Command Palette
Search for a command to run...
dLLM:简单扩散语言建模
dLLM:简单扩散语言建模
Zhanhui Zhou Lingjie Chen Hanghang Tong Dawn Song
摘要
尽管扩散语言模型(Diffusion Language Models, DLMs)发展迅速,但近年来的许多模型逐渐趋同于一组共享的核心组件。然而,这些组件通常分散在临时搭建的研究代码库中,或缺乏透明、清晰的实现方式,导致其难以复现或扩展。随着该领域发展速度的加快,迫切需要一个统一的框架,能够在标准化共用组件的同时,保持足够的灵活性以支持新方法与新架构的探索。为填补这一空白,我们提出了 dLLM——一个开源框架,旨在统一扩散语言建模的核心环节,包括训练、推理与评估,并使这些组件易于针对新设计进行定制。借助 dLLM,用户可通过标准化的流程复现、微调、部署并评估开源的大规模 DLM,例如 LLaDA 和 Dream。此外,该框架还提供轻量级、可复现的实现方案,帮助研究者在有限计算资源下从零开始构建小型 DLM,支持将任意基于 BERT 的编码器或自回归语言模型转换为扩散语言模型。我们还公开发布了这些小型 DLM 的模型检查点(checkpoints),以提升 DLM 的可及性,并推动未来研究的快速发展。
一句话总结
来自加州大学伯克利分校和伊利诺伊大学厄巴纳-香槟分校的研究人员推出了 dLLM,这是一个统一的开源框架,标准化了扩散语言模型的训练、推理和评估流程,使 LLaDA 和 Dream 等模型的复现、定制和部署更加便捷,并通过轻量级配方和已发布的检查点降低入门门槛。
主要贡献
- dLLM 引入了一个统一的开源框架,标准化了扩散语言模型的训练、推理和评估,支持在 LLaDA 和 Dream 等架构上实现可复现的开发和轻松定制。
- 该框架提供了极简的端到端配方,可在可及计算资源下将现有的 BERT 风格编码器或自回归语言模型转换为 DLM,并发布检查点以降低新研究者的入门门槛。
- dLLM 支持即插即用的推理算法和统一的评估接口,便于在无需修改架构或消耗大量计算资源的情况下,实现跨模型的公平比较和加速迭代。
引言
作者利用扩散语言建模(dLM)日益增长的势头——其优势包括迭代优化和高效解码——但当前因代码库分散且不可复现而面临碎片化问题。先前工作缺乏标准化的训练、推理和评估流程,导致模型复现或比较困难——尽管许多模型共享相似组件。其主要贡献是 dLLM,一个开源框架,将这三个核心阶段统一为模块化、可扩展的流水线,使用户能够复现、微调和评估 LLaDA 和 Dream 等模型,同时提供轻量级配方,可在最小计算资源下将现有 BERT 或自回归语言模型转换为 DLM。
方法
作者采用一个模块化的训练与推理框架,旨在统一离散扩散语言建模(DLM)工作流。该架构的核心是一个灵活的训练器接口,支持 Masked Diffusion(MDLM)和 Block Diffusion(BD3LM)目标,实现预训练、监督微调(SFT)以及从自回归语言模型适配的无缝切换。训练流程基于 HuggingFace 生态系统,集成 accelerate 实现分布式训练,peft 实现参数高效微调,而自定义训练器(如 MDLMTrainer)则作为标准 transformers Trainer 的轻量级封装。该设计允许用户通过最小代码更改(如切换 right_shift_logits 参数或使用 PrependBOSWrapper 封装数据整理器)在不同训练范式间切换——例如,将 MDLMTrainer 替换为 BD3LMTrainer,或将自回归模型适配至 MDLM。
在推理方面,框架引入了一个统一的 Sampler 抽象,将模型架构与解码策略解耦。这使得采样器可即插即用——例如,将标准 MDLMSampler 替换为加速版 MDLMFastdLLMSampler——而无需修改底层模型。如下图所示,该接口同时支持基础和优化推理路径,同时保持与现有模型实现的兼容性。

为增强可解释性,框架包含一个 TerminalVisualizer,用于跟踪并显示推理过程中 token 的解码顺序。与严格从左到右解码的自回归模型不同,DLM 以任意顺序解码 token,因此解码轨迹是关键的诊断特征。可视化器渲染 token 的逐步解码过程,如下图所示,展示了从完全遮蔽到完全解码的响应演化过程,以及实时指标如已解码遮蔽数和耗时。

MDLM 的训练目标是最小化未遮蔽 token 的时间加权负对数似然,形式化为:
LMDLM=Et∼U(0,1),x0[t1i∈Mt∑−logpθ(x0i∣xt)].对于 BD3LM,损失按块计算并依赖先前生成的块,表达为:
LBD3LM=k=1∑KEt∼U(0,1),x0t1i∈mask(Bk,t)∑−logpθ(x0i∣xtBk,x<Bk).这种分解允许块内并行生成,同时利用先前块缓存的键值状态,提升效率与可扩展性。
实验
- MDLM 预训练及后续微调(SFT 或 BD3LM)验证了扩散语言模型可通过统一训练器接口有效适配推理与指令遵循任务。
- 评估实验确认 DLM 性能对推理超参数高度敏感,因此需要灵活、可复现的评估框架,以紧密匹配各模型与任务的官方结果。
- 通过 MDLM SFT 微调开源权重 DLM(LLaDA、Dream)可提升推理能力,尤其在指令变体上,但基础模型在分布外任务上可能出现退化。
- BERT 风格模型仅通过 SFT 即可转换为功能完整的扩散聊天机器人,在部分基准测试中表现具有竞争力,尽管未进行生成架构修改。
- 自回归模型(如 Qwen3)可通过 SFT 高效转换为 DLM(MDLM 或 BD3LM),在代码生成任务中表现强劲,证明无需持续预训练即可实现 AR 到扩散模型的实用转换。
- 训练曲线与复现表格证实稳定收敛及官方评估分数的忠实复现,验证了 dLLM 框架的一致性与可靠性。
作者使用其统一的 dLLM 框架复现 LLaDA-Base 的评估结果,显示在多个基准测试中与官方分数高度一致,同时支持一致的跨模型比较。结果表明,其实现方案在 MMLU 和 GSM8K 等任务上表现相当或略优,验证了评估流水线的保真度。这种可复现性支持该框架用于扩散语言模型的公平标准化评估。

作者评估了基于 ModernBERT 的聊天模型与可比的仅解码器模型,发现尽管为仅编码器架构,它们在大多数基准测试中优于 GPT-2 变体,甚至在 BBH 和 MATH 上超越 Qwen1.5-0.5B-Chat。结果表明,BERT 风格模型无需架构修改即可作为扩散语言模型的可行骨干,但在知识密集型任务上仍落后于同等规模的自回归模型。
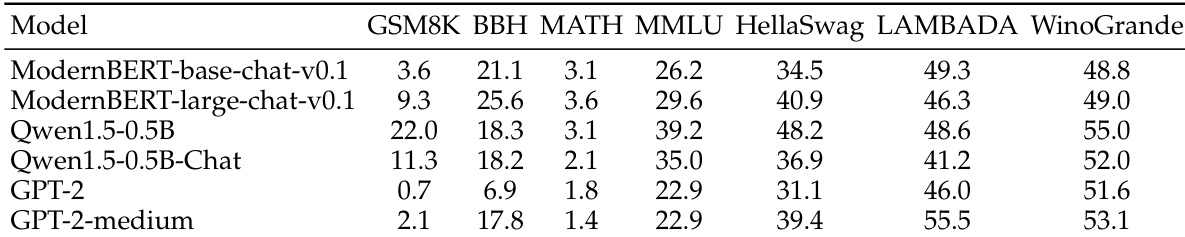
作者使用统一评估框架复现 LLaDA-Base 的结果,表明其 dLLM 实现方案在多个基准测试中紧密匹配或略超官方分数。这表明框架能可靠捕捉模型性能,同时支持一致的跨模型比较。研究结果强调了精确推理配置在评估扩散语言模型中的重要性。

作者使用统一评估框架复现 LLaDA-Base 的结果,显示在多个基准测试中与官方分数高度一致,但在 BBH 和 HellaSwag 等任务中出现轻微差异。这证实了框架能忠实复现先前工作,同时支持一致的跨模型比较。微小差异突显了扩散语言模型对评估配置的高度敏感性,即使在匹配设置下亦然。

作者使用其 dLLM 框架评估缓存与并行解码在多个基准测试中的性能增益,显示结合两者优化始终提供最高加速比,同时保持接近基线的准确率。结果表明,仅并行解码即可显著提升吞吐量,添加缓存进一步放大效率而无显著准确率损失。这些发现突显了其统一评估流水线在隔离并量化推理层优化影响方面的实用价值。