Command Palette
Search for a command to run...
SARAH:面向空间感知的实时智能体人类
SARAH:面向空间感知的实时智能体人类
Evonne Ng Siwei Zhang Zhang Chen Michael Zollhoefer Alexander Richard
摘要
随着具身智能体(embodied agents)在虚拟现实(VR)、远程存在(telepresence)及数字人应用中的日益重要,其运动表现必须超越简单的语音同步手势:智能体应能面向用户、响应用户的动作,并保持自然的视线交互。然而,现有方法普遍缺乏这种空间感知能力。为此,我们提出首个实时、完全因果的、具备空间感知能力的对话式运动生成方法,可直接部署于流式VR头显设备上。在给定用户位置与双人语音输入的前提下,我们的方法能够生成全身运动,使手势与语音同步,同时根据用户位置动态调整智能体朝向。该方法的架构融合了基于因果Transformer的变分自编码器(VAE),采用交错的潜在标记(interleaved latent tokens)以支持流式推理,并结合一个以用户轨迹和音频为条件的流匹配模型(flow matching model)。为适应不同用户对视线交互强度的偏好,我们引入了一种基于分类器自由引导(classifier-free guidance)的视线评分机制,实现学习与控制的解耦:模型从数据中学习自然的空间对齐模式,而用户可在推理阶段灵活调节眼神接触的强度。在Embody 3D数据集上的实验表明,我们的方法在超过300 FPS的帧率下实现了当前最优的运动质量,较非因果基线方法快约3倍,同时精准捕捉了自然对话中的细微空间动态。我们进一步在真实VR系统中验证了该方法的有效性,成功将具备空间感知能力的对话式智能体推向实时部署。更多细节请参见:https://evonneng.github.io/sarah/
一句话摘要
Meta Reality Labs 的研究人员提出了一种实时、因果的时空感知对话动作生成方法,该方法结合了 Transformer VAE 和流匹配技术,使虚拟现实代理能够通过音频和位置信息动态对齐手势与视线,实现超过 300 FPS 的性能并在实际部署中提供自然交互。
主要贡献
- 我们提出了首个实时、完全因果的虚拟代理时空感知对话动作生成方法,使其仅凭用户过去和当前的位置及双人音频即可动态朝向用户并使手势与语音同步。
- 我们的架构结合了基于因果 Transformer 的 VAE(采用交错潜在标记实现流式推理)与基于用户轨迹和音频的流匹配模型,以及一种无需分类器的视线引导机制,该机制将学习到的空间行为与用户可调节的注视强度解耦。
- 在 Embody 3D 数据集上评估,我们的方法在超过 300 FPS 下实现了最先进的动作质量——速度是非因果基线方法的三倍,并成功部署于实时 VR 系统,展示了在无未来帧访问的情况下仍能实现的实时空间响应能力。
引言
作者利用实时、因果生成建模技术,使 VR 和远程呈现系统中的虚拟代理在对话过程中能够动态朝向用户——根据语音和空间移动自然转身、注视和做手势。先前的方法要么忽略空间上下文,要么假设参与者静止,或依赖无法实时流式处理的非因果模型,限制了它们在交互系统中的应用。他们的主要贡献是 SARAH:一种流式架构,结合了基于因果 Transformer 的 VAE(采用交错潜在标记)、基于用户轨迹和双人音频的流匹配模型,以及一种无需分类器的视线引导机制,允许用户在推理时调节注视强度——在超过 300 FPS 下实现最先进的动作质量。
数据集
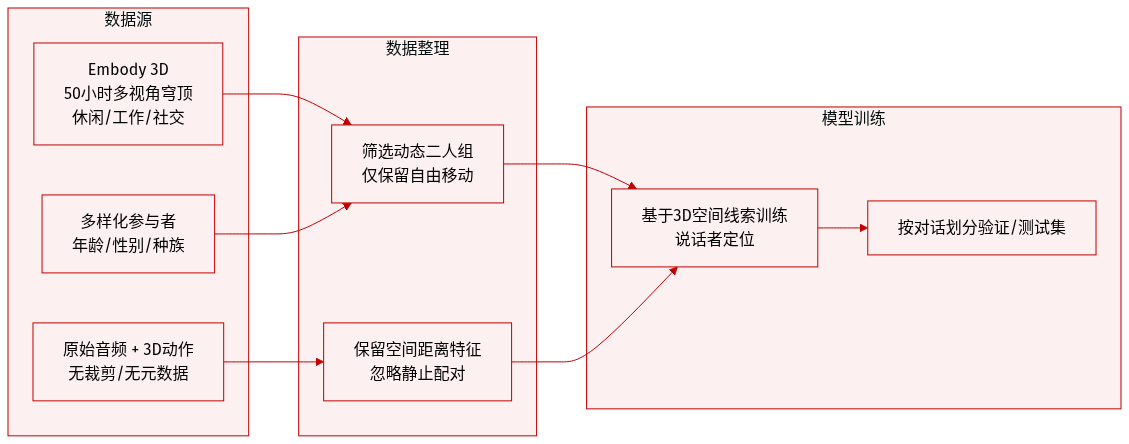
- 作者使用 Embody 3D 数据集 [McLean et al. 2025] 中的双人对话子集,该数据集包含约 50 小时的多视角穹顶捕捉互动,涵盖休闲、工作和社会对话。
- 参与者代表不同年龄、性别和种族群体,数据集包含音频和 3D 动作标注。
- 与先前仅捕捉单人说话者且无空间上下文的单人数据集(如 Speech2Gesture、BEAT),或参与者静止对坐的双人数据集(如 Audio2Photoreal、Panoptic Studio)不同,Embody 3D 记录了自然、动态的互动,参与者可自由走动并改变位置。
- 该数据集用于训练模型学习对话中的 3D 空间亲密度,利用其对说话者之间运动与空间关系的独特捕捉。
- 未指定裁剪或元数据构建细节;处理重点是直接从源文件中使用原始音频和 3D 动作标注。
方法
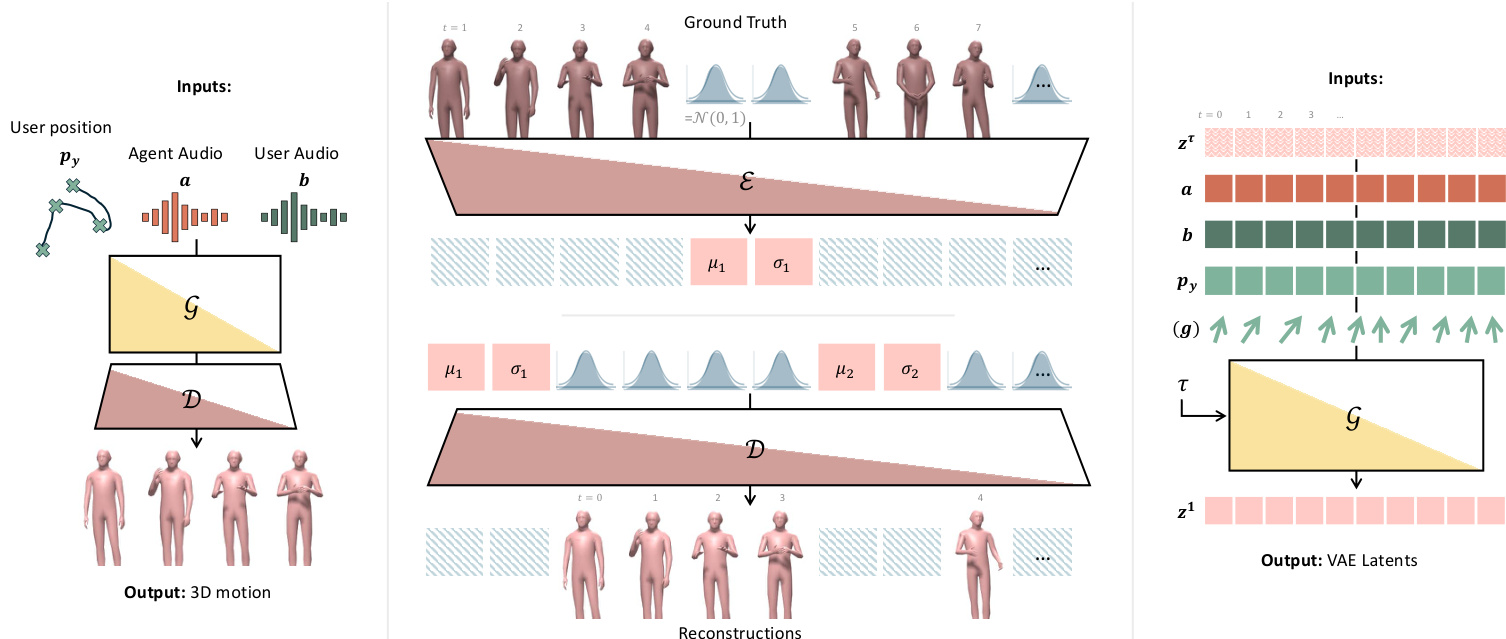
作者利用一种实时自回归动作合成流水线,该流水线以双人对话音频和用户空间位置为条件,为 AI 代理生成时空感知的 3D 动作。该系统围绕一个基于因果 Transformer 的变分自编码器(VAE)和一个流匹配生成器构建,两者均设计用于满足严格时间因果性的流式推理。
整体框架从输入条件开始:用户的地面投影头部位置 py∈RT×2,以及通过 HuBERT 从代理和用户语音流中提取的音频特征 a,b∈RT×Da。这些输入被送入生成模型 G,输出代理的动作序列 x∈RT×Dx。请参考框架图以了解端到端流水线的视觉概览,包括 VAE 编码器-解码器结构和流匹配生成器。
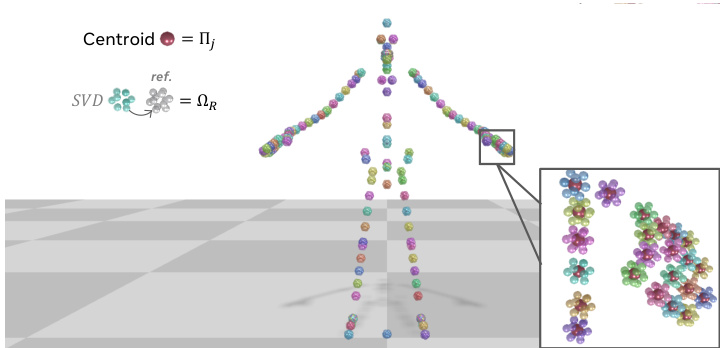
为实现高效稳定的训练,作者采用完全欧几里得动作表示。不同于传统的关节角度参数化,每个关节 j 被编码为一个 3D 正二十面体:其 12 个顶点的质心给出全局位置 Πj,全局朝向 Ωj 通过与参考正二十面体的 SVD 恢复。这种表示避免了局部旋转引起的误差传播并改善收敛性。完整姿态因此被编码为 xt∈RJ×12×3,其中 J 为关节数量,并相对于第一帧进行归一化以防止漂移。如图所示,这种几何编码提供了鲁棒且可微分的动作表示。
架构的核心是基于因果 Transformer 的 VAE。与标准 VAE 将全局潜在变量置于序列开头不同,该模型以固定时间步长 s 交错插入潜在标记 μk,σk∈RDz,实现因果注意力。编码器 E 以块形式处理输入:(x1:S,μ1,σ1,xs+1:2S,μ2,σ2,…),其中每个 μk/σk 标记仅关注先前帧和更早的潜在变量。解码器 D 镜像此模式。模型使用结合重建和 KL 散度的 VAE 损失进行训练:
LVAE=∥x−x^∥22+βk=1∑KKL(qϕ(zk∣x1:kS)∥N(0,I)),其中 K=T/s,x^ 为重建结果,zk∼N(μk,σk2) 为第 k 块的采样潜在变量。训练后,编码器用于提取潜在序列 z=(z1,…,zK)∈RK×Dz 以供生成使用。
动作生成器是一个在潜在空间上运行的基于 Transformer 的流匹配模型。它通过预测速度场 vθ(zτ,τ,c) 将噪声 ϵ∼N(0,I) 传输到数据,其中 τ∈[0,1] 为流时间,c=[py;a;b] 为条件。插值潜在变量形成如下:
zτ=τz+(1−τ)ϵ,ϵ∼N(0,I).训练使用 x1 预测,损失为:
Lflow=Eτ,ϵ,z[∥G(zτ,τ,c)−z∥22],其中 τ∼U[0,1]。分类器自由引导通过以 5% 概率独立丢弃每个模态实现。对于实时流式处理,强制执行因果注意力掩码,并通过插值保持时间一致性:每一步中,先前预测的潜在变量被插入噪声序列,然后进行去噪。
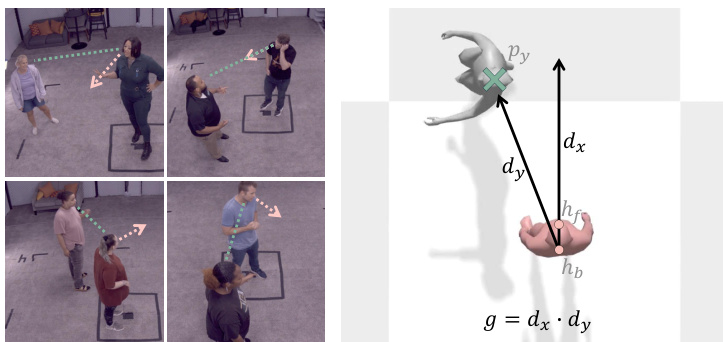
为实现可控的注视行为,作者引入了一种可调的注视引导机制。注视得分 g 计算为代理朝向 dx 与朝向用户方向 dy 的点积:
dx=∥hf−hb∥hf−hb,dy=∥pu−hb∥py−hb,g=dx⋅du.该得分范围从 -1(背对)到 1(直接眼神接触)。训练期间,g∈RT×1 与条件 c 拼接,分类器自由引导以 5% 概率丢弃 g。推理时,可指定目标注视得分以调节眼神接触强度,同时保留自然变化。如图所示,这允许对非语言参与线索进行细粒度控制。
部署时,动作以 s=4 帧为块生成,保留最后 2 个标记以保持时间连续性。系统使用中点求解器,每块迭代 4 次,实现 60 fps 的实时流式处理。逼真渲染通过另一种基于学习的方法处理,该方法根据从语音推导出的关节参数和面部表情合成几何和纹理。
实验
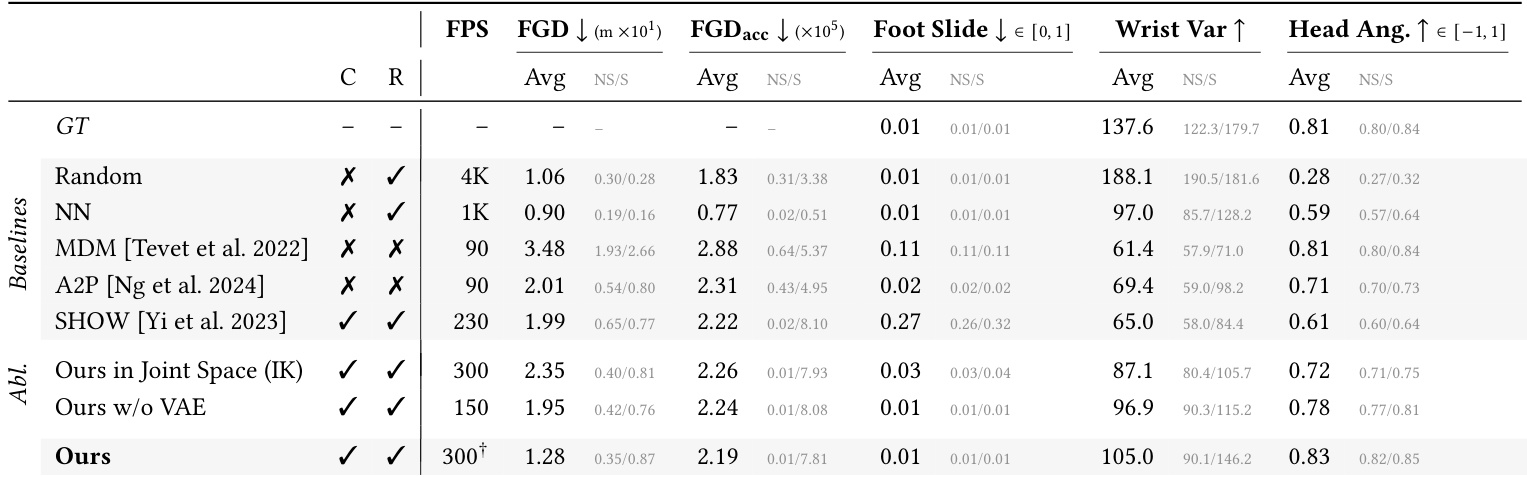
- 该模型生成的时空感知对话动作在质量上可与最先进的方法(包括非因果和非实时方法)竞争,同时保持实时、因果推理。
- 它在注视对齐方面表现优异,显著优于检索和生成基线方法,能够在自然对话上下文中使代理朝向用户。
- 与检索方法不同,它生成新颖动作,联合优化真实性、表现力和空间感知,而非受限于数据集示例。
- 与基于扩散的基线方法(MDM、A2P)相比,它在动作动态、脚部滑动和表现力方面表现更优,同时运行更快且无需未来上下文。
- 与仅依赖音频的模型(SHOW)相比,它通过显式条件化用户位置展示了更优的全身协调性和空间感知。
- 消融研究证实了欧几里得动作表示(相对于关节角度)在精确定位中的价值,以及 VAE 在捕捉动作分布而不牺牲物理合理性的关键作用。
- 注视方向在推理时可通过分类器自由引导控制,实现可调节的社会参与度——从避免眼神接触到完全面向用户——同时保持动作质量。
- 定性视频结果显示在说话/倾听模式间自然过渡、情境适当的肢体语言,以及与现成 LLM 和 TTS 结合的实时 VR 应用的无缝集成。
作者证明,他们的模型在实时生成时空感知对话动作的同时,保持了与非因果、非实时基线相当的真实性与表现力。结果表明,推理时的显式注视控制允许灵活调整代理朝向用户的方向,适度引导可同时提升对齐度和动作质量,而严格对齐则会牺牲自然变化。消融研究确认,他们的欧几里得动作表示和因果 VAE 对实现高保真度和物理合理性至关重要,且不牺牲速度。
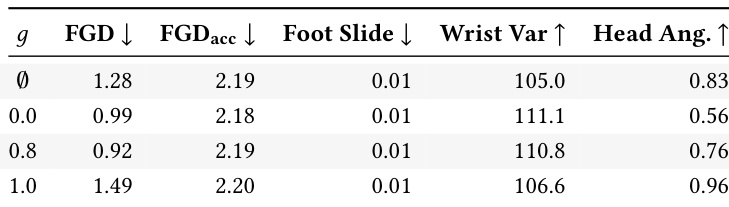
作者使用因果、实时模型生成时空感知对话动作,在保持竞争力的真实性和多样性的同时,显式对齐代理的注视方向朝向用户。结果表明,他们的方法在注视对齐和物理合理性方面优于非因果基线,并通过生成满足多重标准的新颖动作超越检索方法,而非仅从现有数据中采样。消融研究确认,他们的欧几里得动作表示和通过 VAE 的潜在压缩对保持空间准确性和表现力动态至关重要。