Command Palette
Search for a command to run...
OmniGAIA:迈向原生全模态AI智能体
OmniGAIA:迈向原生全模态AI智能体
摘要
人类智能天然地将多模态感知(涵盖视觉、听觉与语言)与复杂的推理能力及工具使用相结合,从而与世界进行交互。然而,当前的多模态大语言模型(LLM)主要局限于双模态交互(如视觉-语言),缺乏实现通用人工智能助手所必需的统一认知能力。为弥合这一差距,我们提出 OmniGAIA——一个全面的基准测试框架,用于评估多模态智能体在涉及深度推理与多轮工具执行任务中的表现,覆盖视频、音频与图像等多种模态。OmniGAIA 采用一种新颖的多模态事件图(omni-modal event graph)构建方法,从真实世界数据中合成复杂的、多跳(multi-hop)查询任务,这些任务要求跨模态推理与外部工具的深度融合。此外,我们提出 OmniAtlas,这是一种原生多模态基础智能体,基于工具融合推理范式,并具备主动的多模态感知能力。OmniAtlas 通过一种基于事后指导的树状探索策略生成训练轨迹,并结合 OmniDPO 方法实现细粒度错误修正,显著提升了现有开源模型的工具使用能力。本研究标志着迈向下一代原生多模态人工智能助手的重要一步,为真实世界场景下的通用智能交互奠定了基础。
一句话总结
中国人民大学、小红书公司及合作者的研究人员推出了 OmniGAIA —— 一个面向原生多模态智能体的基准测试,要求其在视频/音频和图像/音频输入上进行多跳推理与多轮工具使用;同时推出 OmniAtlas —— 一个具备主动感知与工具集成推理能力的基础智能体,通过回溯引导探索与 OmniDPO 训练,显著提升了开源模型在真实世界智能体任务上的表现。
主要贡献
- OmniGAIA 引入了首个面向原生多模态智能体的基准测试,要求在视频、图像和音频模态上进行多跳推理与多轮工具使用,包含 360 个真实世界任务与开放式答案,以评估超越感知的真实智能体能力。
- 该基准通过新颖的多模态事件图谱流水线构建,从真实数据中挖掘、扩展并模糊化跨模态信号,以合成具有挑战性但可解的任务,从而系统评估工具集成推理能力。
- OmniAtlas 是一个具备主动感知与工具集成推理能力的原生多模态智能体,通过回溯引导轨迹合成与 OmniDPO 训练,将如 Qwen3-Omni 等开源模型在 OmniGAIA 上的 Pass@1 从 13.3 提升至 20.8。
引言
作者利用不断增长的多模态基础模型能力,统一视觉、音频与语言,但指出当前系统存在关键缺口:多数现有系统侧重感知而非智能体推理与工具使用。以往基准测试多为双模态且以感知为中心,无法评估真实多媒体输入上的多跳推理或多轮工具整合能力。为此,他们提出 OmniGAIA —— 一个包含 360 个任务的基准测试,涵盖“视频+音频”与“图像+音频”场景,要求跨模态推理与可验证的工具使用;并推出 OmniAtlas —— 一个通过新颖轨迹合成与微调流水线训练的原生多模态智能体,显著提升开源模型在这些复杂任务上的表现。
数据集
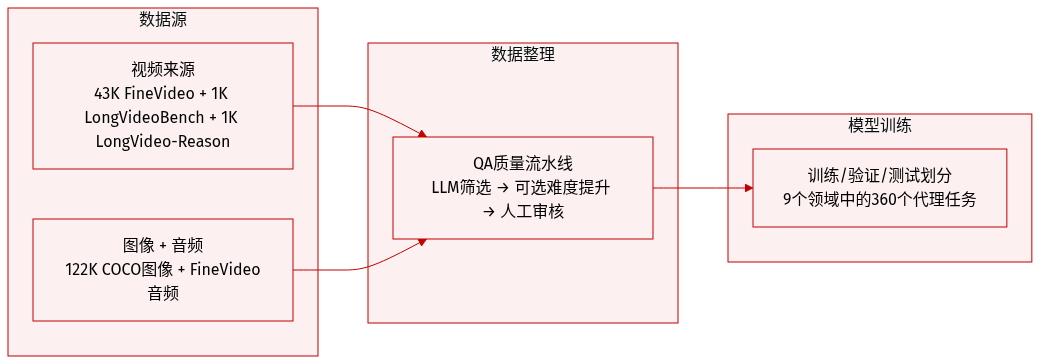
- 作者构建 OmniGAIA 以模拟真实世界的多模态交互,包含两种设置:“视频+音频”与“图像+音频”配对。
- 视频数据方面,聚合了 FineVideo 的 43K 个片段(平均 4 分钟),以及 LongVideoBench 和 LongVideo-Reason 各约 1K 个片段(平均 10 分钟),用于测试长上下文推理能力。
- 图像+音频方面,将 COCO 2017 的 122K 标注图像与 FineVideo 的音频轨道配对,创建多样化的声学-视觉场景。
- 每对问答需经过三阶段质量流程:LLM 筛选(使用 DeepSeek-V3.2 和 Gemini-3-Pro)以过滤自然性、多模态必要性与答案唯一性;可选难度扩展(增加证据或计算);最终由三名计算机科学研究生人工审核,验证正确性与可解性。
- OmniGAIA 包含 360 个跨 9 个领域的智能体任务,旨在考验长时程感知、多步推理与工具使用(主要为网络搜索,偶尔涉及代码)。任务需基于数分钟媒体内容,常涉及多跳规划。
方法
作者采用多阶段、智能体驱动的流水线构建复杂的多跳多模态任务。框架始于从多样视频、音频与图像源收集数据,随后进行细粒度信息提取、事件图谱构建、智能体扩展,最终通过受控模糊化生成问答对。每一阶段旨在逐步丰富任务的语义与逻辑结构,确保生成的问题需跨模态推理与工具使用。
第一阶段,对原始媒体输入(涵盖长视频、音频片段与图像)进行处理,提取结构化、时间感知的信号。对于视频,作者将其分割为 60 秒片段以保留时间粒度,生成片段级与全视频描述,捕捉场景、事件与环境声音。音频通过带时间戳的 ASR、说话人分离与声学事件检测进行分析,并附加全局摘要与环境标签(如“体育场”、“室内”)。图像则进行 OCR、物体与人脸识别及整体描述。这些输出按“确定性优先”原则结构化为 JSON 报告,以最小化幻觉并支持下游图谱构建。
参考框架图,这些提取的信号被结构化为初始事件图谱。作者使用 DeepSeek-V3.2 作为推理智能体构建此图谱,明确编码实体、事件及其跨模态关系。图谱拓扑设计反映真实世界复杂性——分支、级联与混合结构——以合成逻辑一致的多跳任务。该图谱作为后续智能体扩展阶段的骨架。
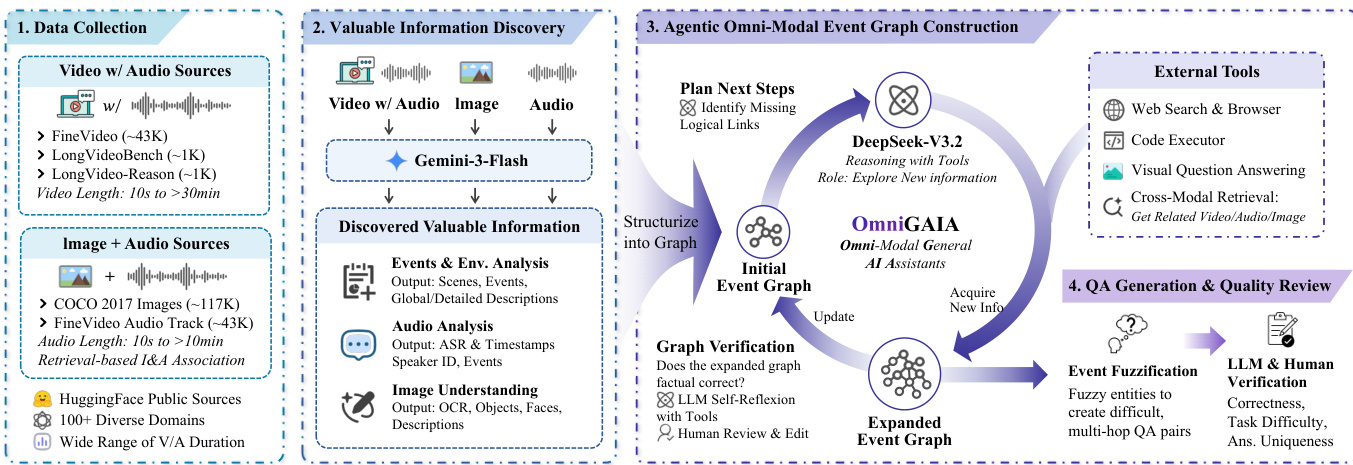
智能体扩展阶段引入了工具集成推理范式。DeepSeek-V3.2 智能体作为探索智能体,自主调用一系列外部与跨模态工具,以发现缺失证据并扩展图谱。这些工具包括网络搜索与浏览(用于时效性知识)、代码执行(用于数值推理)、视觉问答(用于外部图像分析)与跨模态检索(用于链接相关视频、音频或图像内容)。智能体还支持主动多模态感知,可按需请求特定视频段、音频窗口或裁剪图像区域——避免整体降采样,保留关键细节的保真度。
图谱扩展后,作者通过事件模糊化生成问答对。不直接查询图谱节点,而是选择长推理路径上的节点,并应用模糊变换——如将特定实体替换为其类型或屏蔽关键属性。这迫使模型遍历完整逻辑路径并整合多源、多模态证据以推导唯一答案,从而提高任务难度并减少琐碎事实查找。
OmniAtlas 的训练策略基于合成智能体轨迹。作者使用 Gemini-3-Flash 将原始媒体转换为详细文本注释,再使用 DeepSeek-V3.2 通过引导树探索生成工具增强的解决方案轨迹。每一步中,智能体采样多个延续,验证器修剪错误分支,仅保留成功轨迹用于监督微调。训练目标采用掩码监督,仅计算智能体生成的标记(推理与工具调用)的损失,忽略工具观察结果以防止记忆环境反馈。
如下图所示,作者进一步使用 OmniDPO(一种细粒度错误修正方法)优化模型。对于每个失败轨迹,Gemini-3-Flash 识别首个错误步骤并生成修正前缀。这创建了正负偏好对——记为 τwin 和 τlose——用于优化掩码 DPO 目标。该方法聚焦于错误发生的特定模块,无论是在感知、推理还是工具使用环节。
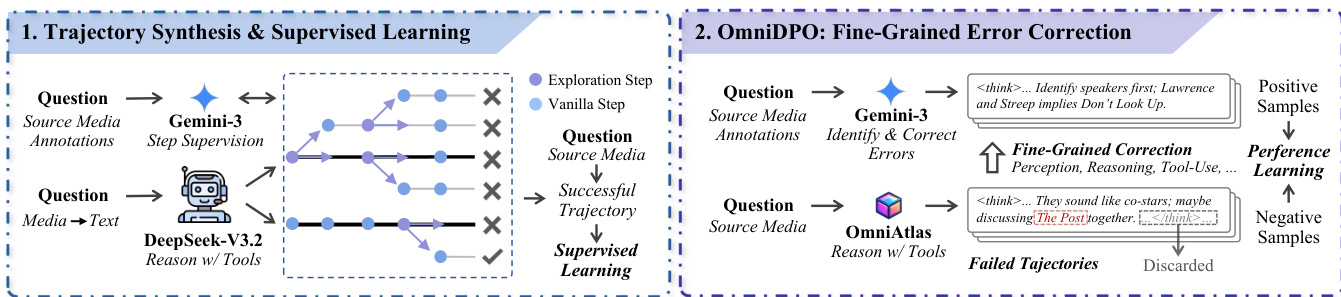
智能体行为由形式化轨迹定义控制:τ=[(st,at,ot)]t=0T,其中 st 为推理思考,at 为动作(工具调用或最终响应),ot 为工具观察结果。生成按步进行,调用工具时暂停,将观察结果附加至上下文后继续生成。这保留中间推理状态并支持连贯的长时程问题解决。系统提示明确鼓励“按需查看”行为,使智能体仅在必要时请求特定媒体片段或区域,这对高效处理长视频与高分辨率图像至关重要。
实验
- OmniGAIA 基准测试揭示了专有模型(如 Gemini-3-Pro)与开源模型之间存在巨大性能差距,凸显了开源多模态感知与工具集成推理的不足。
- 仅扩大模型规模无法提升性能;工具使用策略等智能体能力比参数数量更为关键。
- OmniAtlas 显著提升各规模模型的性能,尤其对小模型效果更佳,通过改进工具使用与推理实现,但感知错误仍是持续瓶颈。
- 困难任务暴露了级联失败:工具使用不佳导致推理崩溃,尤其在开源模型中;即使使用 OmniAtlas,多跳推理仍具挑战性。
- 工具使用至关重要但非充分条件——成功智能体避免调用不足与查询漂移,优先基于位置定位、验证事实并在验证后才计算。
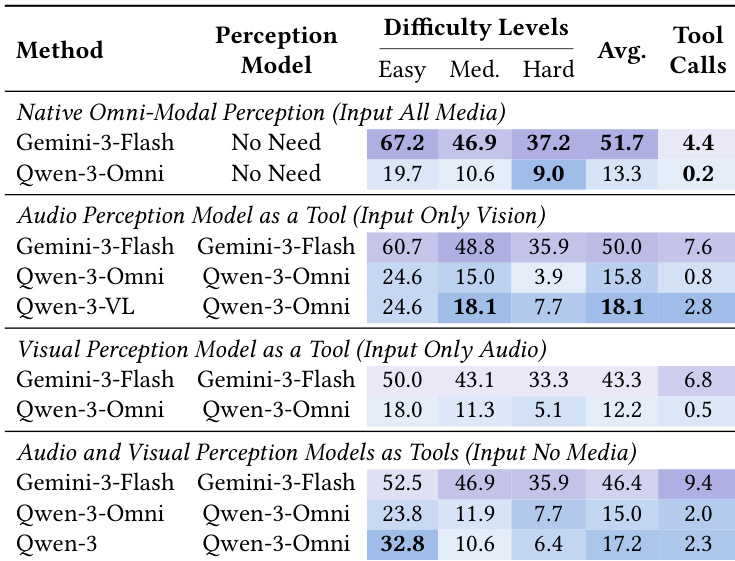
- 对强智能体而言,原生感知优于工具感知,提供更高准确率与更低成本;工具感知对弱智能体在简单任务中或有帮助,但在困难任务中损害性能。
- OmniAtlas 训练(SFT + DPO)有效减少工具使用与推理错误,SFT 驱动主要提升,DPO 提供进一步优化。
- 案例研究表明,失败常源于工具使用中的过早假设或确认偏误,而成功则需结构化证据获取与验证。
作者在挑战性基准测试上评估了一系列专有与开源多模态模型,揭示了顶级专有系统(如 Gemini-3-Pro)与最佳开源基线之间存在显著性能差距。他们提出的 OmniAtlas 框架显著提升开源模型在各类别与难度等级上的表现,尤其对小模型,通过增强工具使用策略而非依赖规模实现。尽管如此,需多跳推理的困难任务仍具挑战性,感知错误在工具使用改进后仍是关键瓶颈。
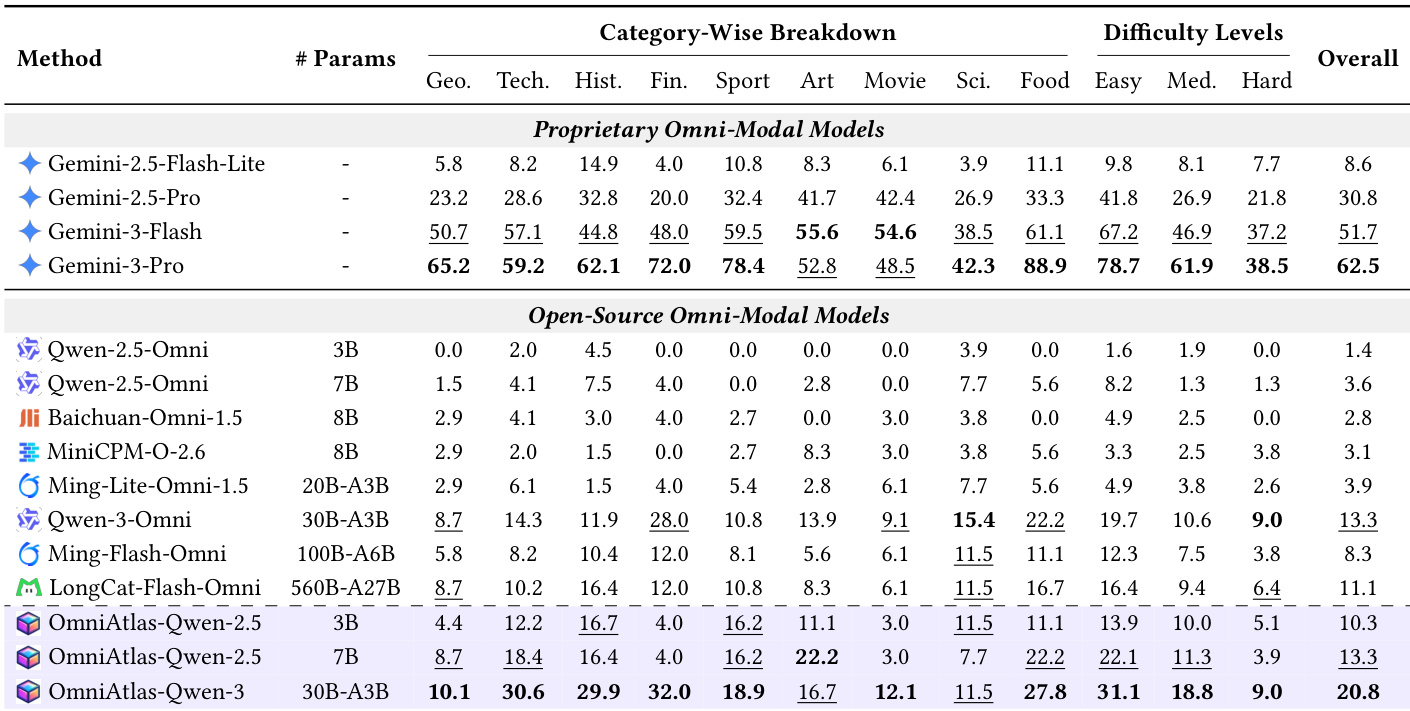
作者使用 OmniAtlas 微调开源多模态模型,显著减少工具使用与推理错误,同时提升整体性能。结果表明,结合监督微调与直接偏好优化可获得最强提升,尤其在小模型上。尽管如此,感知错误仍较高,表明原生多模态理解仍是关键瓶颈。
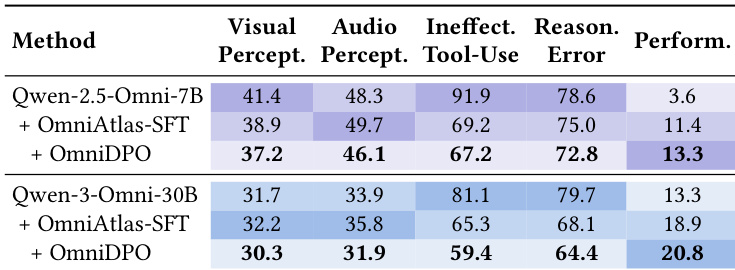
作者通过细粒度错误分析揭示,无效工具使用与推理错误主导了各模型的失败,尤其在困难任务上,开源模型表现出近乎饱和的工具误用与级联推理崩溃。专有模型如 Gemini-3-Pro 在感知与工具使用上错误率显著更低,凸显其更成熟的规划能力,而 OmniAtlas 改善了工具策略,但视觉与音频感知仍是持续瓶颈。结果表明,即使增强工具参与,基础感知局限仍是解决复杂多跳任务的关键障碍。
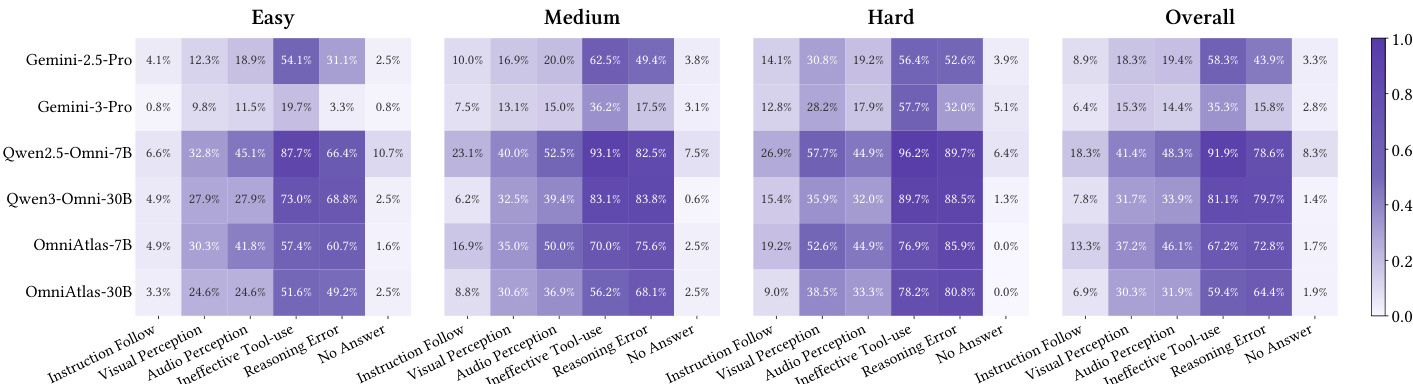
作者比较了原生多模态感知与将感知模型作为外部工具使用,发现原生感知对如 Gemini-3-Flash 等强模型提供更优性能与效率,而工具感知对弱模型仅提供有限增益且持续增加工具调用成本。对 Qwen-3-Omni,用工具替代原生感知在简单任务上提升性能,但在困难任务上表现下降,表明工具无法弥补缺乏集成跨模态推理的缺陷。结果确认,对强智能体应默认使用原生感知,工具感知仅作为弱系统或缺失模态的备选方案。