HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

前沿人工智能风险管理体系实践:风险分析技术报告 v1.5

统一潜在表示(Unified Latents, UL):如何训练你的潜在表示
























前沿人工智能风险管理体系实践:风险分析技术报告 v1.5
统一潜在表示(Unified Latents, UL):如何训练你的潜在表示
Mobile-Agent-v3.5:多平台基础GUI Agent
SpargeAttention2:通过混合Top-k+Top-p掩码与蒸馏微调实现可训练的稀疏注意力
AutoWebWorld:通过有限状态机合成无限可验证的Web环境
无界客户端-服务器系统的有界模型检测
检索增强模型相较于LLM在推理方面带来了多少提升?面向混合知识的多跳推理基准测试框架
视觉虫洞:异构多Agent系统中的潜在空间通信
帕尼尼:通过结构化记忆实现令牌空间中的持续学习
ResearchGym:在真实世界AI研究中评估语言模型代理
学习配置智能体AI系统
人工智能代理社会中的社会化现象是否涌现?——Moltbook案例研究
稀疏自编码器的合理性检验:SAE 是否优于随机基线?
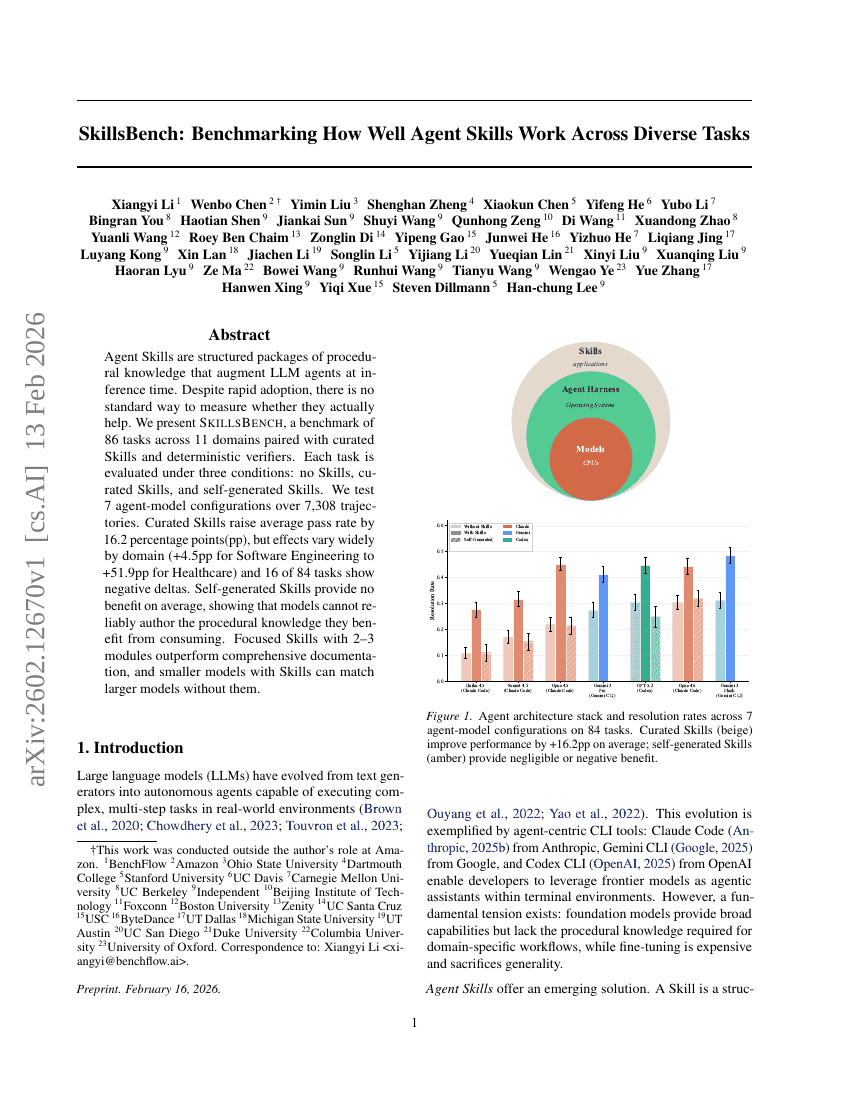
SkillsBench:跨多样化任务评估Agent技能的有效性
GLM-5:从Vibe Coding到Agentic Engineering
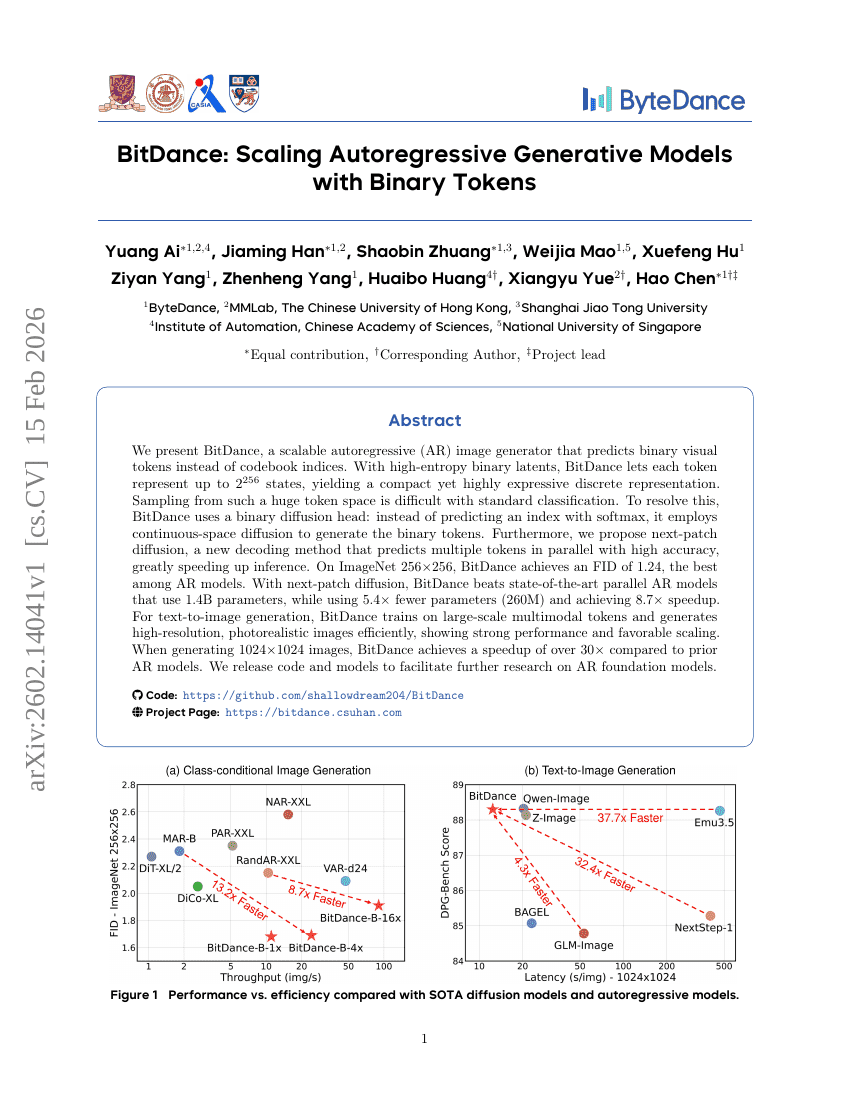
字节跳动:基于二进制标记的自回归生成模型扩展
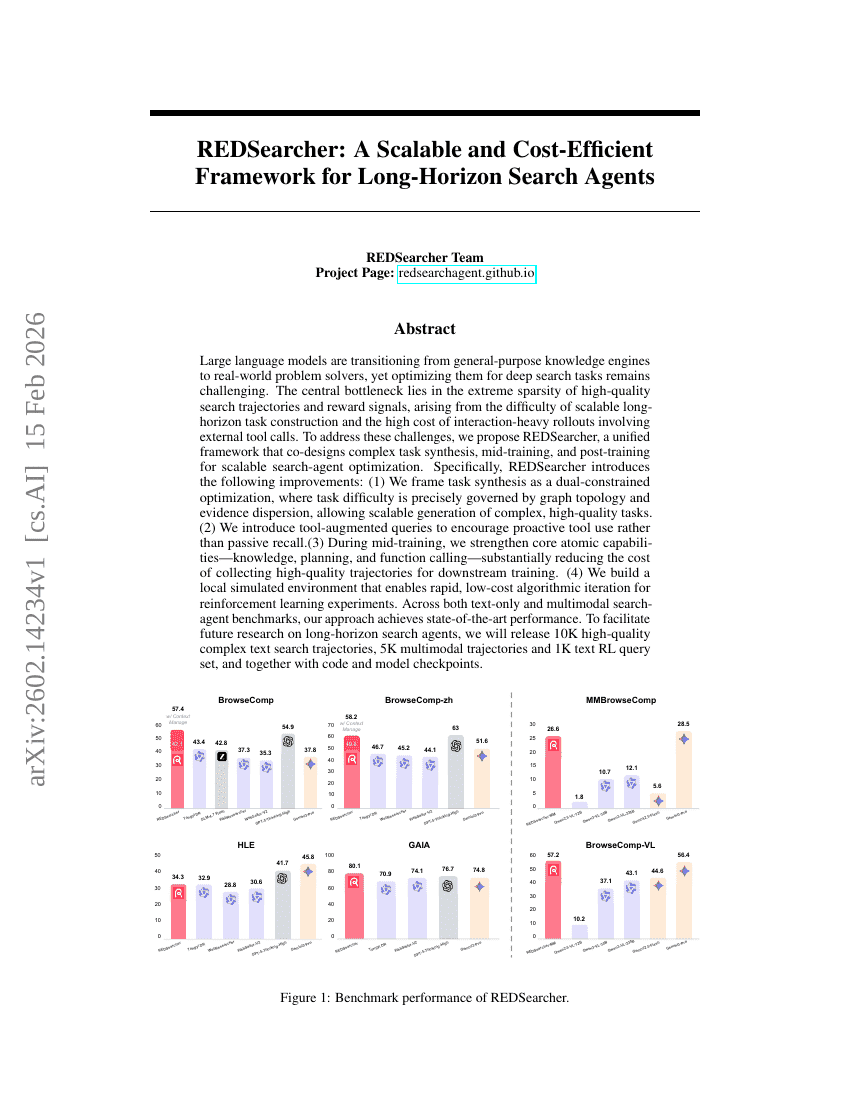
REDSearcher:一种可扩展且成本高效的长时序搜索Agent框架
Qute:面向量子原生数据库
InnoEval:将研究创意评估视为一种基于知识的多视角推理问题
查询作为锚点:基于大语言模型的场景自适应用户表征
SemanticMoments:通过三阶矩特征实现无需训练的动作相似性计算
RLinf-Co:基于强化学习的模拟-现实协同训练用于视觉-语言-动作模型
ABot-M0:基于动作流形学习的机器人操作视觉-语言-动作基础模型
强化学习如何提升视觉推理能力?一种“怪物合成式”的分析
MedXIAOHE:构建医学领域MLLMs的完整方案
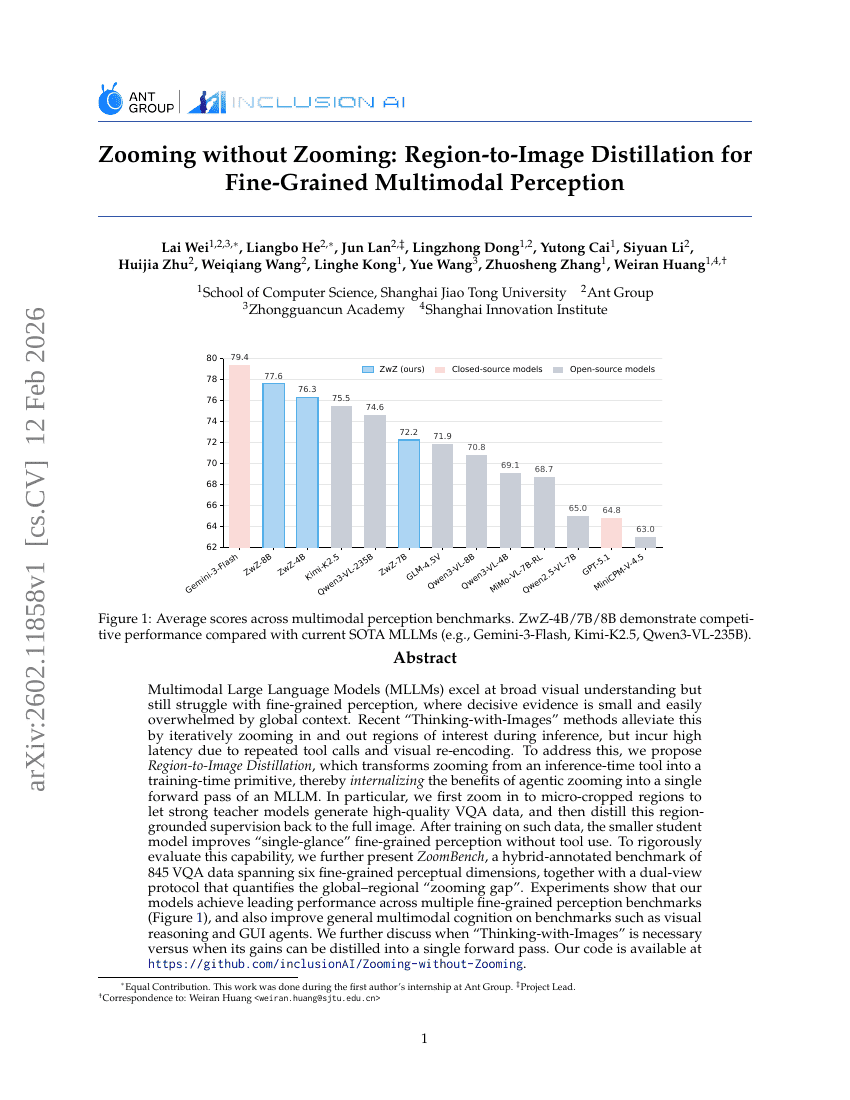
无需缩放的缩放:面向细粒度多模态感知的区域到图像知识蒸馏
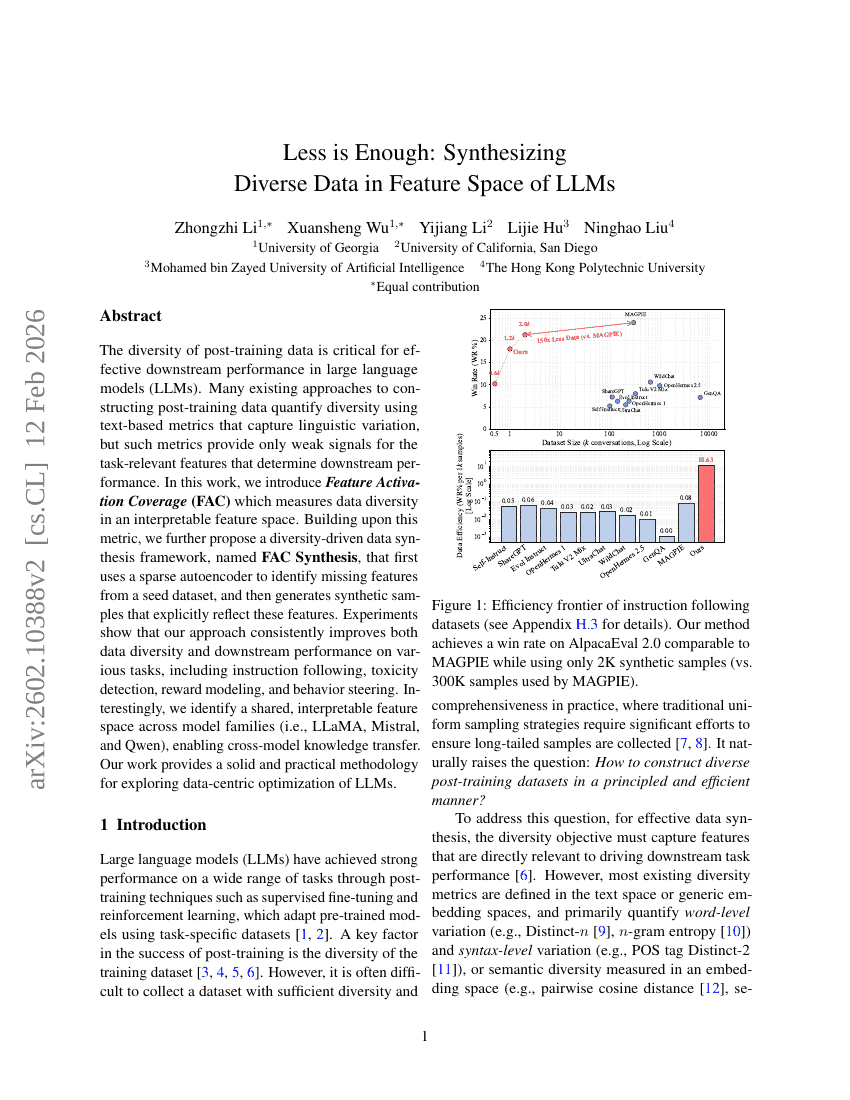
少即是足:在LLM的特征空间中合成多样化数据
GigaBrain-0.5M*:一种基于世界模型强化学习的VLA
MOSS-Audio-Tokenizer:面向未来音频基础模型的音频分词器扩展
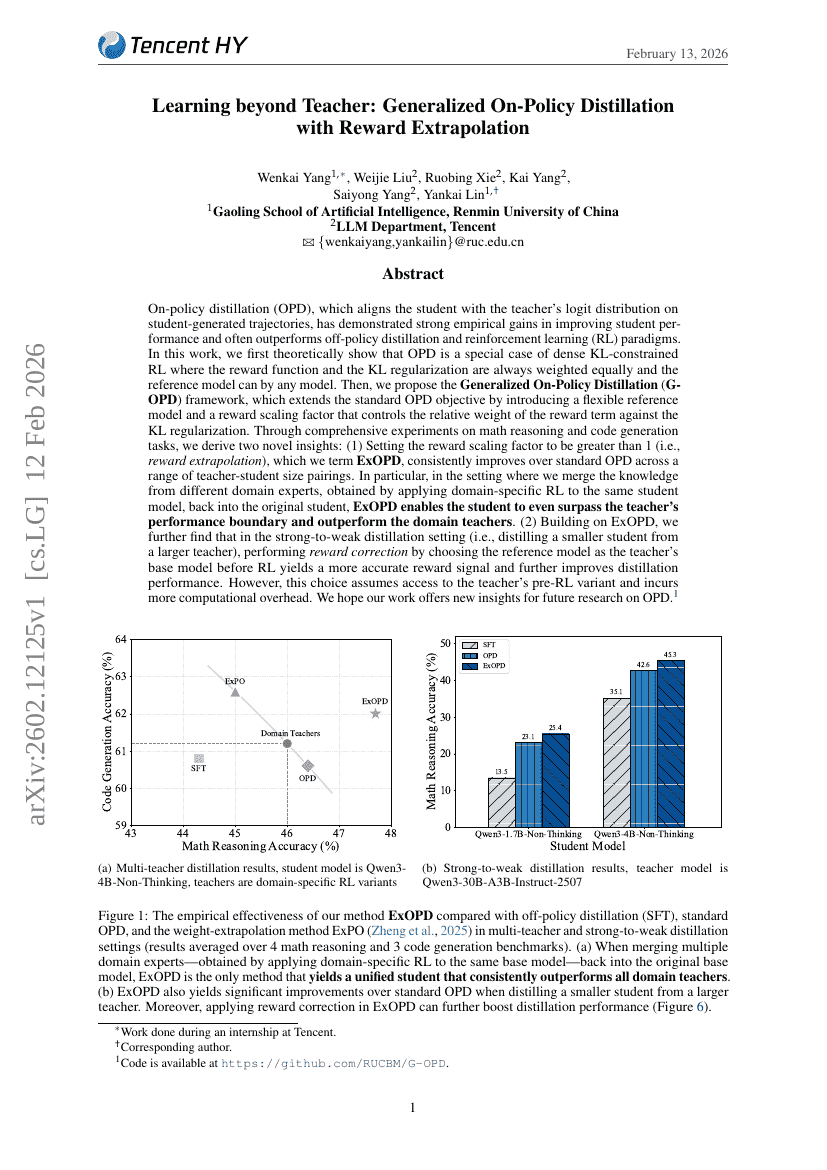
超越教师的学习:基于奖励外推的广义在线策略蒸馏
DeepGen 1.0:一种轻量级统一多模态模型,用于推进图像生成与编辑
Composition-RL:为大语言模型强化学习构建可验证的提示词组合
Mobile-Agent-v3.5:多平台基础GUI Agent
SpargeAttention2:通过混合Top-k+Top-p掩码与蒸馏微调实现可训练的稀疏注意力
AutoWebWorld:通过有限状态机合成无限可验证的Web环境
无界客户端-服务器系统的有界模型检测
检索增强模型相较于LLM在推理方面带来了多少提升?面向混合知识的多跳推理基准测试框架
视觉虫洞:异构多Agent系统中的潜在空间通信
帕尼尼:通过结构化记忆实现令牌空间中的持续学习
ResearchGym:在真实世界AI研究中评估语言模型代理
学习配置智能体AI系统
人工智能代理社会中的社会化现象是否涌现?——Moltbook案例研究
稀疏自编码器的合理性检验:SAE 是否优于随机基线?
SkillsBench:跨多样化任务评估Agent技能的有效性
GLM-5:从Vibe Coding到Agentic Engineering
字节跳动:基于二进制标记的自回归生成模型扩展
REDSearcher:一种可扩展且成本高效的长时序搜索Agent框架
Qute:面向量子原生数据库
InnoEval:将研究创意评估视为一种基于知识的多视角推理问题
查询作为锚点:基于大语言模型的场景自适应用户表征
SemanticMoments:通过三阶矩特征实现无需训练的动作相似性计算
RLinf-Co:基于强化学习的模拟-现实协同训练用于视觉-语言-动作模型
ABot-M0:基于动作流形学习的机器人操作视觉-语言-动作基础模型
强化学习如何提升视觉推理能力?一种“怪物合成式”的分析
MedXIAOHE:构建医学领域MLLMs的完整方案
无需缩放的缩放:面向细粒度多模态感知的区域到图像知识蒸馏
少即是足:在LLM的特征空间中合成多样化数据
GigaBrain-0.5M*:一种基于世界模型强化学习的VLA
MOSS-Audio-Tokenizer:面向未来音频基础模型的音频分词器扩展
超越教师的学习:基于奖励外推的广义在线策略蒸馏
DeepGen 1.0:一种轻量级统一多模态模型,用于推进图像生成与编辑
Composition-RL:为大语言模型强化学习构建可验证的提示词组合