Command Palette
Search for a command to run...
面向大规模语言模型终端能力扩展的数据工程
面向大规模语言模型终端能力扩展的数据工程
Renjie Pi Grace Lam Mohammad Shoeybi Pooya Jannaty Bryan Catanzaro Wei Ping
摘要
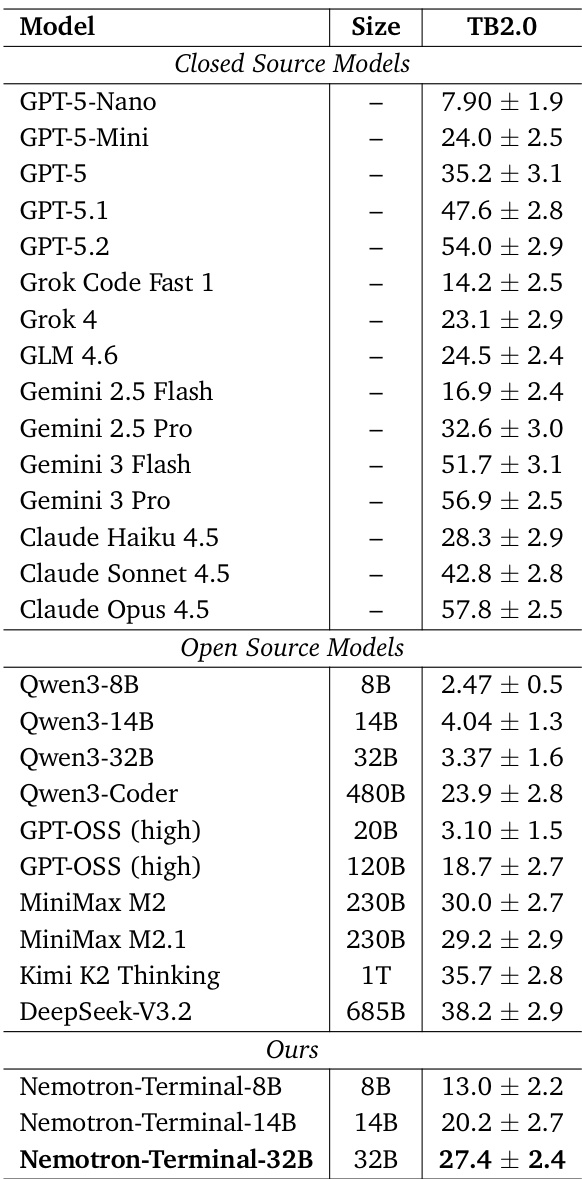
尽管大型语言模型在终端能力方面取得了快速进展,但当前顶尖终端智能体背后的数据训练策略仍 largely 未公开。为此,本文通过系统性研究终端智能体的数据工程实践,做出了两项关键贡献:(1)提出一种轻量级的合成任务生成管道——Terminal-Task-Gen,支持基于种子(seed-based)和技能(skill-based)的任务构建;(2)对数据与训练策略进行了全面分析,涵盖数据过滤、课程学习(curriculum learning)、长上下文训练以及模型规模扩展行为。基于该管道,我们构建了Terminal-Corpus,一个大规模开源的终端任务数据集。利用该数据集,我们训练了Nemotron-Terminal系列模型,其初始化自Qwen3(8B、14B、32B),在Terminal-Bench 2.0评测中取得了显著性能提升:Nemotron-Terminal-8B的得分从2.5%提升至13.0%,Nemotron-Terminal-14B从4.0%提升至20.2%,Nemotron-Terminal-32B从3.4%提升至27.4%,性能已接近甚至匹配远大于其规模的模型。为加速该领域的研究进展,我们已将模型检查点及大部分合成数据集在Hugging Face平台开源,地址为:https://huggingface.co/collections/nvidia/nemotron-terminal。
一句话总结
皮仁杰、Grace Lam 与 NVIDIA 研究人员提出 Terminal-Task-Gen,一种合成数据管道,用于生成 Terminal-Corpus 以训练 Nemotron-Terminal 模型。该模型通过基于技能的任务设计和课程学习,在 Terminal-Bench 2.0 上表现优于更大模型,加速了开源终端智能体研究。
主要贡献
- 我们提出了 Terminal-Task-Gen,一种可扩展的合成任务生成管道,结合数据集适配与基于技能的任务构建,生成 Terminal-Corpus,解决了终端智能体缺乏透明、高质量训练数据的问题。
- 我们系统评估了包括过滤、课程学习和长上下文训练在内的数据工程策略,揭示了有针对性的数据组成和扩展如何提升不同规模模型在终端任务上的表现。
- 使用 Terminal-Corpus,我们训练了 Nemotron-Terminal 系列模型(8B、14B、32B),在 Terminal-Bench 2.0 上分别达到 13.0%、20.2% 和 27.4% 的成绩,性能媲美更大模型,同时发布模型检查点和数据集以加速开放研究。
引言
作者采用结构化数据工程方法,解决面向终端的大型语言模型(LLM)高质量训练数据稀缺的问题——随着模型越来越多地与命令行环境交互以执行软件任务,这一缺口尤为关键。以往方法要么依赖低效的多智能体系统生成合成数据,要么通过适配器复用非终端数据集,但缺乏环境保真度和技能针对性。其主要贡献是 Terminal-Task-Gen,一个轻量级管道,结合数据集适配与基于技能的合成任务生成,实现可扩展、定向的终端智能体数据创建。基于此,他们训练了 Nemotron-Terminal 系列,其性能显著优于基础模型,并匹敌更大前沿系统——表明战略性数据设计可超越蛮力扩展。
数据集
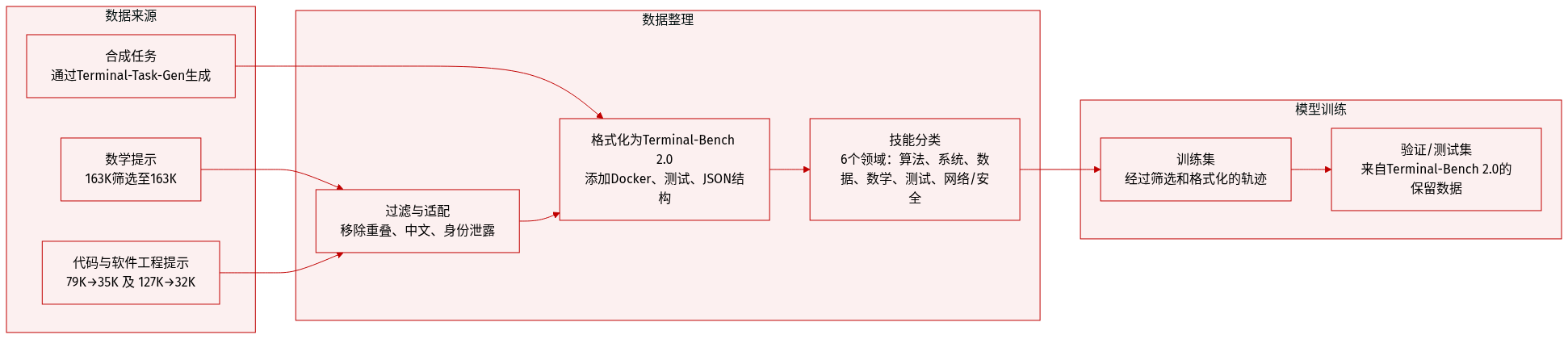
作者使用混合数据集,结合精选提示集与合成终端任务,训练能够执行端到端终端工作流的智能体。
-
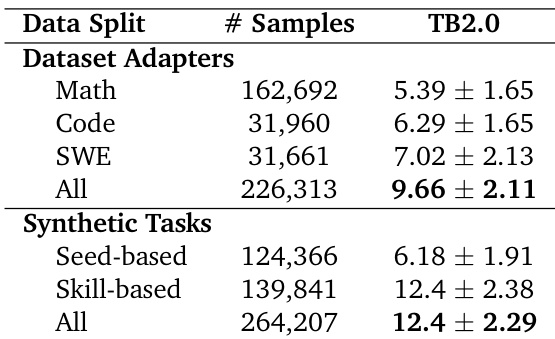
数据集组成与来源:
- 来自 Nemotron-Cascade 的三个主要提示子集:数学(163K → 163K 过滤后)、代码(79K → 35K 过滤后)和软件工程(127K → 32K 过滤后),源自 OpenMathReasoning、OpenCodeReasoning 和 SWE-Bench 变体。
- 通过 Terminal-Task-Gen 生成的合成任务,使用结构化种子和 6 个基础技能维度的分类法:算法、系统、数据处理、数学、测试、网络/安全。
- 所有数据均使用 Terminus 2 模板适配为 Terminal-Bench 2.0 格式,包含环境 Dockerfile 和测试用例(适配器任务除外,其无测试用例)。
-
关键子集详情:
- 数学提示:163K 提示经过过滤,排除简单问题(基于 DeepSeek-R1 响应长度 < 2K token)。
- 代码提示:79K 提示经过过滤和去重,保留 35K,针对具有挑战性的编程问题。
- SWE 提示:来自多个 SWE 基准的 127K 实例,过滤后保留 32K 唯一提示,每个包含问题描述和有缺陷的代码文件。
- 合成任务:通过 LLM(DeepSeek-V3.2)使用种子记录(问题描述、领域、可选解决方案)或基于技能的模板生成;包含测试用例、输入文件和 Docker 环境。
-
数据使用与处理:
- 所有轨迹均使用 Terminus 2 生成,其将输出结构化为 JSON(分析、计划、命令、任务完成)。
- 提示数据集通过将提示插入指令占位符并添加领域特定后缀,映射至 Terminal-Bench 格式。
- 合成任务以自然语言提示、pytest 测试用例(含部分得分权重)、输入文件和 Docker 环境格式化——匹配 Terminal-Bench 结构。
- 合成任务不生成标准答案;正确性通过合成测试验证。
-
过滤与整理:
- 去污染:移除与 Terminal-Bench 2.0 测试样本存在 14-gram 重叠的提示。
- 质量过滤:移除包含身份泄露和中文字符的响应。
- 可选轨迹过滤:丢弃不完整或失败的轨迹,以鼓励简洁性和正确性。
- 技能分类法确保覆盖安全、软件工程、数据科学和系统管理等领域。
方法
作者采用两阶段合成数据生成管道,构建大规模、高质量数据集,用于训练基于终端的自主智能体。该框架始于数据集适配,摄入现有问题库(如数学、代码和软件工程数据集),并通过提示过滤、去重和结构适配将其转换为终端兼容任务。此阶段确保广泛的基础覆盖,将抽象问题陈述转化为包含明确文件 I/O 要求和验证标准的可执行终端工作流。
如下图所示,合成任务生成阶段并行运行,源自两个不同来源:种子数据和精心整理的基础终端技能分类法。基于种子的生成使用邻近领域(如科学计算或算法挑战)的高质量问题规范,提示 LLM 将其重构为自包含的终端任务。LLM 适配器为每个问题添加具体工程约束——如包安装、输入/输出文件路径和测试用例生成——同时确保解决方案隔离以防止泄露。生成的任务与预构建的领域特定 Docker 镜像配对,封装常见依赖项,实现高效、可扩展的任务创建,无需为每个任务单独构建环境。
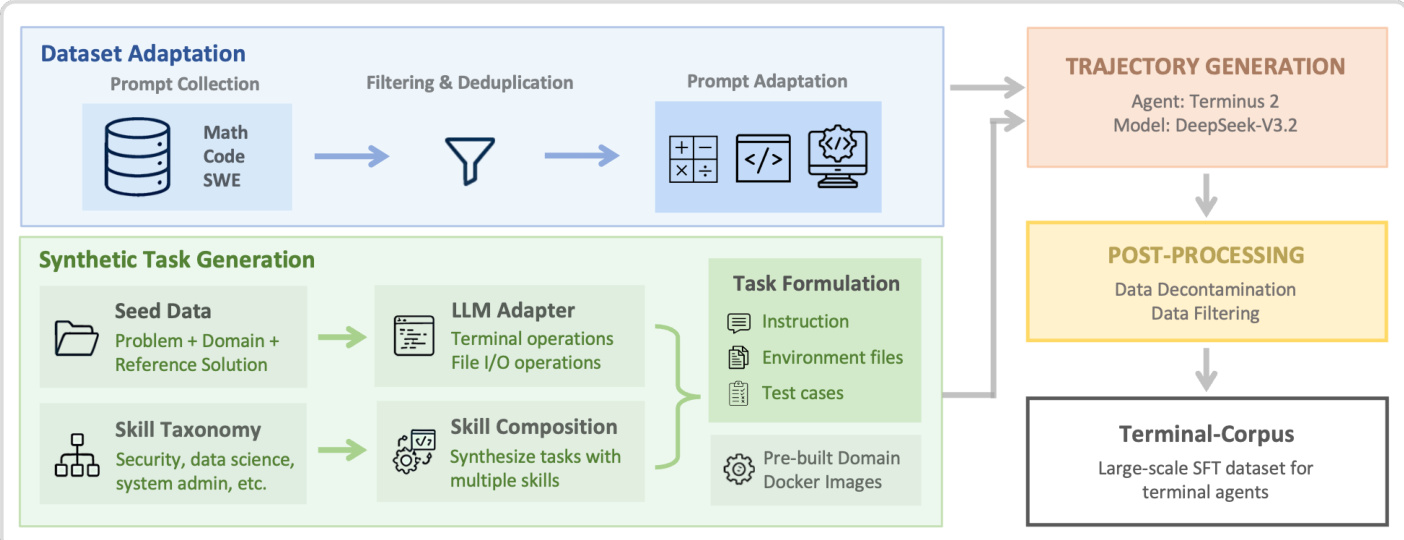
相比之下,基于技能的生成从结构化的基础终端操作集——如文件操作、依赖管理或调试——中合成新任务,这些操作被组织为九个领域特定类别。LLM 被提示创造性地组合每项任务中的 3–5 个基础操作,确保新颖性同时保持可验证性。领域特定模块(如数据科学或安全)被注入标准化系统提示模板,以指导任务制定。这些模块强制执行领域适当约束——例如,数据科学要求统计分析流水线,安全要求漏洞利用载荷构建——同时保持统一输出格式以便下游处理。
如下图所示,系统提示模板要求生成的任务自包含、真实且可编程验证。它强制执行严格规则,防止解决方案泄露,并要求明确指定文件路径、格式和测试要求。每个任务必须包含提示、测试用例、元数据和环境配置,全部编码在 XML 标签中以便结构化解析。提示还规定任务应难解易验,确保智能体必须推理而非检索。

对于数据集适配,对种子问题应用领域特定指令模板。例如,数学适配器指示智能体将最终答案写入 /app/solution.txt,而 SWE 适配器指导智能体定位缺陷、生成 SEARCH/REPLACE 编辑并将差异保存至 /app/solution.patch。这些模板确保跨领域的任务结构一致,同时保留原始问题的语义意图。


生成的任务随后由 Terminus 2 智能体执行,其在沙盒 Docker 容器内通过交互式 tmux 会话运行。每一步,智能体接收终端输出并响应结构化 JSON 动作计划,包含分析、下一步推理和待执行的按键序列。智能体模型 DeepSeek-V3.2 在生成的轨迹数据上微调,数据经过后处理去污染和过滤后编译为最终 Terminal-Corpus 数据集。该端到端管道实现对基于终端的问题解决技能的系统性覆盖,同时保持可扩展性和领域一致性。
实验
- 验证了在精选合成数据上训练的 Nemotron-Terminal 模型,在 Terminal-Bench 2.0 上显著优于更大的基础模型,仅用适度计算资源即取得竞争性结果。
- 证明合成轨迹数据使小型模型获得基础模型完全缺乏的领域特定终端技能——如调试、安全和数据查询。
- 确认结合多种数据源(数学、代码、SWE)比单一来源性能更强,凸显数据多样性价值。
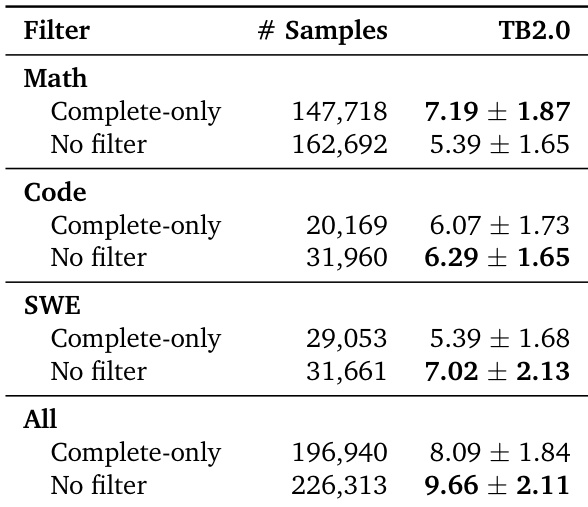
- 发现训练时过滤轨迹会损害性能;保留不完整或失败轨迹通过暴露真实错误恢复模式提高鲁棒性。
- 表明超出标准限制扩展上下文长度不会提升性能,反而可能因噪声长尾数据而降低性能。
- 确立混合阶段课程学习相比并发训练无优势,支持更简单的数据混合策略。
- 验证模型规模和训练数据量均正向影响性能,更大模型从数据增加中获益更多。
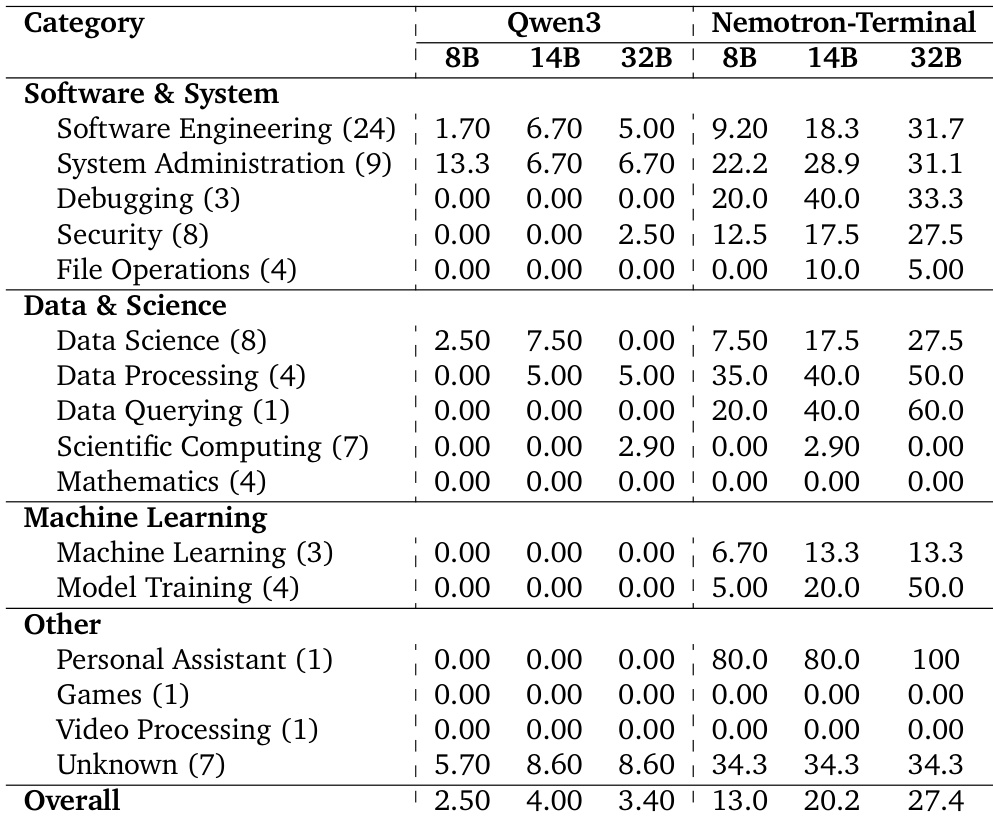
作者使用合成终端轨迹数据微调 Qwen3 模型,在 Terminal-Bench 2.0 上取得媲美或超越更大模型的性能,尽管参数量适中。结果表明,其 Nemotron-Terminal 变体显著优于基础 Qwen3 模型,甚至超越多个闭源和开源系统,证明高质量、领域特定训练数据可弥合与前沿模型的能力差距。在数据查询、安全和调试等功能类别中,性能提升尤为显著,基础模型此前完全无法胜任。
作者评估了数据集适配器上的轨迹过滤策略,发现不应用过滤始终优于仅保留完整轨迹,尤其在组合所有数据源时。结果表明,保留不完整轨迹可改善模型表现,暗示部分或失败尝试的暴露提供了有价值的学习信号。这表明严格过滤可能丢弃有用训练数据,降低整体有效性。
作者评估了不同训练数据源对模型性能的影响,发现结合多个领域比单一来源效果更强。合成任务,尤其是基于技能的任务,带来最大性能提升,而添加基于种子的数据在不提高平均分的情况下增强鲁棒性。结果证实,多样化、高质量数据比依赖单一数据类型更有效。
作者使用合成轨迹数据微调 Qwen3 模型,生成的 Nemotron-Terminal 变体在几乎所有终端任务类别中显著优于其基础模型。结果表明,即使是 8B 和 14B 等小型模型也实现显著提升,32B 模型通过掌握数据查询和模型训练等此前无法触及的领域,媲美更大系统。这些改进突显,有针对性的数据整理而非仅模型规模,是解锁稳健终端能力的关键。
作者比较了 Qwen3-8B 在 Terminal-Bench 2.0 上的两种微调策略,发现混合单阶段训练方法优于两阶段课程策略。结果表明,混合策略得分 13.03 ± 2.16,高于课程学习的 10.39 ± 1.71,表明在此设置中分阶段数据暴露无益。
