Command Palette
Search for a command to run...
基于混合在线与离线策略优化的探索性记忆增强型LLM Agent
基于混合在线与离线策略优化的探索性记忆增强型LLM Agent
Zeyuan Liu Jeonghye Kim Xufang Luo Dongsheng Li Yuqing Yang
摘要
探索能力仍是采用强化学习训练的大语言模型智能体面临的核心瓶颈。尽管以往方法利用预训练知识,但在需要发现新状态的环境中表现不佳。为此,我们提出了一种混合强化学习框架——探索性记忆增强的在线与离线策略优化(Exploratory Memory-Augmented On- and Off-Policy Optimization, EMPO²)。该框架通过引入记忆机制提升探索能力,并融合在线与离线策略更新机制,使大语言模型在具备记忆能力时表现优异,同时在无记忆条件下仍具备良好的鲁棒性。在ScienceWorld和WebShop两个基准任务上,EMPO²相较于GRPO分别实现了128.6%和11.3%的性能提升。此外,在分布外测试中,EMPO²展现出卓越的适应新任务的能力,仅需少量试错即可完成任务迁移,且无需参数更新。这些结果表明,EMPO²是一种极具前景的框架,有助于构建更具探索性与泛化能力的大语言模型智能体。
一句话总结
微软研究院与KAIST的研究人员提出了EMPO²,这是一种混合强化学习框架,通过记忆增强探索与双策略更新提升大语言模型代理的适应能力,在ScienceWorld上比GRPO高出128.6%,在WebShop上高出11.3%,且在新任务中仅需极少试验次数。
主要贡献
- EMPO²通过引入结合在线与离线学习及记忆增强探索的混合强化学习框架,解决了大语言模型代理的探索瓶颈,使其能够发现超越预训练知识的新状态。
- 该方法在训练过程中动态更新参数化策略权重与非参数化记忆,使代理即使在部署时无记忆可用,仍能引导探索并提高鲁棒性。
- 在ScienceWorld和WebShop上的评估表明,EMPO²分别比GRPO提升128.6%和11.3%,并展现出强大的分布外适应能力——仅需极少试验且无需参数更新,验证了其泛化能力。
引言
作者利用强化学习提升大语言模型代理在陌生环境中探索的能力,解决当前多数代理过度依赖预训练知识、无法系统探索新状态的关键问题。以往的记忆增强方法虽能改善短期适应,但因参数固定而停滞;而GRPO等在线强化学习方法则因探索不足难以跳出局部最优。他们的主要贡献是EMPO²——一种混合在线与离线策略的算法,能联合更新模型参数与外部记忆,实现持续探索、更快收敛,并在ScienceWorld和WebShop等任务中展现强大的少样本泛化能力。
数据集
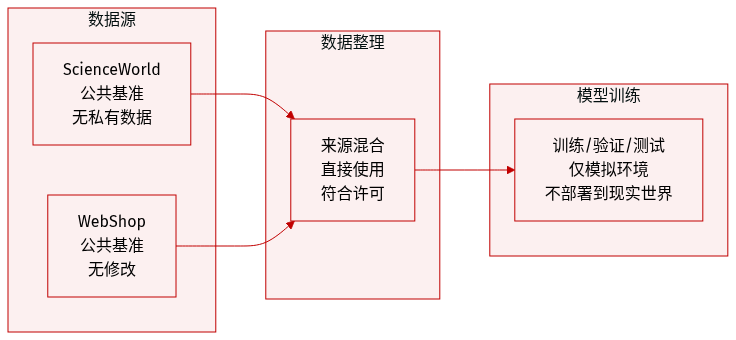
- 作者在ScienceWorld和WebShop两个公开研究基准上评估EMPO²,这两个数据集不含任何私有或敏感数据。
- 两个数据集均原样使用,未作修改或额外数据收集;所有使用均符合原始许可证与社区标准。
- 研究限于模拟环境,以避免在安全关键的实际场景中部署在线强化学习系统所带来的风险。
- 对于实际应用,作者强调大语言模型生成的响应必须经过更严格的审查以确保安全性。
- 未提及任何数据集特定的预处理、裁剪或元数据构建;重点是在现有环境中进行基准评估。
方法
作者采用一种称为“探索性记忆增强在线与离线策略优化”(EMPO²)的混合学习框架,以应对大语言模型在线强化学习中的探索挑战。该方法结合参数化更新(通过策略梯度优化)与非参数化更新(通过存储自生成反思提示的外部记忆缓冲区),使代理能从过去经验中学习,同时逐步将指导内化至策略参数中。
EMPO²的核心是一个记忆缓冲区 M,用于存储策略 πθ 在每轮结束后自动生成的提示。当一轮结束时,策略被提示反思最终状态与任务,生成如“你关注了红灯泡但未完成点亮它的任务”之类的提示。这些提示被存入记忆,并在后续 rollout 中被检索以指导动作生成。检索操作符 Retr(st;M) 依据当前状态 st 从记忆中选取最多10条最相关的提示,通常通过嵌入空间中的余弦相似度实现。这种记忆增强提示使代理能避免重复错误并探索新策略。
参考框架图,该图展示了通过组合两种 rollout 模式与两种更新模式所启用的三种学习模式。第一种模式中,代理在无记忆情况下进行提示,仅基于当前状态与任务生成动作:at+1∼πθ(⋅∣st,u)。第二种模式使用记忆增强提示:at+1∼πθ(⋅∣st,u,tipst)。在更新阶段,来自记忆增强 rollout 的轨迹可通过两种方式处理:在线策略更新(使用与 rollout 相同的提示)或离线策略更新(移除提示,基于无条件分布 πθ(⋅∣st,u) 更新策略)。
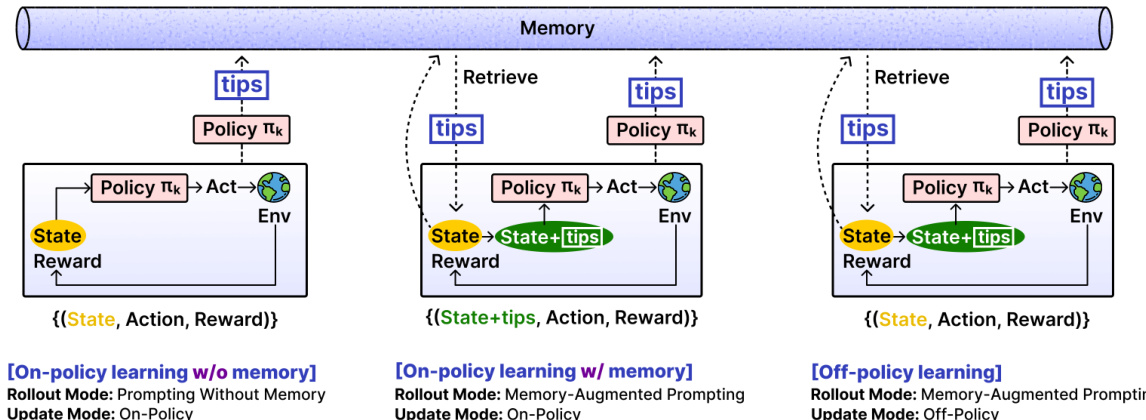
离线策略更新模式对知识内化尤为关键,其功能类似一种奖励引导的知识蒸馏:在提示条件下采样的轨迹作为教师示范,而学生策略 πθ(⋅∣s,u) 被更新以复现高优势动作并抑制低优势动作。重要性采样比率 ρθ 相应调整:对于离线策略更新,旧策略在提示条件下的对数概率被替换为当前无条件策略下的对数概率。这种不匹配使基础策略能在推理时无需提示即可吸收提示指导的好处。
为稳定易发生梯度爆炸的离线策略训练,作者引入掩码机制:在 πθ(⋅∣st,u) 下概率低于阈值 δ 的标记被排除在优势加权损失之外。修改后的GRPO损失变为:
Eu∼p(U){τ(i)}∼πθold[NT1∑i=1N∑t=1Tmin(ρθ(i,t)A(at(i)),clip(ρθ(i,t),1−ϵ,1+ϵ)A(at(i)))⋅1πθ(at(i)∣st(i),u)≥δ]−βDKL(πθ(⋅∣u)∥πref(⋅∣u)),其中 ρθ(i,t)=πθold(at(i)∣st(i),u,tipst)πθ(at(i)∣st(i),u) 适用于离线策略更新。
为进一步鼓励探索,EMPO²引入基于状态新颖性的内在奖励。一个记忆列表存储不同状态,对每个新状态,计算其与现有条目的余弦相似度。若相似度低于阈值,则将该状态加入记忆并赋予内在奖励 rintrinsic=n1,其中 n 为相似历史状态数。该机制即使在无外在奖励时也能促进新状态探索,并有助于维持策略熵。
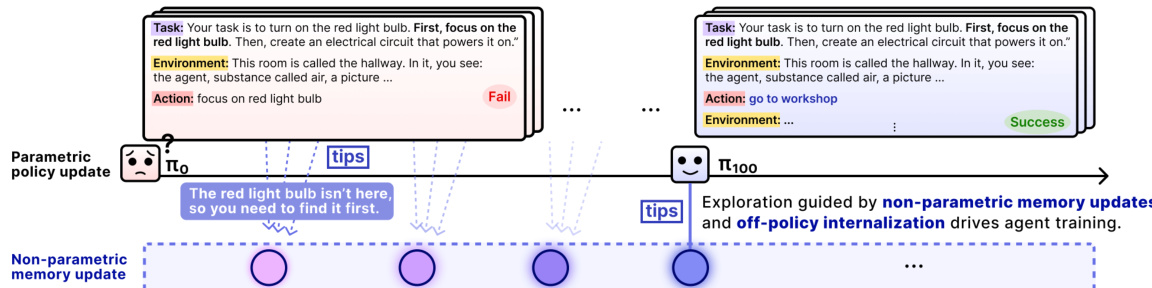
如下图所示,代理的学习轨迹从初始失败演变为成功完成任务,由非参数化记忆更新与离线策略内化引导。初始策略 π0 可能无法定位红灯泡,但在反思并存储如“红灯泡不在此处,需先找到它”等提示后,后续策略如 π100 能利用这些提示更有效探索并最终成功。
整体架构实现为多步 rollout 与交替策略更新。每个训练迭代中,代理采样任务,在记忆增强或无记忆提示下执行 rollout,生成并存储提示,然后使用三种学习模式之一更新策略。记忆缓冲区实现为快速可检索的键值存储,支持余弦相似度搜索与固定容量,确保 rollout 期间高效访问相关提示。
实验
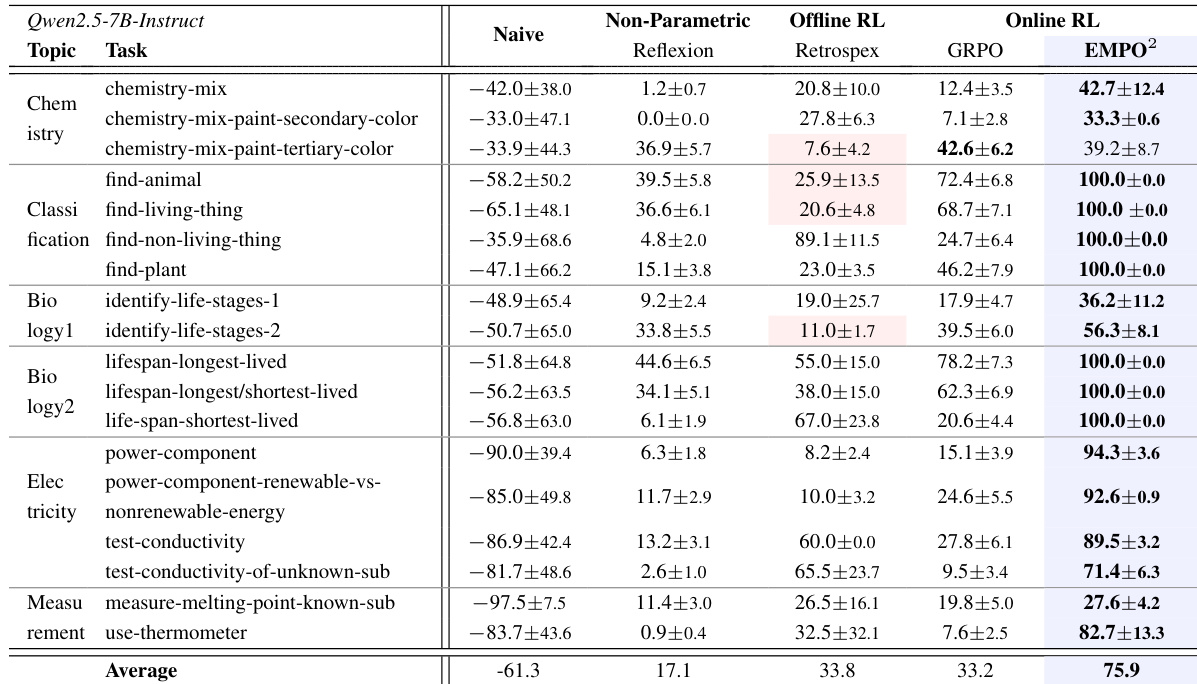
- EMPO²通过结合记忆增强的在线与离线学习显著提升大语言模型代理的探索与泛化能力,在ScienceWorld和WebShop上优于GRPO、Reflexion和Retrospex等基线方法。
- 在ScienceWorld中,EMPO²性能提升超过GRPO两倍以上,掌握复杂多步任务并在多个案例中达到满分,展现出强大的长期规划与假设检验能力。
- 在WebShop上,EMPO²超越包括GiGPO在内的所有基线,因增强的网页导航与决策探索能力而实现更高的成功率与得分。
- EMPO²通过记忆更新快速适应新任务,在多个领域10步内平均提升136%,而GRPO表现不稳定或退化。
- 消融实验确认在线策略记忆与离线策略更新均不可或缺;移除任一均导致性能下降,凸显其在稳定高效学习中的互补作用。
- 内在奖励对防止策略崩溃与鼓励探索至关重要,尽管其具体形式或尺度主要影响学习速度,而非最终性能。
- 记忆集成带来适度计算开销(约19% rollout 时间),但显著提升学习效率,整体上EMPO²仍比GRPO更省时。
作者使用EMPO²通过结合记忆增强探索与混合在线/离线强化学习来增强大语言模型代理。结果表明,EMPO²在ScienceWorld任务中持续优于基线方法,获得更高平均回报并解决此前失败的任务。该框架还展现出强大泛化能力,通过极少记忆更新即可快速适应新任务,且无需参数更改。
作者使用EMPO²通过结合记忆增强探索与混合在线/离线强化学习来增强大语言模型代理。结果表明,EMPO²在ScienceWorld和WebShop上均优于所有基线,获得更高分数与成功率,同时展现出对新任务的更强适应能力——仅需极少记忆更新。该框架的有效性源于其组件的互补作用,实现更快收敛与更鲁棒的泛化,且适应过程无需参数更新。
