Command Palette
Search for a command to run...
ARLArena:一种用于稳定智能体强化学习的统一框架
ARLArena:一种用于稳定智能体强化学习的统一框架
摘要
代理强化学习(Agentic Reinforcement Learning, ARL)作为一种极具前景的范式,正迅速受到关注,其旨在训练智能体完成复杂、多步骤的交互任务。尽管早期研究已展现出令人鼓舞的成果,但ARL仍存在高度不稳定性,常导致训练崩溃。这种不稳定性限制了其在更大规模环境和更长交互时域下的可扩展性,也制约了对算法设计选择的系统性探索。本文首先提出ARLArena——一个稳定训练方案与系统化分析框架,旨在在受控且可复现的环境中深入研究训练稳定性问题。ARLArena首先构建了一个清晰、标准化的测试平台;随后,我们将策略梯度方法分解为四个核心设计维度,并系统评估各维度在性能与稳定性方面的表现。通过这一细粒度的分析,我们提炼出对ARL的统一理解,并进一步提出SAMPO——一种旨在缓解ARL中主导不稳定性来源的稳定代理策略优化方法。实验结果表明,SAMPO在多种代理任务中均展现出一致的稳定训练过程与优异的性能表现。总体而言,本研究为ARL提供了统一的策略梯度视角,同时为构建稳定、可复现的大语言模型(LLM)驱动的智能体训练流水线提供了切实可行的指导。
一句话总结
加州大学洛杉矶分校与威斯康星大学麦迪逊分校的研究人员提出了 ARLArena —— 一个系统性诊断智能体强化学习(ARL)不稳定性的框架,并提出了 SAMPO —— 一种结合序列级裁剪、细粒度优势设计和动态过滤的稳定策略优化器,能够在 ALFWorld 和 WebShop 等多轮任务中实现可复现且高性能的训练。
主要贡献
- ARLArena 引入了一个标准化测试平台和诊断框架,可隔离并分析四个核心策略梯度设计维度,从而在 ALFWorld 和 Sokoban 等多轮任务中实现可复现的智能体强化学习稳定性评估。
- 通过系统性分解,该研究识别出关键稳定性驱动因素:序列级裁剪优于宽容裁剪、环境感知的优势设计和动态采样——最终形成 SAMPO,这是一种可缓解训练崩溃的新型策略优化方法。
- SAMPO 展现出一致的训练稳定性,并在多个智能体基准测试中平均比 GRPO 提升 25.2% 的性能,验证了其在长视野、交互式大语言模型代理训练中的鲁棒性和有效性。
引言
作者利用智能体强化学习(ARL)训练大型语言模型,以完成网页导航和工具使用等复杂多步交互任务,其中长视野决策与规划至关重要。以往的 ARL 方法因累积误差、稀疏奖励和非平稳动态而存在严重训练不稳定性,限制了其可扩展性和可复现性。为解决此问题,他们提出了 ARLArena —— 一个标准化测试平台和四维策略梯度分析框架,用于隔离并评估关键设计选择。其主要贡献是 SAMPO —— 一种结合序列级裁剪、环境感知优势设计和动态采样的稳定策略优化方法,可在多样化的智能体环境中持续提升训练稳定性和性能。
数据集
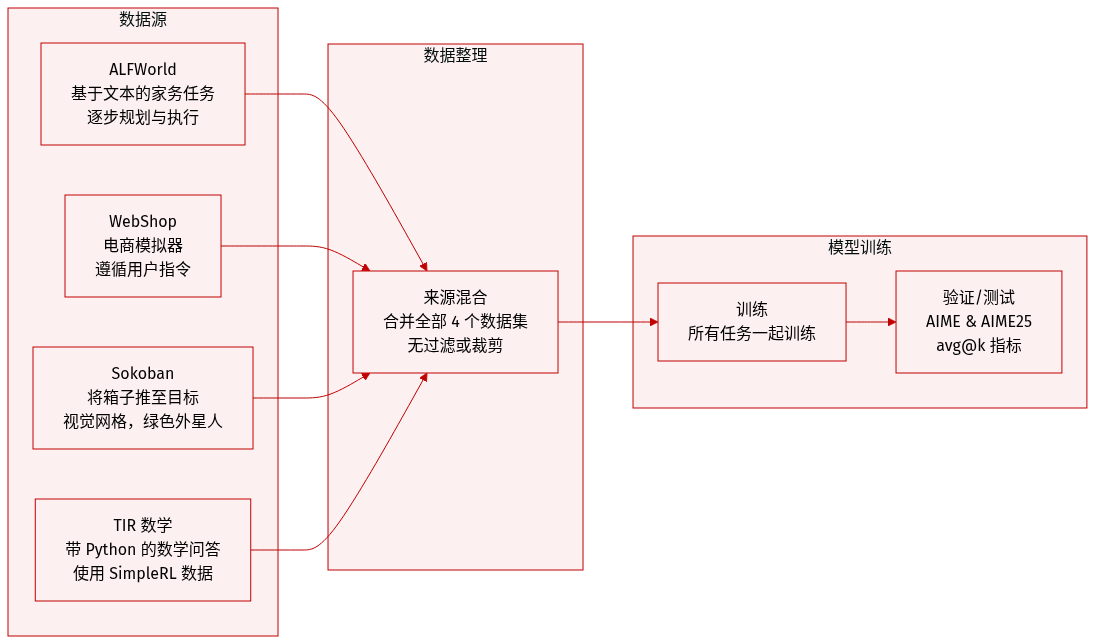
作者使用一个由四个不同环境组成的多任务数据集,每个环境旨在评估不同的推理与决策能力:
-
ALFWorld(Shridhar 等,2020):基于文本的交互环境,模拟家庭任务。代理需通过顺序决策完成目标。未指定数据规模或过滤细节;用于训练和评估规划与语言理解能力。
-
WebShop(Yao 等,2022):大规模电商模拟器,代理需理解用户指令并导航商品选择与购买流程。未提供明确的数据规模或过滤规则;用于测试在真实场景中的指令遵循与顺序决策能力。
-
Sokoban(Schrader,2018):经典的 2D 网格谜题,代理需将箱子推至目标格。状态以视觉形式呈现;动作为离散移动。视觉元素包括绿色外星人角色(代理)、黄色箱子和红色边框的黑色目标格。未提供数据规模或过滤细节;用于评估空间推理与规划能力。
-
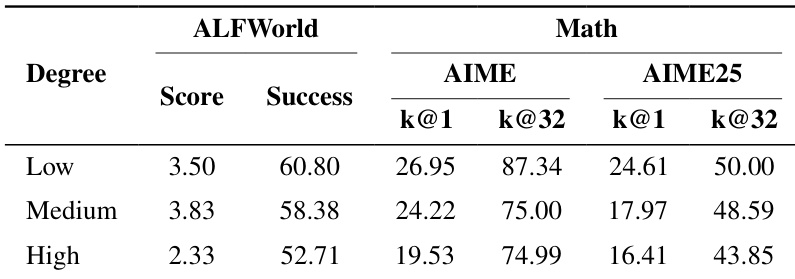
TIR Math(Xue 等,2025):聚焦数学问答,使用 Python 作为符号与中间推理工具。训练数据改编自 SimpleRL(Zeng 等,2025);在 AIME 和 AIME25 基准上使用 avg@k 指标(Yu 等,2025b)进行评估。用于测试数学推理与工具整合能力。
本文未说明这些数据集的训练集划分比例、数据混合比例或预处理步骤(如裁剪或元数据构建)。Sokoban 中的视觉元素仅用于可解释性描述,未提及图像裁剪或变换。
方法
作者采用结构化多部分框架设计并评估面向大语言模型的智能体强化学习策略优化方法。整体架构分为四个概念部分:测试平台构建、策略梯度维度分析、实证发现与统一算法合成。
请参考框架图,该图展示了从测试平台初始化到梯度维度分解,最终形成 SAMPO 算法的流程。流程始于第 1 部分,通过行为克隆、格式惩罚强制、辅助 KL 正则化和超参数调优来稳定测试平台。行为克隆使用预训练模型的监督轨迹初始化策略,确保代理从有效行为流形开始。格式惩罚强制结构化输出(显式 和 标签),减少无效 rollout。辅助 KL 损失约束策略偏离参考模型,保留预训练知识的同时允许探索。最后,搜索任务特定超参数网格,确保方法间公平评估。
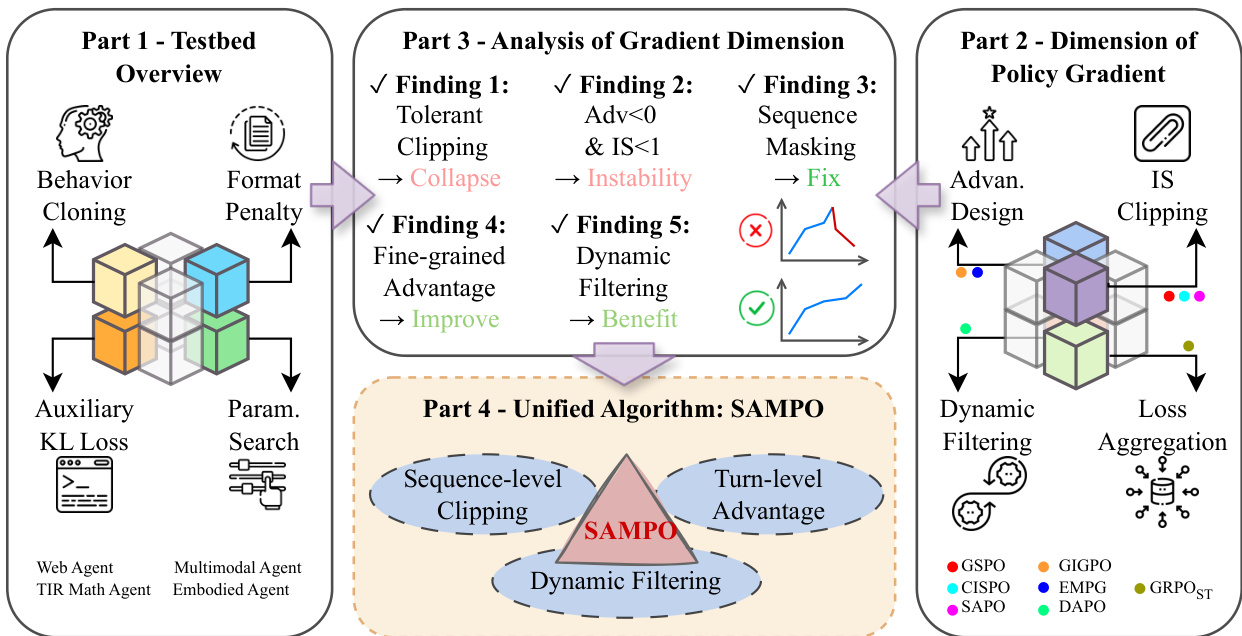
第 2 部分将策略梯度分解为四个正交设计维度:损失聚合、重要性采样(IS)裁剪、优势设计和动态轨迹过滤。每个维度独立探索,以隔离其对训练稳定性和性能的影响。损失聚合方案包括 token-mean 和 sequence-mean 变体,区别在于如何加权轨迹中的 token。IS 裁剪方法从 token 级硬裁剪(GRPO)到序列级裁剪(GSPO),变体如 CISPO 和 SAPO 引入了 stop-gradient 或软衰减机制。优势设计结合分层信用分配(GiGPO)或熵调制信号(EMPG),以应对长视野设置中的稀疏奖励。动态过滤移除奖励相同的退化轨迹并重新采样,以增强梯度信息量。
第 3 部分综合这些维度的消融研究实证发现。关键见解包括:(1)训练崩溃由低 IS 比率的负优势序列驱动,可通过序列掩码缓解;(2)序列级裁剪在长视野稳定性上优于 token 级裁剪;(3)细粒度优势估计改善信用分配;(4)动态过滤通过移除无信息样本提升梯度质量。
第 4 部分将这些发现整合为 SAMPO —— 一种统一的策略优化范式。SAMPO 结合三个核心组件:序列级裁剪、回合级优势估计和动态轨迹过滤。损失函数表述如下:
L(θ)=∑i=1NTi1∑i=1N∑t=0Ti−1min(si(θ)Ai′,clip(si(θ),1±ε)Ai′),s.t.0<∣{y∣is_equivalent(a,y)}∣<G.其中,si(θ) 是轨迹 i 上 token 级重要性比率的几何平均,确保序列级一致性。优势 Ai′ 结合轨迹级和步级信号:Ai′=Ai+ω⋅Astep(y^i,k),其中 ω 控制细粒度信用的贡献。约束确保仅保留具有混合成功结果的轨迹,促进信息丰富的梯度更新。这种集成设计可在多样化的智能体任务中实现稳定、可扩展的训练。
实验
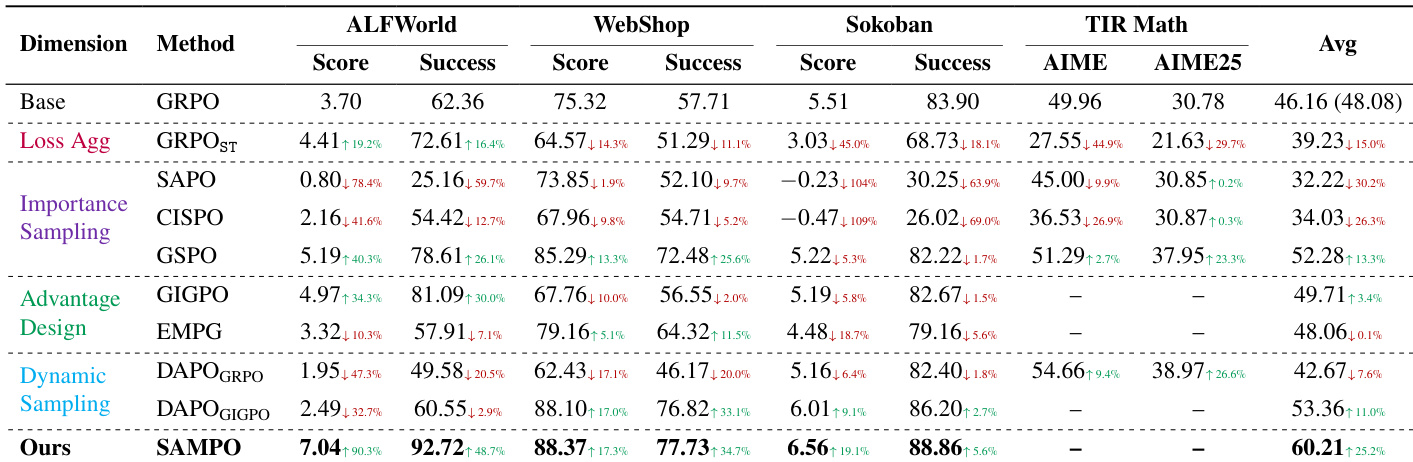
- 带序列级裁剪的 GSPO 实现最稳定且性能最高的训练,平均优于其他 IS 变体 13.3%,并避免了 CISPO 和 SAPO 等宽容裁剪方法中的崩溃。
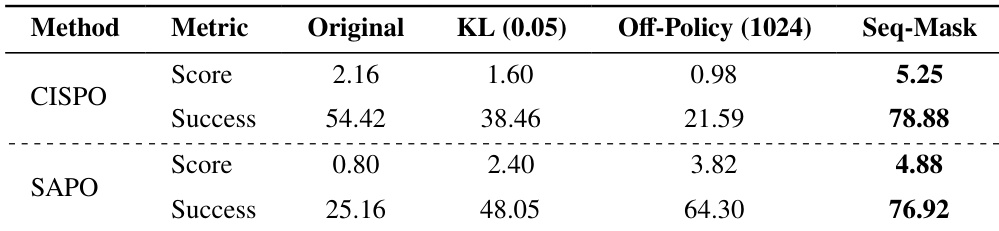
- 宽容裁剪(CISPO、SAPO)可实现快速早期收益,但因梯度爆炸和 KL 散度导致训练崩溃,主要由低重要性比率的负优势 token 驱动。
- 序列掩码(SAPO_SM、CISPO_SM)通过过滤有害样本有效稳定宽容裁剪方法,使其性能恢复至 GSPO 水平。
- GIGPO 整合细粒度环境优势信号,在 ALFWorld 上比 GRPO 提升 16.4% 性能,增强稀疏奖励处理能力。
- 动态过滤仅在与 GIGPO 配对时提升性能,因其多样化的优势信号保留格式学习;对 GRPO 则有害,因移除关键格式修正信号。
- 序列均值损失聚合在数学等变长任务上降低性能,凸显 token 级加权的重要性。
- 离策略陈旧性对性能产生负面影响;较低陈旧性(更小 rollout 批次)在 ALFWorld 和 TIR Math 中均带来更高成功率。
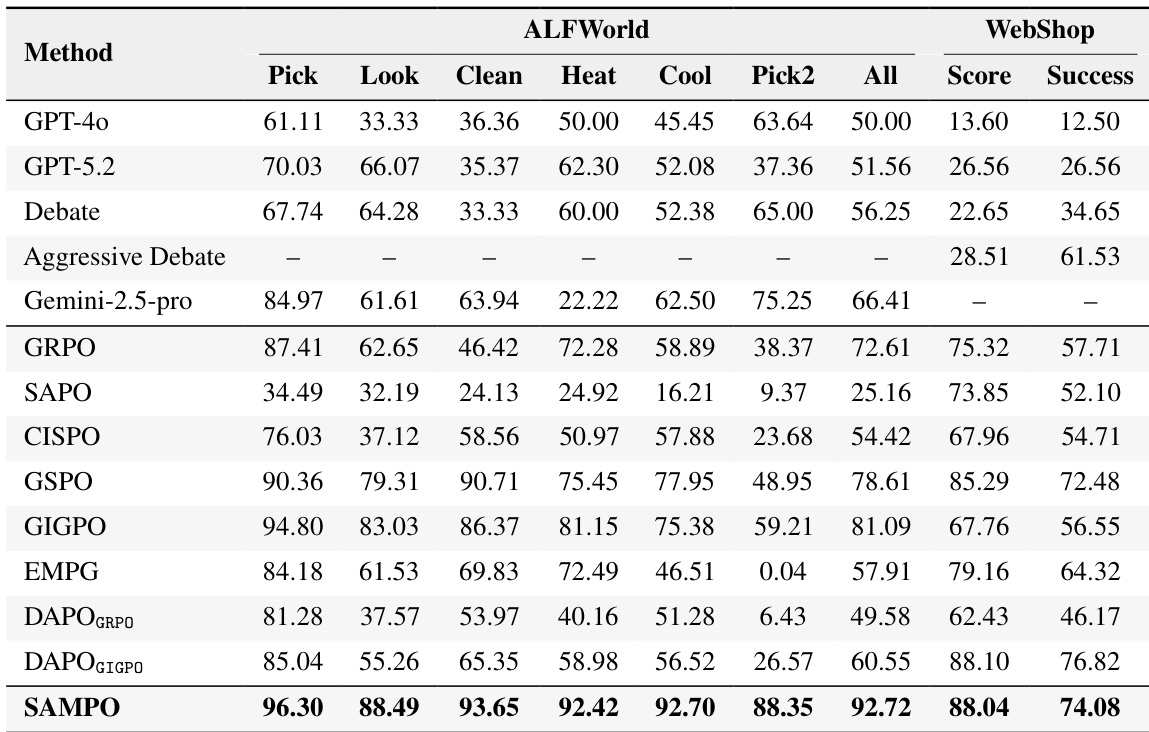
- SAMPO 训练的 Qwen3-4B 在 ALFWorld 和 WebShop 上优于更大的闭源模型(GPT-5.2、o3、Gemini 2.5 Pro),表明稳定 RL 训练可超越推理时工程。
- 发现具有尺度不变性:Qwen3-8B 实验确认序列级裁剪、优势设计和动态过滤在更大规模下仍具优势,SAMPO 保持最优。
- RL 训练重塑代理行为:减少 WebShop 中低效分页循环,提升 ALFWorld 中对象交互,但残留问题如回溯和过早购买仍存在。
作者在多个智能体任务中评估多种策略优化方法,发现序列级裁剪(GSPO)产生最稳定训练和最高性能,而宽容裁剪方法(CISPO、SAPO)尽管初期收益,但因不稳定而崩溃。为这些宽容方法引入序列掩码可恢复稳定性和性能,使其接近 GSPO。其最终方法 SAMPO 结合序列级裁剪、细粒度优势设计和动态过滤,在各项任务中取得最佳整体结果,优于基线方法和更大闭源模型。
结果表明,较低的离策略陈旧性在 ALFWorld 和数学任务中均提升性能,低陈旧性设置下成功率和准确率更高。陈旧性增加与性能下降相关,表明策略更新受益于更新鲜的 rollout 数据。这种敏感性凸显了在智能体强化学习中管理离策略效应的重要性。
作者在 ALFWorld 上评估 CISPO 和 SAPO 的稳定化策略,发现序列掩码显著提升两种方法的成功率和得分,而增加 KL 惩罚或离策略批大小则降低性能。结果表明,掩码有害的负优势序列比正则化或批大小调整更有效恢复训练稳定性。
作者在多个智能体任务中评估多种策略优化策略,发现带序列级裁剪的 GSPO 通过稳定训练和提升最终成功率持续优于其他方法。宽容裁剪变体如 SAPO 和 CISPO 显示早期收益,但因负优势样本导致不稳定而崩溃,序列掩码可有效缓解。结果确认,稳定 ARL 训练更依赖于精心设计的重要性采样,而非激进探索或损失聚合选择。
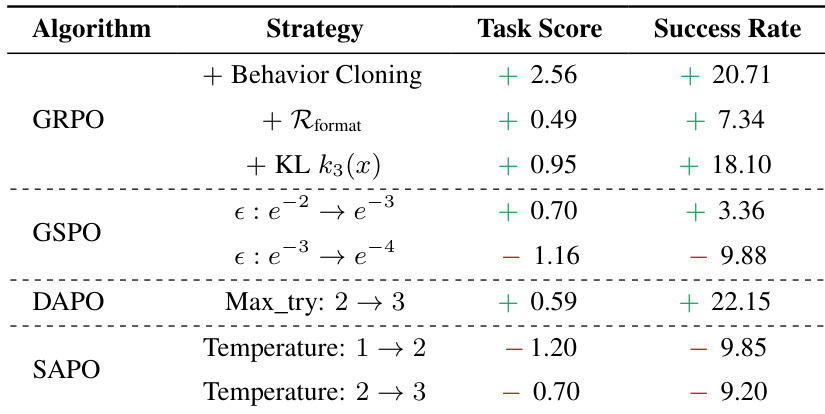
作者使用一套智能体任务评估策略优化方法,发现 GSPO 和 SAMPO 通过序列级裁剪和精细优势设计持续稳定训练并优于其他方法。结果表明,SAPO 和 CISPO 等宽容裁剪方法初期快速提升,但因负优势样本导致不稳定而崩溃,序列掩码可有效恢复性能。SAMPO 实现最先进的成功率,超越闭源模型和多智能体系统,表明原理性 RL 训练可优于推理时工程。