Command Palette
Search for a command to run...
MolHIT:基于分层离散扩散模型推进分子图生成
MolHIT:基于分层离散扩散模型推进分子图生成
Hojung Jung Rodrigo Hormazabal Jaehyeong Jo Youngrok Park Kyunggeun Roh Se-Young Yun Sehui Han Dae-Woong Jeong
摘要
基于扩散模型的分子生成已成为人工智能驱动药物发现与材料科学领域的一项有前景的研究方向。尽管由于二维分子图的离散特性,图结构扩散模型已被广泛采用,但现有方法在化学有效性方面表现不佳,且在实现目标性质方面远逊于一维建模方法。在本工作中,我们提出MolHIT——一种强大的分子图生成框架,有效克服了现有方法长期存在的性能瓶颈。MolHIT基于分层离散扩散模型(Hierarchical Discrete Diffusion Model),将离散扩散机制拓展至包含化学先验信息的额外类别,并采用解耦原子编码策略,根据原子在分子中的化学功能角色对原子类型进行分离建模。总体而言,MolHIT在MOSES数据集上首次实现了图扩散模型在分子生成任务中的近乎完美的化学有效性,达到新的最先进水平,并在多个评价指标上超越了强大的一维建模基线。此外,我们在下游任务中进一步验证了其优异性能,包括多属性协同引导生成与骨架扩展任务。
一句话总结
来自KAIST AI、LG AI Research和首尔大学的研究人员提出了MolHIT,这是一种分层离散扩散模型,通过编码化学先验知识并解耦原子角色,显著提升了分子图生成效果,在MOSES基准上实现了近乎完美的有效性及SOTA性能,并在属性引导设计和骨架扩展等下游任务中表现优异。
主要贡献
- MolHIT引入了一种分层离散扩散模型,通过从粗到细的状态转换编码化学先验,解决了先前图扩散模型有效性低的问题,同时保持结构新颖性。
- 提出解耦原子编码,按芳香性、电荷等化学角色拆分原子类型,解决朴素编码中的信息丢失问题,提高重建和生成的可靠性。
- 在MOSES及其他基准测试中评估,MolHIT在无条件和条件任务中均实现近乎完美的有效性及最先进性能,优于1D和现有2D基线模型。
引言
作者利用分层离散扩散和化学感知的原子编码解决分子图生成问题,此前模型在有效性与新颖性之间难以平衡。现有图扩散方法将原子视为独立类别,使用忽略芳香性或电荷等化学角色的朴素编码,导致生成结构无效或不现实。MolHIT引入两阶段扩散过程:先学习粗粒度化学身份,再逐步细化,并结合解耦原子编码,明确按功能角色分离原子类型,从而在MOSES上实现近乎完美的有效性,并在骨架扩展和多属性生成等基准和下游任务中超越1D和2D基线模型。
数据集
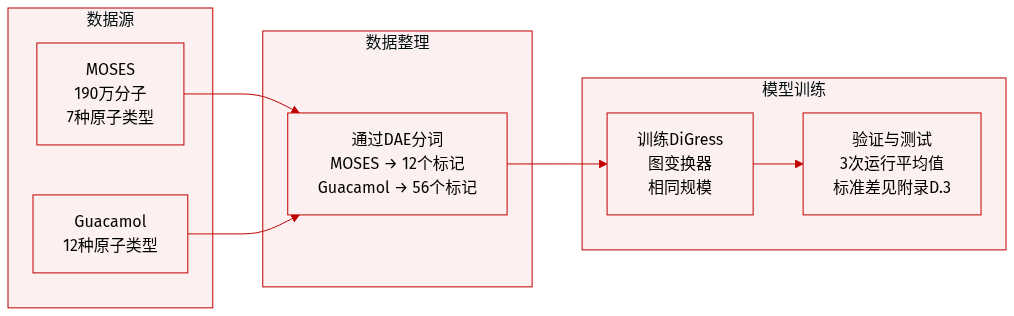
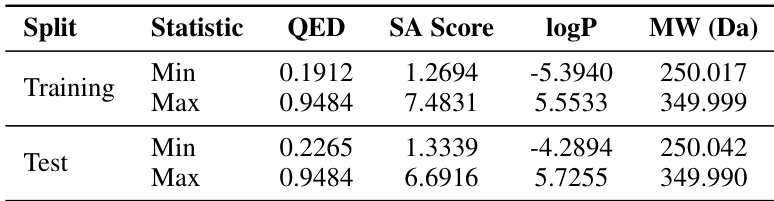
- 作者使用两个大型分子数据集:MOSES(190万分子,7种重原子类型)和Guacamol(12种重原子类型)。
- 两个数据集均通过DAE处理:MOSES扩充为12个标记,Guacamol解耦为56个标记。
- 模型架构沿用DiGress,使用相同大小的图Transformer。
- 所有结果均为三次独立运行的平均值,标准差见附录D.3。
方法
作者利用分层离散扩散模型(HDDM)将标准离散扩散框架推广为多阶段腐蚀过程,使分子图生成的去噪过程更具结构化和化学意义。核心创新在于通过中层语义类别扩充状态空间,连接干净原子类型与最终掩码状态,使模型能从宽泛化学类别逐步细化到具体原子身份。
如框架图所示,HDDM在三层状态空间上运行:干净状态集 S0、中层状态集 S1 和单一掩码状态 S2={m}。前向扩散过程由一系列转移矩阵控制,逐步将干净原子映射到其语义组(如卤素、芳香族、硫族、脂肪族),最终过渡到掩码状态。该分层结构通过块结构转移核 Q(1)(映射干净状态到中层状态)和 Q(2)(映射所有非掩码状态到掩码)编码。在时间步 t 的累积前向转移定义为:
Qt=αtI+(βt−αt)Q(1)+(1−βt)Q(2),其中 αt 和 βt 是单调递减的扩散调度,满足 α0=β0=1 且 αT=βT=0,且 αt≤βt。该公式确保Chapman–Kolmogorov一致性,支持可追踪的多步转移。
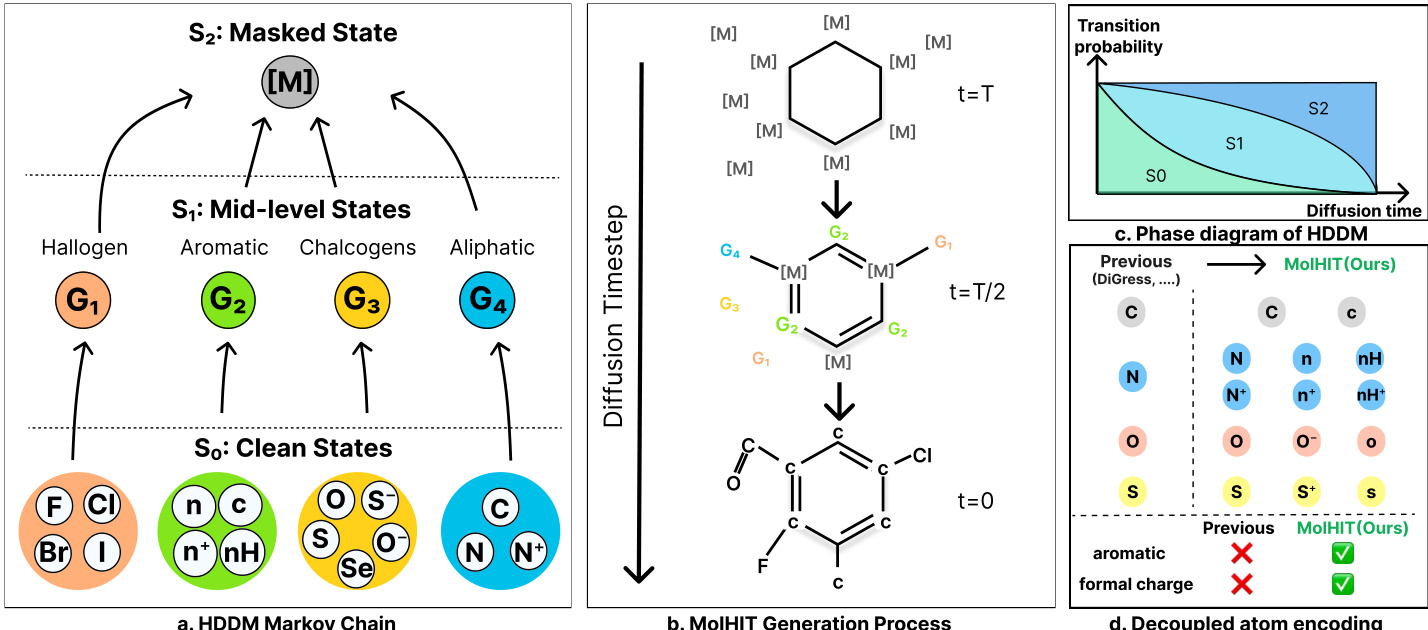
对于分子图生成,作者将原子和键的扩散过程解耦。原子通过HDDM过程扰动,键则使用均匀转移核以确保结构多样性。前向动力学如下:
QX,t=αX,tI+(βX,t−αX,t)QX,t(1)+(1−βX,t)QX,t(2),QE,t=αE,tI+(1−αE,t)1dE1dET.模型训练目标是从噪声图 Gt 预测干净图 G0=(X0,E0),使用交叉熵损失独立优化原子和键预测:
Lθ=Et,Gt∼q(⋅∣G0)[i=1∑n−logpθX(X0,i∣Gt,t)+λ1≤i<j≤n∑−logpθE(E0,ij∣Gt,t)],其中 λ 平衡节点和边的贡献。
为增强化学保真度,作者引入解耦原子编码(DAE),通过明确将芳香性、氢饱和度和形式电荷编码为独立标记状态来扩展原子词汇。这解决了粗粒度编码中的结构歧义(如区分[n]与[nH]),并支持复杂基序(如杂芳香族和两性离子)的近乎完美重建。如图所示,DAE使MolHIT能生成形式电荷比例与训练分布匹配的分子,这是先前模型所不具备的能力。
采样通过“投影-加噪”(PN)采样器执行,该采样器通过分类采样将模型的去噪预测投影到离散流形,再使用前向核重新加噪至前一时间步。这绕过后验约束并鼓励结构多样性。温度采样和top-p采样选择性应用于原子预测,以控制质量-多样性权衡。整体生成过程如图所示:分子从 t=T 的完全掩码状态,经 t=T/2 的中层语义状态,最终在 t=0 重构为完整结构,由分层转移概率引导。
实验
- MolHIT在MOSES的关键指标(质量、有效性、FCD、骨架新颖性)上达到最先进性能,展示了在药物样化学空间中强导航能力,同时探索新颖结构。
- 在GuacaMol上,MolHIT在大多数指标上优于基线模型,尽管使用完整未过滤数据集,显示出对带电和复杂分子的鲁棒性;FCD性能差距归因于扩展原子词汇的建模挑战。
- 在多属性引导生成中,MolHIT显著提升条件精度(MAE降低52.4%)和可靠性(Pearson相关系数高达0.950),同时不牺牲有效性,证实其对QED、SA、MW和logP等化学属性的有效控制。
- 在骨架扩展中,MolHIT在有效性、多样性和命中率上超越DiGress,表明其在保留固定骨架的同时生成化学合理且结构多样的扩展部分的能力更优。
- 消融研究证实DAE、PN采样器和HDDM均对整体性能有显著贡献,温度采样揭示质量与新颖性之间的权衡,最优设置可实现近乎完美的有效性和高质量。
作者在MOSES基准上使用MolHIT生成分子,并与1D序列和2D图基线模型比较。结果显示MolHIT在质量和骨架新颖性上达到最高,同时保持近乎完美的有效性,在结构创新与化学可行性之间优于先前模型。模型还表现出强分布保真度,体现在高骨架检索和SNN得分,表明其有效捕捉底层药物样化学空间而不发生过拟合。
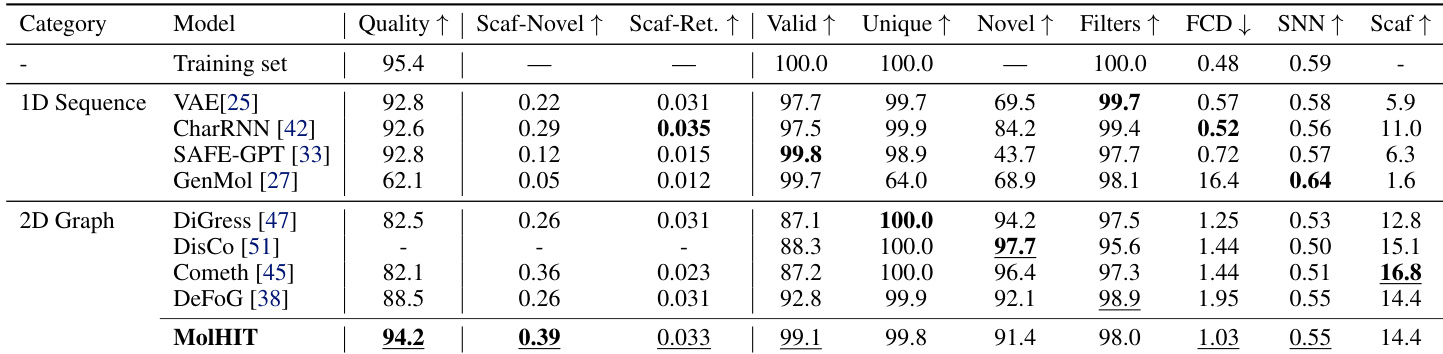
作者使用完整未过滤的GuacaMol数据集评估MolHIT,与先前在过滤子集上训练的模型形成对比。结果显示MolHIT在有效性与骨架新颖性上达到最高,同时保持强分布保真度,尽管训练周期更少,仍在大多数指标上优于DiGress变体。模型在处理带电原子和更广化学空间时表现出鲁棒性,同时不牺牲结构质量。

作者使用MOSES数据集评估多属性引导生成,对模型施加QED、SA、logP和MW条件。结果显示MolHIT在匹配目标属性方面精度高(MAE低,Pearson相关性强),同时有效性保持在95%以上。这表明模型有效平衡了属性控制与结构可行性。
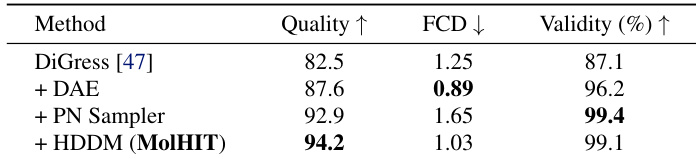
作者通过消融研究展示,将解耦原子编码、PN采样器和HDDM逐步整合到DiGress中,可逐步提升分子生成质量、有效性和分布保真度。结果显示MolHIT在质量上达到最高,有效性近乎完美,同时保持有竞争力的FCD,表明其有效导航药物样化学空间。每个组件均有显著贡献,完整MolHIT配置优于所有中间变体。
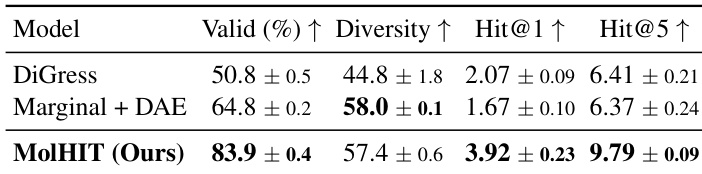
作者在骨架扩展任务中使用MOSES数据集评估MolHIT,与DiGress和带解耦原子编码的边缘转移基线比较。结果显示MolHIT在有效性和Hit@1、Hit@5得分上显著更高,表明其在保持结构多样性的同时更强地恢复真实分子扩展部分的能力。改进表明MolHIT更好地平衡了对固定骨架的保真度与对有效化学空间的探索。