Command Palette
Search for a command to run...
GUI-Libra:基于动作感知监督与部分可验证强化学习训练原生GUI智能体进行推理与行动
GUI-Libra:基于动作感知监督与部分可验证强化学习训练原生GUI智能体进行推理与行动
摘要
开源原生GUI智能体在长周期导航任务上仍落后于闭源系统。这一差距主要源于两大局限:高质量、动作对齐的推理数据稀缺,以及直接套用通用后训练流程,忽视了GUI智能体所面临的独特挑战。我们识别出这些流程中的两个根本性问题:(i)采用标准的思维链(CoT)监督微调(SFT)往往损害了智能体对环境的准确感知(grounding);(ii)分步式强化学习验证与反馈(RLVR)式训练面临部分可验证性问题,即多个动作可能均正确,但验证时仅使用单一示范动作,导致训练信号不充分。这使得离线阶段的分步评估指标难以有效预测在线任务的成功率。在本研究中,我们提出GUI-Libra——一种专为GUI智能体设计的后训练方案,以应对上述挑战。首先,为缓解动作对齐推理数据的稀缺问题,我们构建并过滤了一套数据生成与筛选流程,并发布了一个经过精心整理的81K规模GUI推理数据集。其次,为协调推理与环境感知之间的关系,我们提出一种动作感知的SFT方法,通过混合“先推理后执行”与“直接执行”两类数据,并对token进行重加权,以强化动作生成与环境对齐的表达能力。第三,为在部分可验证条件下稳定强化学习训练,我们揭示了在RLVR中KL正则化被长期忽视的重要性,证明KL信任区域(KL trust region)对于提升离线到在线的预测能力至关重要;同时,我们引入成功自适应缩放机制,以降低不可靠负梯度的影响。在多样化的网页与移动端基准测试中,GUI-Libra在分步准确率和端到端任务完成率方面均表现出持续提升。实验结果表明,通过精心设计的后训练策略与数据治理方法,可在无需昂贵在线数据收集的前提下,显著增强智能体的任务求解能力。我们已开源该数据集、代码与模型,以推动面向高效推理型GUI智能体的后训练研究发展。
一句话总结
来自 UIUC、微软和北卡罗来纳大学教堂山分校的研究人员推出了 GUI-Libra,这是一种定制化的训练框架,通过精心构建 81K 条推理数据、采用动作感知监督优化监督微调(SFT)、并通过 KL 正则化稳定强化学习(RL),显著提升了 Android、网页和移动端基准测试中的任务完成率,且无需昂贵的在线数据。
主要贡献
- 为解决 GUI 代理高质量推理数据稀缺的问题,GUI-Libra 引入了一套可扩展的数据构建与过滤流程,发布了一个精心筛选的 81K 数据集,将推理轨迹与可执行动作对齐,以实现更有效的监督。
- 该框架提出动作感知的监督微调方法,混合“先推理后动作”与“直接动作”监督模式,通过重新加权 token 以优先处理定位与动作 token,从而缓解长链式思维推理通常导致的定位精度下降问题。
- 针对部分可验证场景下的强化学习,GUI-Libra 通过 KL 正则化与成功自适应缩放稳定训练,提升离线到在线预测能力,在 AndroidWorld、Online-Mind2Web 和 WebArena-Lite-v2 基准测试中取得显著提升。
引言
作者利用原生 GUI 代理——即端到端的视觉-语言模型,可直接将指令映射为可执行动作——来解决长视野导航任务,其中推理与精确定位必须并存。先前工作面临两大关键问题:推理数据稀缺且噪声大,削弱策略学习;通用的后训练流程未能考虑 GUI 特有的挑战,如部分可验证性(存在多个有效动作但仅标注一个),导致奖励模糊和 RL 不稳定。其主要贡献是 GUI-Libra,一种统一的训练框架,引入了 81K 条动作对齐的推理数据集、动作感知的监督微调(优先处理定位 token 以防止 CoT 引发的性能退化),以及结合 KL 正则化与成功自适应梯度缩放的保守 RL,以在部分反馈下稳定学习。该方法在移动端和网页基准测试中提升任务完成率,无需昂贵的在线交互,证明更智能的数据构建与训练设计可弥合与闭源系统的性能差距。
数据集

),(2) 结构化动作(JSON 格式,包裹在 ... 中)。
-
支持 13 种动作类型:Click、Write、Terminate、Swipe、Scroll、NavigateHome、Answer、Wait、OpenAPP、NavigateBack、KeyboardPress、LongPress、Select。
-
包含 action_target(自然语言描述的 UI 元素)和 action_description(简要理由),用于过滤和上下文构建。
-
推理增强:
- 使用 GPT-4.1(在对比 GPT-4o、o4-mini、GPT-4.1 后选定),并采用增强提示,包含 GUI 特定的结构化推理指南。
- 生成器可在合理情况下覆盖原始动作;保留原始数据集中的坐标作为 point_2d。
- 生成后过滤不匹配项(如错误目标或动作)。
-
训练用途:
- SFT 数据集训练模型将视觉 + 文本上下文映射为推理 + 动作。
- RL 数据集通过平衡步骤与领域覆盖优化策略。
- 过滤过程中的边界框标注支持 RL 奖励计算。
-
评估基准:
- 定位:ScreenSpot-V2(1,269 项任务)和 ScreenSpot-Pro(1,555 项任务,高分辨率)测量在真实边界框内的点击准确率。
- 导航:
- MM-Mind2Web-v2(3,349 个样本,跨 3 个子集)使用自然语言重写的动作历史;成功需正确定位 + 精确匹配动作执行。
- AndroidControl-v2(398 个清洗后样本)通过可访问性树映射验证动作类型、值和坐标正确性——避免固定距离阈值。
该流程支持训练能够逐步推理、精准执行、跨平台泛化的 GUI 代理——同时解决高质量、富含推理的交互数据稀缺问题。
方法
作者采用两阶段训练框架 GUI-Libra,构建可在单个模型内同时推理与执行的原生 GUI 代理。该框架解决了现有流程中的关键挑战,包括长链式思维(CoT)导致的定位退化,以及强化学习中逐步奖励的部分可验证性。整体架构旨在生成不仅动作预测准确,且在长视野导航中对分布偏移和奖励模糊具有鲁棒性的代理。
参见框架图,其展示了端到端流程。过程始于高质量推理数据的构建,随后是混合“推理后动作”与“直接动作”监督的动作感知监督微调(ASFT)阶段,最后是结合 KL 正则化与成功自适应负梯度缩放的保守强化学习(RL)阶段,以在部分可验证奖励下稳定策略优化。
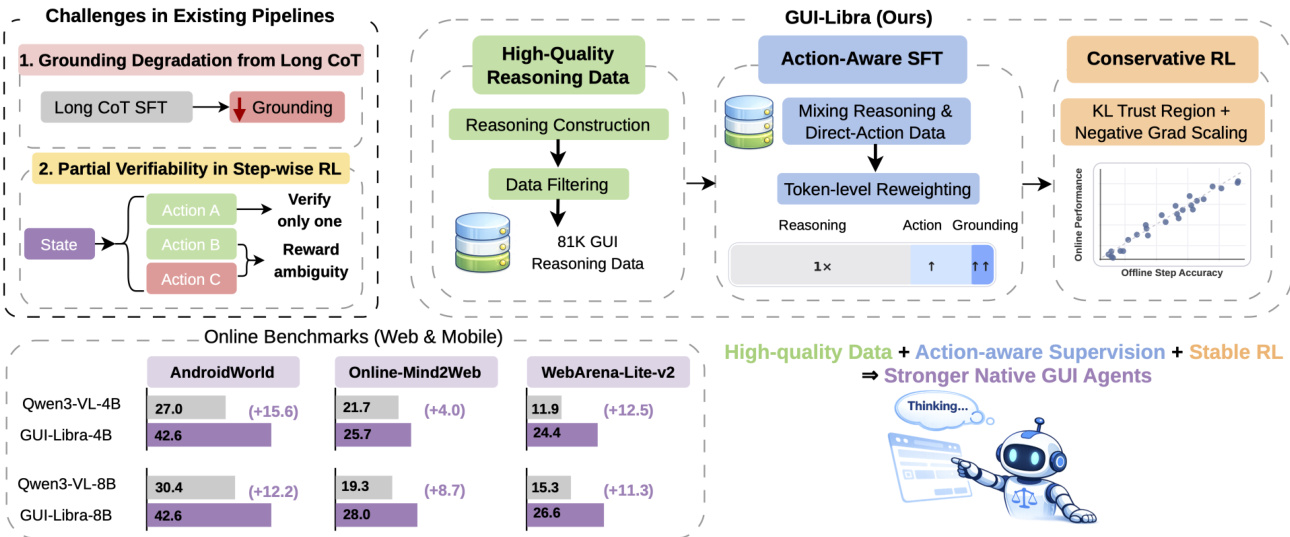
在第一阶段,作者引入动作感知 SFT,训练混合了含与不含显式推理轨迹的数据。混合数据集包含“推理后动作”样本(模型先生成思考过程再输出动作)和“直接动作”样本(仅保留 与 之间的结构化动作输出)。这种双模式监督增强了动作预测的学习信号,同时减少对冗长中间推理的依赖,从而缓解定位退化。训练目标进一步引入 token 级重加权,赋予动作与定位 token 更高权重。具体而言,... 内的 token 被视为动作输出,并拆分为动作 token(不含 point_2d 字段)与定位 token(与 point_2d 关联)。ASFT 目标函数定义为加权交叉熵损失:
LASFT(θ)=−E(xt,ct,at,gt)∼Dmix∣ct∣+αa∣at∣+αg∣gt∣logπθ(ct∣xt)+αalogπθ(at∣xt,ct)+αglogπθ(gt∣xt,ct,at),其中 αa 和 αg 控制动作与定位 token 的相对重要性。这种灵活加权方案允许模型强调以动作为中心的学习,同时保留推理能力。
如图所示,第二阶段采用保守 RL,基于 ASFT 初始化的策略构建。作者在部分可验证的逐步奖励下采用组相对策略优化(GRPO)框架。为应对分布偏移与奖励模糊的挑战,他们引入两个关键组件:KL 正则化与成功自适应负梯度缩放(SNGS)。KL 正则化通过相对于参考策略(通常为 SFT 初始化)维持信任区域来约束策略漂移,有助于控制占用不匹配 C(π) 与离线有效性质量 ηˉπ,确保离线匹配分数仍可预测在线成功率。SNGS 通过降低由模糊“负”结果引发的梯度进一步优化策略更新。具体而言,对每个状态,从一组 G 个候选动作中计算经验组成功率 p^g(s),并仅对负优势应用缩放因子 λg(s):
A~k≜{Ak,λg(s)Ak,Ak≥0,Ak<0.其中 λg(s)=min(λ0+κp^g(s),1)。这种保守更新策略保留可靠的正信号,同时削弱由潜在有效但未获认可的替代方案驱动的更新,从而实现更稳健的策略优化。
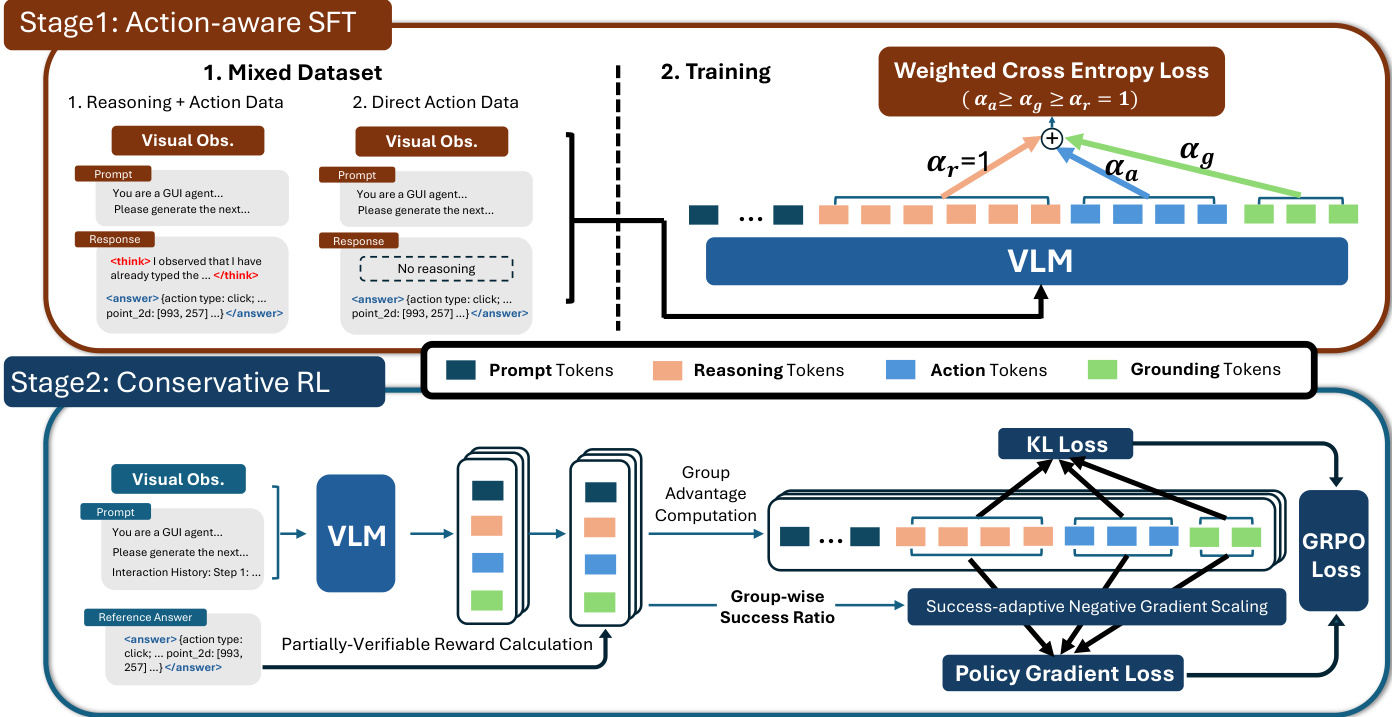
RL 阶段实施的奖励函数是格式与准确率奖励的加权和,后者为主要关注点。准确率奖励通过检查动作类型、值(使用词级 F1)与定位(预测点是否落在演示边界框内)评估语义正确性。此设计符合部分可验证性设置,其中正奖励表示可靠正确的预测,而低奖励可能源于错误动作或有效但未获认可的替代方案。
实验
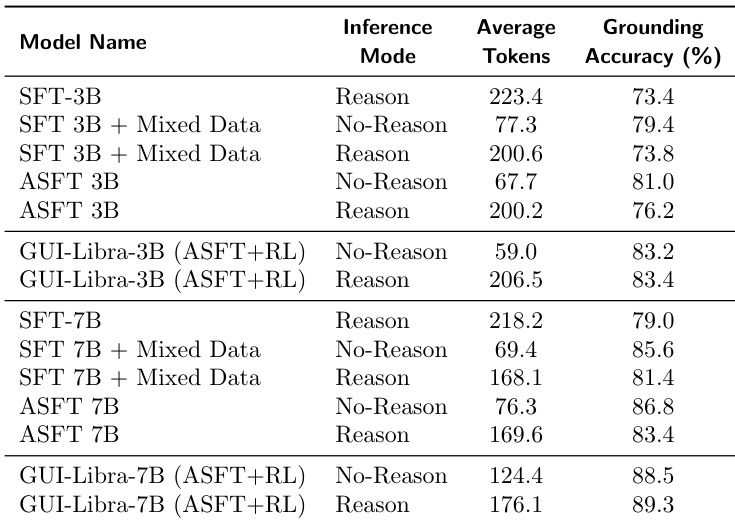
- 长 CoT 推理会降低 GUI 定位准确率,性能随响应长度增加而下降;移除 CoT 或仅使用定位训练可缓解此问题,但限制推理收益。
- 动作感知 SFT 与 RL 训练能有效对抗长 CoT 引发的定位退化,通过将推理与动作执行对齐,即使在长输出下仍保持高准确率。
- GUI-Libra 在离线与在线基准测试中持续优于基础模型和许多更大的专有系统,尤其在 AndroidWorld 和真实网站等长视野、现实环境中表现突出。
- RL 中的 KL 正则化稳定训练、提升策略熵,并强化离线指标与在线任务成功的相关性,减少奖励操纵。
- SFT 与 RL 中的数据过滤通过聚焦高质量、平衡样本增强泛化能力,在 Pass@1 和 Pass@4 指标中均取得显著提升。
- 在 RL 中混合直接定位监督可改善空间定位,但损害导航性能,揭示定位精度与推理能力之间的权衡。
- 训练与推理期间的显式推理对强在线泛化至关重要,尤其在动态环境中;即使训练时使用 CoT,推理时移除 CoT 仍会降低性能。
- GUI-Libra 的提升主要源于定位准确率的改进而非动作类型预测,如细粒度离线指标分析所示。
作者发现,推理期间更长的推理输出会持续降低 GUI 代理的定位准确率,但可通过动作感知监督微调缓解,并通过强化学习进一步解决。使用混合数据与 RL 训练的模型即使生成长推理轨迹也能实现高定位准确率,优于基础模型与标准 SFT 变体。结果表明,RL 使模型在推理模式下维持或超越定位性能,同时生成显著更多 token,表明推理与动作执行的对齐得到改善。
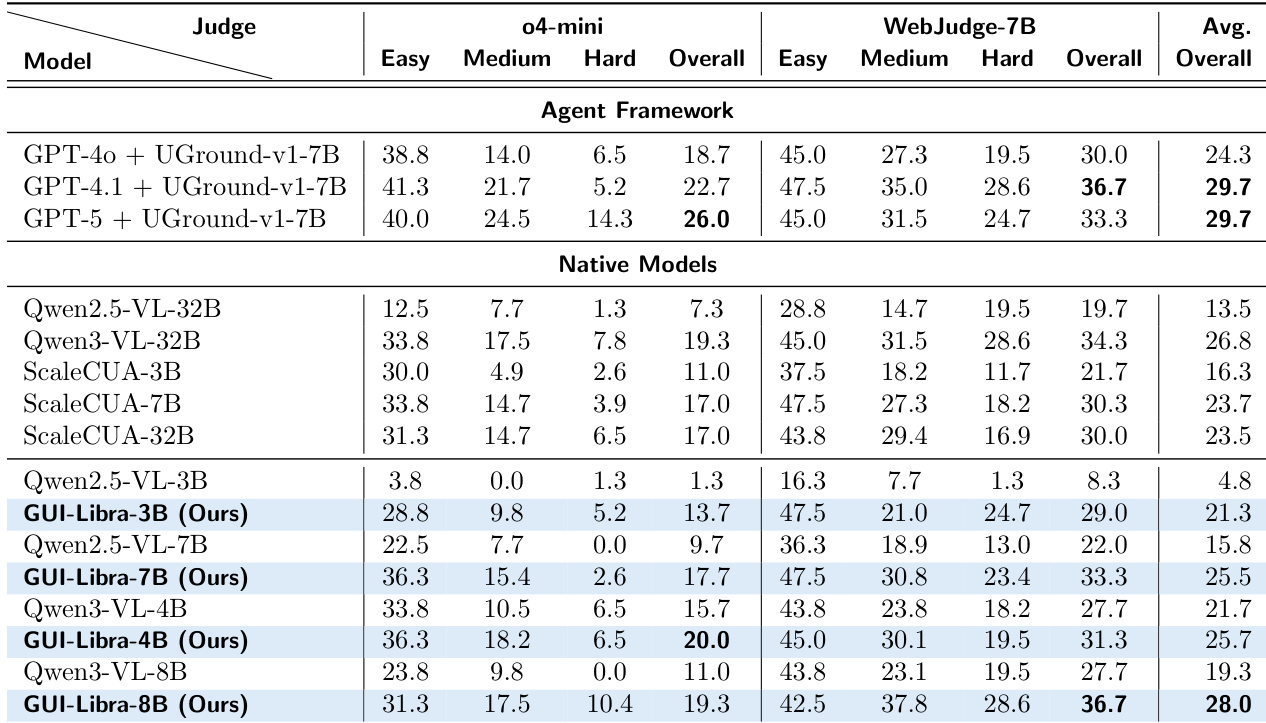
作者发现,GUI-Libra 在多个基准测试中持续优于开源与专有模型,即使参数量更小也达到最先进水平。其方法通过动作感知 SFT 与 RL 有效缓解长推理轨迹通常导致的定位退化,实现在离线与在线设置中的稳健性能。结果表明,训练与推理期间的显式推理对泛化至关重要,尤其在动态环境中。
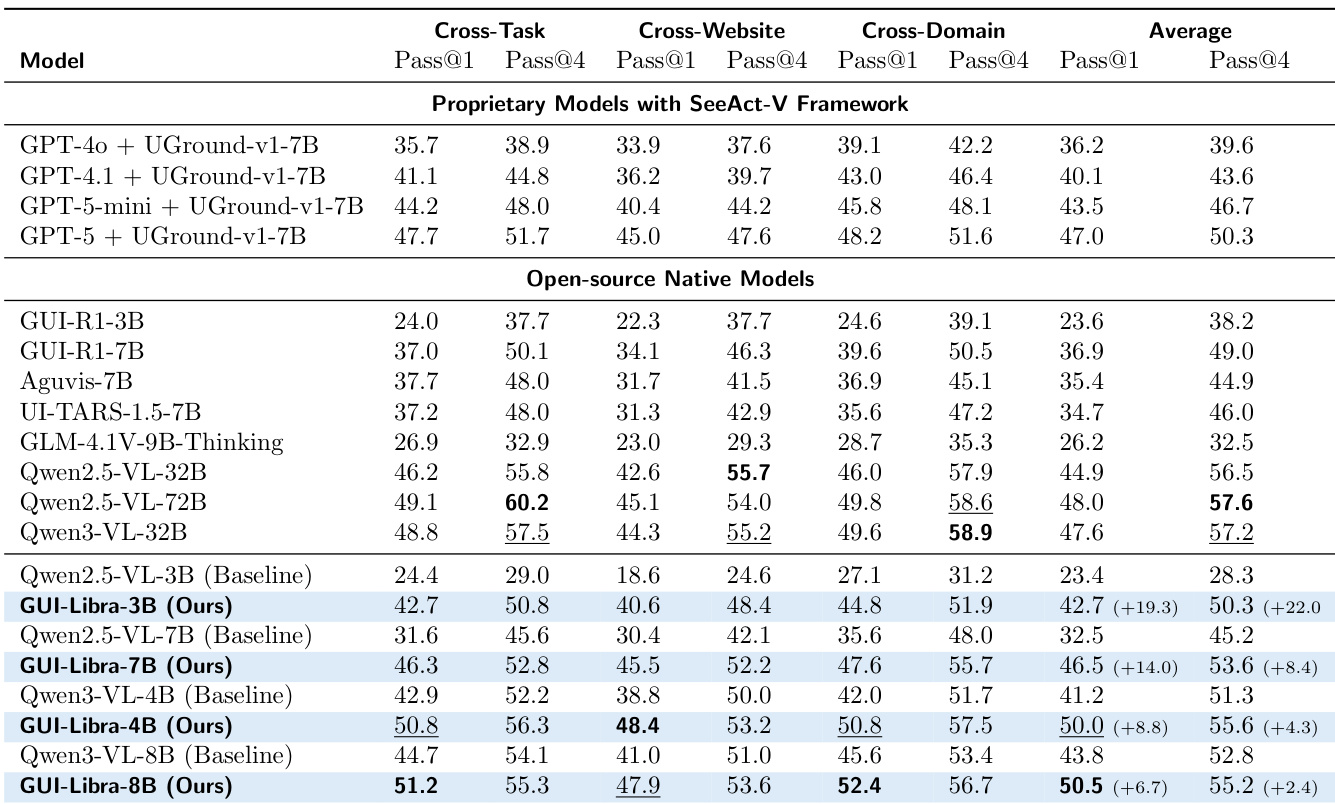
作者表明,GUI-Libra 模型在多个基准测试中持续优于其基础模型及其他开源与专有模型,即使在更小规模下也达到顶级性能。结果表明,该方法有效弥合了小模型与大系统之间的差距,尤其在跨领域与跨网站设置中,同时保持强劲的平均性能。提升归因于训练流程增强推理与定位的能力,无需大规模或领域特定数据。
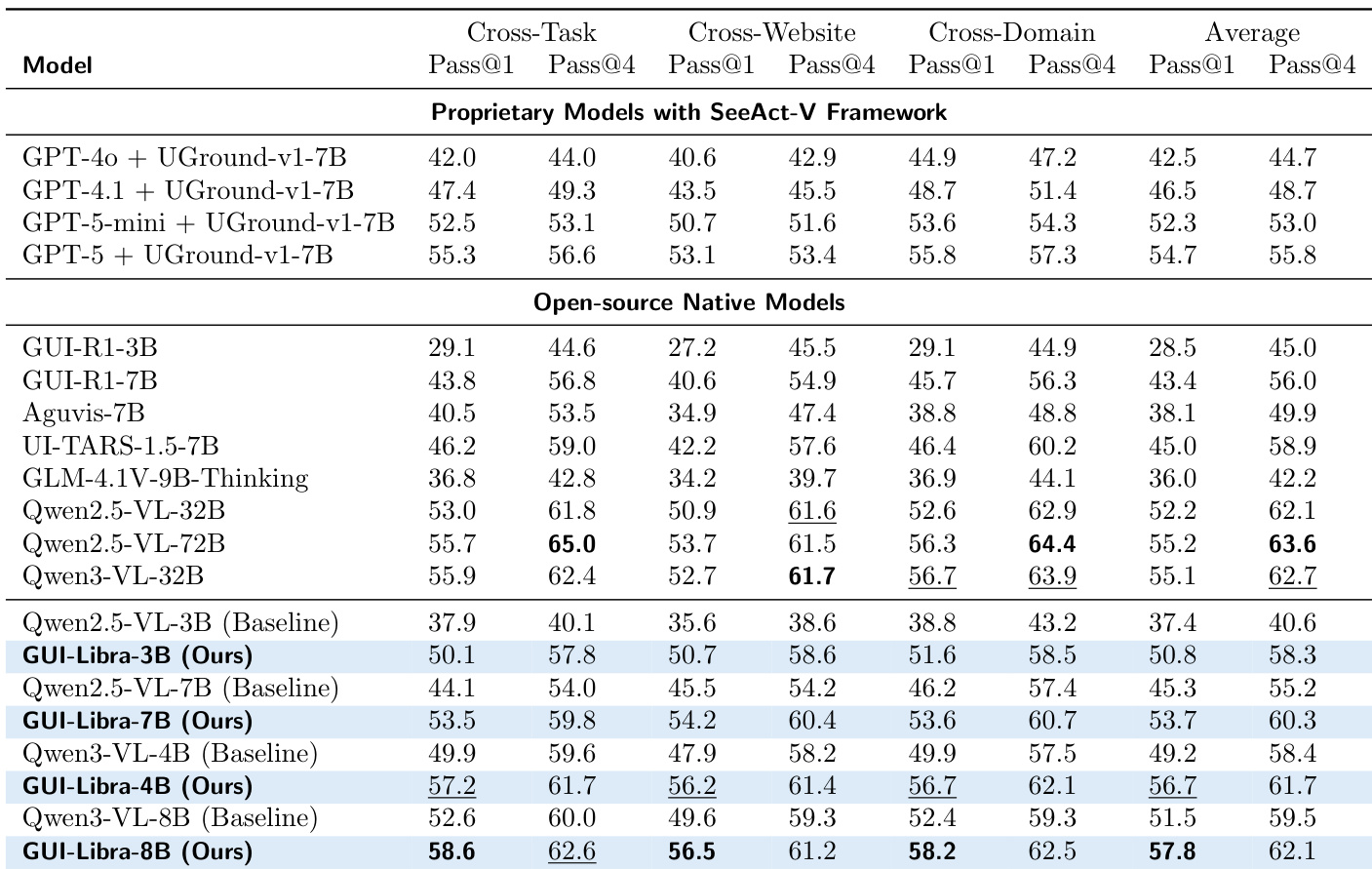
作者发现,为基础模型添加逐步摘要模块可提升任务成功率,较大模型通常实现更高准确率。然而,未含此类模块的 GUI-Libra 模型仍能匹配或超越这些增强系统的性能,表明其训练方法增强了原生决策能力。这表明,结合目标明确训练的架构简洁性可媲美更复杂的代理框架。

作者发现,GUI-Libra 模型在 Online-Mind2Web 上持续优于原生与代理框架基线,在 o4-mini 与 WebJudge-7B 评估器下均取得最高分。性能随模型规模扩展,GUI-Libra-8B 在原生模型中整体得分最高,超越更大规模的开源与专有系统。结果凸显 GUI-Libra 在不同难度级别与评估器类型下泛化能力,同时无需依赖多模块架构仍保持强劲性能。