Command Palette
Search for a command to run...
DeepVision-103K:一个视觉多样、覆盖广泛且可验证的多模态推理数学数据集
DeepVision-103K:一个视觉多样、覆盖广泛且可验证的多模态推理数学数据集
Haoxiang Sun Lizhen Xu Bing Zhao Wotao Yin Wei Wang Boyu Yang Rui Wang Hu Wei
摘要
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)已被证明能够有效提升大型多模态模型(Large Multimodal Models, LMMs)在视觉理解与推理方面的能力。然而,现有数据集主要依赖于小规模人工构建或对已有资源的重组,导致数据多样性与覆盖范围受限,从而制约了模型性能的进一步提升。为此,我们提出 DeepVision-103K,一个面向RLVR训练的综合性数据集,涵盖丰富的K12数学主题、广泛的知识点以及多样的视觉元素。在DeepVision上训练的模型在多模态数学基准测试中表现出色,并能有效泛化至一般的多模态推理任务。进一步分析表明,训练后的模型在视觉感知、反思与推理能力方面均有显著增强,验证了DeepVision在推动多模态推理能力发展方面的有效性。数据集获取:https://huggingface.co/datasets/skylenage/DeepVision-103K。
一句话总结
阿里巴巴集团与上海交通大学的研究人员推出了 DeepVision-103K,这是一个用于 RLVR 训练的大规模数据集,通过多样化的结构化视觉-数学内容,增强多模态模型在 K12 数学及通用任务中的视觉推理能力,克服了以往数据的局限性。
主要贡献
- DeepVision-103K 通过提供大规模、聚焦 K12 的资源,包含丰富的视觉元素和广泛的数学覆盖范围,解决了现有 RLVR 数据集多样性不足的问题,使多模态推理模型的训练更有效。
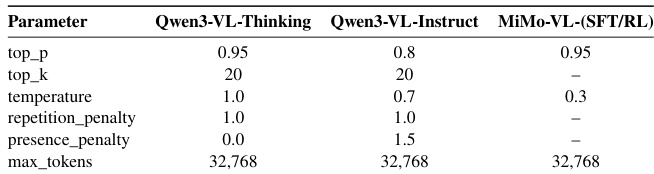
- 使用基于正确性的奖励与 GSPO 在 DeepVision-103K 上训练的模型,在多模态数学基准测试中(如 WeMath 上达到 85.11%)表现持续提升,并能泛化到通用多模态任务,优于官方思维变体及基于先前开源数据集训练的模型。
- 人工分析确认了三大关键提升:改进的一次性视觉感知、主动视觉反思以纠正错误、更严谨的数学推理——验证了 DeepVision 的结构化视觉逻辑任务与可验证奖励驱动了可测量的能力提升。
引言
作者利用“可验证奖励的强化学习”(RLVR)提升大型多模态模型(LMMs)的视觉反思与推理能力,这是解决融合文本与图像的复杂现实任务的关键能力。以往 RLVR 数据集受限于规模小、多样性低,常来自重复使用或人工整理的来源,限制了模型的泛化与性能提升。其主要贡献是 DeepVision-103K,一个大规模、多样化的数据集,涵盖 K12 数学主题,包含丰富的视觉元素和基于逻辑的任务,使模型在多模态数学基准测试中取得优异成绩,同时泛化到更广泛的推理任务,增强核心视觉感知与推理能力。
数据集

作者使用 DeepVision-103K——一个大规模、可验证的多模态数学数据集——训练强化学习模型(RLVR)。其组成、处理与应用方式如下:
-
数据集组成与来源
基于从 MM-MathInstruct-3M 和 MultiMath-300K 获取的 330 万道真实 K12 数学题构建。经过三阶段筛选流程后,最终数据集包含 7.7 万组高质量、可验证的问答对。 -
关键子集详情
- 数学子集:7.7 万样本,筛选标准为唯一答案、视觉必要性、中等难度(通过率介于 1/8 至 7/8 之间)。
- 视觉逻辑子集:2.6 万样本,源自 Zebra-CoT 与 GameQA,涵盖迷宫、国际象棋、俄罗斯方块;使用相同通过率标准筛选。
- 视觉类别:涵盖 6 大类——几何、解析图、图表、现实物品等——包含 400 多个独立知识点与 200 多个细粒度主题。
- 筛选规则:
- 阶段 1:移除证明/解释类任务与多答案问题,仅保留视觉必需、单答案项。
- 阶段 2:使用 MiMo-VL-7B-SFT 推理 + MathVerify 筛选通过率在 [1/8, 7/8] 的样本;对代表性不足的难度范围进行选择性采样。
- 阶段 3:使用 Gemini-3-Flash 验证输入完整性、图文对齐性与答案正确性——标记为错误的样本均被剔除。
-
训练用途
- 模型使用 7.7 万组问答对作为主要 RLVR 信号进行训练。
- 数学与视觉逻辑子集在训练中混合,以协同增强数学与视觉推理能力。
- 未进行图像裁剪,图像原样使用。元数据包括视觉元素类型(由 GPT-5 mini 标注)与分层主题标签。
-
处理与元数据
- 视觉元素基于先前研究(Mo 等,2018;Rosin,2008)的分类体系进行归类。
- 每个样本包含图像、问题与答案——结构化设计用于多模态问答与逐步推理。
- 所有数据均经过安全与可验证性过滤;不保留任何个人标识或损坏内容。
实验
- 在 DeepVision 上训练持续提升多模态数学推理能力,在 WeMath 和 LogicVista 等关键任务上超越官方思维变体与闭源模型。
- DeepVision 模型有效泛化到通用多模态任务,优于基础模型与思维变体,表明其推理能力提升超越数学范畴。
- 在 DeepVision 上进行 RL 训练增强了三项核心能力:视觉感知(准确的一次性识别)、视觉反思(主动重新检查错误)、数学推理(更严谨的逻辑链)。
- 消融实验确认,结合多模态数学与视觉逻辑数据比仅训练数学数据表现更优,因为视觉逻辑强化了跨领域的空间推理与模式识别能力。
- 查询正确性验证至关重要——未经验证的训练数据导致显著性能下降,凸显 RL 训练中准确奖励信号的必要性。
- 训练动态显示响应长度增加、奖励上升、熵值稳定,反映模型在 RL 微调过程中持续提升。
在 DeepVision 上训练持续提升多个基准测试中的数学与通用多模态推理能力,优于基线模型,媲美或超越闭源与官方思维变体。性能提升源于增强的视觉感知、反思与数学推理能力,消融实验确认结合多模态数学与视觉逻辑数据比单一领域表现更优。训练期间查询正确性验证也被证明是实现最佳性能的关键。
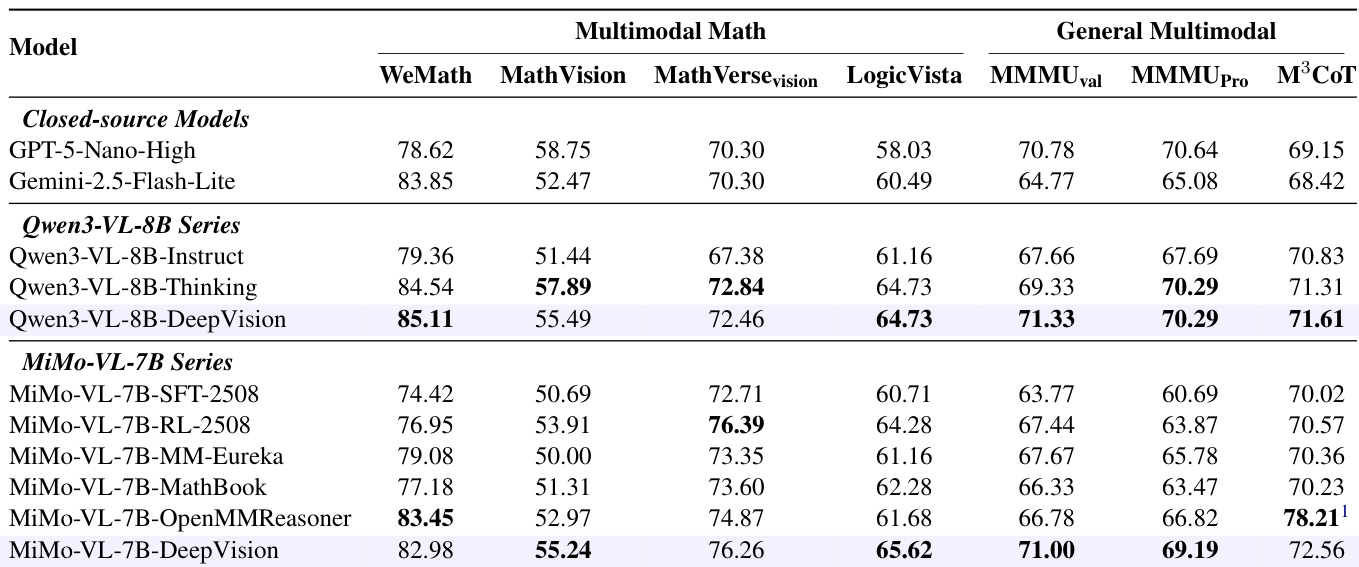
作者使用 GSPO 进行基于规则奖励的 RL 训练,并在多模态数学与通用推理基准上评估模型。结果表明,在 DeepVision 上训练持续优于基础模型与思维变体,提升归因于增强的视觉感知、反思与数学推理能力。视觉逻辑数据与已验证查询正确性的加入进一步提升了泛化性与模型可靠性。
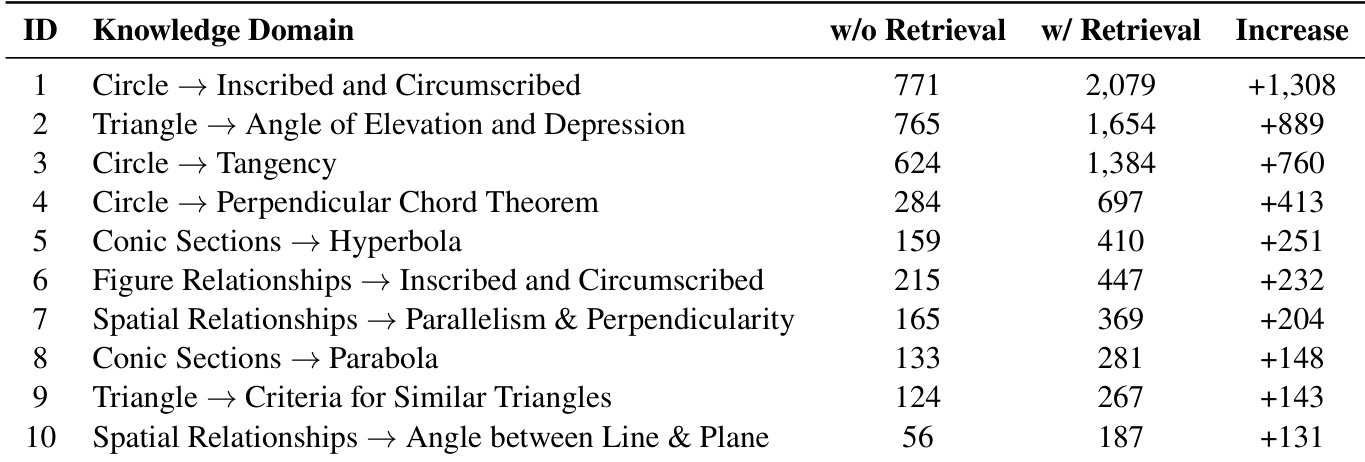
作者使用检索增强训练提升模型在几何知识领域的表现,启用检索时观察到持续增益。结果表明,引入外部知识显著提升准确率,尤其在复杂转换如“圆与内接/外接关系”中。不同领域提升幅度各异,表明检索在需概念衔接的领域效果最显著。
在 DeepVision 数据上训练持续提升多个基准测试中的数学与通用多模态推理能力,优于仅在数学数据或未经验证数据上训练的模型。视觉逻辑数据的引入增强了空间推理与模式识别能力,这些能力正向迁移至数学与通用任务;而经验证的正确答案对于强化学习中的有效奖励信号至关重要。与基础模型相比,使用 DeepVision 微调的模型展现出更强的视觉感知、反思与数学推理能力。