HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Parallelized Autoregressive Decoding for Omni-Modal Dense Video Captioning

Light-Omni: Reflex over Reasoning in Agentic Video Understanding with Long-Term Memory
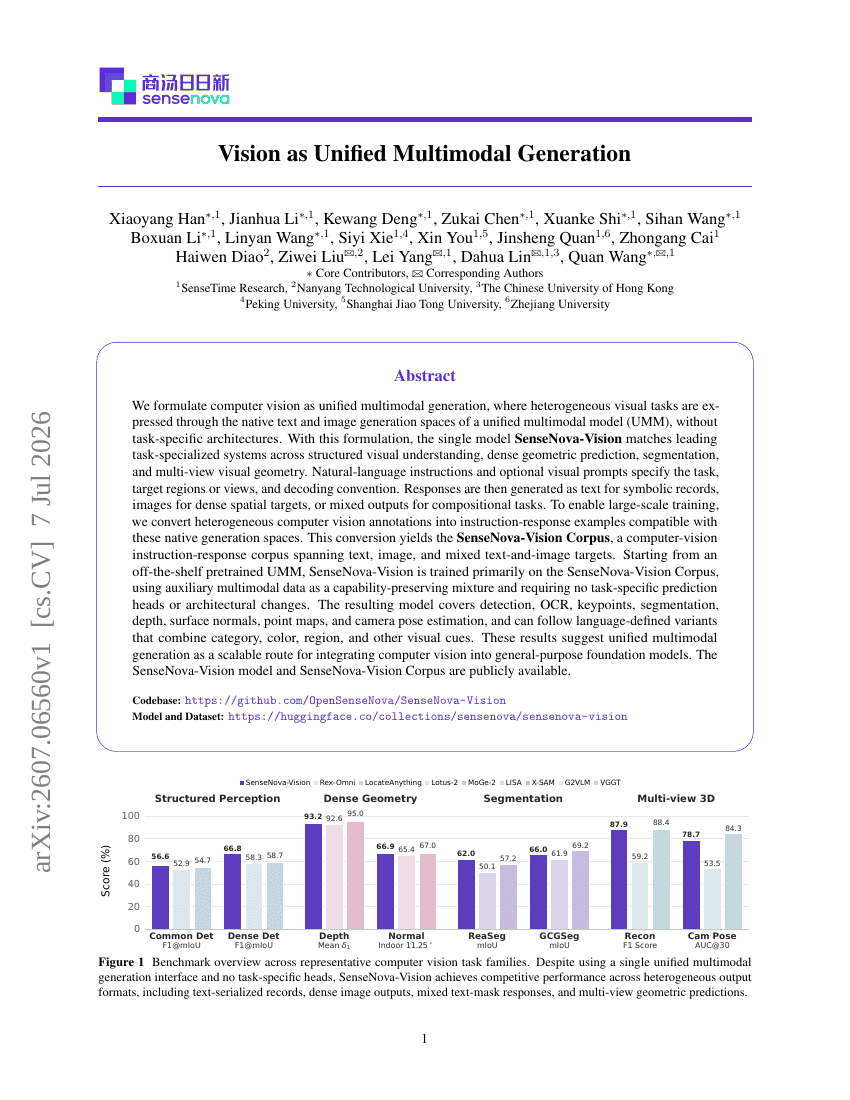
Vision as Unified Multimodal Generation
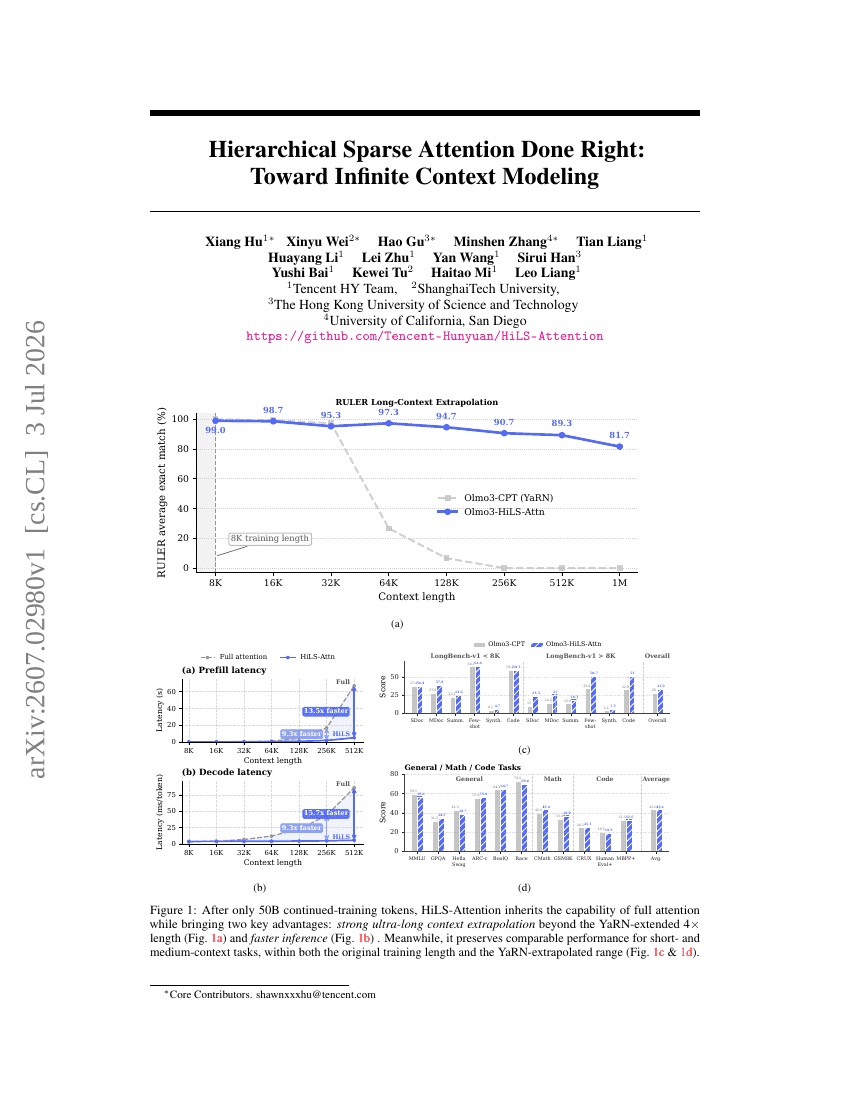
Hierarchical Sparse Attention Done Right: Toward Infinite Context Modeling

AlayaWorld: Long-Horizon and Playable Video World Generation

RynnWorld-4D: 4D Embodied World Models for Robotic Manipulation

Nemotron-Labs-3-Puzzle-75B-A9B: Compressing Hybrid MoE LLMs
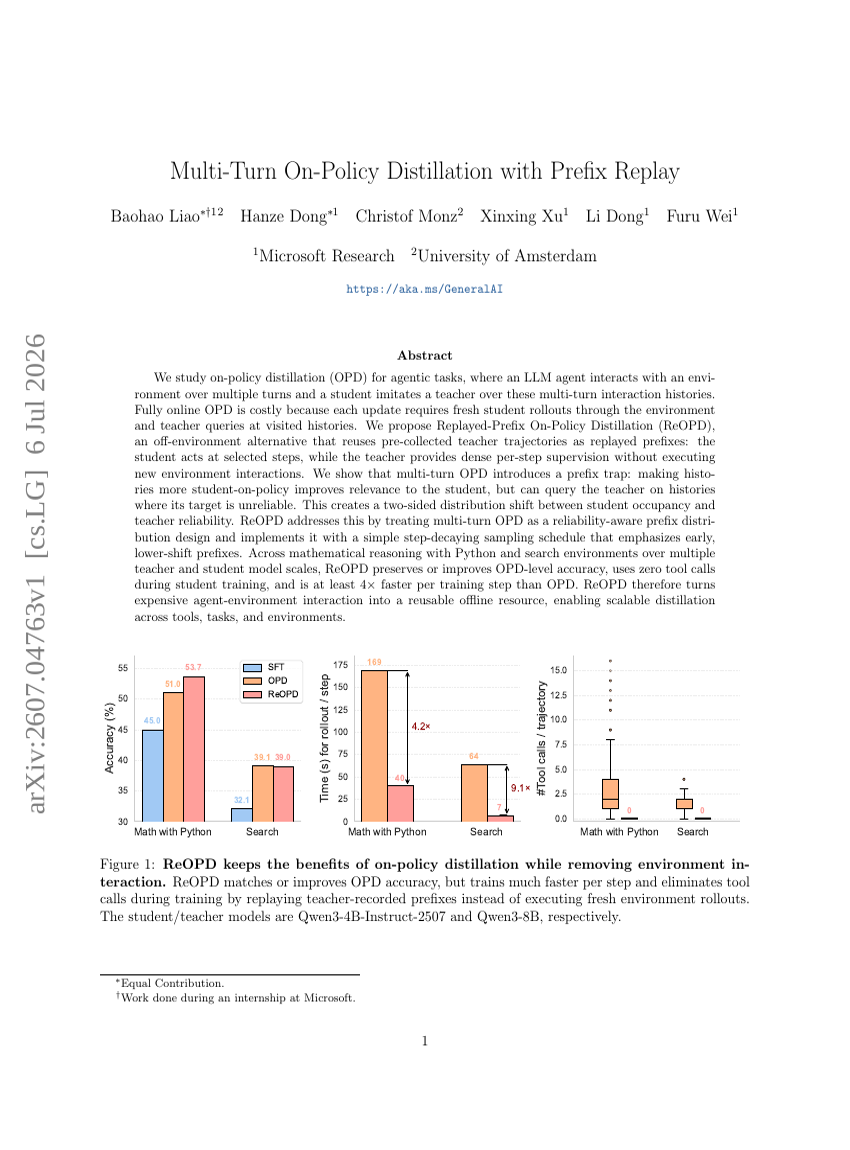
Multi-Turn On-Policy Distillation with Prefix Replay

Gemma 4 Technical Report

UI-MOPD: Multi-Platform On-Policy Distillation for Continual GUI Agent Learning

Wan-Streamer v0.2: Higher Resolution, Same Latency

EVA-Client: A Unified Framework for Deployment, Evaluation, and Data Collection on Real Robots

GigaWorld-1: A Roadmap to Build World Models for Robot Policy Evaluation
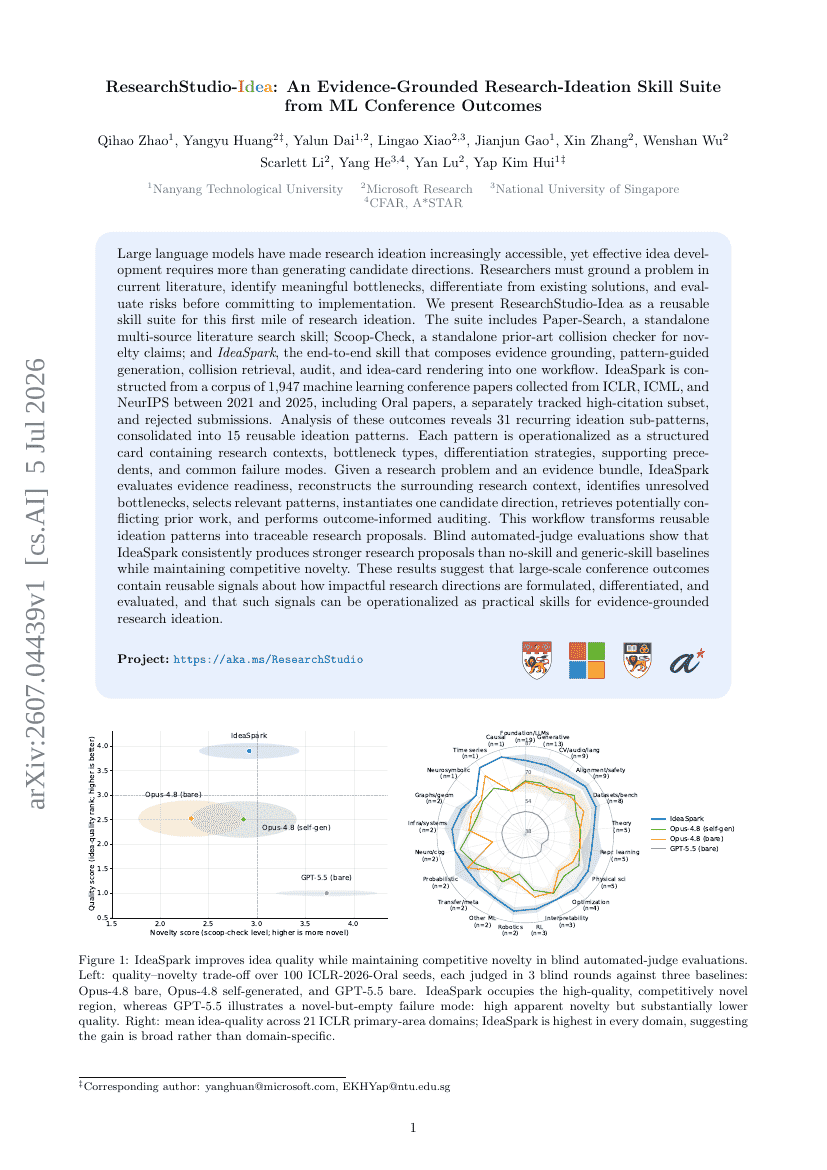
ResearchStudio-Idea: An Evidence-Grounded Research-Ideation Skill Suite from ML Conference Outcomes

ResearchStudio-Reel: Automate the Last Mile of Research from Paper to Poster, Video, and Blog

FINAL Bench: Measuring Functional Metacognitive Reasoning in Large Language Models

SceneFun3D: Fine-Grained Functionality and Affordance Understanding in 3D Scenes

TheoremGraph: Bridging Formal and Informal Mathematics

Always-On Agents: A Survey of Persistent Memory, State, and Governance in LLM Agents

Securing the AI Agent: A Unified Framework for Multi-Layer Agent Red Teaming

DataComp-VLM: Improved Open Datasets for Vision-Language Models
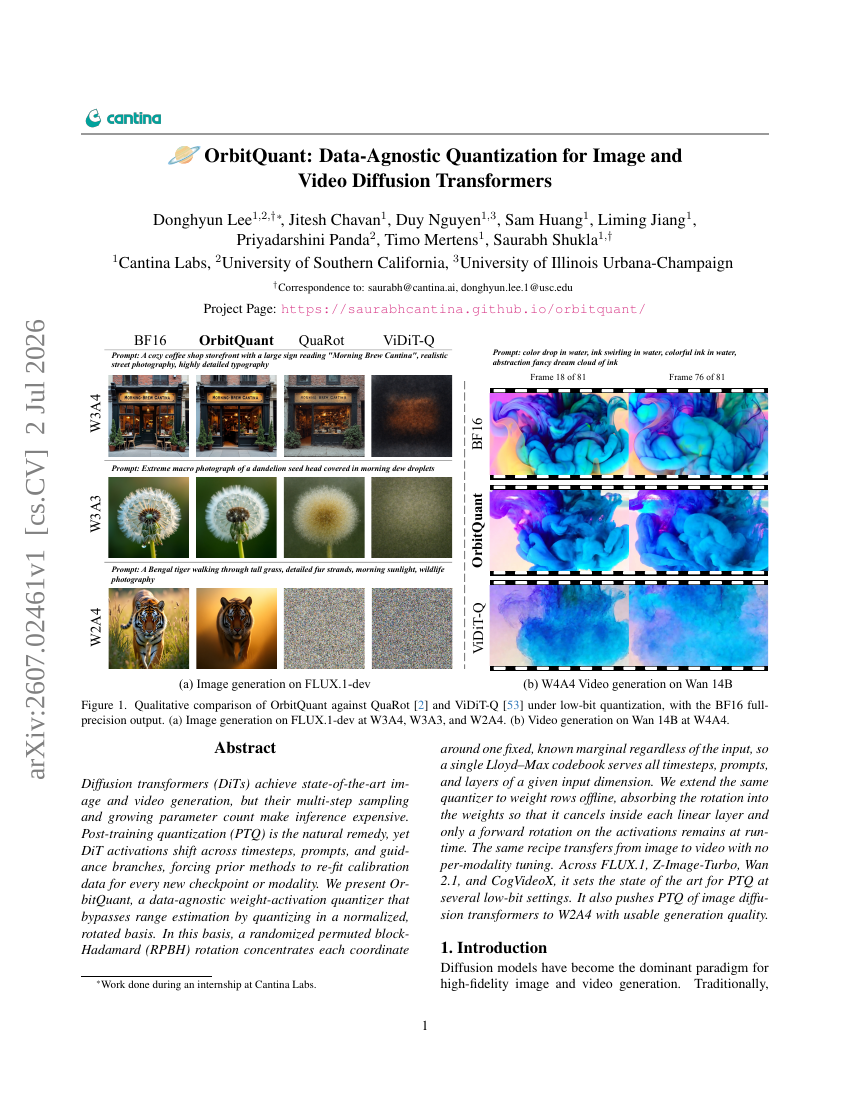
OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers

VLA-Corrector: Lightweight Detect-and-Correct Inference for Adaptive Action Horizon

Embodied.cpp: A Portable Inference Runtime of Embodied AI Models on Heterogeneous Robots

The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning

GeneBench-Pro: Evaluating Multistage Statistical Reasoning in Genomics, Quantitative Biology, and Translational Biomedicine

Position: AI/ML Deepfake Research is Misaligned with AI-Generated Non-Consensual Intimate Imagery (AIG-NCII)

To Grok Grokking: Provable Grokking in Ridge Regression

A Random Matrix Theory Perspective on the Consistency of Diffusion Models
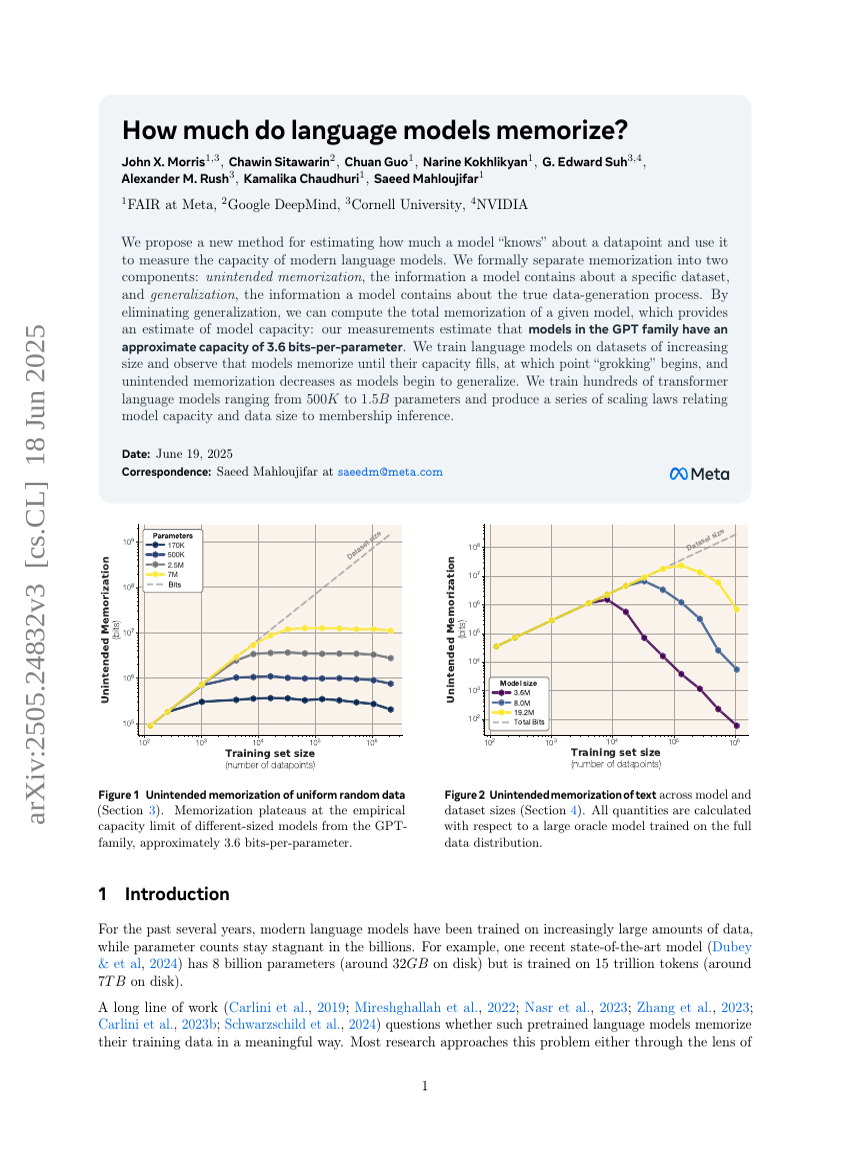
How much do language models memorize?

The Obfuscation Atlas: Mapping Where Honesty Emerges in RLVR with Deception Probes

Position: The Alignment Community is Unintentionally Building a Censor’s Toolkit
Parallelized Autoregressive Decoding for Omni-Modal Dense Video Captioning
Light-Omni: Reflex over Reasoning in Agentic Video Understanding with Long-Term Memory
Vision as Unified Multimodal Generation
Hierarchical Sparse Attention Done Right: Toward Infinite Context Modeling
AlayaWorld: Long-Horizon and Playable Video World Generation
RynnWorld-4D: 4D Embodied World Models for Robotic Manipulation
Nemotron-Labs-3-Puzzle-75B-A9B: Compressing Hybrid MoE LLMs
Multi-Turn On-Policy Distillation with Prefix Replay
Gemma 4 Technical Report
UI-MOPD: Multi-Platform On-Policy Distillation for Continual GUI Agent Learning
Wan-Streamer v0.2: Higher Resolution, Same Latency
EVA-Client: A Unified Framework for Deployment, Evaluation, and Data Collection on Real Robots
GigaWorld-1: A Roadmap to Build World Models for Robot Policy Evaluation
ResearchStudio-Idea: An Evidence-Grounded Research-Ideation Skill Suite from ML Conference Outcomes
ResearchStudio-Reel: Automate the Last Mile of Research from Paper to Poster, Video, and Blog
FINAL Bench: Measuring Functional Metacognitive Reasoning in Large Language Models
SceneFun3D: Fine-Grained Functionality and Affordance Understanding in 3D Scenes
TheoremGraph: Bridging Formal and Informal Mathematics
Always-On Agents: A Survey of Persistent Memory, State, and Governance in LLM Agents
Securing the AI Agent: A Unified Framework for Multi-Layer Agent Red Teaming
DataComp-VLM: Improved Open Datasets for Vision-Language Models
OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
VLA-Corrector: Lightweight Detect-and-Correct Inference for Adaptive Action Horizon
Embodied.cpp: A Portable Inference Runtime of Embodied AI Models on Heterogeneous Robots
The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
GeneBench-Pro: Evaluating Multistage Statistical Reasoning in Genomics, Quantitative Biology, and Translational Biomedicine
Position: AI/ML Deepfake Research is Misaligned with AI-Generated Non-Consensual Intimate Imagery (AIG-NCII)
To Grok Grokking: Provable Grokking in Ridge Regression
A Random Matrix Theory Perspective on the Consistency of Diffusion Models
How much do language models memorize?
The Obfuscation Atlas: Mapping Where Honesty Emerges in RLVR with Deception Probes
Position: The Alignment Community is Unintentionally Building a Censor’s Toolkit