Command Palette
Search for a command to run...
DreamID-Omni:面向可控以人为中心的音视频生成统一框架
DreamID-Omni:面向可控以人为中心的音视频生成统一框架
Xu Guo Fulong Ye Qichao Sun Liyang Chen Bingchuan Li Pengze Zhang Jiawei Liu Songtao Zhao Qian He Xiangwang Hou
摘要
近年来,基础模型的快速发展彻底革新了音视频联合生成技术。然而,现有方法通常将以人为中心的任务——包括基于参考的音视频生成(R2AV)、视频编辑(RV2AV)以及音频驱动的视频动画(RA2V)——视为相互独立的目标。此外,在单一框架内实现对多个角色身份与语音音色的精确、解耦控制,仍是尚未解决的开放性挑战。本文提出DreamID-Omni,一种统一的可控人像音视频生成框架。具体而言,我们设计了一种对称条件扩散变换器(Symmetric Conditional Diffusion Transformer),通过对称条件注入机制,有效整合异构的条件信号。为解决多人物场景中普遍存在的身份-音色绑定失败与说话人混淆问题,我们引入双层级解耦策略:在信号层面采用同步RoPE(Synchronized RoPE),确保注意力空间中的刚性绑定;在语义层面则引入结构化描述(Structured Captions),建立显式的属性-主体映射关系。此外,我们提出一种多任务渐进式训练方案,利用弱约束的生成先验来正则化强约束任务,有效防止过拟合,并协调不同目标之间的冲突。大量实验表明,DreamID-Omni在视频、音频及音视频一致性等多个维度上均达到全面领先的性能表现,甚至超越当前主流的商业专有模型。我们将开源代码,旨在弥合学术研究与商用级应用之间的鸿沟。
一句话总结
清华大学与字节跳动智能创作实验室的研究人员提出了 DreamID-Omni,这是一个统一框架,采用对称条件扩散Transformer与双层级解耦策略,实现精确的多角色音视频生成,在性能上超越商业模型,同时推动学术与工业的对齐。
主要贡献
- DreamID-Omni 引入了一个统一的对称条件扩散Transformer框架,可同时支持基于参考的音视频生成、视频编辑和音频驱动动画,克服了以往任务专用方法的碎片化问题。
- 为解决多人场景中身份-音色绑定失败的问题,该框架采用双层级解耦策略:使用同步RoPE实现信号层级对齐,结构化字幕实现语义层级属性映射。
- 通过多任务渐进式训练方案逐步引入约束任务,DreamID-Omni 在视频、音频及音视频一致性方面达到当前最优性能,超越主流专有模型。
引言
作者利用扩散模型在音视频生成方面的最新进展,解决以人物为中心的任务碎片化问题——包括基于参考的生成、视频编辑和音频驱动动画——这些问题此前由孤立模型分别处理。先前工作在多人场景中难以实现身份-音色绑定,且缺乏可灵活切换任务而无需改变架构的统一模型。DreamID-Omni 引入对称条件扩散Transformer,将参考图像、音色、驱动音频等异构输入融合进共享潜在空间,实现任务无缝切换。为解决说话人混淆问题,采用双层级解耦:Syn-RoPE 实现刚性信号层级绑定,结构化字幕实现显式语义映射。多任务渐进式训练策略进一步协调弱约束与强约束目标,在保持视频、音频及跨模态一致性高保真度的同时避免过拟合——甚至超越主流商业模型。
数据集
-
作者使用 IDBench-Omni,这是一个包含200个高质量测试样本的新基准,分为三组:100组身份-音色-字幕三元组用于生成,50个遮罩视频用于可控编辑,50个驱动音频用于音频驱动动画——全部设计用于压力测试多人、真实场景和跨模态控制情形。
-
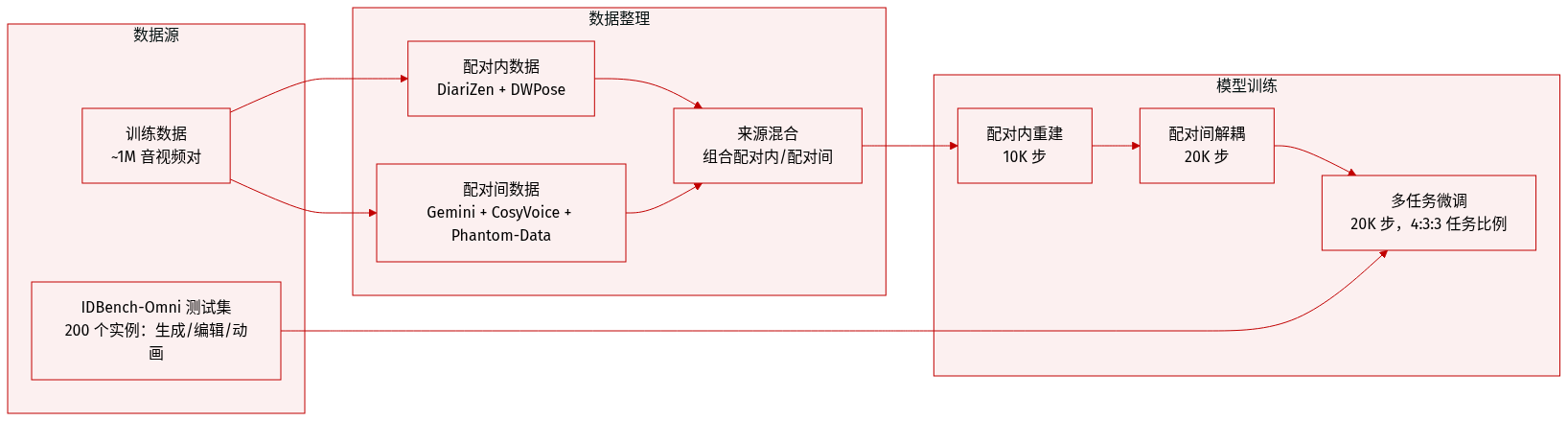
训练数据来自约100万对音视频数据,分两个阶段构建:配对内数据使用 DiariZen 进行说话人分割以提取音色参考,使用 DWPose 裁剪人脸区域作为身份参考;配对外数据利用 DiariZen 和 Gemini 标注多说话人片段,再使用 CosyVoice 和 ClearerVoice 生成干净的克隆语音,视频身份则遵循 Phantom-Data 流程。
-
训练从配对内重建(10K步)开始,随后是配对外解耦与全任务微调(各20K步)。最终阶段,数据按4:3:3的比例采样用于R2AV、RV2AV和RA2V任务,全局批大小为32,学习率为1e-5。
-
评估指标涵盖视频(AES、ViCLIP文本-视频相似度、ArcFace ID-Sim)、音频(AudioBox-Aesthetics PQ、CLAP语义一致性、Whisper WER、WavLM T-Sim)和音视频同步(SyncNet Sync-C/D)。多人场景中的说话人混淆由 Gemini-2.5-Pro 使用结构化提示判断。
方法
作者采用统一的概率框架,建模在给定文本提示 T、参考身份 I 和参考音色 A 条件下同步音视频流的生成。为支持参考生成(R2AV)、编辑(RV2AV)和动画(RA2V)任务间的灵活切换,框架可选地引入源视频上下文 Vsrc 和驱动音频流 Adri,建模联合分布 P(Y∣T,I,A,Vsrc,Adri)。该条件结构通过切换结构输入的存在性实现任务无缝过渡,如附带的任务统一表所示。
参考框架图,图中展示了 DreamID-Omni 的核心架构:一个具有对称条件和双向交叉注意力的双流扩散Transformer(DiT)。视频和音频流并行运行,各自通过一系列DiT块处理其对应的潜在表示。这些块通过交叉注意力层互连,以强制模态间细粒度的时间同步和语义对齐。该架构通过统一潜在空间处理异构输入——身份参考、结构上下文和文本提示。
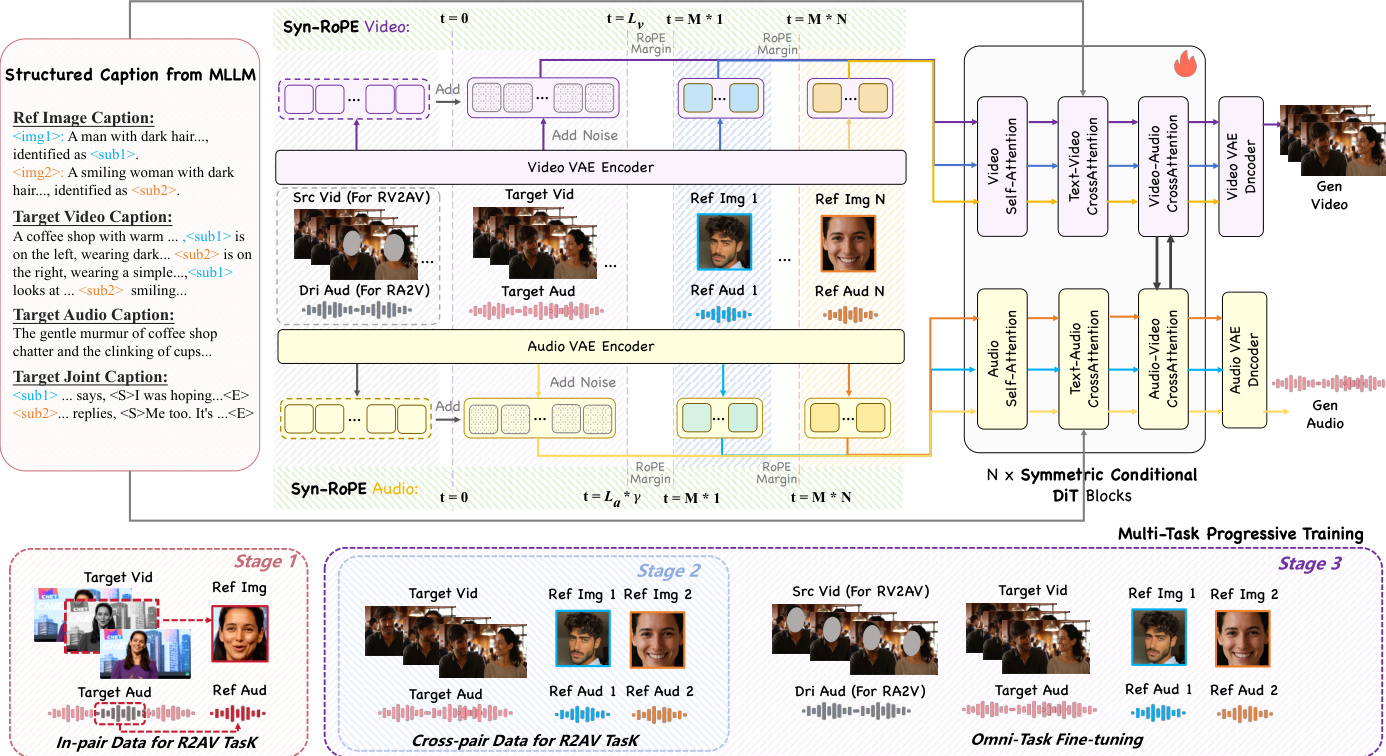
关键创新是对称条件DiT,其构造具有结构对称性的条件信号。令 zv 和 za 表示带噪目标视频和音频潜在表示。模型通过将参考特征与带噪潜在表示拼接,并通过逐元素操作添加结构上下文,构建两个条件序列 Xv 和 Xa:
Xv=[zv;Ev(I)]+[Ev(Vsrc);0Ev(I)]Xa=[za;Ea(A)]+[Ea(Adri);0Ea(A)]这种双重注入策略将身份保持与结构引导解耦,使模型无需更改架构即可自适应切换任务。当结构输入缺失时,加法项消失,有效退化为R2AV模式。
为解决多人场景中的身份-音色纠缠问题,作者引入双层级解耦策略。在信号层级,Syn-RoPE 在注意力空间中为每个参考身份分配不同的时序位置段。目标视频和音频潜在表示占据初始范围 [0,L−1],而每个身份 k 分配保留段 [k⋅M,(k+1)⋅M−1],其中 M≫L。该设计通过旋转子空间分离确保身份间解耦,并通过将同一身份的视觉与声学特征映射到相同位置槽实现身份内同步。在语义层级,结构化字幕将每个参考身份 Ik 与唯一锚点标记 ⟨subk⟩ 绑定,该标记在视频、音频和联合字幕字段中一致使用,以解决属性-内容错配问题。
训练通过三阶段多任务渐进策略进行。第一阶段“配对内重建”,使用掩码重建损失训练R2AV任务,防止复制并鼓励合成。损失仅计算在潜在表示的未掩码区域,定义为:
Linpair=Ez,t,C[λv∥(1−Mv)⊙(ϵv−e^θ(zv,t,t,C))∥22+λa∥(1−Ma)⊙(ϵa−e^θ(za,t,t,C))∥22]第二阶段“配对外解耦”,从不同片段中提取身份和音色参考,以强制抽象概念学习,损失在完整流上计算,掩码置零。第三阶段“全任务微调”,通过混合R2AV、RV2AV和RA2V样本数据集统一所有任务,使模型可根据输入条件切换模式。
在推理时,作者对每个流独立应用多条件无分类器引导策略,使用链式公式确保身份和音色引导基于文本对齐:
ϵ^final=ϵ^θ(zt,∅,∅)+wT⋅(ϵ^θ(zt,T,∅)−ϵ^θ(zt,∅,∅))+wS⋅(ϵ^θ(zt,T,S)−ϵ^θ(zt,T,∅))其中 S 对视频为 I,对音频为 A,wT、wS 为引导尺度。这确保所有模态生成稳定且一致。
实验
- 在R2AV、RV2AV和RA2V任务上验证了卓越性能,视频、音频及跨模态一致性方面优于或匹配当前最优方法。
- 展示了准确的身份-音色绑定与说话人归属,尤其在多人对话中,基线方法常出现错配与误归属。
- 消融研究证实双层级解耦(结构化字幕 + Syn-RoPE)对保持说话人身份、音色及文本对齐至关重要。
- 多任务渐进式训练被证明必不可少:从弱约束任务(R2AV)开始,再引入更严格的任务(RV2AV/RA2V),可防止过拟合并提高泛化能力。
- 定性结果与用户研究一致表明,相比基线方法,视觉质量更高、更贴合文本、音视频同步更强。
作者将他们的方法与多个当前最优基线在音视频生成任务上进行比较,表明其方法在视频质量、身份保持和音视频对齐指标上均取得领先或具竞争力的分数。结果表明,在将特定说话人与其音色绑定并保持唇形同步准确性方面表现更优,尤其在多人场景中,竞争方法常误分配语音。消融研究进一步证实,其双层级解耦和渐进训练策略对于处理复杂结构化生成任务至关重要,可避免说话人混淆或身份-音色错配。

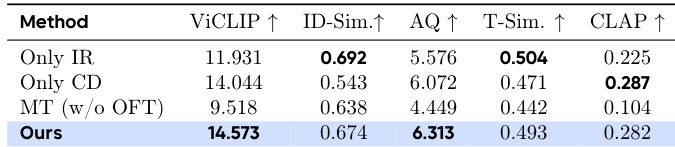
作者评估了其模型的消融变体在关键生成指标上的表现,表明完整方法在ViCLIP和AQ得分上最高,同时在身份和音色相似度上保持竞争力。移除渐进训练或解耦组件会导致文本遵循性和音视频一致性下降,证实其多阶段设计的必要性。结果表明,无任务渐进或结构化字幕的联合训练会显著损害说话人归属和指令遵循能力。
作者在RV2AV任务上将他们的方法与主流视频编辑模型进行比较,表明其方法在视频质量和身份保持指标上达到当前最优水平,同时生成高质量同步音频。结果表明,相比缺乏音频生成支持的基线,其音视频对齐和文本遵循能力更优。

作者在多人对话场景中评估其方法与消融变体,表明移除Syn-RoPE或结构化字幕会降低音色绑定和说话人身份一致性。其完整模型在视觉、音频和同步指标上得分最高,同时最小化说话人混淆。结果证实两个组件对于准确的多说话人音视频生成均至关重要。

作者在R2AV任务上通过人类评估分数从多个维度将他们的方法与多个基线进行比较。结果表明,其方法在文本-视频对齐、身份相似度、视频质量、文本-音频对齐、音色相似度、音频质量及唇形同步准确性方面得分最高,优于所有对比方法。这表明其在生成连贯、身份一致且多模态对齐的音视频内容方面整体性能更优。
