HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

AgentVista:在超具挑战性的真实视觉场景中评估多模态 Agent

DARE:通过分布感知检索将LLM Agents与R统计生态系统对齐





























AgentVista:在超具挑战性的真实视觉场景中评估多模态 Agent
DARE:通过分布感知检索将LLM Agents与R统计生态系统对齐
SkillNet:构建、评估与连接 AI 技能
MOOSE-Star:打破复杂性壁垒,开启科学发现的可行训练新范式
SURvHTE-Bench:生存分析中异质性治疗效应估计的基准测试
PanoWan:通过经纬度感知机制将 Diffusion 视频生成模型提升至 360° 全景维度
ArtHOI:基于视频先验的 4D 重建生成可 Articulated 的人 - 物交互
Proact-VL:面向实时 AI 伴侣的主动式 VideoLLM
T2S-Bench 与思维结构:综合文本到结构推理的基准测试与提示方法
异构智能体协同强化学习
Helios:实时长视频生成模型
Valet:传统不完全信息卡牌游戏的标准化测试平台
推测性解码
利用学习进阶指导科学学习中的 AI 反馈
HoMMI:从人类示范中学习全身移动操作
密度引导的响应优化:基于隐含接受信号的社群对齐
Gravity Falls:移动设备鱼叉式网络钓鱼的域名生成算法(DGA)检测方法比较分析
从熵到复杂性(Epiplexity):重新审视计算受限智能中的信息论视角
三模态 Masked Diffusion Models 的设计空间
CHIMERA:用于可泛化LLM推理的紧凑型合成数据
RubricBench:使模型生成的评分标准与人类标准对齐
MMR-Life:为多模态多图像推理拼合真实场景
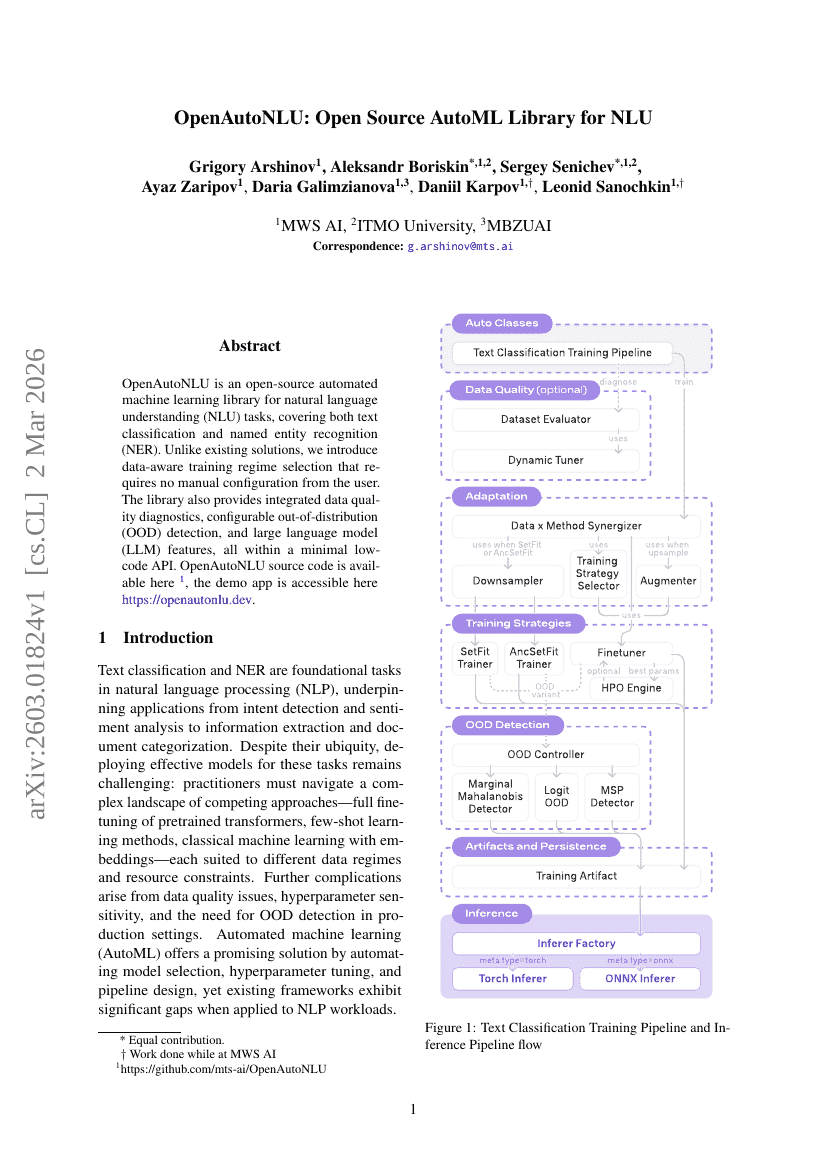
OpenAutoNLU:面向自然语言理解的开源AutoML库
OmniLottie:通过参数化 Lottie Tokens 生成矢量动画
从规模到速度:面向图像编辑的自适应测试时缩放
通过上下文共玩家推理实现 Multi-agent 协作
ACTIONENGINE:通过状态机 Memory 实现从反应式到程序化 GUI Agent 的演进
CiteAudit:你引用了它,但你读过吗?面向大语言模型时代的科学引用验证基准
模式寻找与均值寻找相结合实现快速长视频生成
CUDA Agent:面向高性能CUDA内核生成的大规模智能体强化学习
翻译复原:面向基准测试与数据集自动化翻译的高效流水线
通过奖励建模增强图像生成中的空间理解
SkillNet:构建、评估与连接 AI 技能
MOOSE-Star:打破复杂性壁垒,开启科学发现的可行训练新范式
SURvHTE-Bench:生存分析中异质性治疗效应估计的基准测试
PanoWan:通过经纬度感知机制将 Diffusion 视频生成模型提升至 360° 全景维度
ArtHOI:基于视频先验的 4D 重建生成可 Articulated 的人 - 物交互
Proact-VL:面向实时 AI 伴侣的主动式 VideoLLM
T2S-Bench 与思维结构:综合文本到结构推理的基准测试与提示方法
异构智能体协同强化学习
Helios:实时长视频生成模型
Valet:传统不完全信息卡牌游戏的标准化测试平台
推测性解码
利用学习进阶指导科学学习中的 AI 反馈
HoMMI:从人类示范中学习全身移动操作
密度引导的响应优化:基于隐含接受信号的社群对齐
Gravity Falls:移动设备鱼叉式网络钓鱼的域名生成算法(DGA)检测方法比较分析
从熵到复杂性(Epiplexity):重新审视计算受限智能中的信息论视角
三模态 Masked Diffusion Models 的设计空间
CHIMERA:用于可泛化LLM推理的紧凑型合成数据
RubricBench:使模型生成的评分标准与人类标准对齐
MMR-Life:为多模态多图像推理拼合真实场景
OpenAutoNLU:面向自然语言理解的开源AutoML库
OmniLottie:通过参数化 Lottie Tokens 生成矢量动画
从规模到速度:面向图像编辑的自适应测试时缩放
通过上下文共玩家推理实现 Multi-agent 协作
ACTIONENGINE:通过状态机 Memory 实现从反应式到程序化 GUI Agent 的演进
CiteAudit:你引用了它,但你读过吗?面向大语言模型时代的科学引用验证基准
模式寻找与均值寻找相结合实现快速长视频生成
CUDA Agent:面向高性能CUDA内核生成的大规模智能体强化学习
翻译复原:面向基准测试与数据集自动化翻译的高效流水线
通过奖励建模增强图像生成中的空间理解