Command Palette
Search for a command to run...
想象力有助于视觉推理,但在潜在空间中尚未实现
想象力有助于视觉推理,但在潜在空间中尚未实现
You Li Chi Chen Yanghao Li Fanhu Zeng Kaiyu Huang Jinan Xu Maosong Sun
摘要
隐式视觉推理旨在通过多模态大语言模型的隐藏状态来模拟人类的想象过程。尽管该范式被视为视觉推理领域具有前景的方向,但其有效性的内在机制仍不清晰。为揭示其真实效能来源,本文采用因果中介分析(Causal Mediation Analysis)对隐式推理的有效性进行探究。我们将该过程建模为一个因果链:输入作为处理变量(treatment),隐式标记(latent tokens)作为中介变量(mediator),最终答案作为结果变量(outcome)。研究发现存在两个关键的断联现象:(a) 输入—隐式状态断联:对输入施加剧烈扰动时,隐式标记几乎未发生显著变化,表明隐式标记未能有效关注输入序列;(b) 隐式状态—答案断联:对隐式标记进行扰动,对最终答案的影响微乎其微,说明隐式标记对输出结果的因果作用极为有限。此外,通过广泛的探针分析(probing analysis)进一步揭示,隐式标记所编码的视觉信息极为有限,且彼此之间具有高度相似性。基于上述发现,本文质疑隐式推理的必要性,并提出一种简洁有效的替代方案——CapImagine。该方法通过显式文本引导的方式,直接教会模型进行视觉想象。在以视觉为核心的任务基准测试中,CapImagine显著优于复杂的隐空间推理基线模型,充分展现出通过显式想象实现视觉推理的卓越潜力。
一句话总结
清华大学与阿里巴巴的研究人员提出 CapImagine,一种基于文本的显式想象方法,通过绕过无效的隐状态中介,在视觉任务中超越潜在推理,揭示潜在标记的弱因果关联与有限视觉编码能力,从而重新定义高效的视觉推理。
主要贡献
- 通过因果中介分析,研究发现多模态模型中的潜在标记在因果影响上极小——无论是从输入到潜在状态,还是从潜在状态到最终答案——表明它们既未有效关注输入,也未驱动推理结果。
- 作者提出 CapImagine,一种基于文本的想象方法,通过训练模型以文本描述模拟视觉操作,替代潜在空间推理,提供更具可解释性且因果基础更扎实的替代方案。
- CapImagine 在多个基准上显著优于潜在空间基线,在 HR-Bench-8K 上提升 4.0%,在 MME-RealWorld-Lite 上提升 4.9%,证明显式文本想象在视觉推理中的有效性。
引言
作者利用因果中介分析探究多模态大语言模型中的潜在视觉推理是否如预期般运作——即通过隐状态编码并传播视觉语义。他们发现潜在标记对输入变化敏感度极低,对最终答案的因果影响可忽略,表明输入到潜在状态、潜在状态到输出的路径均出现断裂。尽管先前的潜在空间方法实证表现强劲,但缺乏可解释性且未能编码有意义的视觉信息。作为回应,作者引入 CapImagine,一种基于文本的替代方法,在训练中将视觉操作转化为显式文本描述。该方法不仅恢复了因果保真度,还在多个视觉中心基准上超越潜在空间基线,表明显式文本想象在视觉任务中比隐状态推理更有效。
数据集

-
作者以 Monet-SFT-125K 为基础数据集,并通过两种图像重写方式增强:对于 Visual-CoT 和 Zebra-CoT 子集(聚焦于放大区域),将原始问题与高亮图像区域输入 Qwen3-VL-4B,生成简洁的描述以重新聚焦视觉语义;对于 Refocus 和 CogCoM 子集(涉及图像操作如标记或绘图),将原始与操作后图像输入 Qwen3-VL-4B,提示其描述视觉差异并口头化操作揭示的关键信息。
-
为确保重写文本顺利融入推理链,他们使用 MLLM 全局优化推理轨迹,纠正不一致并提升流畅性,使新文本描述在逻辑上与原始推理过程对齐。
-
尽管 Monet-SFT-125K 之前已过滤,Visual-CoT 子集(占数据集 94.88%)仍包含低质量实例——许多存在答案与推理不匹配或问题模糊/无法回答——因此作者通过 MLLM 自动质量过滤评估推理正确性与问题清晰度,经人工验证后仅保留 17k 高质量实例。
-
为确保与 Monet 的公平比较,他们在第 5.3 节进行消融研究以考虑数据集规模缩小的影响,并在实验中保持受控训练设置。
方法
作者采用一种称为“潜在视觉推理”的新范式,将基于 Transformer 的多模态语言模型(MLLM)的最终隐藏状态视为潜在标记,以中介视觉问答。该方法使模型在解码时动态交替生成标准文本标记与潜在标记,有效将感知推理与语言输出解耦。整体框架遵循抽象因果流 X→Z→Y,其中 X 代表图像与问题的联合输入,Z 表示潜在推理标记,Y 为最终答案。
推理时,模型在发出特殊标记 <llatent_start> 时启动潜在模式,解码 <llatent_end> 时退出。在潜在模式内,模型将自身最后隐藏状态作为下一步输入,绕过显式分词。解码规则形式化定义为:
hi=M(E(x);y<i),y0=∅ yi=I(i∈IL)⋅ϕ(hi)+I(i∈/IL)⋅E(Decode(hi))其中 IL 索引潜在标记位置,ϕ(hi) 为可选投影,E(⋅) 将隐藏状态映射到嵌入。该机制允许模型内部模拟视觉操作——如画线或高亮区域——而不输出中间文本,从而保持推理保真度。
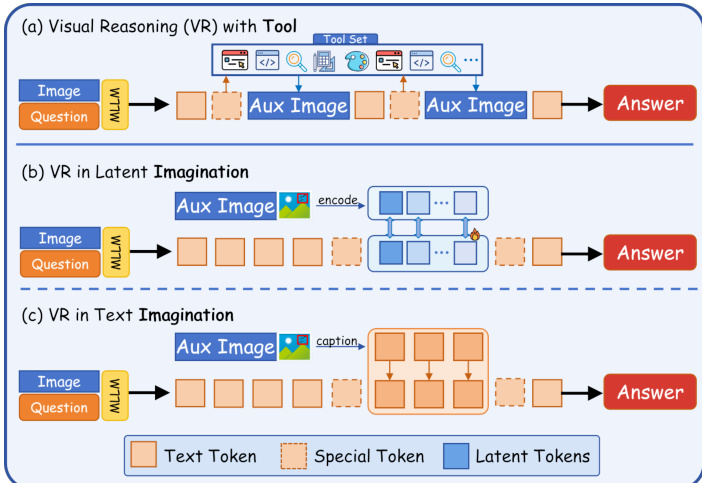
参考框架图,图中展示三种不同的视觉推理模式:(a) 带工具的 VR,外部工具生成辅助图像;(b) 潜在想象中的 VR,潜在标记编码内部视觉模拟;(c) 文本想象中的 VR,推理以描述性标题形式表达。作者聚焦于潜在想象路径,该路径避免显式调用工具,而是依赖模型内部表示空间执行视觉操作。
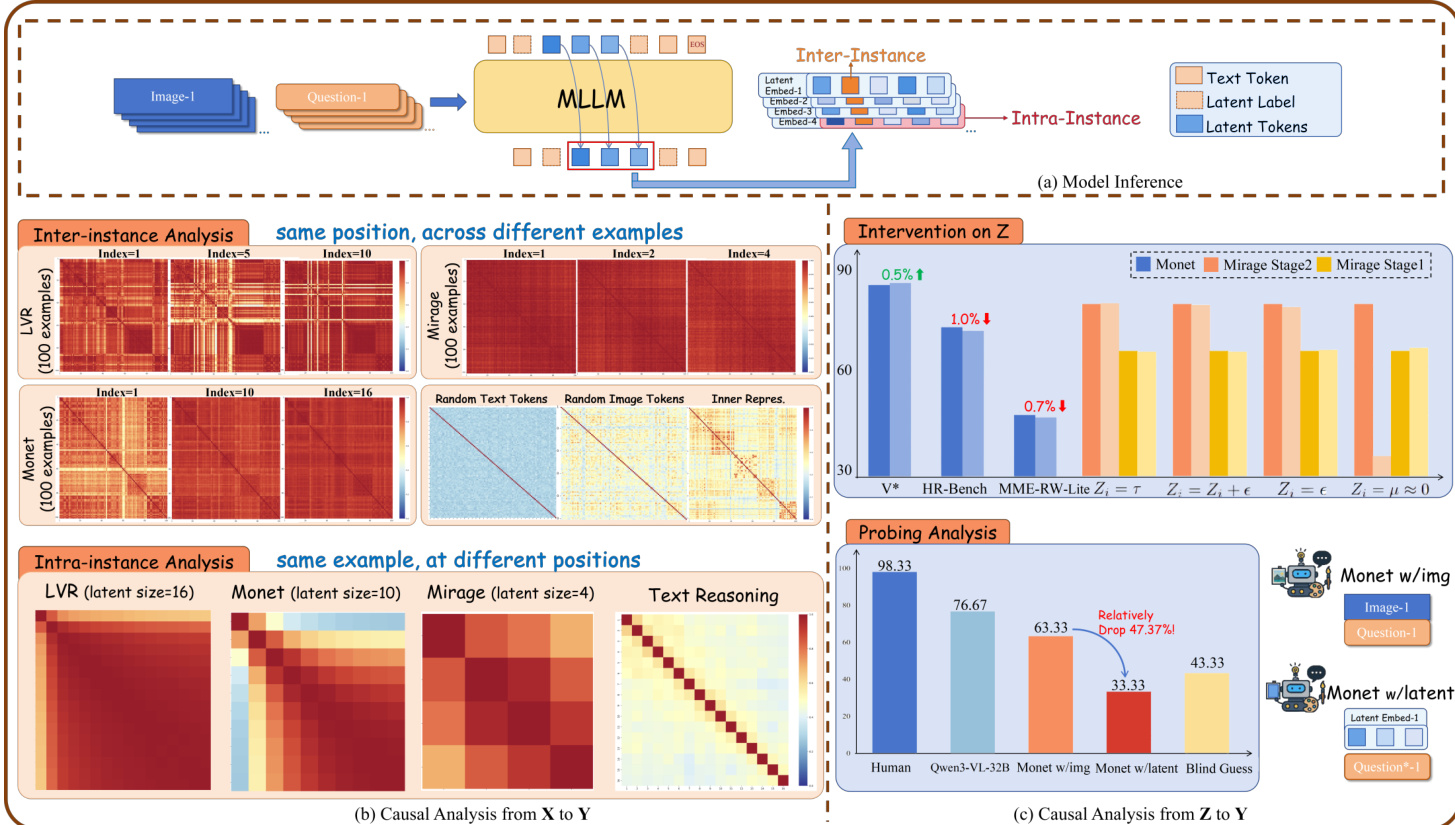
如图所示,模型推理架构将图像与问题输入整合进 MLLM,生成文本标记、特殊标记与潜在标记序列。潜在标记在实例内上下文中处理,而实例间分析则比较不同示例的潜在表示。作者对 Z 进行因果干预——如扰动潜在嵌入或替换为随机值——以量化其对最终答案准确性的贡献。探测实验进一步表明,依赖潜在标记的模型在移除这些标记时表现显著下降,凸显其在视觉推理中的关键作用。
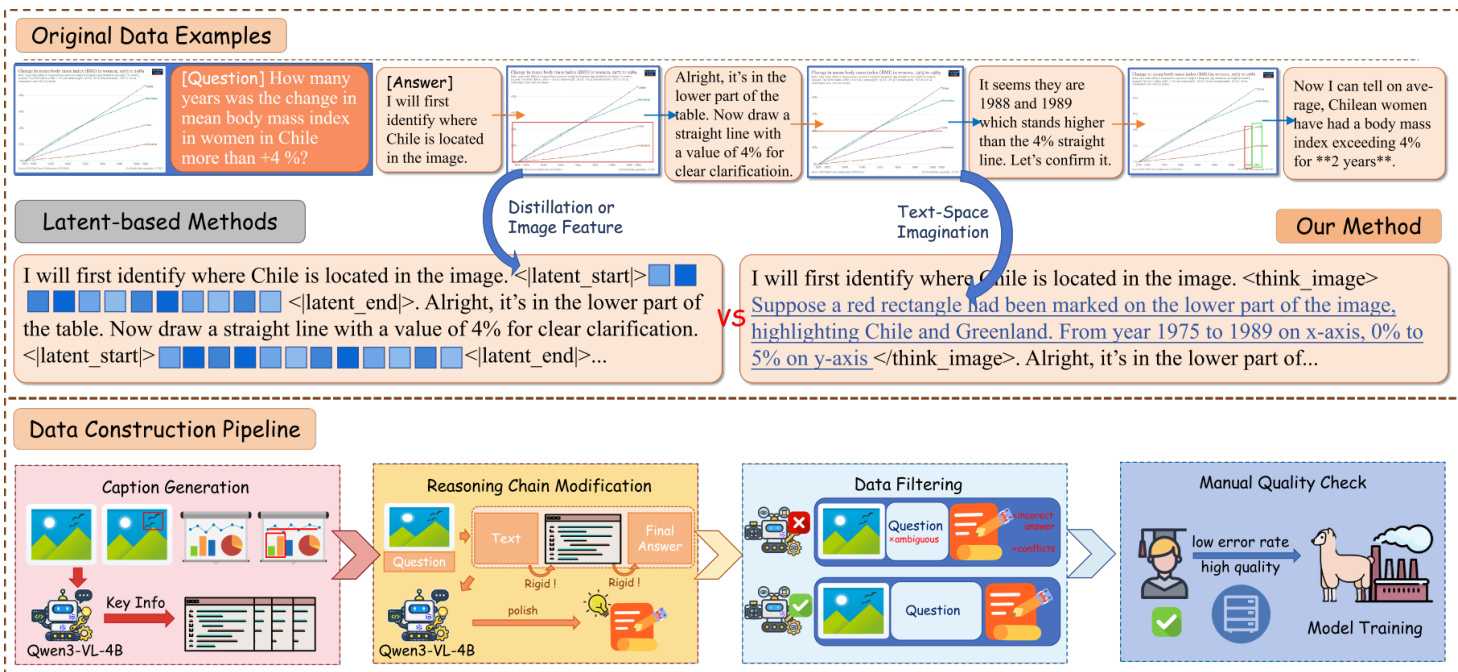
为训练与评估该范式,作者构建数据集流程:首先使用 Qwen3-VL-4B 生成描述,随后修改推理链插入潜在标记标记。数据过滤移除模糊或冲突示例,人工质量检查确保高保真度后再进行模型训练。最终方法使模型能在潜在空间内模拟视觉操作——如标记区域或画线——而非依赖外部工具或冗长文本描述。这与基于潜在空间的基线形成对比,后者要么蒸馏图像特征,要么进行文本空间想象,两者均缺乏潜在标记中介的精确性。
实验
- 跨模型与任务的潜在标记高度相似,推理过程中坍缩为统一表示,表明其几乎未编码输入或任务特定信息。
- 对潜在标记的干预对最终答案影响微乎其微,表明其对模型输出因果影响极小。
- 探测分析显示潜在标记编码的视觉语义有限,即使训练以捕捉视觉证据,仍不足以准确推导答案。
- 文本驱动的视觉想象在感知与推理基准上超越潜在空间方法,展现更强因果中介与更好泛化能力。
- 消融研究证实文本想象描述至关重要;移除后性能下降,而数据过滤提升对齐性与有效性。
- 文本形式推理在输入与想象标记间表现出强因果依赖,对想象内容的干预显著降低性能。
- 尽管序列更长,文本推理的推理速度与潜在方法相当,且快于工具增强方法,提供更优的效率-性能权衡。
- 当前潜在标记更像软提示而非活跃的视觉推理载体,凸显在潜在空间中实现因果、信息性推理的差距。
结果显示,在 Monet 中大幅修改潜在标记在多个基准上仅导致微小性能变化,表明这些标记对最终答案的因果影响有限。模型似乎依赖其他路径而非潜在推理过程,即使强制潜在状态统一,输出质量也未显著下降。
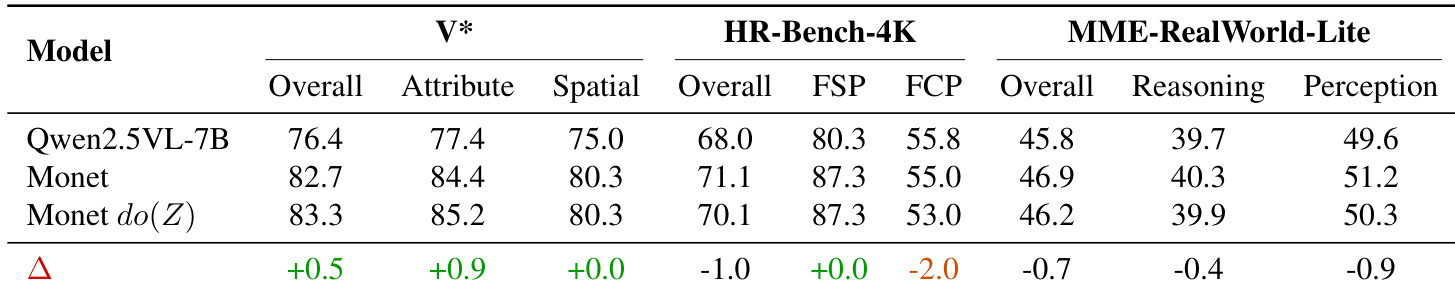
作者使用因果中介分析测试修改潜在推理标记对最终答案的影响,发现大幅干预仅导致微小性能变化。结果表明潜在标记在实例与任务间高度相似,推理中逐步坍缩为统一表示,对答案推导贡献极小。相比之下,文本推理过程展现更强因果影响与语义多样性,表明潜在标记当前更像占位符而非活跃推理载体。
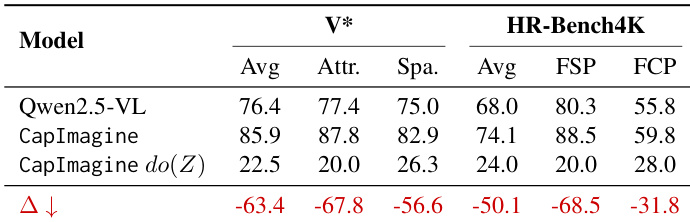
结果显示,在 Mirage 中对潜在标记进行大幅干预(如替换为噪声或接近零值)在第一阶段仅导致微小性能变化,但在第二阶段引发严重退化,表明第二阶段更依赖潜在标记完整性。作者以此论证潜在标记通常对最终输出因果影响有限,除非极端干预完全破坏模型行为。

作者采用文本驱动的视觉想象方法,在多个基准上持续优于 Monet 和 LVR 等潜在空间方法,尤其在细粒度感知与抽象推理任务中表现突出。结果显示潜在标记在实例与任务间高度相似,推理中坍缩,对最终答案因果影响极小,表明其更像占位符而非活跃推理载体。相比之下,文本想象展现强因果依赖并显著影响性能,提供更有效且高效的推理路径。
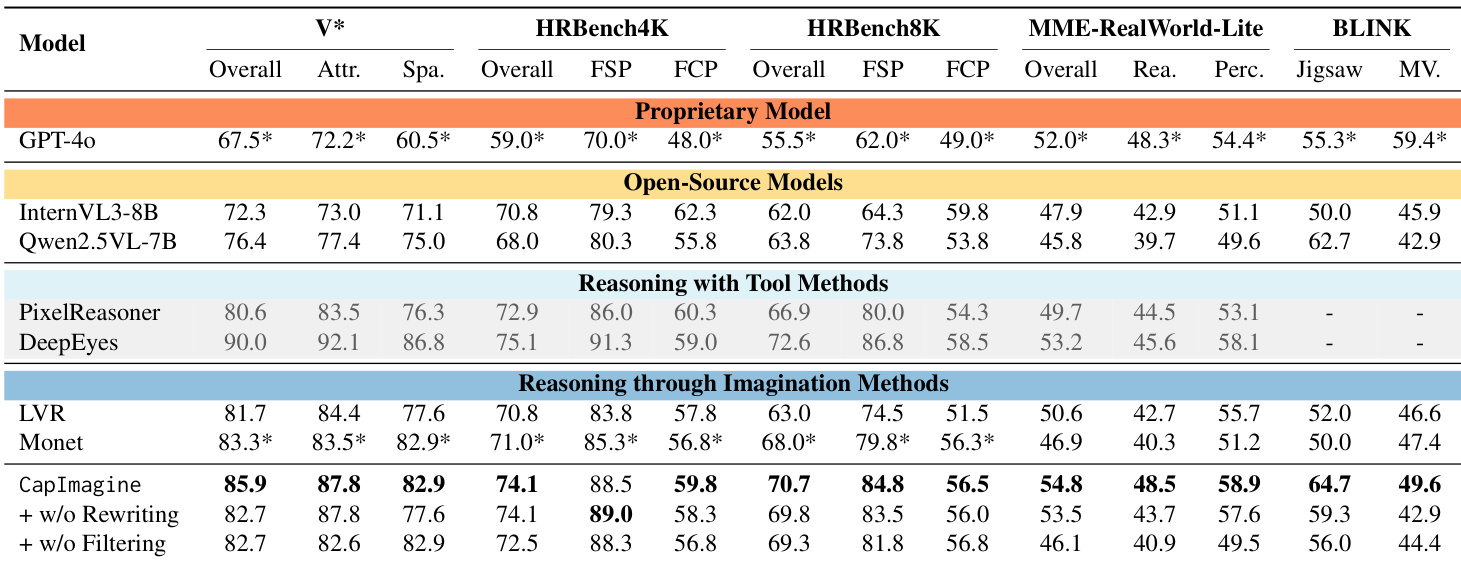
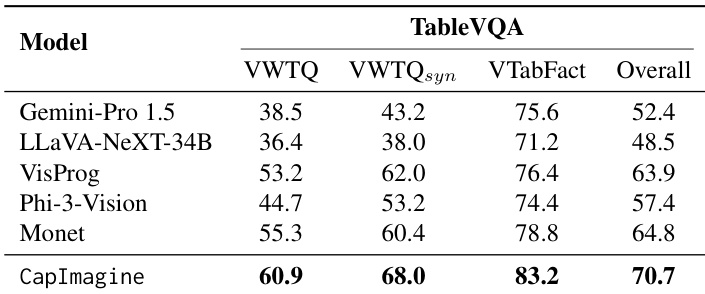
CapImagine 在 TableVQA 基准上超越所有对比模型,在所有子类别与总体得分上均最高。结果表明文本驱动的视觉想象在需要结构化推理的表格数据任务中提升性能。这表明对于此类视觉推理挑战,显式文本推理路径可能比潜在空间方法更有效。