Command Palette
Search for a command to run...
SkyReels-V4:多模态视频-音频生成、修复与编辑模型
SkyReels-V4:多模态视频-音频生成、修复与编辑模型
摘要
SkyReels V4 是一个统一的多模态视频基础模型,支持视频与音频的联合生成、图像修复(inpainting)及编辑任务。该模型采用双流多模态扩散变换器(Multimodal Diffusion Transformer, MMDiT)架构,其中一条分支负责视频生成,另一条分支则生成时序对齐的音频,二者共享基于多模态大语言模型(Multimodal Large Language Models, MMLM)的强大文本编码器。SkyReels V4 支持丰富的多模态输入指令,包括文本、图像、视频片段、掩码(masks)以及音频参考。通过结合 MMLM 的多模态指令理解能力与视频分支 MMDiT 中的上下文学习机制,模型能够在复杂条件约束下注入细粒度的视觉引导信息;同时,音频分支 MMDiT 亦可利用音频参考来指导声音的生成过程。在视频处理方面,模型采用通道拼接(channel concatenation)的统一表达形式,将多种修复类任务——如图像转视频、视频扩展、基于条件的视频编辑等——统一整合至单一接口中,并自然拓展至基于视觉参考的修复与编辑任务,仅需通过多模态提示即可实现。SkyReels V4 支持最高达 1080p 分辨率、32 FPS 帧率及最长 15 秒的视频生成,可实现高保真度、多镜头、电影级质量的视频内容生成,并确保音视频同步。为实现高分辨率、长时长生成的计算可行性,我们提出一种高效策略:首先联合生成低分辨率的完整视频序列与高分辨率关键帧,随后通过专用的超分辨率模型与帧插值模型进行精细化重建。该方法在保证生成质量的同时显著降低计算开销。据我们所知,SkyReels V4 是首个同时具备以下能力的视频基础模型:支持多模态输入、实现视频与音频的联合生成、并以统一范式处理生成、修复与编辑任务,且在电影级分辨率与时长下仍保持卓越的性能与效率。
一句话总结
SkyReels 团队与 Skywork AI 提出 SkyReels-V4,这是一种采用双流 MMDiT 架构、共享 MMLM 文本编码器的统一多模态视频基础模型,支持通过高效低-高分辨率生成方式,在 1080p/32fps/15s 分辨率下实现视频与音频的联合生成、编辑与修复,为电影级多模态内容创作树立新标准。
主要贡献
- SkyReels-V4 引入双流 MMDiT 架构,通过共享 MMLM 文本编码器实现统一多模态条件控制,支持从文本、图像、视频片段、遮罩和音频参考等多种输入中联合生成同步的视频与音频。
- 该模型通过视频分支中的通道拼接公式统一生成、修复与编辑任务,支持图像转视频、视频扩展、遮罩引导编辑等任务于单一接口,而音频分支则利用参考音频引导声音合成。
- 通过先生成低分辨率序列与高分辨率关键帧,再进行超分辨率与插帧的高效策略,实现电影级画质(1080p,32 FPS,15s),并在 SkyReels-VABench 和 Artificial Analysis Arena 等基准测试中超越现有最先进模型。
引言
作者利用近期多模态扩散建模的进展,解决视频-音频生成系统碎片化的问题:以往模型要么分别处理各模态,要么缺乏统一的编辑与修复能力。现有方法——无论是商业模型如 Sora-2,还是开源模型如 Kling-Omni——在完整音视频对齐、多模态条件控制或单一架构下的可扩展编辑方面均存在困难,常牺牲同步性、分辨率或灵活性。SkyReels-V4 引入双流 MMDiT 框架,支持从文本、图像、视频、遮罩、音频等多种输入联合生成同步视频与音频,同时通过通道拼接范式统一生成、修复与编辑。此外,通过高效的低/高分辨率关键帧策略,实现电影级输出(1080p,32 FPS,15s),成为首个在生产级质量与速度下集成所有这些能力的系统。
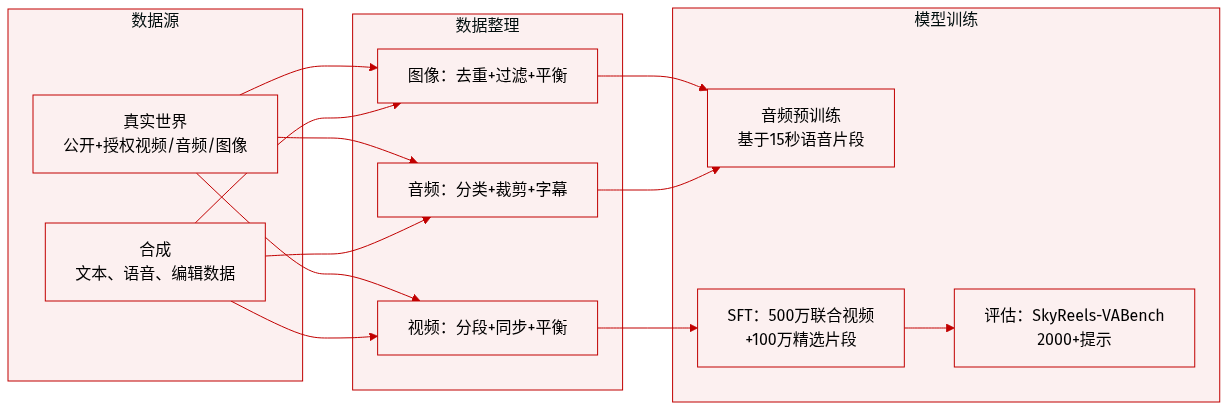
数据集
-
作者使用包含真实世界与合成数据的多模态训练数据集,涵盖图像、视频与音频。
-
真实数据来自公开来源(LAION、Flickr、WebVid-10M、Koala-36M、OpenHumanVid、Emilia、AudioSet、VGGSound、SoundNet)及授权内部内容(电影、电视剧、短视频、网络剧)。
-
合成数据填补多语言文本生成、语音合成与多模态编辑的空白。文本生成覆盖中文、英文、日文、韩文、德文、法文等,支持字体感知渲染与上下文感知样式;视频-文本数据包含运动匹配的文字特效;语音数据使用多种 TTS 模型与稀有文字语料;修复/编辑数据通过分割、编辑与可控生成流水线构建。
-
图像处理包括去重、质量筛选(分辨率、IQA、水印)及聚类平衡(预训练)或实体/场景匹配(微调)。
-
音频处理使用 Qwen3-Omni 将片段分类为音效、音乐、语音或歌唱;按信噪比、MOS、削波与静音比例过滤;分割或拼接至15秒;用 Whisper 转录语音/歌唱;通过 Qwen3-Omni 生成统一字幕。
-
视频处理使用智能分割(VLM 增强的 TransNet)确保叙事连贯性,通过 VideoCLIP 去重,按基础、内容与运动质量筛选,按概念与运动分类平衡,并通过 SyncNet 同步音视频(保留偏移量 |offset| ≤ 3 且置信度 > 1.5、最小音量 -60 dB 的片段)。
-
音频主干从头预训练于数十万小时可变长度语音(最长15秒),以捕捉音高与情感等说话人特征。
-
在监督微调阶段,作者在 500 万条多模态联合生成视频(占数据20%)上训练,再用 100 万条人工精选高质量视频微调,以提升运动连贯性与音视频对齐。
-
为评估,作者引入 SkyReels-VABench:包含 2000+ 条提示的基准测试,涵盖多语言(中文、英文)、内容类型(广告、教育、叙事)、主体、环境、运动动态与音频模态(语音、歌唱、音效、音乐)。
方法
作者采用双流多模态扩散 Transformer(MMDiT)架构,实现统一框架下的视频与音频联合生成、修复与编辑。模型通过并行、对称分支处理视频与音频模态,共享源自多模态大语言模型(MMLM)的文本编码器。该设计支持接收丰富的多模态条件信号——包括文本、图像、视频片段、遮罩与音频参考——同时保持电影级分辨率与时长下的计算效率。
参考框架图,其整体架构如下:输入管道从多模态条件开始:视觉参考(图像或视频片段)通过 Video-VAE 编码,音频参考通过 Audio-VAE 处理。这些与噪声潜变量及时空遮罩通过通道拼接输入视频分支,同时与 MMLM 编码器生成的文本嵌入一起输入两个分支。MMLM 编码器产生统一语义上下文,通过自注意力与交叉注意力机制独立供给视频与音频流。

视频与音频分支的每个 Transformer 块采用混合设计:前 M 层采用双流配置,视频/音频与文本标记在归一化与投影中保持独立参数,但在联合自注意力中交互,促进网络早期强跨模态对齐。后续 N 层转为单流架构,处理拼接标记并共享参数,最大化计算效率。为抵消单流阶段潜在的语义稀释,视频分支在自注意力后增加额外的文本交叉注意力层,强化生成全程的文本引导。
视频与音频流之间在每个 Transformer 块嵌入双向交叉注意力,实现持续时间同步。音频流关注视频特征,反之亦然,确保生成音频与视觉内容保持时间对齐。尽管时间分辨率不同——21 帧视频对应 218 个音频标记——作者对音频标记应用旋转位置嵌入(RoPE),频率缩放因子为 21/218≈0.09633,使其时间结构与视频流对齐。
训练采用流匹配目标,模型预测引导噪声潜变量走向干净数据的速度场。损失函数联合优化视频与音频分支:
Lflow=Et,zv0,za0,ϵv,ϵa[vθv(t,Zvt,Zat,c)−(zv0−ϵv)2+vθa(t,Zat,Zvt,c)−(za0−ϵa)2]其中 c 包含多模态嵌入与可选遮罩。
对于视频修复与编辑,作者采用通道拼接公式,将多种任务——包括文本转视频、图像转视频、视频扩展与时空编辑——统一于单一接口。视频 MMDiT 输入形式为:
Zinput=Concat(V,I,M)其中 V 为噪声视频潜变量,I 包含 VAE 编码的条件帧,M 为二值遮罩,指示需生成区域(0)或保留区域(1)。该机制仅应用于视频流;音频分支根据(部分编辑后)视频内容从头生成同步音频。
为高效实现高分辨率、长时长生成,作者引入级联 Refiner 模块,执行联合视频超分辨率与帧插值。如下图所示,Refiner 接收来自基础模型的低分辨率完整序列与高分辨率关键帧,以及多模态条件信号。它采用视频稀疏注意力(VSA)将计算成本降低约 3×,同时保持质量,实现 1080p 与 32 FPS 的实用推理。
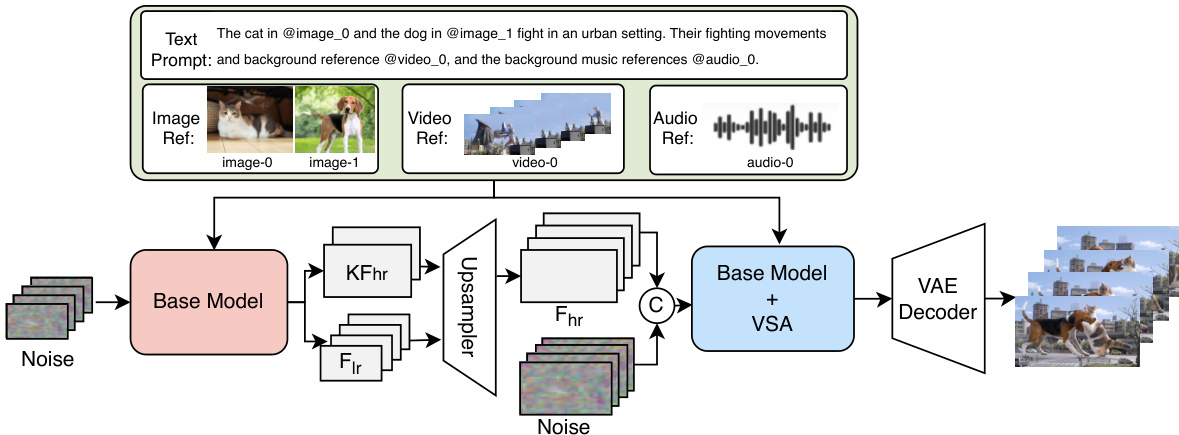
Refiner 从预训练视频生成模型初始化,并在相同流匹配范式下训练。它支持无条件增强与通过空间遮罩引导的条件修复,仅在目标区域进行细化。该设计使模型能够处理复杂编辑场景——包括水印移除、主体操作与全局风格迁移——同时保持时间连贯性与声学同步。
实验
- 在 Artificial Analysis 公开排行榜的带音频文本转视频任务中排名第三,表明在顶级模型中具有用户偏好的音视频合成能力。
- 在五项维度的人工评估中获得最高综合得分:指令遵循、音视频同步、视觉质量、运动质量与音频质量,尤其在指令遵循与运动质量方面表现突出。
- 在成对比较中超越主要基线模型(Veo 3.1、Kling 2.6、Seedance 1.5 Pro、Wan 2.6),在大多数评估维度中更常被评为“良好”。
- 展示了实用的多模态编辑能力,包括主体插入、属性修改、背景替换与参考引导合成,并通过真实应用案例验证。