Command Palette
Search for a command to run...
MobilityBench:面向真实世界出行场景中路径规划Agent的评估基准
MobilityBench:面向真实世界出行场景中路径规划Agent的评估基准
Zhiheng Song Jingshuai Zhang Chuan Qin Chao Wang Chao Chen Longfei Xu Kaikui Liu Xiangxiang Chu Hengshu Zhu
摘要
基于大语言模型(LLM)的路径规划智能体作为一种新兴范式,通过自然语言交互与工具协同决策,展现出支持日常人类出行的广阔前景。然而,在真实出行场景中开展系统性评估仍面临诸多挑战,包括多样化的路径规划需求、地图服务的非确定性响应,以及实验结果可复现性不足等问题。为此,本研究提出 MobilityBench——一个可扩展的真实出行场景下LLM路径规划智能体评估基准。MobilityBench基于大规模、匿名化的真实用户查询数据构建,数据来源于高德地图(Amap),覆盖全球多个城市,涵盖广泛的路径规划意图类型。为实现可复现的端到端评估,我们设计了一个确定性的API回放沙箱环境,有效消除了实时服务带来的环境波动。此外,我们提出了一套多维度评估协议,以结果有效性为核心,辅以对指令理解、规划能力、工具使用及执行效率等方面的综合评估。借助MobilityBench,我们在多种真实出行场景中对多个基于LLM的路径规划智能体进行了全面评估,并深入分析了其行为特征与性能表现。研究结果表明,当前模型在基础信息检索与常规路径规划任务上表现良好,但在偏好约束型路径规划任务中面临显著挑战,凸显了个性化出行应用中仍有巨大的优化空间。我们已将该基准数据集、评估工具包及完整文档公开发布,详见:https://github.com/AMAP-ML/MobilityBench。
一句话总结
来自中国科学院计算机网络信息中心(CNIC)、中国科学院及阿里巴巴集团高德地图的研究人员推出了 MobilityBench,这是一个基于真实高德地图查询、可扩展且可复现的基准测试平台,用于评估基于大语言模型的路径规划智能体。结果显示,当前模型在基础任务上表现良好,但在偏好约束的个性化路径规划方面仍存在明显差距。
主要贡献
- MobilityBench 引入了一个可扩展、基于真实世界数据的基准测试,用于评估基于大语言模型的路径规划智能体。该基准基于来自全球 350 多个城市的匿名用户查询构建,涵盖多途经点路线、多模态交通和偏好感知导航等多样化意图。
- 为确保可复现性,该基准采用确定性的 API 回放沙箱,缓存并重放地图服务响应,消除了实时交通和系统更新在评估过程中引入的环境波动。
- 评估协议结合了结果有效性与指令理解、规划能力、工具使用和效率的评估,揭示当前模型在基础任务上表现良好,但在偏好约束路径规划上仍存在困难,凸显了个性化出行支持方面的关键差距。
引言
作者利用大语言模型构建路径规划智能体,以自然语言和 API 交互方式处理复杂、真实世界的出行请求。此前的基准测试因聚焦高层级行程规划而非基于真实地图数据的细粒度、约束丰富的导航任务而存在不足,且依赖非确定性实时 API,导致难以复现。MobilityBench 通过引入基于 350 多个城市匿名高德用户查询构建的可扩展真实世界基准,并结合确定性 API 回放沙箱,确保评估一致性。其多维评估协议不仅评估结果有效性,还涵盖指令理解、规划、工具使用和效率——揭示当前模型在基础任务上表现良好,但在偏好约束路径规划上表现不佳,指明了未来研究的关键方向。该基准、工具包和数据已公开发布,以支持可复现、可扩展的研究。
数据集

- 作者使用 MobilityBench——一个基于从高德地图六个月收集的 10 万条匿名出行查询构建的可扩展基准——在真实世界场景中评估路径规划智能体。
- 每个 episode 是一个四元组:(x, z, S, y),其中 x 是自然语言查询,z 提供用户位置等上下文,S 是可回放的 API 快照,y 是仅用于评估的结构化真实标注。
- 查询基于语音输入转录为文本,并经过过滤以去除格式错误或模糊请求;近似重复项被去重,以确保多样性。
- 任务分类体系使用 Qwen-4B 进行意图分类,通过开放集标注扩展,并由专家细化为 11 种场景,归为 4 大类:基础信息检索、路径依赖信息检索、基础路径规划和偏好约束路径规划。
- 真实标注 (y) 通过专家定义的标准操作程序构建,实现为可执行工具程序,用于提取槽位、解析位置并调用路线/天气/交通工具;输出经过验证并存档用于评估。
- 所有工具交互均通过确定性回放沙箱运行,缓存高德 API 响应;未匹配的调用采用模糊匹配或空间最近邻查找等回退策略,并严格进行模式验证。
- 数据集覆盖 22 个国家和 350 多个城市,任务分布为:36.6% 基础信息检索,9.6% 路径依赖信息检索,42.5% 基础路径规划,11.3% 偏好约束路径规划。
- episodes 经过筛选,仅保留结果可验证、可执行的案例;智能体无法看到真实标注,也不能请求澄清,确保查询自包含且可解。
实验
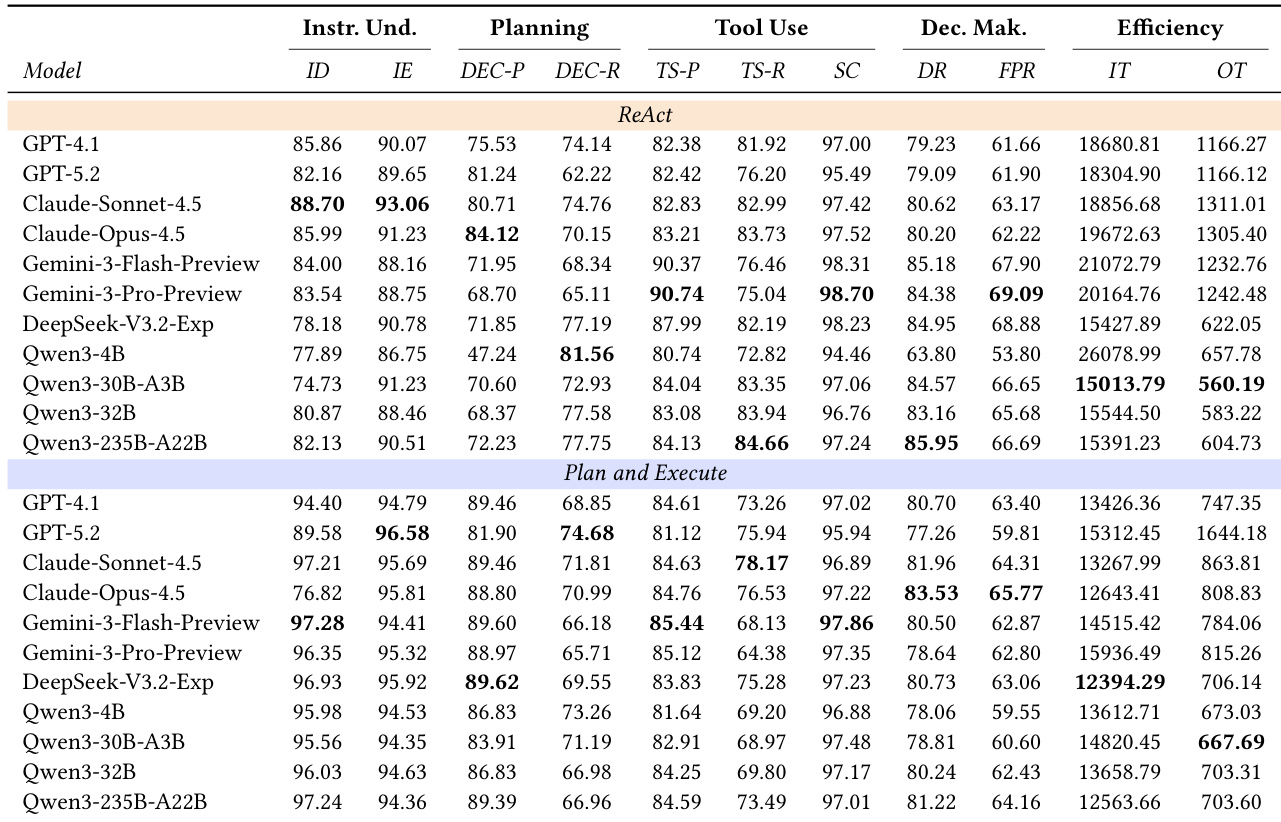
- 引入多维评估协议,将路径规划智能体分解为四个核心能力:指令理解、规划、工具使用和决策,实现超越端到端成功率的细粒度诊断。
- 在 7,098 个真实世界出行 episode 上评估了多种大语言模型(开源和闭源),采用 ReAct 和 Plan-and-Execute 两种框架。
- Claude-Opus-4.5 和 Gemini-3-Pro-Preview 在整体表现上领先;开源模型如 Qwen3-235B-A22B 和 DeepSeek-V3.2-Exp 表现出强劲竞争力,尤其在成本效率方面。
- ReAct 因其动态反馈循环在任务成功率上优于 Plan-and-Execute,但输入 token 使用量高出约 35%,增加计算成本。
- Plan-and-Execute 在偏好约束、逻辑密集型场景中表现更优,因其强制预先规划,减少偏离和幻觉。
- 更大的模型持续提升性能,符合缩放定律;MoE 架构带来显著增益;更大模型也生成更长、更详尽的计划。
- 启用“思考”模式提升各模型最终通过率(Qwen-30B-A3B 最高提升 +6%),但显著增加 token 输出量和延迟,限制了实时部署可行性。
作者采用多维评估协议,从指令理解、规划、工具使用、决策和效率等方面评估路径规划智能体,结果显示闭源模型如 Claude-Opus-4.5 和 Gemini-3-Pro-Preview 在任务成功率上普遍领先,而大型开源模型如 Qwen3-235B-A22B 在较低计算成本下表现具有竞争力。结果表明,ReAct 框架因其动态反馈循环实现更高最终通过率,但 token 使用量显著更高;Plan-and-Execute 在效率上更优,但在复杂场景中鲁棒性降低。模型规模和推理模式均能提升性能,更大模型和启用思考模式可提高成功率,但以增加延迟和资源消耗为代价。