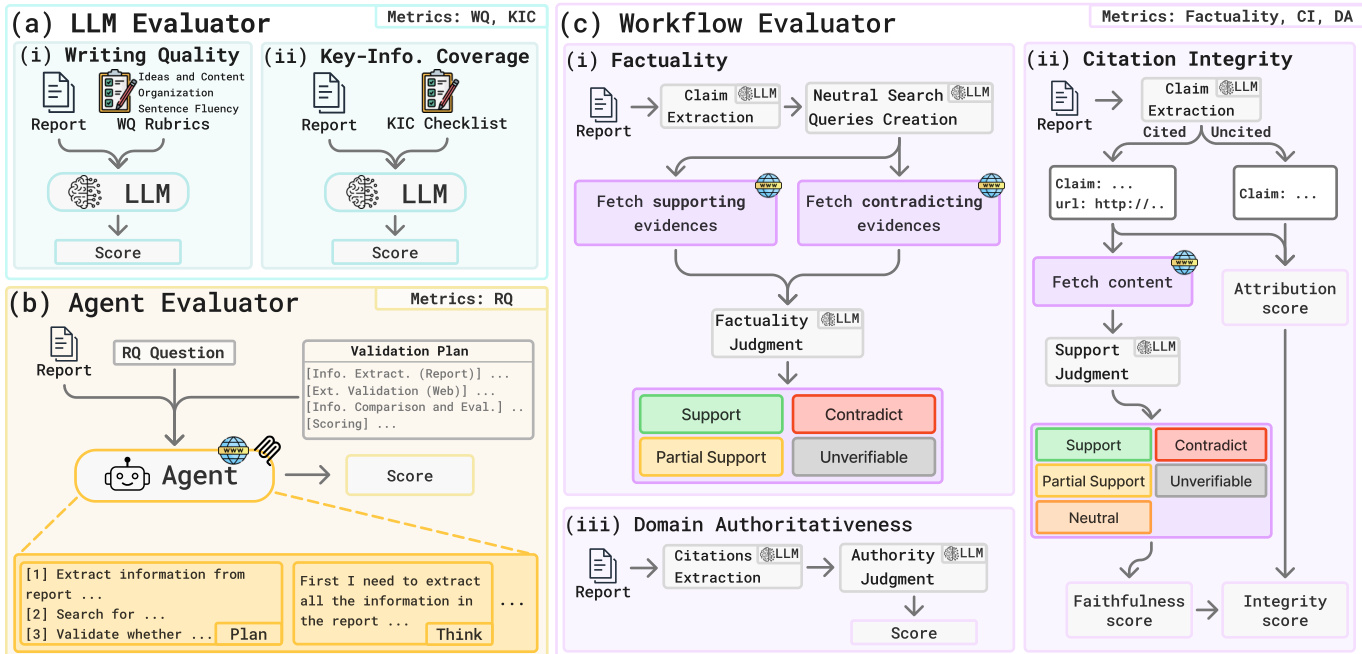
每个指标的评分形式化以确保定量可比性。例如,事实性计算为支持与部分支持主张的加权平均:
Ft=Nsupp,t+Npart,t+Ncon,tNsupp,t+0.5Npart,t引用完整性定义为 CA 与 CF 的调和平均数:
CI=CA+CF2⋅CA⋅CF关键信息覆盖率是 K 个生成问题的简单召回率:
KICt=K1k=1∑Kvk,t该架构使 DREAM 能够适应深度研究任务的开放性,同时通过代理工具使用和多层面验证管道保持严格的基于事实的评估。
实验
- DREAM 引入了一种新颖的评估框架,通过代理推理和外部工具访问动态构建自适应指标,克服了静态人工设计评分标准或 LLM 生成清单的局限性。
- 人工评估确认,代理生成的协议高度可解释、清晰且可验证,尤其在集成检索能力时。
- DREAM 展示出对时间过时的更高敏感性,比依赖固定标准的静态基准更有效地惩罚过时报告。
- 它可靠地检测流畅、结构良好的报告中的细微推理缺陷——而现有指标往往失败甚至奖励有缺陷的内容。
- DREAM 揭示仅靠引用对齐不足以保证事实正确性,表明即使引用充分的主张在未经外部验证时仍可能事实错误。
- 基准测试显示,领先的开源研究代理能生成高质量、流畅的报告,但存在系统性引用基础缺陷,要么引用不准确,要么极少引用。
- DREAM 的评估信号在不同 LLM 底层模型上表现稳健,尽管分数略有波动,但仍保持一致的代理排名。
作者使用报告长度统计数据比较三个开源深度研究代理在三个基准上的表现,发现 Smolagents Open DR 始终生成显著更长且变化更大的报告,而 Tongyi Deep Research 生成最简洁和稳定的输出。LangChain Open DR 居中,长度和变化性适中。这些输出规模差异在不同数据集中持续存在,表明代理间存在不同的设计优先级或生成行为。

作者使用基于代理的框架生成评估标准,发现结合多步推理与外部检索显著提升了生成指标的相关性、可验证性和清晰度,优于静态 LLM 或无工具访问的代理。人工评估者一致给予检索增强协议更高评分,确认基于外部证据的评估增强了可解释性和验证可靠性。这种结构优势使更可靠地检测时间过时、推理缺陷和事实错误成为可能,而静态或引用对齐方法会遗漏这些。

作者使用 DREAM 在多个评判模型上评估三个深度研究代理,发现尽管绝对分数因评估器而异,但代理的相对性能排名保持一致。Smolagents Open DR 在关键信息覆盖率和推理质量等自适应指标上始终领先,而 LangChain Open DR 在引用归属上更强但忠实度较弱。Tongyi Deep Research 在写作质量上得分最高,但引用完整性几乎为零,凸显开源系统在可靠来源基础方面的持续差距。

作者使用 DREAM 在多个数据集上基准测试三个开源深度研究代理,发现尽管代理能生成流畅且事实基础的报告,但它们始终未能建立可靠的引用完整性。Smolagents Open DR 在大多数自适应和静态指标上领先(除引用相关指标外),而 LangChain Open DR 在引用归属上更强但忠实度差。结果确认当前代理缺乏对外部来源的稳健基础,暴露了尽管内容质量高,但在可信研究综合方面的关键差距。

作者使用 DREAM-KIC 评估深度研究报告的时间敏感性,发现它始终惩罚过时信息,而静态指标如 DRB-RACE 在较旧知识截止日期下显示极小或不一致的退化。结果表明,基于最新证据的代理评估是检测时间过时所必需的,因为静态评分标准无法捕捉时间敏感的事实缺口。
