Command Palette
Search for a command to run...
VLANeXt:构建强大VLA模型的配方
VLANeXt:构建强大VLA模型的配方
Xiao-Ming Wu Bin Fan Kang Liao Jian-Jian Jiang Runze Yang Yihang Luo Zhonghua Wu Wei-Shi Zheng Chen Change Loy
摘要
随着大规模基础模型的兴起,视觉-语言-动作模型(Vision-Language-Action models, VLAs)应运而生,其利用强大的视觉与语言理解能力,实现通用型策略学习。然而,当前VLAs的研究格局仍呈现碎片化与探索性特征。尽管多个研究团队提出了各自的VLAs模型,但由于训练协议与评估设置缺乏统一标准,导致难以判断哪些设计选择真正具有关键影响。为厘清这一快速演进的研究领域,本文在统一框架与评估体系下,重新审视VLAs的设计空间。基于一个类似于RT-2和OpenVLA的简单VLA基线模型,我们系统性地从三个维度剖析关键设计选择:基础组件、感知核心要素以及动作建模视角。通过此项研究,我们提炼出12项关键发现,共同构成构建高性能VLAs的实用指导原则。基于此探索,我们提出了一种结构简洁但效果显著的新模型——VLANeXt。该模型在LIBERO与LIBERO-plus基准测试中均超越了此前的最先进方法,并在真实场景实验中展现出优异的泛化能力。为促进社区协作,我们将开源一个统一且易于使用的代码库,作为共享平台,供研究者复现本研究结果、探索设计空间,并在此共同基础之上开发新型VLAs变体。
一句话总结
来自多个机构的研究人员提出了 VLANeXt,这是一种精简的 VLA 模型,系统性评估了组件、感知和动作建模中的设计选择,在 LIBERO 基准测试中超越先前方法,并通过统一的开源代码库支持现实世界泛化,推动社区驱动的 VLA 开发。
主要贡献
- 本文通过引入统一评估框架并系统分析基础组件、感知和动作建模中的设计选择,应对碎片化的 VLA 领域,提炼出 12 条实用发现,形成可复现的 VLA 开发配方。
- 提出 VLANeXt,一种轻量级模型,基于上述见解构建,在不依赖大规模模型扩展的情况下,在 LIBERO 和 LIBERO-plus 基准测试中超越先前最先进方法,证明有原则的设计选择可带来强大性能。
- VLANeXt 在现实世界操作任务中表现出稳健泛化能力,并由公开发布的模块化代码库支持,使社区可在标准化协议下探索和复现设计决策。
引言
作者利用不断发展的视觉-语言-动作(VLA)模型领域,这些模型使用大型视觉-语言基础模型,直接将视觉和语言输入映射为机器人动作——实现无需任务特定训练的可扩展、通用机器人控制。先前工作已产生许多 VLA 变体,但不一致的训练协议和评估设置使难以隔离哪些设计选择真正提升性能。作者通过在统一框架下系统探索 VLA 设计空间,评估基础组件、感知输入和动作建模策略来解决此问题。其核心贡献是 VLANeXt,一种基于 12 条提炼设计原则构建的轻量模型,在 LIBERO 和 LIBERO-plus 基准测试中超越更大先前模型,并在现实任务中泛化良好——表明有原则的架构选择比规模或临时工程更重要。他们还发布了一个开放、模块化的代码库,以标准化未来的 VLA 研究。
方法
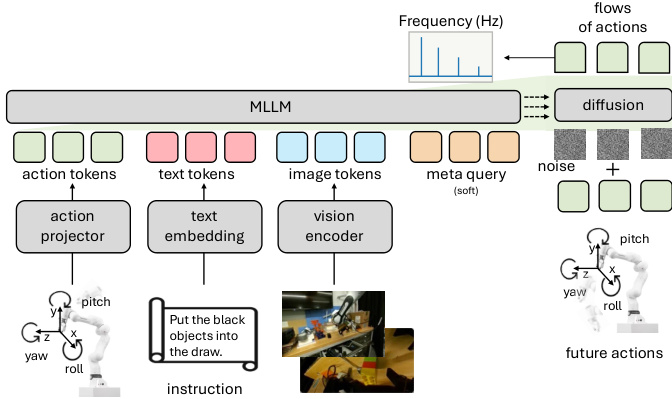
作者利用系统消融框架将基线 VLA 模型演进为 VLANeXt,聚焦三个核心维度:基础组件、感知要素和动作建模。整体架构结合多模态 LLM 主干与专用策略模块,以视觉、文本和本体感觉输入为条件,并通过连续动作建模和辅助目标优化。
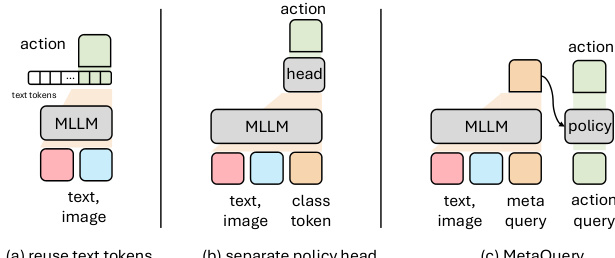
基础设计始于受 RT-2 和 OpenVLA 启发的基线,使用 LLaMA 作为语言主干,SigLIP2 作为视觉编码器。动作预测最初通过重用文本标记处理,但作者发现引入显式策略头——由附加到多模态嵌入的类标记驱动——可带来适度提升。请参考策略模块设计框架图,该图对比了标记重用、独立策略头和 MetaQuery 风格的多标记策略模块。最终架构采用 12 层策略网络与 16 个查询标记,通过将动作预测与语言标记空间解耦显著提升性能。
动作建模通过分块和损失函数选择优化。模型不逐步预测动作,而是预测长度为 8 的动作块,提高时间一致性。作者评估了这些连续动作向量的多个学习目标:基于分箱的分类、直接回归、扩散(DDIM)、流匹配和 VQ-VAE 码本分类。回归和流匹配优于分类,流匹配因其对多模态分布的鲁棒性被选中。动作块建模为形状 (t,dim) 的连续向量,归一化至 [−1,1] 并离散化为 256 个分箱用于基线比较,但最终模型使用流匹配进行直接连续预测。
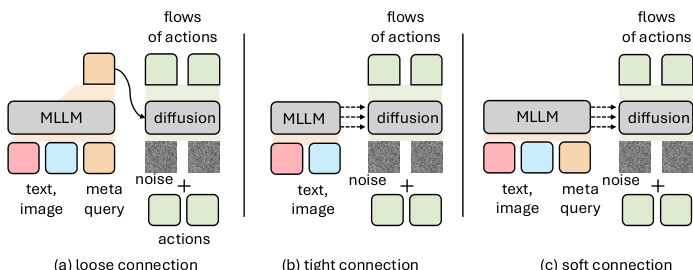
VLM 主干从 LLaMA-3.2-3B 升级至 Qwen3-VL-2B,提供强大的性能-效率权衡。VLM 与策略模块之间的连接也经过优化:“软”策略在模块间插入可学习的元查询作为潜在缓冲区,支持层间交互,优于“松散”(完全解耦)和“紧密”(直接层间)连接。如下图所示,这种软连接通过在感知和动作模块间引入潜在推理空间促进更有效的表征传递。
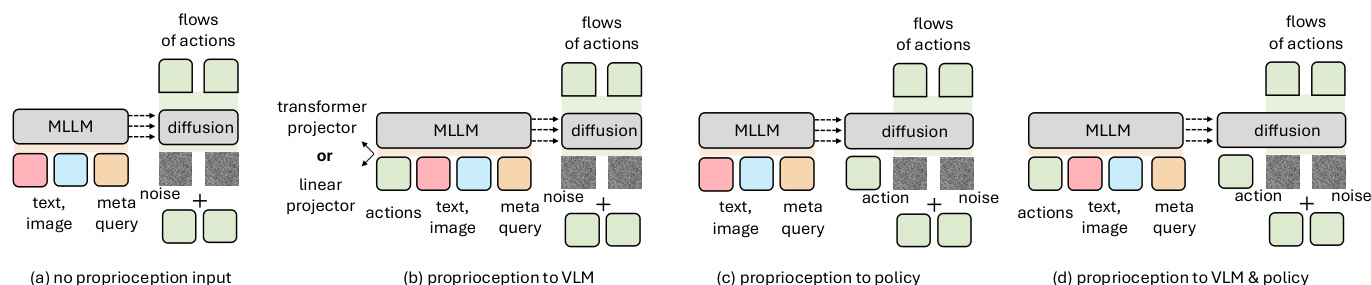
在感知方面,模型结合多视角视觉输入(第三人称和腕部相机),并在 VLM 或策略模块中条件化本体感觉。作者发现,在两个阶段条件化本体感觉表现最佳,如本体感觉条件化图所示。冗余的时间观察历史被认为不必要,简化了输入管道。
为进一步增强动作生成,作者引入两个辅助目标。世界建模——使用 Emu3.5 分词器预测未来图像标记——提升性能但使训练成本增加三倍,因此未纳入最终配方。相反,采用轻量级频域辅助损失:对动作块应用离散余弦变换,模型最小化预测与真实频域系数之间的 MSE,权重为流匹配损失的 0.1–0.2。这利用了机器人动作序列的低秩、结构化特性。
最终 VLANeXt 架构整合所有组件:多视角视觉输入、语言指令和本体感觉由 Qwen3-VL-2B 主干分词和处理;元查询实现与 12 层策略模块的软交互;动作块通过流匹配预测;频域损失提供额外正则化。完整系统如架构图所示,还突出显示了频域目标和机器人 6 自由度动作空间(偏航、俯仰、滚转、x、y、z)。
实验
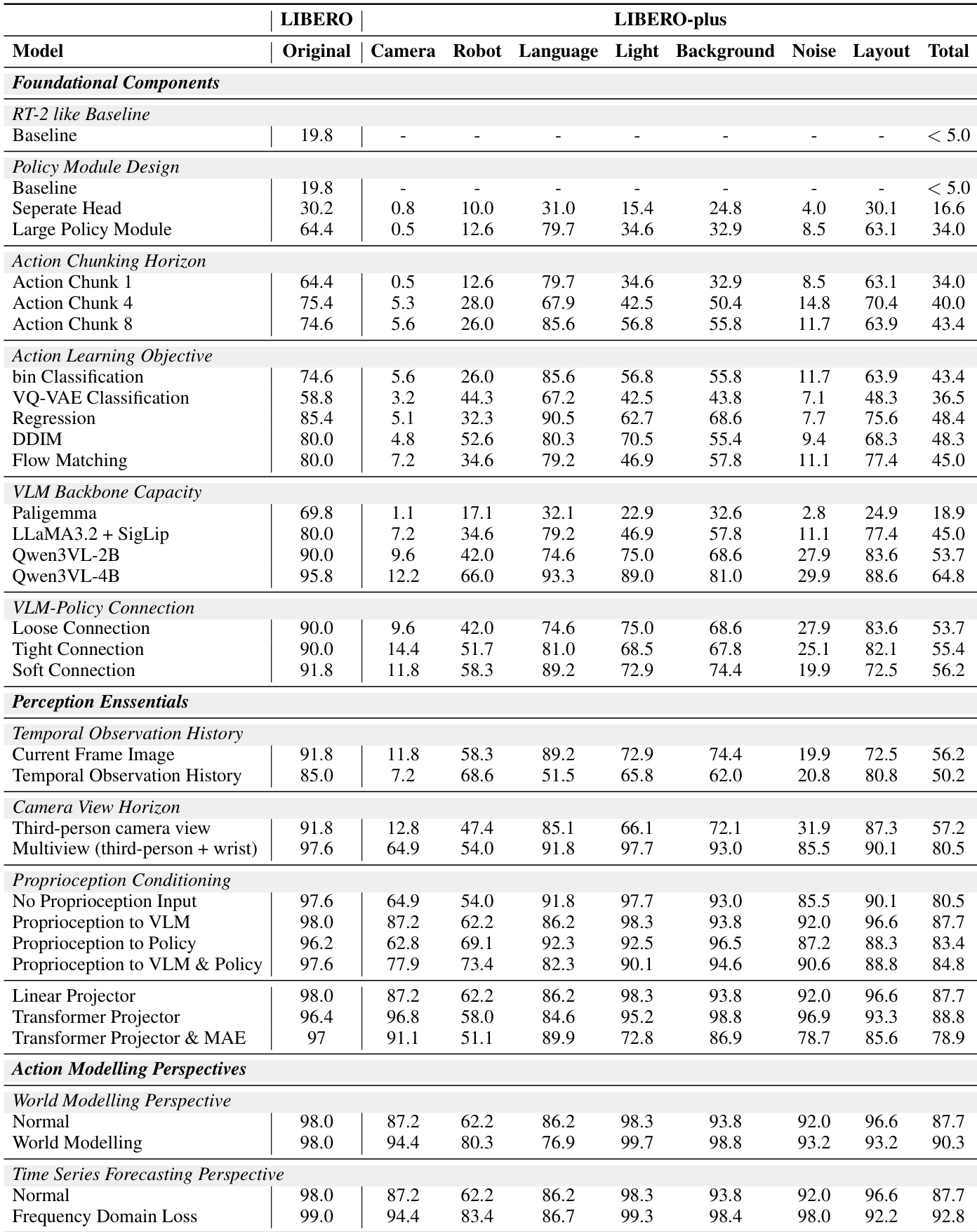
- 添加时间观察历史未提升性能,可能引入噪声,表明当前帧输入足以生成动作。
- 多视角相机输入(第三人称加腕部相机)通过互补视觉线索解决空间歧义,显著提升性能。
- 在 VLM 层级条件化本体感觉优于在策略层级或不使用,实现与视觉和语言输入的更好融合。
- 基于 Transformer 的本体感觉投影器相比线性投影仅提供边际增益,但为简化保留线性投影。
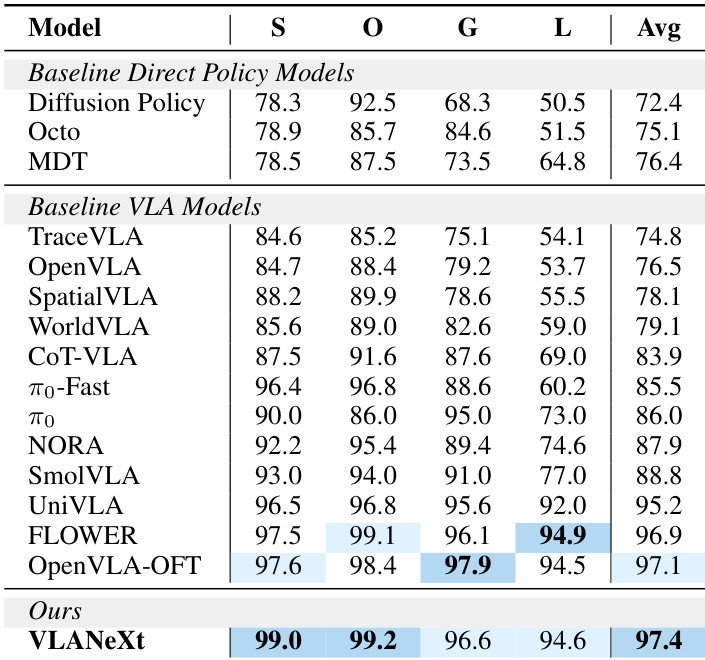
- VLANeXt 在标准 LIBERO 基准测试中达到最先进结果,优于直接策略学习和先前 VLA 方法。
- 在具有未见视觉、物理和语义扰动的挑战性 LIBERO-plus 基准测试中,VLANeXt 表现出强大泛化能力,成功率比 OpenVLA-OFT 提高 10%。
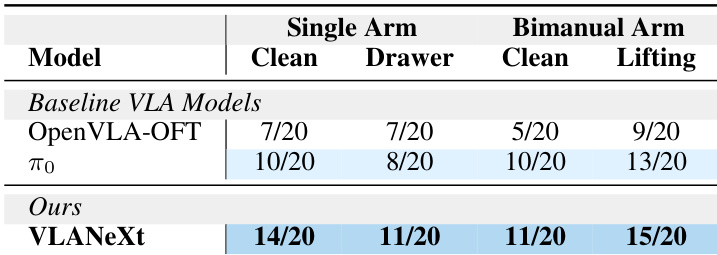
- 在单臂和双臂任务的现实世界评估中,VLANeXt 表现稳健,即使在无双臂训练情况下也能适应双臂任务,展示跨具身灵活性。
作者在 LIBERO-plus 基准测试中评估其 VLANeXt 模型,该测试在视觉、物理和语义维度引入多样化扰动。结果表明 VLANeXt 在几乎所有扰动类型中优于先前 VLA 模型(包括 OpenVLA-OFT),并取得最高平均成功率,表明在未见条件下更强的泛化能力。模型的一致增益表明其设计选择有效增强对现实世界变化的鲁棒性。
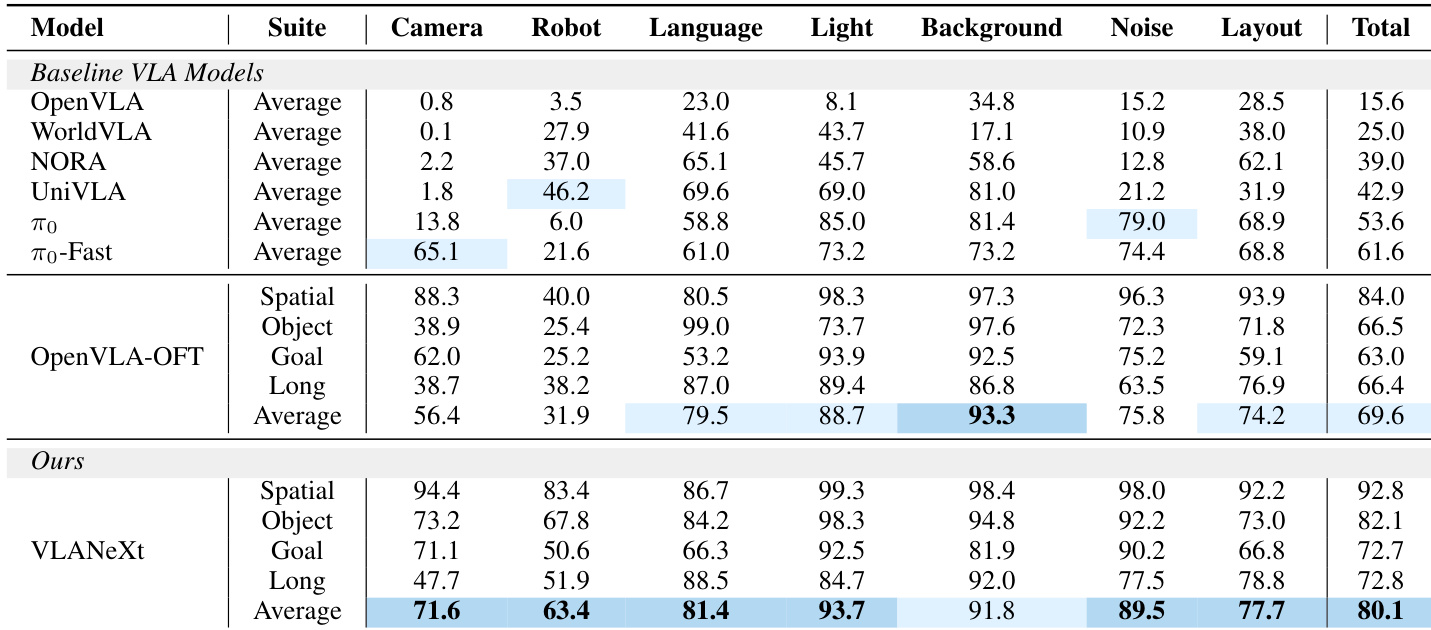
作者评估了视觉-语言-动作模型的多种设计选择,发现多视角相机输入和在 VLM 层级条件化本体感觉带来最强性能增益,而添加时间观察历史无益且可能降低结果。其最终模型在标准和扰动基准测试中均达到最先进成功率,展示在视觉、物理和语义变化下的稳健泛化能力。现实世界评估进一步证实模型在单臂和双臂任务中的有效性和适应性。
作者在现实世界机器人任务中评估 VLANeXt 与基线 VLA 模型,包括单臂和双臂设置。结果表明 VLANeXt 在所有任务中持续优于基线,即使在双臂场景中也取得更高成功率,尽管仅在单臂数据上预训练。这表明模型对新具身和现实条件的强大适应性。
作者在 LIBERO 基准测试中评估 VLANeXt 与多种直接策略和 VLA 基线,显示其在所有任务类别中达到最先进性能。结果表明其设计选择显著提升成功率,尤其在物体和目标导向任务中,明显优于先前方法。模型的强平均性能表明视觉、语言和动作输入的有效整合,实现可泛化的机器人策略学习。