Command Palette
Search for a command to run...
LongCLI-Bench:面向命令行界面中长时程智能体编程的初步基准与研究
LongCLI-Bench:面向命令行界面中长时程智能体编程的初步基准与研究
摘要
近年来,人工智能辅助编程的进展使得智能体(agents)能够通过命令行界面执行复杂的任务流程。然而,现有的评估基准存在诸多局限:任务周期过短、数据因从GitHub爬取而存在污染,且缺乏细粒度的评估指标,难以对真实软件工程场景中至关重要的长周期规划与执行能力进行严格评估。为弥补这些不足,我们提出LongCLI-Bench——一个面向长周期、真实任务场景的综合性评估基准,用于系统性地评测智能体在复杂软件开发任务中的表现。我们从超过1000份计算机科学课程作业与真实世界工作流中精心筛选出20个高质量、长周期的任务,涵盖四大工程类别:从零开始构建(from scratch)、功能新增、缺陷修复(bug fixing)以及代码重构(refactoring)。针对该基准,我们设计了一套双集测试协议,分别衡量任务需求达成情况(fail-to-pass)与回归问题规避能力(pass-to-pass),并引入细粒度的步骤级评分机制,以精准定位执行过程中的失败环节。大规模实验结果显示,即便采用当前最先进的智能体,其在LongCLI-Bench上的通过率仍低于20%。进一步的步骤级分析表明,绝大多数任务的完成度不足30%,凸显关键失败多集中于执行初期阶段。尽管自我修正机制带来有限提升,但通过计划注入(plan injection)与交互式引导的人机协作模式,显著提升了任务成功率。这些结果表明,未来研究亟需在提升智能体自身规划与执行能力的同时,重点发展协同式人机工作流,以应对长周期任务中面临的重大挑战。
一句话总结
来自南开大学、SII、盛大脑智能东京研究院、上海人工智能实验室和上海交通大学的研究人员推出了 LongCLI-Bench,这是一个通过双集测试和步骤级评分评估 AI 代理在长视距 CLI 任务中表现的新基准,揭示了严重的性能差距,并主张通过人机协作改进现实世界的软件工程工作流。
主要贡献
- LongCLI-Bench 引入了一个包含 20 个长视距、真实世界 CLI 任务的新基准,这些任务从 1000 多个计算机科学作业和工作流中精心挑选,涵盖四类工程领域,以解决现有基准的局限性,如短视距和 GitHub 数据污染。
- 它采用双集评估协议,衡量需求完成度(失败→通过)和回归避免能力(通过→通过),并辅以步骤级评分,以识别代理在复杂多步骤执行中的失败点。
- 实验表明,最先进的代理通过率低于 20%,大多数在任务早期即失败,而人类指导协作显著优于自我修正,揭示规划与执行是自主软件工程中的关键瓶颈。
引言
作者利用 AI 代理在基于命令行的软件工程中的日益广泛应用,解决了一个关键空白:现有基准无法评估反映真实开发场景的长视距、多步骤任务。先前工作依赖于从 GitHub 抓取的短任务和二元通过/失败结果,掩盖了早期失败并存在数据污染。LongCLI-Bench 引入了 20 个精心挑选的复杂任务,涵盖四个工程类别——从零开始开发、功能添加、缺陷修复和重构——这些任务来源于学术作业和真实工作流。它采用双集评估(失败→通过和通过→通过)及步骤级评分,精确定位代理的失败点,揭示即使顶级代理成功率也低于 20%,主要由于早期阶段的规划与执行失效。作者进一步表明,通过注入计划或交互式指导的人机协作显著优于自我修正,主张未来进展必须优先考虑人机协同工作流与自主代理改进并重。
数据集

作者使用 LongCLI-Bench,这是一个专为评估代理在长视距、真实工程任务中表现而设计的精选基准。以下是数据集的组成与使用方式:
-
来源与构成:
任务来自两个无污染控制来源:
• 计算机科学课程作业(从 108 门课程收集的 958 个),经人工筛选,仅保留 Codex 难以处理的复杂多步骤工程任务。
• 真实世界的研究与工程工作流,人工构建以反映环境搭建、流水线构建和代码集成等顺序性、相互依赖的开发活动。 -
关键子集细节:
• 最终基准包含 20 个精选任务。
• 每个任务包括:初始代码库、需求文档、隔离环境、人工编写的解决方案代码库、双集测试套件、评分解析器和元数据(领域、难度、预估人工耗时)。
• 领域涵盖六大领域:系统编程、Web 开发、数据工程、机器学习、应用和 DevOps。
• 平均任务规模:15,000+ 行代码,104 个文件,涉及 C、Python、Java、JavaScript 等语言。
• 专家完成时间平均超过 1000 分钟/任务——远长于 Terminal-Bench@2 等短基准。 -
在模型训练/评估中的数据使用:
• 基准不用于训练,仅作为评估套件测试代理在长而复杂工作流中的规划、上下文保持和执行能力。
• 任务通过解析器对测试输出进行步骤级评分。
• 双集验证确保解决方案正确性和回归安全性。 -
处理与构建:
• 任务经过迭代优化和人工验证,确保可解性并符合基准目标。
• 无自动抓取——所有任务均人工编写或筛选,避免污染。
• 每个任务构建耗时约 40 小时,包括需求撰写、解决方案路径设计、测试环境搭建和脚本创建。
• 元数据包括领域、难度和时间预估,支持细粒度分析。
方法
作者采用结构化流程构建用于代码生成系统的稳健评估基准,强调可复现性、污染控制和细粒度评估。流程始于从两个领域获取任务规范:计算机科学课程作业和真实工作流。这些任务通过过滤机制处理,剔除具有短视距解决方案或易通过执行结果的候选者,确保任务复杂性和评估意义。
请参阅框架图以了解端到端工作流。流程始于“数据收集与过滤”阶段,摄入上千个任务文件。随后使用 CodeX 精炼为人工编写的需求文档,并经专家评审验证任务难度、步骤数和完成状态。对于课程作业,作者部分重写需求,替换变量名和叙述背景,以减轻检索式污染。对于真实任务,需求从零人工编写,确保原创性和清晰性。
如下图所示:
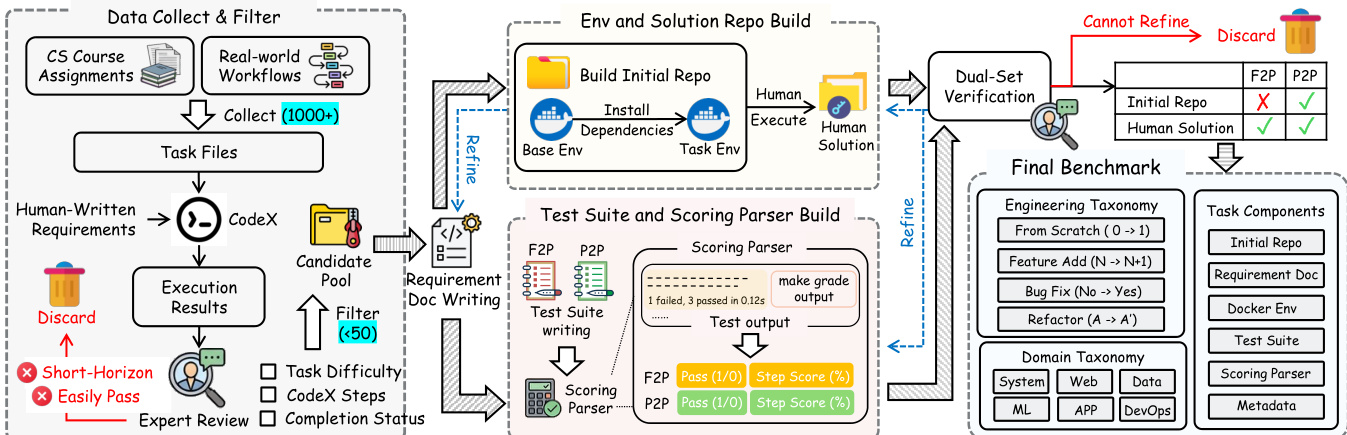
下一阶段是在 Docker 容器中构建执行环境和解决方案代码库。作者从基础镜像迭代解决每个任务,记录所有依赖项。这些依赖被封装进 Dockerfile 以确保环境一致性,而人工编写的解决方案则作为可解性验证的参考代码库。此双重输出——环境与解决方案——需通过双集验证:初始代码库需通过人工解决方案测试,仅通过 F2P 和 P2P 标准的任务方可进入下一阶段。
“测试套件与评分解析器构建”模块生成结构化测试用例和评分机制。解析器评估代理输出对功能与行为需求的满足程度,生成细粒度指标,如通过/失败状态和步骤得分。这些指标汇总为总分,支持对代理在功能正确性和过程保真度方面的细粒度分析。
最终基准包含两个分类体系:工程分类(按开发阶段分类,如功能添加、缺陷修复、重构)和领域分类(按应用领域分类,如系统、Web、机器学习、DevOps)。每个基准条目包括需求文档、Docker 环境、测试套件、评分解析器和元数据,确保全面且可复现的评估。
代理评估循环(如第一张图顶部所示)展示了代理如何与终端和工具箱交互、执行代码并接收多轮测试输出。结果根据详细测试套件评分,该套件将需求映射到功能检查,整体指标反映功能通过率和步骤级正确性。此架构支持代码生成系统的系统性、可扩展和可解释评估。
实验
- 测试独立于实现设计,避免偏差,使用 F2P(需求完成)和 P2P(回归预防)集验证任务完成度与系统稳定性。
- 任务需满足严格验证:F2P 初始失败但解决方案后通过,P2P 两状态均通过;失败任务经专家迭代评审或被丢弃。
- 评估在隔离的 Docker 环境中运行,评分基于步骤级完成;可选多轮尝试和自我修正模式允许迭代优化。
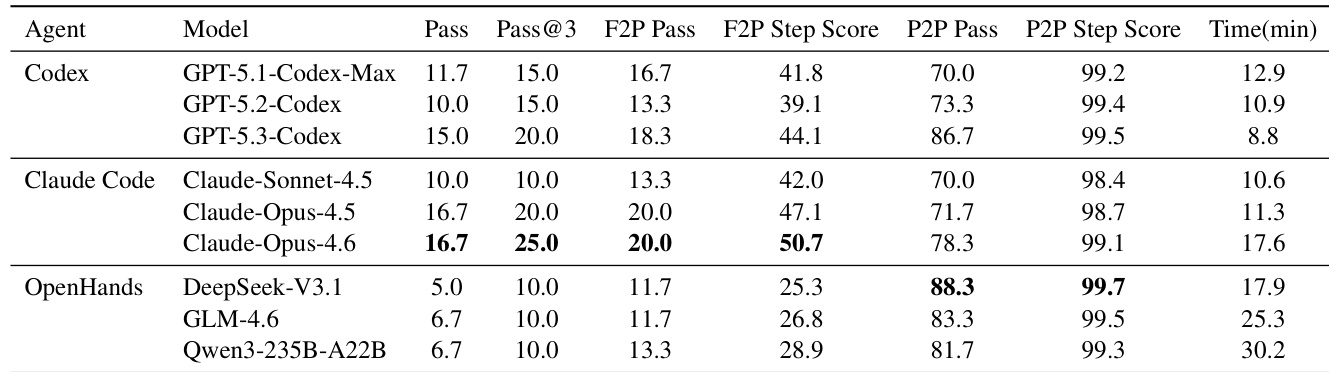
- 商业代理(Codex、Claude)在需求完成上优于开源代理(DeepSeek、GLM、Qwen),但所有代理在长视距任务中均表现困难;最高通过率仅为 16.7%。
- 高 P2P 步骤得分(>98%)掩盖了低通过率(70–88%),表明代理在添加新功能时常破坏现有功能。
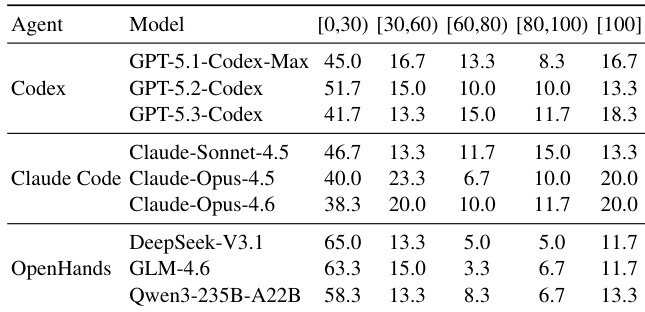
- 失败集中于任务早期(<30% 步骤得分),表明初始规划不足;商业代理在早期推理上表现更强。
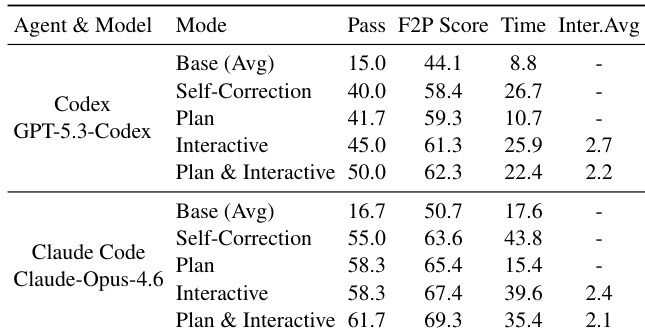
- 自我修正提升通过率,尤其从 T1 到 T2,但后期轮次可能引入回归;时间成本无一致趋势。
- 人类协作——通过静态计划注入或动态指导——显著提升性能;结合方法在更少干预下获得最佳结果。
- 失败并非源于语法错误,而是战略失效:重复循环、环境问题误诊、上下文漂移导致回归。
作者使用 LongCLI-Bench 评估代理在复杂长视距 CLI 任务中的表现,揭示即使顶级商业模型通过率也低于 20%,突显长期规划与环境感知的显著差距。结果表明,尽管大多数代理在回归测试中保持高步骤级准确率,但二元通过率低得多,表明修改过程中频繁意外破坏现有功能。在 OpenHands 框架下的开源代理整体完成率较低但回归稳定性更高,表明在复杂任务中限制执行范围可减少错误表面积。
作者评估代理在人类协作模式下的表现,发现结合静态计划注入与动态交互指导可获得最高通过率和步骤得分,同时减少所需人工干预次数。结果表明,前期结构化规划提高效率,但实时人类指导更擅长处理意外执行问题,凸显人机混合工作流优于完全自主。
作者使用 LongCLI-Bench 评估代理在需要环境感知和多步规划的复杂长视距 CLI 任务中的表现,并与 Terminal-Bench@2 等简单基准对比。结果表明,即使顶级商业代理通过率也较低,揭示长期推理与回归预防的重大差距,而人类协作与结构化规划显著改善结果。

作者使用步骤级评分分析代理在长视距 CLI 任务中的失败点,揭示大多数失败发生在执行早期,大多数任务尝试得分低于 30%。商业代理-模型组合在早期阶段表现强于开源框架,表明初始规划更好,而低分集中凸显在复杂多步骤任务中维持工作流连续性和环境感知的持续挑战。