Command Palette
Search for a command to run...
一个超大规模视频推理套件
一个超大规模视频推理套件
摘要
视频模型的快速发展主要集中在视觉质量的提升,而其推理能力却尚未得到充分探索。视频推理将智能置于时空一致的视觉环境中,这类环境超越了文本所能自然表达的范畴,从而支持对时空结构(如连续性、交互性与因果关系)的直观推理。然而,由于缺乏大规模训练数据,系统性地研究视频推理及其扩展规律面临显著障碍。为弥补这一空白,我们提出了前所未有的大规模视频推理数据集——Very Big Video Reasoning(VBVR)数据集。该数据集涵盖200个精心设计的推理任务,遵循严谨的分类体系,包含超过一百万段视频片段,规模约为现有数据集的千倍(约三个数量级)。此外,我们还推出了VBVR-Bench——一个可验证的评估框架,该框架突破了传统基于模型判断的局限,引入基于规则且与人类认知对齐的评分机制,从而实现可复现、可解释的视频推理能力诊断。依托VBVR系列资源,我们开展了视频推理领域首批大规模扩展性研究之一,并观察到模型在面对未见推理任务时已初现涌现式泛化能力的迹象。总体而言,VBVR为可泛化的视频推理研究迈入下一阶段奠定了坚实基础。相关数据集、基准工具包及模型均已公开,访问地址为:https://video-reason.com/。
一句话总结
来自伯克利、南洋理工、东北大学、加州大学圣地亚哥分校等机构的研究人员推出了 VBVR,这是一个大规模视频推理数据集和基准,支持可扩展、可解释的评估;该数据集揭示了视频模型中的涌现泛化能力,推动时空推理能力超越以往小规模研究。
主要贡献
- 为解决视频推理缺乏大规模训练数据的问题,作者推出了 VBVR 数据集,包含超过一百万个视频片段,涵盖 200 个精心设计的任务,按感知、变换、空间性、抽象和知识五大认知分类组织。
- 他们提出了 VBVR-Bench,一种基于规则、与人类判断对齐的可验证评估框架,以实现可复现和可解释的视频推理评估,摆脱不可靠的模型自评。
- 利用 VBVR 套件,他们开展了视频推理领域首批大规模扩展性研究之一,观察到模型对未见过任务的早期涌现泛化迹象,为未来通用视频推理研究奠定基础。
引言
作者采用一种基于认知架构的原则性方法——涵盖感知、变换、空间性、抽象和知识——构建了 VBVR,这是一个包含超过 200 万样本、覆盖 200 个任务的大规模视频推理数据集,填补了时空推理领域大规模训练数据的空白。以往视频生成与推理研究多聚焦于视觉保真度或狭窄的零样本评估,缺乏标准化训练划分和可复现的评估框架以支持扩展性研究。他们的主要贡献是 VBVR-Bench——一种基于规则、与人类判断对齐的评估系统,可实现对推理能力的可解释诊断,同时提供实证证据表明:在 VBVR 上扩展视频模型可获得对未见过任务的涌现泛化能力——为下一代通用视频推理系统奠定基础。
数据集

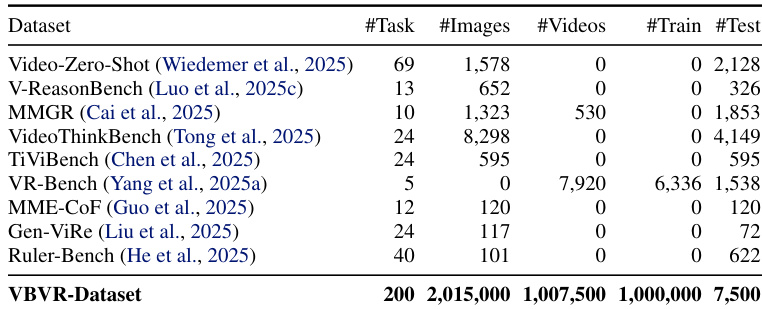
作者使用 VBVR-Dataset —— 一个大规模合成视频推理基准 —— 在 200 个认知驱动的任务上训练和评估模型,其中 150 个任务公开发布,50 个保留用于未来排行榜。以下是数据的组成、处理与应用方式:
-
数据集构成与来源
- 基于认知科学原理,通过同行评审流程从 500 多个提案中筛选出 150 个获批任务设计构建而成。
- 任务以参数化生成器(VBVR-DataFactory)实现,托管于 GitHub 仓库,命名标准化(例如 G-15_grid_avoid_obstacles_data-generator)。
- 生成器由商业团队(G 类型)和开源开发者(O 类型)共同贡献。
-
关键子集详情
- 训练集:100 个任务 × 10,000 个样本 = 100 万样本。每个任务通过参数空间(如网格尺寸、障碍物布局)的约束随机采样生成多样化、非平凡样本。
- 测试集:150 个任务 × 50 个样本 = 7,500 个样本。包含 50 个与训练集重叠的任务用于分布内评估,以及 100 个独特任务用于分布外泛化。
- 过滤规则:所有任务必须满足六项标准:信息充分性、确定性可解性、视频依赖性、视觉清晰度、参数多样性(≥10,000 个样本)和技术可行性(基于 PIL 渲染)。被拒绝的任务包括多步逻辑链或需要精确数值解的物理任务。
- 验证:每个样本自动验证其可解性(如 A* 搜索)、视觉清晰度(无遮挡、文本清晰)和参数边界。失败样本触发重试;持续失败则记录日志。
-
论文中的数据使用
- 训练使用 100 个任务的 100 万样本。测试评估使用 150 个任务的 7,500 个样本。
- 模型 VBVR-Wan 在 100 万训练样本上训练,显示在显式监督下推理性能提升。
- 评估涉及生成 4,500 个视频(500 个测试提示 × 9 个模型),由人工标注者使用三个 1–5 分制评分:任务完成度、推理逻辑、视觉质量。
-
处理与基础设施
- 渲染:所有视觉素材为 512×512 像素、24 位 RGB、24 帧/秒、H.264 编码。
- 存储:样本存储于私有加密的 AWS S3 存储桶,按生成器/任务分层组织。每个样本包含:first_frame.png、prompt.txt、final_frame.png 或 goal.txt、ground_truth.mp4。
- 生成:通过 AWS Lambda(最多 990 个并发工作节点)扩展,使用 SQS 队列、CloudWatch 监控和 DLQ 处理失败任务。典型运行时间:2–4 小时,成本 $800–1200。
- 可复现性:每个样本记录生成器的 Git 提交哈希。版本控制的模块化代码支持独立更新。
- 多样性保障:分层采样、约束满足、重复检测(通过哈希)和视觉随机化(颜色、位置、样式)。
方法
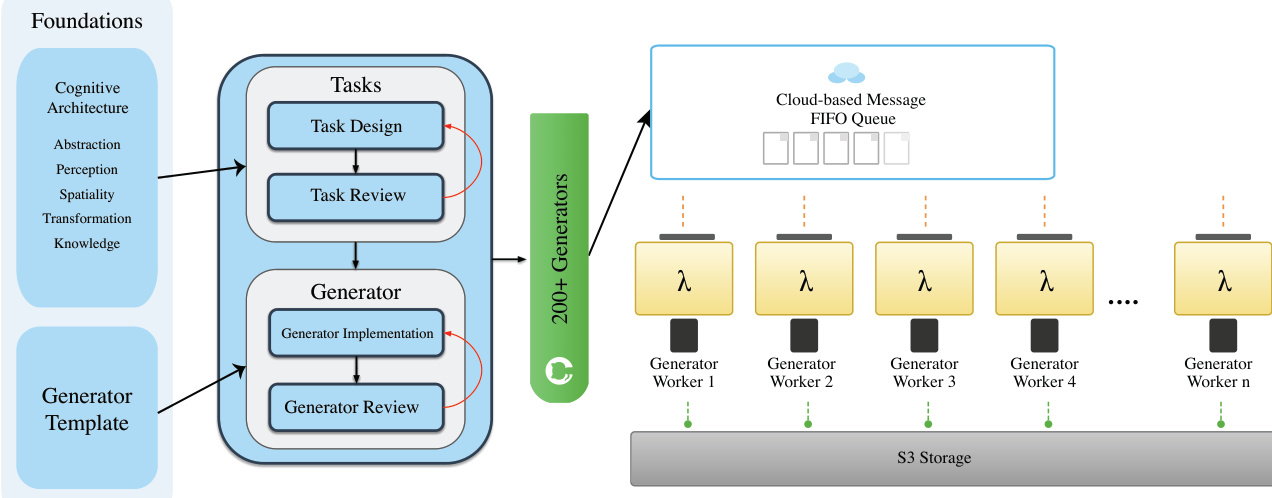
作者采用结构化三阶段流水线进行数据整理:从任务设计与审批开始,继而实现任务专用生成器,最终通过集成质量控制的大规模分布式生成收尾。该流水线确保每个阶段输出定义明确、可复现,适用于下游模型训练与评估。设计基于认知原理——借鉴抽象、空间推理与变换等领域——同时保持灵活性,优先考虑任务意义而非僵化的分类约束。
系统核心是标准化的生成器架构。所有任务生成器继承自 BaseGenerator 抽象类,强制统一接口与输出格式。每个生成器实现四个必需方法:用种子和参数初始化、样本生成、样本验证、标准化输出保存。该模板确保 200 多个生成器间的一致性,便于与 VBVR-DataFactory 集成批量处理,并通过验证钩子嵌入质量保障,检查对象遮挡与解可行性等关键条件。
参考框架图,该图说明任务设计如何流入生成器实现,两个阶段均经过同行与专业评审。验证后的生成器部署于分布式基础设施,通过基于云的 FIFO 消息队列协调。每个生成器工作节点以 Lambda 函数形式存在,从队列拉取任务、执行生成、并将输出存储至 S3。该架构支持在固定随机种子下实现可扩展、容错且可复现的数据生产。
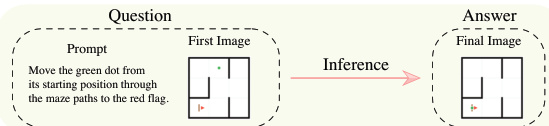
每个生成器产生确定性的四部分输出:初始状态图像(first_frame.png)、文本提示(prompt.txt)、目标状态图像(final_frame.png)和完整解轨迹视频(ground_truth.mp4)。前两部分作为模型输入,后两部分提供可验证监督——使模型不仅能学习正确结果,还能学习达成该结果的推理路径。例如,在网格导航任务中,生成器可指定网格尺寸、障碍物位置和起止点,然后算法计算最短路径,访问所有必需方块后抵达目标。
如下图所示,模型推理过程接收提示和首帧,输出最终帧。评估引擎随后将该输出与真实轨迹和最终状态对比,评估任务完成度、逻辑一致性与视觉保真度。
任务多样性通过结构化参数空间实现,变化对象数量、空间配置、结构复杂度与难度等级。生成器采用分层采样确保这些维度的平衡覆盖。部署前,每个生成器需经代码审查,验证其可扩展性、视觉质量、边缘情况处理与可复现性。仅满足这些标准的生成器才被允许进入大规模生产,确保高质量、多样化且认知有意义的推理任务。
实验
- 推出 VBVR-Bench,一个确定性、基于规则的评估工具包,包含 100 个任务,分为领域内和领域外两组,用于测试超越记忆的泛化与推理原语。
- 验证了自动化评分与人类偏好高度一致,确认该基准对模型能力的可解释性与诊断价值。
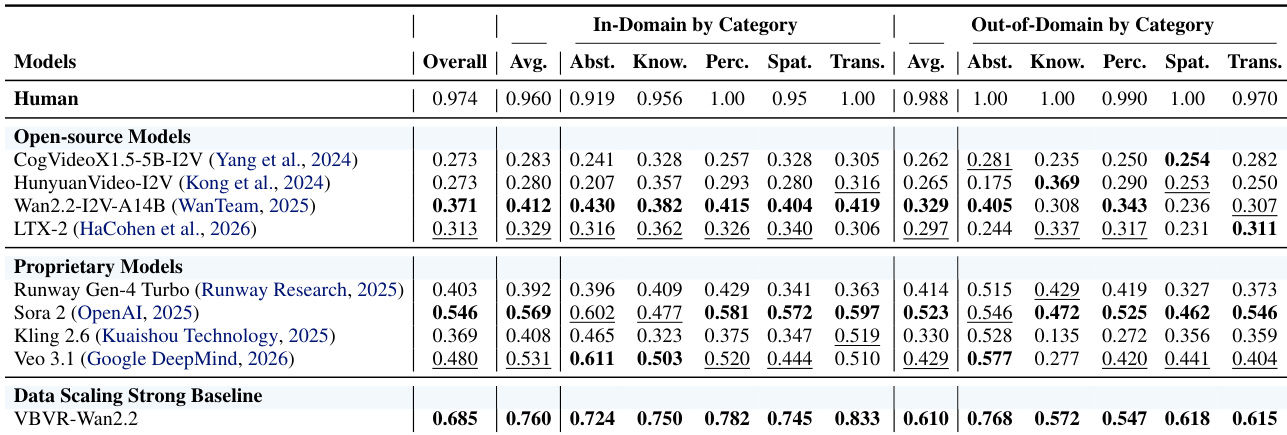
- 发现专有模型(Sora 2、Veo 3.1)优于开源基线,但在 VBVR-Dataset 上微调 Wan2.2 得到的 VBVR-Wan2.2 实现了最先进性能,大幅缩小差距。
- 揭示结构化能力依赖:知识与空间性强正相关,与感知负相关;抽象与变换和空间性负相关,表明模块化认知能力。
- 证明数据扩展可提升领域内和领域外性能,但收益趋于平缓,仍存在持续的泛化差距,表明架构限制。
- 定性分析显示 VBVR-Wan2.2 擅长可控、遵循约束的执行,在精确操作任务上常超越 Sora 2,展现出涌现的多步推理与策略一致性。
- 识别关键失败模式:长时程身份不稳定、分步任务中的程序不忠实、复杂时序或因果约束下的崩溃。
- 确认 VBVR 训练在提升运动与时间一致性的同时保留核心生成质量,支持“可控性是视频模型可验证推理基础”的原则。
作者使用 VBVR-Wan2.2 证明,在大型推理导向数据集上微调可显著提升视频生成性能,尤其在相机运动一致性和主体-背景稳定性方面。结果显示,模型保持高美学与成像质量的同时,在运动动力学和时间连贯性上实现更高精度,表明其向可控、遵循约束的执行而非通用场景生成转变。这表明有针对性的数据扩展可在不牺牲核心生成质量的前提下增强推理能力。

作者使用 VBVR-Dataset 通过结构化基准评估视频推理模型,涵盖 100 个多样化任务,分为领域内和领域外泛化设置。结果显示,在该数据集上微调可显著提升模型性能,尤其在空间与感知推理方面,但长时程控制与过程忠实度仍存在持续差距。能力分析进一步表明,知识与空间性等推理能力呈正相关,而感知与抽象等能力呈强负相关,暗示模型行为中存在不同底层机制。
作者通过受控数据扩展实验评估增加训练数据如何影响领域内与领域外任务的视频推理性能。结果显示,性能随数据增加而提升,但趋于平缓,揭示即使在固定架构下,长时程推理与系统性泛化仍存在持续差距。研究强调,虽然数据扩展可增强可迁移推理能力,但需架构创新以克服时间一致性与约束遵循的根本瓶颈。
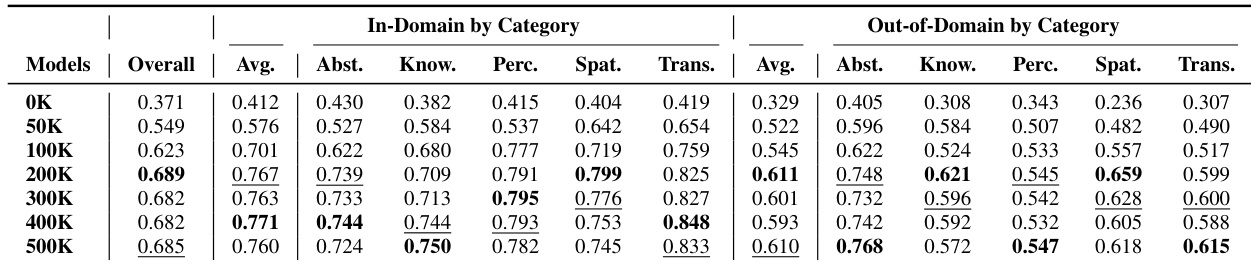
作者使用 VBVR-Bench 评估视频生成模型在领域内与领域外推理任务上的表现,发现 Sora 2 和 Veo 3.1 等专有模型优于开源基线,而使用 VBVR-Dataset 微调 Wan2.2 得到的模型获得最高综合得分,展现强泛化能力。结果显示,增加训练数据可提升领域内与领域外性能,但仍存在持续差距,凸显长时程推理与系统性泛化的局限。能力分析进一步揭示结构化权衡,例如知识与感知呈强负相关,暗示模型推理中存在不同底层机制。