Command Palette
Search for a command to run...
从感知到行动:面向视觉推理的交互式基准
从感知到行动:面向视觉推理的交互式基准
摘要
理解物理结构对于具身智能体、交互式设计以及长时程操作等现实应用场景至关重要。然而,当前主流的视觉语言模型(VLM)评估仍主要集中于与结构无关、单轮交互的设定(例如视觉问答,VQA),这类评估方式无法有效检验智能体在动态环境中对几何关系、接触关系与支撑关系等多重物理约束协同作用的理解能力,因而难以评估其推理动作可行性的能力。为弥补这一空白,我们提出了因果动作与交互层次基准(Causal Hierarchy of Actions and Interactions,简称 CHAIN),这是一个交互式、三维、基于物理引擎的测试平台,旨在评估模型是否能够基于物理约束,实现对结构化动作序列的理解、规划与执行。CHAIN 将评估范式从被动感知转向主动问题求解,涵盖的任务包括机械拼图的相互嵌合、三维物体的堆叠与空间填充等。我们在统一的交互式环境下对当前最先进的 VLM 模型及基于扩散模型的系统进行了全面评估。结果表明,即使是最优模型,仍难以充分内化物理结构与因果约束,往往无法生成可靠、长期的规划,也难以将感知到的结构信息稳健地转化为有效的动作。该项目代码与资源已开源,详情请访问:https://social-ai-studio.github.io/CHAIN/。
一句话总结
来自多个机构的研究人员推出了 CHAIN,这是一个基于物理的 3D 基准,用于评估视觉语言模型(VLM)在物理约束下规划和执行结构化动作的能力,揭示当前模型在将结构可靠转化为长期交互任务(如机械谜题)的可靠计划方面存在失败。
主要贡献
- 我们引入 CHAIN,一个交互式 3D 物理驱动基准,用于评估模型在多步物理推理任务(如互锁谜题和 3D 堆叠)中的表现,超越静态视觉问答(VQA),评估代理如何在几何、接触和支持约束下规划和调整动作。
- 我们对最先进的 VLM 和扩散模型进行统一评估,揭示了持续存在的不足:模型无法可靠地将感知到的物理结构转化为可行的长期动作序列,尤其在交互步骤中约束收紧时表现更差。
- CHAIN 提供 109 个可复现关卡,难度分级并配备标准化指标,揭示当前模型在推理隐藏 3D 约束和在长时间交互中保持稳定、物理基础计划方面存在关键差距。
引言
作者利用交互式 3D 物理环境,评估视觉语言模型和扩散模型在几何、接触和支持等物理结构推理方面的能力,以规划和执行多步动作,这对机器人操作和具身智能等现实应用至关重要。以往基准集中于静态、单轮任务(如 VQA),未能测试模型能否随约束变化调整计划或预测早期动作对未来选项的限制;扩散模型同样在忽略 3D 物理复杂性的简化 2D 设置中被评估。其主要贡献是 CHAIN,一个开源基准,包含 109 个关卡,迫使模型在真实物理约束下迭代感知、行动和修订计划,揭示即使顶级模型也难以将结构理解转化为可靠的长期动作序列。
数据集

作者使用 CHAIN 基准,其包含两个核心任务类别:谜题和堆叠,旨在评估长期推理和物理基础的操作能力。
-
数据集组成与来源:
- 谜题:32 个手工设计的互锁机械任务(10 个简单,12 个中等,10 个困难),在 Unity 中建模以强制精确的运动学和接触约束。灵感来自孔明锁、鲁班锁等设计。
- 堆叠:77 个程序化生成的 3D 空间填充任务(10 个简单,20 个中等,47 个困难),通过基于体素的算法生成,并使用基于规则的验证确保精确体积覆盖。
-
关键子集细节:
- 谜题:难度随零件数量和互锁复杂度增加。简单任务涉及 6 个零件;困难任务超过 30 个。成功要求最终配置完全匹配。
- 堆叠:难度由容器大小、物体数量和形状多样性决定。生成时受约束包括精确覆盖、6 邻域连通性、零件尺寸限制、无 2x3 平面、无孤立零件。困难模式强制零件形状唯一并提高求解努力阈值。
-
数据使用方式:
- 未指定训练集划分和混合比例;在完整基准上进行评估。
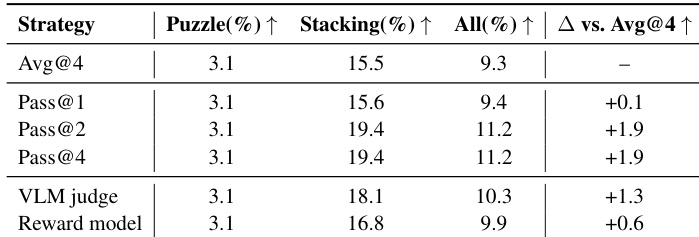
- 模型在闭环交互中评估,每实例步数限制为 30–60 步。主要指标为 Pass@1(因交互成本高),但趋势与多样本指标(Avg@4)一致。
-
处理与元数据:
- 堆叠任务通过分阶段采样生成:简单任务使用轴对齐立方体;中等任务生成平面连接零件;困难任务生成自由形态连接零件并确保形状唯一。
- 物理可行性检查包括无孤立零件和(可选)通过六轴贪婪平移的线性拆卸序列。
- 通过规范化实现强去重:每个零件归一化、旋转至 24 个方向并按字典序排序形成多重集签名(SHA1 哈希)。
- 每个接受的谜题存储为 JSON 清单(零件、解法、装配顺序、统计)和渲染的 3D 可视化。
- 生成包含回退逻辑:若严格最小零件尺寸(如 4)失败,则放宽至最小零件=3 以提高产量。
方法
作者利用结构化三阶段流程构建交互式基准,强调多步推理、物理可控性和代理行为的细粒度评估。该框架旨在超越静态问答范式,将代理嵌入动态、物理感知环境中,成功依赖于顺序规划和因果理解。
参考框架图,该图展示了端到端构建过程。流程从外部仓库(如 Puzzlemaster)获取候选谜题开始,随后进入严格筛选阶段,应用三个标准:链依赖、可行性及人类难度评估。链依赖确保谜题需要有序、因果关联的动作;可行性保证谜题可模拟稳定状态转换和可控动作空间;人类难度评估基于专家解决时间分配层级标签(简单、中等、困难)。对于算法生成而非人工筛选的堆叠任务,应用相同的人类评估协议以保持难度校准一致性。
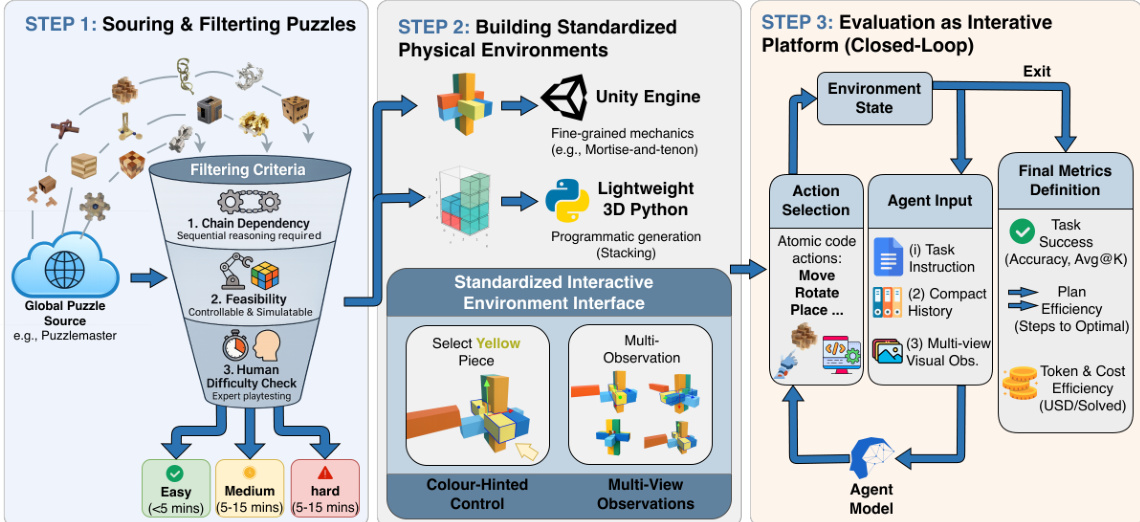
第二阶段,作者使用两个互补工具链构建标准化物理环境:Unity 用于需要精细机械交互的谜题(如孔明锁和鲁班锁),轻量级 3D Python 引擎用于动力学较简单的堆叠任务。为确保统一交互,他们实现颜色提示控制方案:每个对象分配唯一颜色,代理通过颜色选择零件而非额外控制器,避免视觉-语言-动作(VLA)接口引入的混淆变量。提供多视角观测以缓解遮挡并支持空间推理。
最终阶段将基准视为闭环协议下的交互平台。每个评估回合初始化一个任务实例,包含预定义状态(如物体姿态和约束)。在每一步 t,代理接收:(i) 指定目标的任务指令,(ii) 先前观测和动作的紧凑历史,(iii) 当前多视角视觉观测。基于这些输入,代理从预定义集合中选择原子动作(如移动、旋转、放置)。模拟器执行动作,更新环境状态,并返回步骤 t+1 的新观测。循环持续至任务解决或步数预算耗尽。评估指标从完整轨迹计算,包括任务成功率、计划效率(步数至最优)和令牌/成本效率(美元/解决),实现代理性能的多维度评估。
对于多立方体堆叠谜题,作者采用采样-验证生成流程。候选分区采样后,使用 Algorithm X 和舞蹈链(DLX)验证精确覆盖可解性,将问题简化为稀疏矩阵,其中每行代表零件放置,每列代表体素或零件使用约束。同时强制结构约束和可选线性装配可行性。去重通过刚性旋转规范零件形状并哈希结果多重集实现。
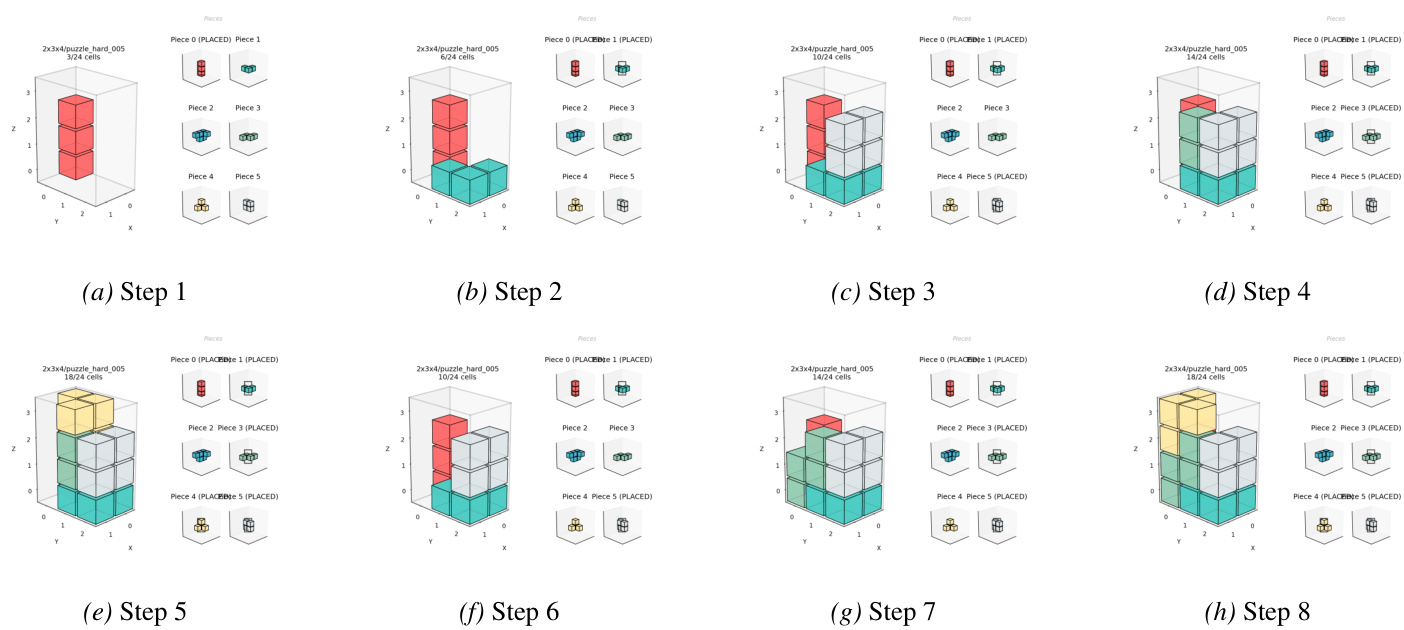
线性装配序列通过贪婪拆卸算法提取:迭代识别沿轴对齐方向可移除的零件。算法维护剩余零件集 R,每轮测试每个零件 i∈R 在六个正交方向 d∈{+x,−x,+y,−y,+z,−z} 是否可移除。若可移除,则添加至移除列表、从 R 移除并重复。若无零件可移除,则算法失败。最终装配顺序 π 通过反转移除序列获得。
该架构使代理评估不仅限于是否解决任务,还包括如何推理物理约束、规划动作序列并适应反馈——所有过程均在可复现、可控且难度校准的环境中进行。
实验
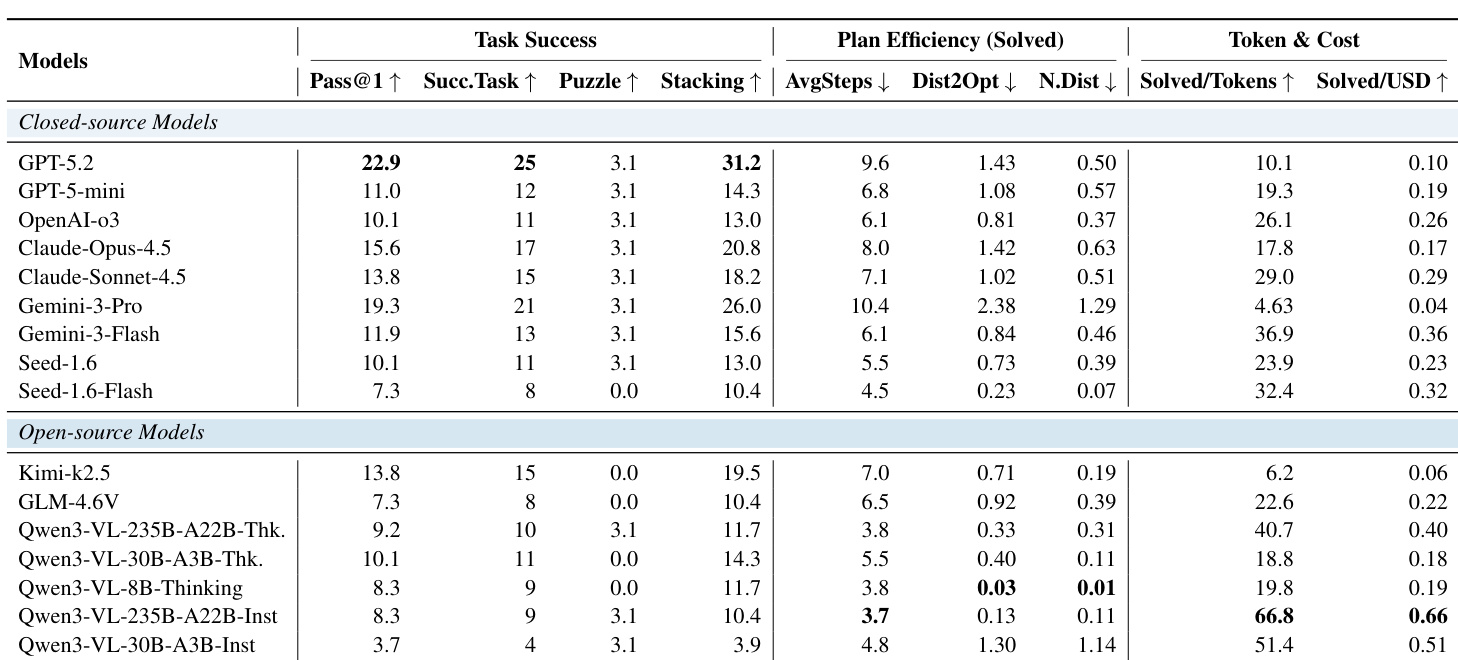
- 在任务成功率、计划效率和成本效率方面评估模型,发现较高成功率常伴随更高资源消耗和成本。
- 闭源模型如 GPT-5.2 在任务成功率上领先但成本更高;开源模型如 Kimi-k2.5 以较低成本提供中等成功率。
- 所有模型在谜题任务上仍极富挑战性,因难以推断隐藏物理约束和规划多步拆卸。
- 堆叠任务显示分层难度:简单关卡大多可解,但中等和困难关卡需全局空间规划,早期贪婪决策易导致死胡同。
- 交互显著提升性能(尤其谜题和复杂堆叠),凸显物理推理中闭环反馈的必要性。
- 世界模型在结构化物理任务上灾难性失败,产生幻觉动作并违反约束,表明对象恒常性和物理基础存在根本局限。
- 奖励模型在长期规划中收益有限;基于验证器的检查提供更可靠改进,表明选择信号质量是关键瓶颈。
- 成功的堆叠策略优先稳定基座形成和增量体积填充,失败源于早期不可逆放置导致几何死胡同。
作者在交互式物理推理基准上评估了多个闭源和开源模型,发现闭源模型通常实现更高任务成功率,但常伴随更高令牌使用量和货币成本。计划效率指标显示,即使成功执行也常包含冗余步骤,尤其在 3D 谜题等复杂任务中,模型在结构推断和约束满足方面挣扎。交互显著优于单次求解,凸显闭环反馈在应对动态物理约束中的必要性。
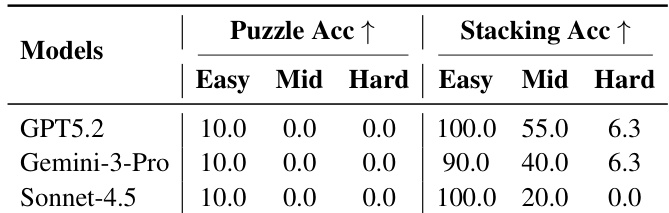
作者在结构化物理推理任务上评估多个大型模型,发现即使 GPT-5.2 和 Gemini-3-Pro 等顶级模型在简单堆叠任务上接近完美准确率,但在中等和困难级别表现显著下降,成功率骤降。谜题任务在所有难度层级均持续具挑战性,无模型在最简单级别外取得任何成功,表明处理 3D 结构推断存在根本局限。结果强调任务难度非平滑可扩展,而取决于特定推理需求(如约束传播和部分可观测下的多步规划)。
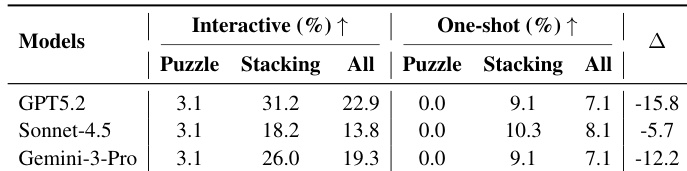
作者在交互式物理推理基准上评估多个模型,发现即使表现最佳的模型在单次设置中的成功率也显著低于交互设置,凸显反馈在解决复杂空间任务中的关键作用。结果表明,交互使挑战性 3D 谜题实现适度成功并大幅改善堆叠表现,暗示闭环适应对处理动态物理约束至关重要。更强模型从交互中获益更多,因其基于反馈修订计划的能力转化为比静态单视角方法更大的性能差距。
作者使用 Kimi-k2.5 评估不同候选选择策略,发现基于验证器的判断优于奖励模型重排序,比基线提升 +1.3,而奖励模型仅提供边际增益。多样本选择(Pass@2 和 Pass@4)提供一致但递减回报,表明选择信号质量(而非采样规模)是提升长期交互规划性能的关键瓶颈。