HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

百川-M3:面向可靠医疗决策的临床问诊建模
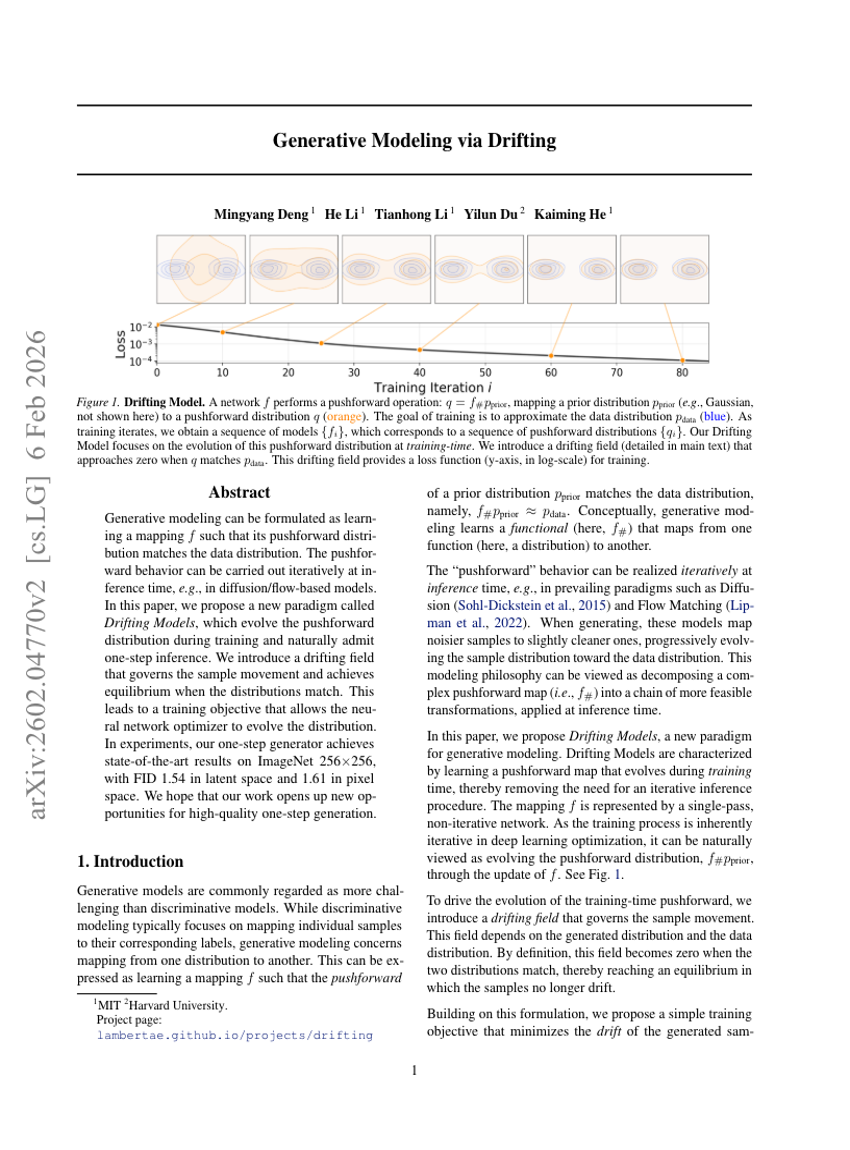
通过漂移进行生成建模




























百川-M3:面向可靠医疗决策的临床问诊建模
通过漂移进行生成建模
AlphaEdit:针对语言模型的零空间约束知识编辑
在13个参数中进行推理学习
DFlash:用于快速推测解码的块扩散方法
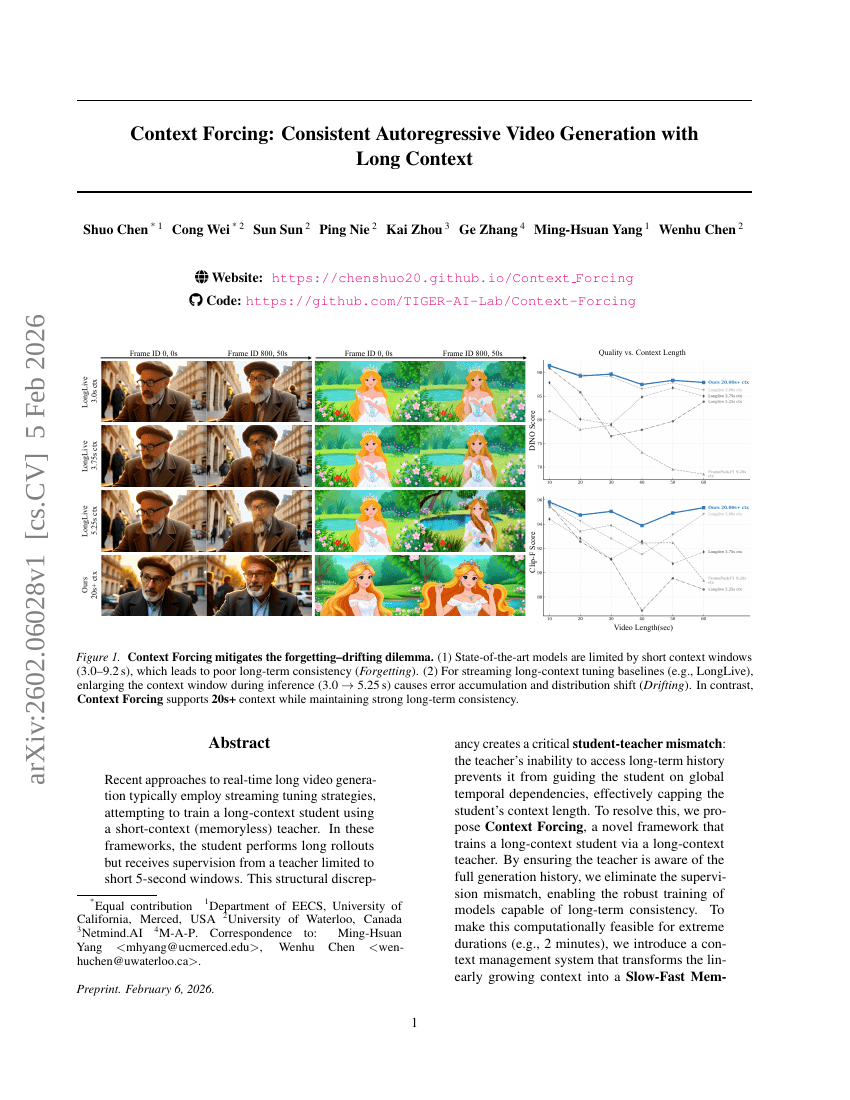
上下文强制:基于长上下文的一致性自回归视频生成
MemSkill:面向自演化智能体的内存技能学习与演化
长度无偏序列策略优化:揭示与控制RLVR中的响应长度变异
Spider-Sense:基于分层自适应筛选的高效Agent防御内在风险感知
CAR-bench:在现实世界不确定性下评估LLM Agent的一致性与限知性
基于延迟流建模的流式 Sequence-to-Sequence 学习
Kiss3DGen:将图像 Diffusion Models 重新用于 3D Asset 生成
基于 Cache 的推理与有状态 Conformer:面向流式自动语音识别的研究
用于 3D 生成的原生且紧凑的结构化 Latents
连续音频语言模型
在虚拟临床环境中演进交互式诊断 Agent
WeDLM:弥合扩散语言模型与标准因果注意力机制以实现快速推理
TurboDiffusion:通过100-200倍加速视频Diffusion模型
HunyuanVideo-Foley:基于表示对齐的多模态扩散模型用于高保真Foley音频生成
Fara-7B:一种用于计算机使用的高效Agent模型
Fun-ASR 技术报告
利用Gemini加速科学研究:案例研究与常用技术
通过策略拍卖实现小规模Agent的扩展
Vibe AIGC:通过智能体编排实现内容生成的新范式
PaperSearchQA:基于RLVR的科学论文搜索与推理学习
EgoActor:通过视觉-语言模型将任务规划嵌入空间感知的视角动作中以实现类人机器人
A-RAG:通过分层检索接口实现智能体增强型检索生成的扩展
Quant VideoGen:通过2比特KV缓存量化实现自回归长视频生成
SoMA:一种用于机器人软体操作的真实到仿真神经模拟器
面向视角自适应的人体视频生成的3D感知隐式运动控制
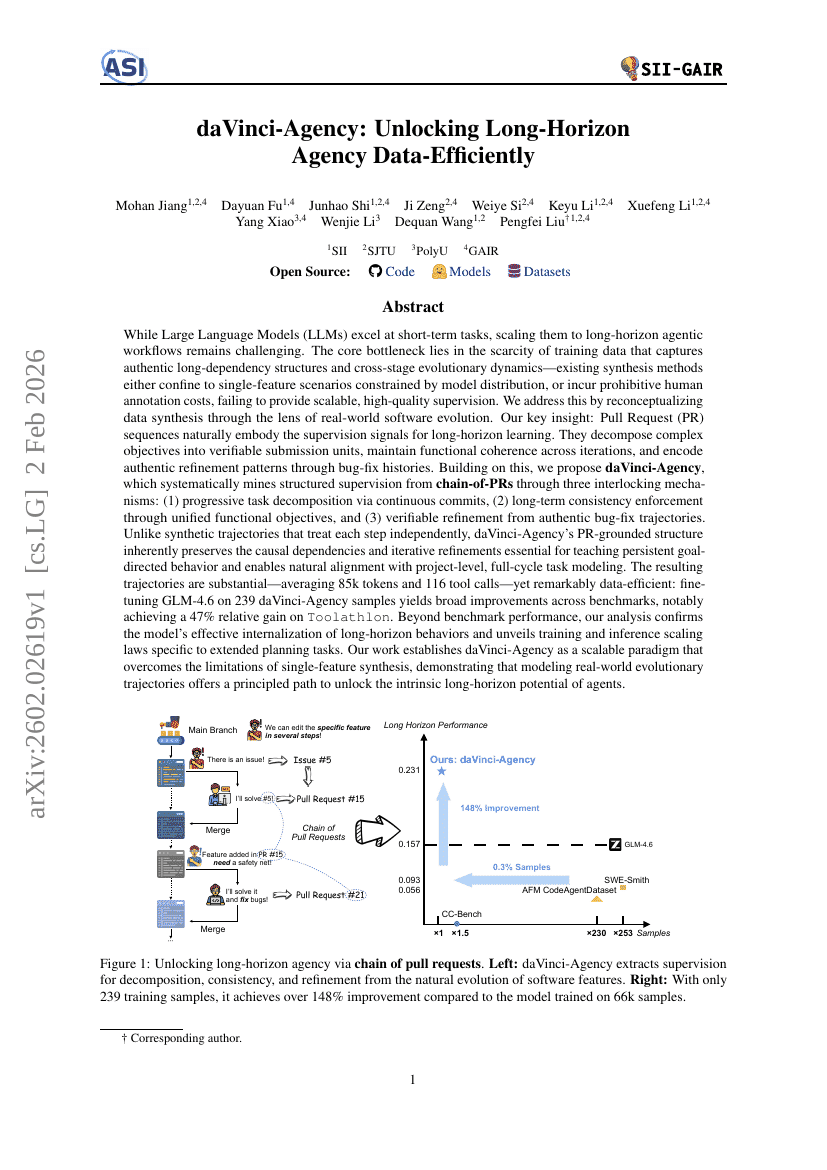
daVinci-Agency:高效解锁长周期代理数据
世界模型的研究并不仅仅是将世界知识注入特定任务中
AlphaEdit:针对语言模型的零空间约束知识编辑
在13个参数中进行推理学习
DFlash:用于快速推测解码的块扩散方法
上下文强制:基于长上下文的一致性自回归视频生成
MemSkill:面向自演化智能体的内存技能学习与演化
长度无偏序列策略优化:揭示与控制RLVR中的响应长度变异
Spider-Sense:基于分层自适应筛选的高效Agent防御内在风险感知
CAR-bench:在现实世界不确定性下评估LLM Agent的一致性与限知性
基于延迟流建模的流式 Sequence-to-Sequence 学习
Kiss3DGen:将图像 Diffusion Models 重新用于 3D Asset 生成
基于 Cache 的推理与有状态 Conformer:面向流式自动语音识别的研究
用于 3D 生成的原生且紧凑的结构化 Latents
连续音频语言模型
在虚拟临床环境中演进交互式诊断 Agent
WeDLM:弥合扩散语言模型与标准因果注意力机制以实现快速推理
TurboDiffusion:通过100-200倍加速视频Diffusion模型
HunyuanVideo-Foley:基于表示对齐的多模态扩散模型用于高保真Foley音频生成
Fara-7B:一种用于计算机使用的高效Agent模型
Fun-ASR 技术报告
利用Gemini加速科学研究:案例研究与常用技术
通过策略拍卖实现小规模Agent的扩展
Vibe AIGC:通过智能体编排实现内容生成的新范式
PaperSearchQA:基于RLVR的科学论文搜索与推理学习
EgoActor:通过视觉-语言模型将任务规划嵌入空间感知的视角动作中以实现类人机器人
A-RAG:通过分层检索接口实现智能体增强型检索生成的扩展
Quant VideoGen:通过2比特KV缓存量化实现自回归长视频生成
SoMA:一种用于机器人软体操作的真实到仿真神经模拟器
面向视角自适应的人体视频生成的3D感知隐式运动控制
daVinci-Agency:高效解锁长周期代理数据
世界模型的研究并不仅仅是将世界知识注入特定任务中