Command Palette
Search for a command to run...
EgoPush:面向移动机器人的端到端第一人称多物体重排学习
EgoPush:面向移动机器人的端到端第一人称多物体重排学习
Boyuan An Zhexiong Wang Yipeng Wang Jiaqi Li Sihang Li Jing Zhang Chen Feng
摘要
人类能够利用自身中心(egocentric)的感知能力,在杂乱环境中重新排列物体,即使存在遮挡也能完成操作,而无需依赖全局坐标。受此能力的启发,我们研究了移动机器人在单个自身中心摄像头视角下,执行长时程、多物体非抓取式重排任务的策略学习方法。为此,我们提出了EgoPush——一种无需依赖易在动态场景中失效的显式全局状态估计的、基于自身中心感知的重排策略学习框架。EgoPush设计了一个以物体为中心的隐空间(object-centric latent space),用于编码物体之间的相对空间关系,而非绝对位姿。这一设计使得一个具备优势信息的强化学习(RL)教师模型能够从稀疏的关键点中联合学习隐状态与移动动作,随后将该知识蒸馏为一个完全基于视觉的、无需显式状态估计的学生策略。为缩小全知教师与部分可观测学生之间的监督差距,我们限制教师的观测仅限于视觉可及的线索,从而诱导出可从学生视角恢复的主动感知行为。为解决长时程任务中的信用分配难题,EgoPush采用时间衰减的、阶段局部的完成奖励机制,将重排任务分解为多个阶段级子问题。大量仿真实验表明,EgoPush在成功率方面显著优于端到端强化学习基线方法,消融实验进一步验证了各项设计选择的有效性。此外,我们在真实世界的移动平台上成功实现了零样本的“仿真到现实”(sim-to-real)迁移。相关代码与演示视频已公开,详见:https://ai4ce.github.io/EgoPush/。
一句话总结
纽约大学的研究人员提出了 EgoPush,这是一种教师-学生框架,使移动机器人仅通过以自我为中心的视觉即可重新排列多个物体。该框架通过学习以物体为中心的潜在表示并提炼出确保视觉可恢复行为的约束教师策略,在 TurtleBot 上实现了稳健的仿真到现实迁移。
主要贡献
- EgoPush 使移动机器人仅通过以自我为中心的视觉即可执行长视野多物体重排任务,通过学习编码相对空间关系的以物体为中心的潜在表示,消除了在纹理稀疏、易遮挡环境中对脆弱全局状态估计的依赖。
- 该框架引入了一种受约束的教师强化学习方法,限制特权教师仅使用以自我为中心的观测,确保其行为可被视觉学生恢复,并促进与现实世界部分可观测性一致的主动感知策略。
- EgoPush 通过分阶段训练与时间衰减奖励改进长视野信用分配,在仿真中实现了比端到端强化学习基线更高的成功率,并在 TurtleBot 平台上展示了零样本仿真到现实迁移能力。
引言
作者利用以自我为中心的视觉使移动机器人能够在无需全局状态估计的情况下执行长视野多物体重排——这一能力对现实部署至关重要,因为在遮挡和稀疏纹理环境中,传统建图方法不可靠。先前的方法要么依赖脆弱的全局状态估计器,要么在使用端到端视觉强化学习时因部分可观测性导致样本效率低下和不稳定。EgoPush 通过引入编码相对空间关系的以物体为中心的潜在空间、仅使用以自我为中心观测的约束教师策略以及带时间衰减奖励的分阶段训练来解决这些缺陷,从而改进长视野信用分配。该框架实现了稳健的仿真到现实迁移,并在成功率和样本效率方面优于基线方法。
数据集
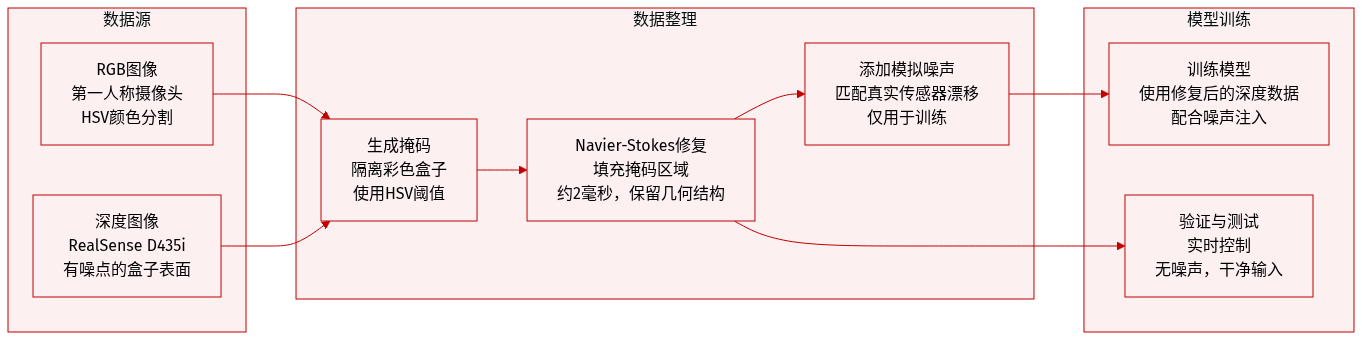
作者使用在 3m × 3m 灰色竞技场中收集的自定义数据集训练和评估其以自我为中心的机器人操作系统,竞技场中包含五个颜色编码的盒子(红、绿、蓝、紫、棕)。数据组成与处理方式如下:
-
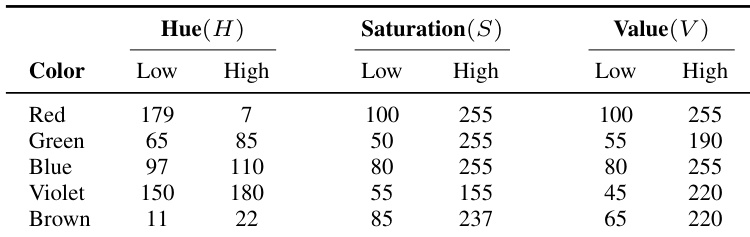
RGB 图像:从机器人的以自我为中心相机捕获。服务器应用基于 HSV 的颜色分割,将每个盒子从背景中分离出来,生成二值掩码。每种颜色的具体 HSV 阈值定义在表 VI 中。
-
深度图像:来自 Intel RealSense D435i 的原始深度数据在盒子顶部表面噪声严重。作者测试了四种后处理方法:
- 基于学习的去噪(CDM):重建质量高,但速度太慢(~50ms/帧),不适合实时控制。
- 板载滤波:在 Jetson Nano 上应用孔洞填充和时空滤波;导致闪烁和丢帧,延迟约 15ms。
- 中值深度填充(基线):用中值深度值替换掩码区域;稳定且快速(~2ms),但丢失几何细节。
- Navier-Stokes 修复(最终选择):使用流体动力学修复掩码区域;比中值填充保留更多几何信息,比板载滤波更稳定,运行速度约 2ms。训练时注入噪声以模拟现实条件。
-
数据使用:系统使用 RGB 掩码过滤深度图像,Navier-Stokes 修复后的深度图在训练和实时控制中输入模型。该策略在几何保真度、稳定性和低延迟之间取得平衡,支持有效的仿真到现实迁移。
方法
作者采用名为 EgoPush 的两阶段蒸馏框架,专为在以自我为中心视觉约束下执行长视野多物体非抓取式重排任务设计。该框架将学习解耦为特权教师阶段和视觉学生阶段,实现零样本仿真到现实迁移。整体架构确保学生策略仅基于以自我为中心的 RGB-D 输入训练,可复制教师行为,同时在感知约束下运行,模拟现实世界传感器限制。
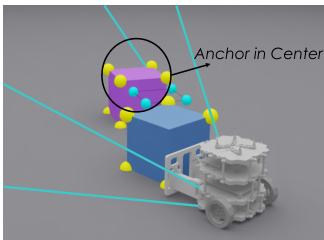
在第一阶段,教师策略通过在线强化学习训练,使用稀疏的特权 3D 关键点编码物体几何和相对姿态。这些关键点分为四类语义组:活动物体、锚点、障碍物和参考目标。为确保教师行为可被学生视觉恢复,作者对教师的观测空间施加两个关键约束:虚拟以自我为中心的视场(FOV)遮罩和中心门控可见性。FOV 遮罩将观测限制在基于机器人位姿的视锥内及最大范围内,近似相机可见性。中心门控可见性条件确保仅当锚点物体位于虚拟 FOV 中央区域时才揭示参考目标关键点,防止教师在不关注锚点的情况下利用目标。如下图所示,该约束观测空间迫使教师依赖任务相关且可恢复的线索。
教师的状态估计器实现为 PointNet,处理每个语义组的可变大小点集,通过共享权重 MLP 和对称池化生成组级潜在嵌入 Ztk。这些潜在嵌入与前一动作 at−1 拼接后输入 MLP 策略头,输出 2D 连续动作 at=[vt,ωt],对应差速底盘的线速度和角速度。奖励函数通过阶段对齐监督促进长视野学习:包括时间加权完成奖励(用于到达和放置活动物体)、通过阶段门控距离减少的进度塑形、平滑性惩罚(抑制突兀动作)以及接近目标时的减速奖励(鼓励稳定停驻)。教师使用 Proximal Policy Optimization (PPO) 训练,并对物理参数应用域随机化。
在第二阶段,学生策略通过监督学习从教师蒸馏,仅使用以自我为中心的 RGB-D 观测。RGB 流仅用于实例分割,将物体分配到语义组(活动、锚点、障碍物),而深度图按组掩码和聚合,生成固定维度的深度层 d~tk。这些深度层作为 CNN 基础状态估计器的输入,替代教师的 PointNet。学生的策略头架构与教师的 MLP 相同,其权重从教师学习的参数初始化以加速收敛。学生使用在线 DAgger 风格过程训练:每次迭代中,教师在线查询以生成当前状态的动作标签,学生执行监督更新。为弥合教师特权潜在空间与学生视觉输入之间的表征差距,作者引入关系蒸馏损失。该损失最小化教师与学生共享语义组潜在嵌入(活动、锚点、障碍物)的成对余弦相似性矩阵的 Frobenius 范数,鼓励学生复制教师对空间关系的感知,而无需显式访问参考目标。如框架图所示,这种关系对齐使学生能够隐式编码目标导向行为。
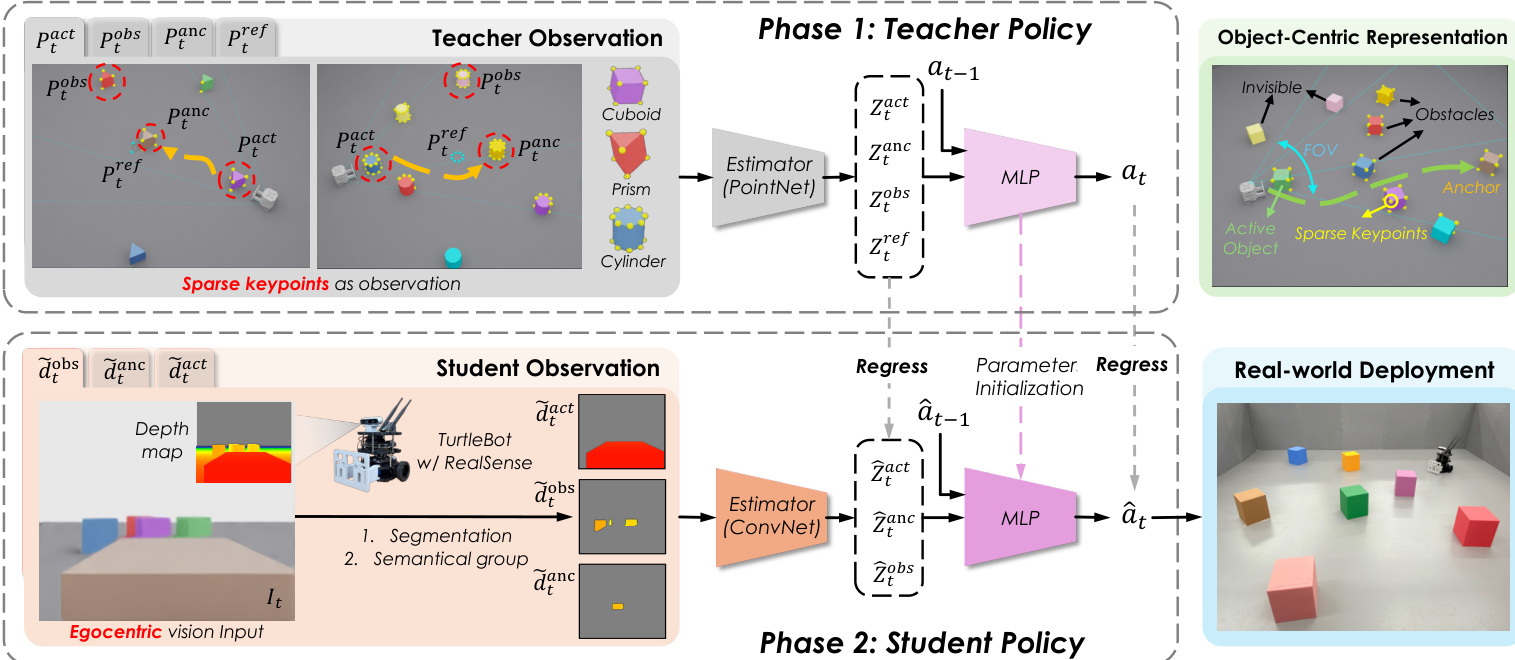
在现实部署中,学生策略运行于安装在配备前推器的 TurtleBot 上的 RealSense 相机提供的 RGB-D 输入。推器缓解了深度相机的感知盲区,但因延长力臂引入动力学挑战,学习策略通过自适应控制补偿。蒸馏过程中进一步对与相机位姿相关的观测应用域随机化以增强鲁棒性。学生无需微调即可泛化到现实条件,得益于结构化蒸馏过程及仿真与现实感知约束的一致性。
实验
- EgoPush 在仿真和现实环境中成功执行具有多样物体几何形状的多物体重排,目标构型精度高。
- 约束强化学习教师的观测空间通过使监督与学生的部分可观测性对齐,显著提升学生学习效果,优于无约束教师变体。
- 将长视野任务分解为顺序子任务并采用阶段级时间衰减奖励,加速强化学习收敛并增强信用分配,实现稳定高效学习。
- 添加关系蒸馏损失有助于学生继承教师的空间推理能力,在几何一致性至关重要的复杂非对称任务中尤为关键。
- 基线方法(包括端到端视觉强化学习和经典建图方法)因长视野推理能力差、部分可观测性和漂移引起的状体不一致而无法可靠解决任务。
- 现实部署展示零样本迁移成功,成功率 80%,虽有轻微偏差,但扭矩限制降低了鲁棒性。
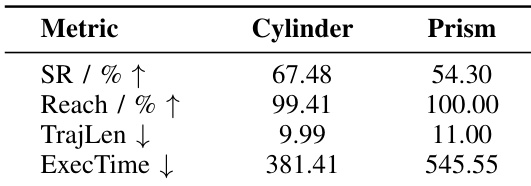
- 学生策略在到达新物体形状(圆柱体、棱柱)方面泛化良好,但因几何依赖接触动力学,在最终对齐上表现不佳。
- 对长方体的精度评估显示学生实现约 86.7% 的归一化精度,确认其相对于不可见目标的精确定位能力。
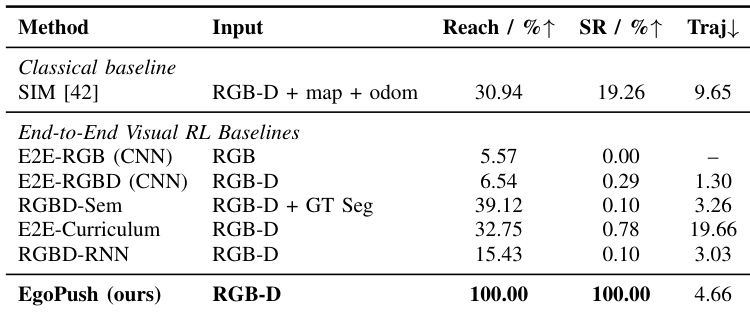
作者使用简化双物体推移任务对比 EgoPush 与经典和端到端视觉强化学习基线,所有方法均在以自我为中心的 RGB-D 感知下运行。结果表明,基线方法仅实现有限的物体到达率,均无法完成完整推移与对齐任务,而 EgoPush 以高效轨迹实现完美成功率和到达率。这凸显结构化蒸馏和空间推理对解决部分可观测性下长视野重排任务的关键作用。
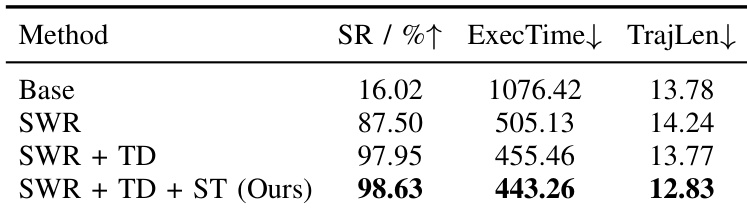
作者采用渐进式奖励塑形方法分解长视野任务,表明添加阶段奖励和时间衰减显著提升学习效率。最终方法在每阶段边界重置衰减计划,相比消融变体实现接近饱和性能、更快收敛和更低执行时间。结果确认结构化信用分配对解决稀疏反馈下复杂顺序重排任务至关重要。
作者对强化学习教师使用受限观测空间以与学生的部分可观测性对齐,显著提升学生表现,尽管略微降低教师效率。结果表明,移除中心门控可见性或全局 FOV 约束会导致学生成功率大幅下降,凸显观测设计对有效蒸馏的重要性。完整方法训练的学生实现 70.7% 成功率,而缺少关键约束的变体无法泛化或学习有意义行为。

作者在现实实验中使用 HSV 阈值范围分割彩色盒子,调整色相值以考虑圆形色彩空间边界,尤其针对红色。这些范围设计确保在不同光照和相机条件下一致的物体检测。所选阈值反映经验调优,以在多种物体颜色间平衡精度与召回率。
作者评估学生策略在非长方体几何物体上的表现,发现模型可靠到达目标物体,但圆柱体和棱柱的成功率显著下降,因在推移过程中维持稳定接触和精确对齐存在挑战。棱柱的执行时间和轨迹长度增加,表明几何复杂性在长视野交互中放大控制误差。结果表明策略的感知和接近能力泛化良好,但精细操作仍对物体形状敏感。