Command Palette
Search for a command to run...
基于视觉信息增益的大规模视觉语言模型选择性训练
基于视觉信息增益的大规模视觉语言模型选择性训练
Seulbi Lee Sangheum Hwang
摘要
大规模视觉语言模型(Large Vision Language Models, LVLMs)虽已取得显著进展,但仍普遍存在语言偏见问题,即模型在回答时往往忽视视觉证据,仅依赖语言先验。尽管已有研究尝试通过解码策略、架构改进或精心设计的指令数据来缓解该问题,但这些方法通常缺乏对单个训练样本或词元(token)实际从图像中获益程度的定量衡量。为此,本文提出一种基于困惑度(perplexity)的度量指标——视觉信息增益(Visual Information Gain, VIG),用于量化视觉输入带来的预测不确定性降低程度。VIG能够在样本和词元两个层面实现细粒度分析,有效识别出具有视觉依据的关键元素,如颜色、空间关系及属性等。基于此,我们进一步提出一种VIG引导的择优训练策略,优先选择高VIG值的样本与词元进行训练。该方法显著增强了模型的视觉语境理解能力,缓解了语言偏见问题,并在大幅减少监督信号依赖的前提下,实现了更优的性能表现,其核心在于仅聚焦于具有视觉信息价值的样本与词元。
一句话总结
首尔科技大学的Seulbi Lee和Sangheum Hwang提出了一种基于困惑度的指标——视觉信息增益(VIG),用于量化每个token的图像贡献度,从而实现选择性训练,减少语言偏见并增强大型视觉语言模型(LVLMs)的视觉对齐能力,同时降低监督需求。
主要贡献
- 我们引入了视觉信息增益(VIG),一种基于困惑度的指标,用于量化视觉输入在多模态数据集中如何降低预测不确定性,从而在样本和token级别实现对视觉依赖性的细粒度分析。
- VIG可可靠识别颜色、空间关系和属性等视觉对齐元素,将其与依赖文本先验的token区分开,并与基准级模态依赖性对齐,验证其作为对齐指标的有效性。
- 借助VIG,我们设计了一种选择性训练方案,优先处理高VIG样本和token,在显著减少监督的情况下提升视觉对齐能力并减少语言偏见,同时实现更优性能。
引言
作者利用一种名为视觉信息增益(VIG)的新指标,量化视觉输入如何降低大型视觉语言模型(LVLMs)的预测不确定性,解决语言偏见这一长期存在的问题——即模型忽略图像而依赖文本先验。先前工作通过架构调整或解码技巧缓解该问题,但均未在样本或token级别衡量视觉依赖性,导致模型易出现幻觉且对齐能力弱。其主要贡献是VIG引导的选择性训练,优先处理视觉信息丰富的样本和token,提升对齐能力并减少监督需求,同时保持性能——提供了一种数据驱动、模型无关的解决方案,可与现有方法互补。

数据集
作者使用经过精心筛选的基准数据集和指令微调数据集来评估和训练模型。数据结构及应用方式如下:
-
评估基准(视觉理解):
- LLaVA-W(LLaVA-Bench In-the-Wild): 24张图像,60个问题,涵盖表情包、绘画、草图等多样化视觉内容。通过GPT-4(gpt-4o-2024-11-20)评估。
- MMVet: 200张图像,218个问题,含真实参考答案。使用GPT-4(gpt-4-0613)评估对话推理能力,采用精确度和效用评分。
- MMBench(英文子集): 约3000道多选题,涵盖20项技能。使用GPT-3.5(gpt-3.5-turbo-0613)提取答案选项(A–D)。报告开发集结果。
- DocVQA: 专注于文档图像理解(如表格、发票、报告)。在官方验证集上评估,报告准确率。
-
幻觉评估基准:
- POPE: 基于MSCOCO、A-OKVQA和GQA构建。从500张图像中提取27,000组问答对。通过50:50存在/不存在对象查询测试对象幻觉。使用三种负采样策略(随机、流行、对抗性);每张图像6个问题。指标:跨策略的准确率和F1平均值。
- CHAIR: 通过两个指标衡量标题幻觉:CHAIR_I(实例级幻觉比率)和CHAIR_S(句子级幻觉率)。提供两种指标的公式。
- MMHal: 来自OpenImages的96个挑战性查询。由GPT-4(gpt-4-0613)按0–5分评分。报告平均分和幻觉率(得分<3视为幻觉)。
-
指令微调数据:
- 对于LLaVA-1.5系列:使用Liu等人[2]的指令数据集。
- 对于ShareGPT4V变体:用ShareGPT4V[7]的高质量标题替换LLaVA中的“详细描述”样本。
- 选择阈值τ_p(在p=70时)按模型确定,列于表C.1中。
未提及裁剪或元数据构建。评估时直接使用原始数据集,而指令微调数据则按协议修改用于训练。
方法
作者采用标准大型视觉语言模型(LVLM)架构,包含三个核心组件:预训练视觉编码器Ev、适配器P和预训练语言模型D。训练分为两个阶段:预训练和指令微调。在预训练阶段,适配器P在大规模图像-标题对上优化,格式化为单轮指令。对于每张图像I及其标题,采样一个简单问题Q(如“描述此图像”),标题作为目标答案A。该阶段对齐视觉特征空间与语言模型的语义空间,同时保持Ev和D冻结。视觉特征及其投影嵌入分别计算为fv=Ev(I)和zv=P(fv)。模型对答案token的预测分布记为qθ(⋅∣a<t,Q,zv),参数为θ。每个样本的指令微调目标定义为:
L(A∣Q,I;θ)=−T1t=1∑Tlogqθ(at∣a<t,Q,zv)其中at是答案A的第t个token,T为序列长度。为方便表示,作者记qQ(⋅)=qθ(⋅∣Q)和qI,Q(⋅)=qθ(⋅∣I,Q),分别表示无视觉输入和有视觉输入时的预测。
为量化样本级别的视觉信息贡献,作者引入视觉信息增益(VIG),定义为有无视觉条件下的困惑度(PPL)对数比:
VIG=log(PPL(A∣Q,I)PPL(A∣Q))PPL(A∣Q)通过模糊图像计算,以模拟视觉线索缺失,遵循先前工作。更高的VIG表示提供视觉输入时模型不确定性降低更多。将VIG重新表述为交叉熵损失形式:
VIG=L(A∣Q)−L(A∣Q,I).在确定性监督下(如VQA和标题数据集),目标分布p为狄拉克δ函数,VIG简化为KL散度的绝对差:
VIG=DKL(pA∣Q∥qQ)−DKL(pA∣I,Q∥qI,Q).该公式表明,VIG经验性地衡量视觉信息在多大程度上减少模型预测与真实值之间的散度。进一步展开,VIG可分解为token级贡献:
VIG=T1t=1∑T[−logqθ(at∣a<t,Q)]−[−logqθ(at∣a<t,Q,zv)]每项表示有无视觉条件下的token级交叉熵损失,表明VIG聚合了每个token的视觉增益。该分解支持对哪些响应token最依赖视觉输入进行细粒度分析。
为展示VIG的实际效用,作者实施了VIG引导的选择性训练。对于每个训练样本(Ii,Qi,Ai),计算样本级VIG VIGi和token级VIG VIGi,t,其中:
VIGi=Ti1t=1∑TiVIGi,t.按VIGi对样本排序并选择前p%,定义选定集合Sp={i∣VIGi≥τp},其中τp为阈值。在此子集中,进一步使用相同阈值选择token:对于每个i∈Sp,视觉信息丰富的token为Ti+={t∣VIGi,t≥τp}。在指令微调期间,仅在⋃i∈SpTi+中的token上计算损失,确保梯度仅在最具视觉信息的区域更新。这种双重选择(样本级和token级)将优化聚焦于具有显著视觉对齐的数据,提高视觉推理效率。
实验
- VIG有效衡量样本和token级别的视觉对齐,与基准特性一致:COCO和POPE显示强视觉依赖,而GQA和SQA倾向于文本依赖。
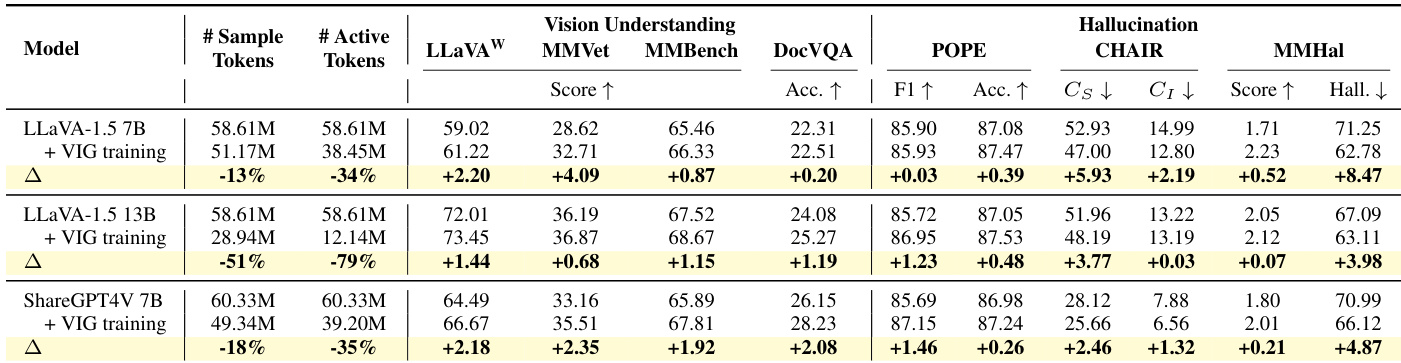
- VIG引导的选择性训练在视觉理解和幻觉基准上提升性能,同时减少高达70%的训练数据,token级过滤被证明对提升至关重要。
- 更大模型从VIG选择中受益更多,在更少token下实现更高性能,展示改进的数据效率。
- VIG训练增强模型各层的视觉注意力,减少“盲目信任文本”,使模型对误导性文本线索更具鲁棒性。
- VIG在不改变架构的情况下优于或匹配现有视觉对齐方法,并可与它们结合以获得叠加增益。
- 消融研究确认,基于VIG的选择(样本+token级)始终优于随机或仅样本级选择,p=70在效率和性能间取得最佳平衡。
- 定性结果显示,VIG训练抑制对象和属性幻觉,迫使模型基于实际视觉内容而非文本先验生成响应。
作者使用VIG引导的选择性训练,根据视觉信息增益过滤样本和token,在视觉理解和幻觉基准上实现性能提升,同时减少训练数据量。结果表明,采用此方法训练的模型更关注视觉token,抵抗误导性文本线索,表明更强的视觉对齐能力。该方法始终优于随机数据缩减,并在不改变架构的情况下补充现有视觉对齐方法。

作者使用VIG引导的选择性训练,根据视觉信息增益过滤样本和token,在显著减少训练token的情况下实现性能提升。结果表明,采用此策略训练的模型表现出更强的视觉对齐能力、更少的幻觉和对误导性文本更强的抵抗力,即使仅使用70%的原始数据。该方法始终优于随机数据缩减,并在不改变架构的情况下补充现有视觉对齐技术。

作者使用VIG引导的选择性训练,在指令微调期间优先处理视觉对齐的样本和token,在视觉理解和幻觉基准上实现性能提升,同时将活跃token数量减少34%至79%。结果表明,这种数据驱动方法在不改变架构的情况下增强视觉对齐能力,优于随机数据缩减和现有无训练或基于训练的方法。增益在不同模型规模和架构中一致,表明将监督聚焦于视觉信息丰富的内容可强化多模态对齐并减少对虚假文本线索的依赖。
作者在所有模型的预训练和指令微调阶段使用相同的训练配置,保持学习率、优化器和调度器等超参数一致,以确保公平比较。结果表明,尽管使用较小的批量大小,指令微调所需训练时间仍少于预训练,显示微调阶段的计算效率。

作者使用VIG引导的选择性训练,优先处理视觉信息丰富的样本和token,在视觉理解和幻觉基准上实现更强性能,同时使用显著更少的训练token。结果表明,即使激进过滤(30%选择)在开放式和幻觉任务上仍保持或提升性能,而覆盖范围更广的任务受益于适度过滤(70%)。该方法始终减少对虚假文本线索的依赖,增强视觉对齐能力,无需改变架构。
