Command Palette
Search for a command to run...
TOPReward:作为机器人学中隐藏零样本奖励的Token概率
TOPReward:作为机器人学中隐藏零样本奖励的Token概率
Shirui Chen Cole Harrison Ying-Chun Lee Angela Jin Yang Zhongzheng Ren Lillian J. Ratliff Jiafei Duan Dieter Fox Ranjay Krishna
摘要
尽管视觉-语言-动作(Vision-Language-Action, VLA)模型在预训练阶段取得了快速进展,但在强化学习(Reinforcement Learning, RL)中的应用仍受限于现实场景下样本效率低和奖励稀疏的问题。构建具备泛化能力的进程奖励模型,对于提供细粒度反馈以弥合这一差距至关重要。然而,现有时间价值函数往往难以超越其训练域进行有效泛化。为此,我们提出TOPReward——一种基于概率原理的新颖时间价值函数,该方法利用预训练视频视觉-语言模型(Vision-Language Models, VLMs)所蕴含的潜在世界知识,来估计机器人任务的执行进度。与以往通过提示(prompting)VLM直接输出进度值的方法不同,后者容易因数值表征偏差而产生误差,TOPReward则直接从VLM内部的token logits中提取任务进度信息,从而实现更准确、鲁棒的估计。在超过130项不同现实任务及多种机器人平台(如Franka、YAM、SO-100/101)的零样本评估中,TOPReward在Qwen3-VL模型上实现了0.947的平均值序相关性(Value-Order Correlation, VOC),显著优于当前最先进的GVL基线方法——后者在同一开源模型上表现接近零相关性。此外,我们进一步验证了TOPReward在下游任务中的广泛适用性,包括任务成功检测与奖励对齐的行为克隆(reward-aligned behavior cloning),展现出其作为通用工具的强大潜力。
一句话总结
来自华盛顿大学和英伟达的研究人员提出了 TOPReward,这是一种利用预训练视觉语言模型(VLM)的 token logits 来估计机器人任务进展的概率时序价值函数,克服了以往数值表示不准确的问题,在 130 多项真实世界任务上实现了 0.947 的 VOC,支持零样本奖励建模和行为克隆。
主要贡献
- TOPReward 引入了一种零样本、基于概率的方法,通过提取预训练视频 VLM 的内部 token logits 来估计机器人任务进展,绕过不可靠的基于文本的数值输出,无需微调即可在真实世界任务中实现泛化。
- 在 ManiRewardBench 上评估——该基准涵盖 Franka、YAM 和 SO-100/101 平台上的 130 多项真实世界任务——TOPReward 在 Qwen3-VL 上实现了 0.947 的平均值序相关性,远超 GVL,后者在相同的开源模型上相关性接近零。
- TOPReward 支持下游强化学习和模仿学习应用,包括成功检测和优势加权行为克隆,在无需任务特定演示或额外训练的情况下提高了真实世界任务的成功率(例如,10/10 对比基线 7/10)。
引言
作者利用预训练的视频视觉语言模型(VLM)为机器人生成零样本奖励信号,解决了现实强化学习中稀疏、手工设计奖励的关键瓶颈。以往方法要么需要昂贵的任务特定微调,要么无法在机器人平台和开源模型间泛化,尤其是依赖自回归文本生成进行进展估计时——这种方法存在数值不稳定问题。TOPReward 的核心创新是完全绕过文本输出:它通过提出二元完成查询并测量模型在“yes”token 上随时间变化的置信度,直接从 VLM 的内部 token logits 中提取任务进展。这产生了一个密集且校准良好的进展信号,可泛化到 130 多项真实世界任务和多种机器人形态,支持如成功检测和奖励对齐行为克隆等应用,无需任何额外训练。
数据集
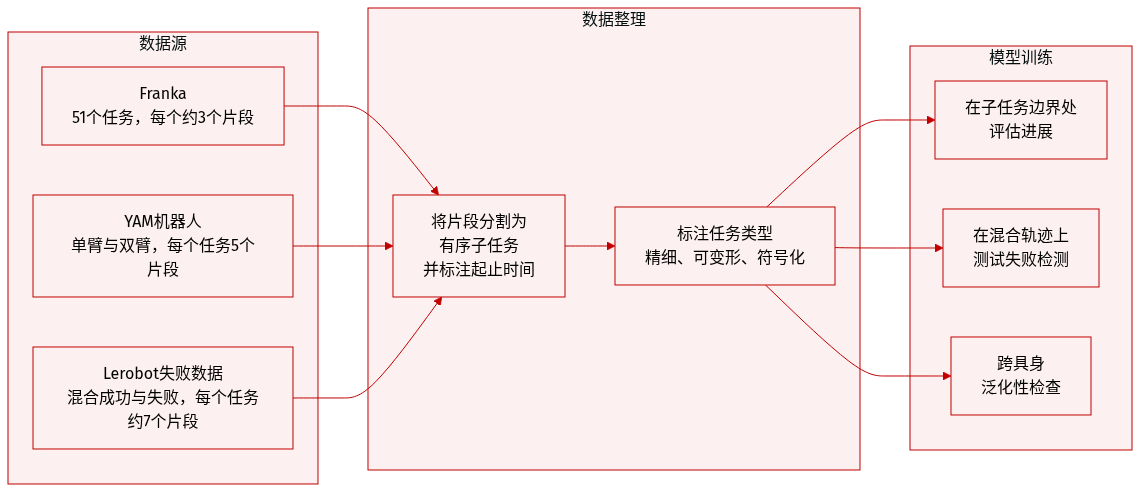
作者使用 ManiRewardBench,这是一个旨在评估真实机器人操作中奖励模型的基准,涵盖四个机器人平台上的 130 项多样化任务:Franka、SO-100/101、单臂 YAM 和双臂 YAM。该数据集支持评估进展敏感性、完成检测和跨形态鲁棒性。
关键子集及其详情:
- Franka 数据集:51 项基于指令的任务(如旋转、清洁、抓取放置),每项任务通常包含 3 个片段。
- 双臂 YAM 数据集:每项任务 5 个片段,涵盖折叠、堆叠、搭建和打开任务。
- 单臂 YAM 数据集:每项任务 5 个片段,聚焦于放置、移除和堆叠动作。
- Lerobot 双臂:成功演示(推、放、移除、堆叠),每项任务 5–10 个片段。
- Lerobot 失败:混合成功与失败轨迹,每项任务约 7 个片段,用于测试成功检测。
- 失败轨迹子集:23 项任务共 156 个片段,包含成功与失败尝试。
处理与标注:
- 每个片段被手动分割为有序、无重叠的子任务(如“抓取物体”、“放置物体”),并标注精确的起止时间戳。
- 子任务标注支持阶段感知评估,允许模型在细粒度进展理解上进行测试,而非简单的成功/失败二元判断。
- 任务涵盖精细操作(如精确角度旋转物体)、可变形物体处理(如折叠毛巾)和符号任务(如按顺序按压键盘按键)。
在本文中的用途:
- 该基准用于评估奖励模型检测进展、处理失败及跨机器人形态泛化的能力。
- 底层数据受限,防止泄漏;仅通过受控评估协议授予访问权限。
- 未指定训练集划分或混合比例——该数据集仅用于评估。
方法
作者利用视觉语言模型(VLM)通过解释模型内部 token 概率作为任务完成可能性的代理,推导出时序密集的奖励信号。核心机制称为 TOPReward,通过将 VLM 条件化在轨迹-指令对上,并查询 token “True” 的对数概率作为标量奖励来运行。这种方法避免依赖指令遵循或数值生成能力,而是将奖励计算扎根于 VLM 的预训练下一个 token 预测目标。
参考框架图:系统输入截至时间 t 的视频帧序列,编码为视频 token,并与一个固定文本提示结合,将任务框架化为二元判断。提示结构为:“video 上述视频展示了一个机器人操作轨迹,完成以下任务:{INSTRUCTION}。判断上述陈述是否为真。答案是:{a}”。VLM 随后计算 rt=logpθ(a=True∣c(τ1:t,u)),其中 c(τ1:t,u) 表示视频条件文本上下文。随着轨迹展开,累积的视觉证据增加“True”的可能性,从而产生随时间单调递增的奖励信号。
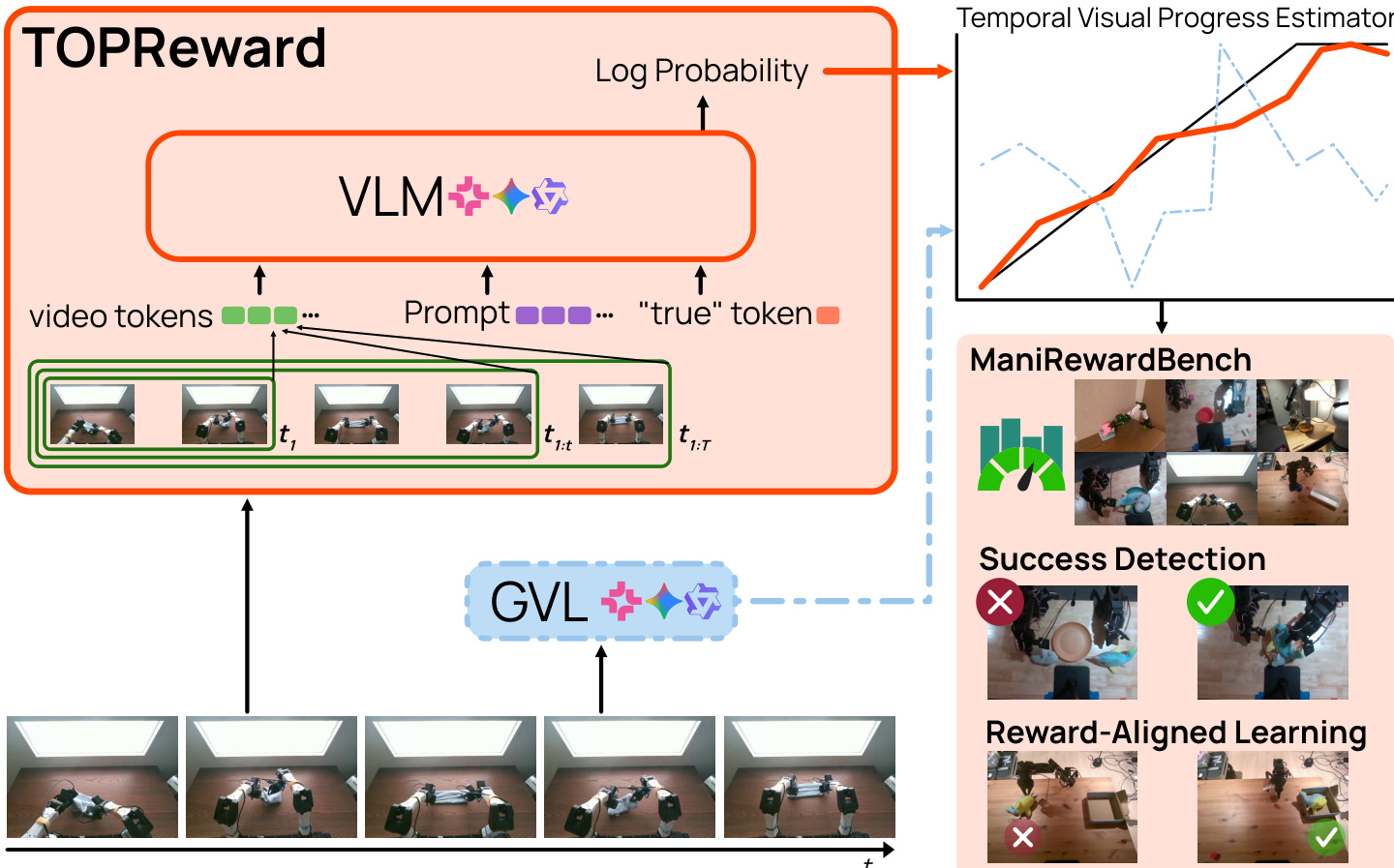
为构建时间进展曲线,作者对 K 个均匀分布的轨迹前缀 {tk}k=1K 进行采样,并计算相应的奖励 {rtk}。这些奖励随后通过最小-最大缩放归一化,生成每个片段内的进展得分 stk∈[0,1]:
stk=maxjrtj−minjrtj+εrtk−minjrtj,其中 ε 确保数值稳定性。此归一化得分支持在单个轨迹内各时间步上一致解释进展。
对于需要每步奖励的应用——如奖励对齐行为克隆——作者从进展增量中推导出密集奖励信号:
Δtk=clip(τ⋅exp(stk−stk−1),min=0,max=δmax),其中 τ 调节正负进展之间的相对权重,δmax 限制最大奖励以防止过度强调高幅度转换。此公式确保奖励信号平滑、可解释且可操作,与任务完成的时间演化一致。
实验
- TOPReward 在大规模机器人数据集(OXE 和 ManiRewardBench)上出色地实现了零样本进展估计,通过利用 logits 概率而非结构化数值输出,在 Qwen3-VL-8B 和 Molmo2-8B 等开源 VLM 上显著优于 GVL。
- 它能有效检测失败轨迹中的任务成功,而基于 VOC 的方法因对排序不敏感而失败;TOPReward 的概率评分在开源模型上实现了更高的 ROC-AUC。
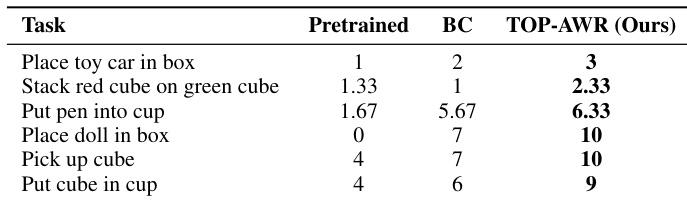
- 在真实部署中,TOPReward 通过优势加权行为克隆改善策略学习,在六项操作任务中持续超越标准模仿学习。
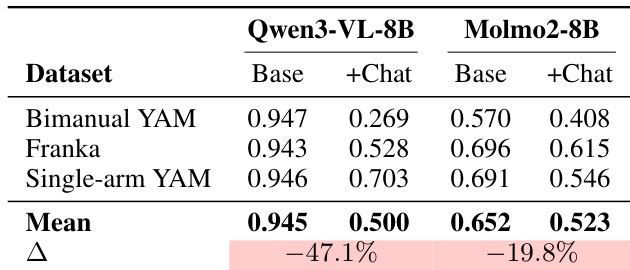
- 消融研究表明,强制聊天模板会降低性能,证实对提示格式的敏感性,尤其对开源模型。
- 总体而言,TOPReward 通过重用预训练 VLM 的内部概率估计提供稳健的零样本进展信号,无需微调即可实现可靠的任务监控和策略改进。
作者使用 TOPReward 在多个机器人数据集上评估零样本进展估计,发现它在 Qwen3-VL-8B 和 Molmo2-8B 等开源模型上持续优于 GVL,尤其在 ManiRewardBench 上实现了接近完美的 VOC 分数。结果表明,TOPReward 的基于 logits 的方法比 GVL 的文本生成方法更好地利用了预训练视频理解能力,后者在校准上存在困难且无法区分成功与失败轨迹。在专有 Gemini-2.5-Pro 上,由于强制聊天模板,性能反转,突显了基于 logits 的方法对提示格式的敏感性。
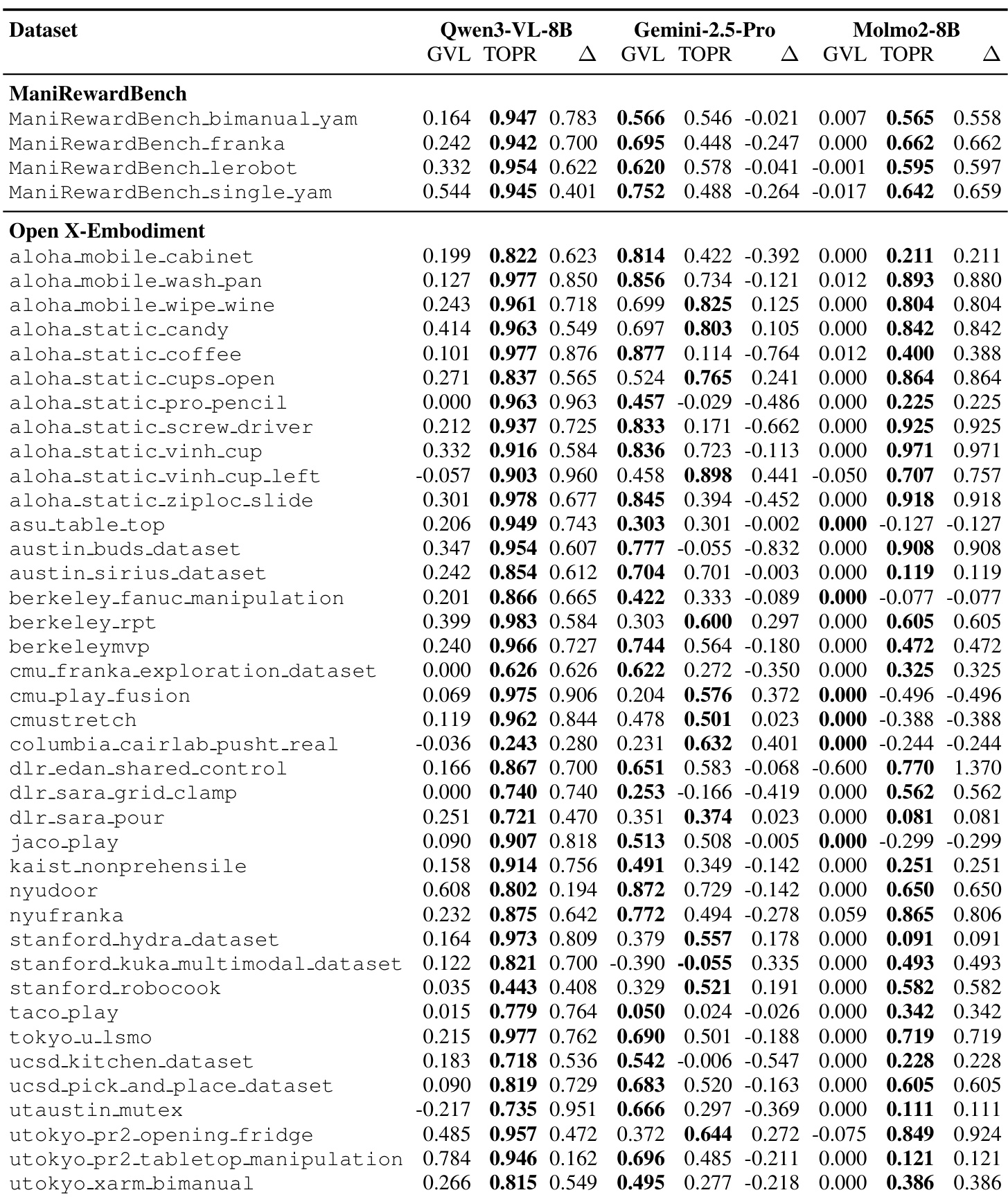
作者使用 TOPReward 通过利用视频语言模型的 token 概率估计机器人任务进展,在开源模型上实现了显著高于 GVL 基线的值序相关性。结果表明,TOPReward 在 Qwen3-VL-8B 和 Molmo2-8B 上持续优于 GVL,而在 Gemini-2.5-Pro 上表现较差,这是由于强制聊天模板的约束。这突显了基于 logits 的方法在开源 VLM 中有效解锁隐式进展估计,而结构化数值生成失败。

结果表明,TOPReward 在 Qwen3-VL-8B 模型上优于 GVL,实现了更高的成功检测 ROC-AUC,而两种方法在 Gemini-2.5-Pro 上表现相当。这表明,TOPReward 的概率方法在识别成功轨迹方面比基于 VOC 的方法更有效,尤其是在使用开源视频语言模型时。

作者评估了聊天模板如何影响 TOPReward 在不同视频语言模型上的性能,发现强制聊天格式显著降低了进展估计的准确性。在 Qwen3-VL-8B 上,使用聊天模板时平均 VOC 下降了 47.1%,而 Molmo2-8B 下降了 19.8%,表明基于 logits 的方法对提示结构高度敏感。这些结果证实提示工程直接影响从 VLM token 概率派生的零样本进展信号的可靠性。
作者使用 TOPReward 为真实机器人任务中的行为克隆计算优势权重,显示在六项操作任务中持续优于标准行为克隆。结果表明,TOP-AWR 微调提高了任务完成率,部分成功分数通常为基线的两到三倍。这证明从 token 概率派生的进展信号能有效指导策略改进,无需任务特定训练。