HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

迈向可预测、对齐且可扩展的机器人学习

特征空间流匹配用于随机世界建模

MiMo-V2.5系列全流程推理优化:将混合滑动窗口注意力效率推向极限

TRACE:基于贡献估计的轮次级奖励分配方法用于长程智能体

KeyFrame-Compass:面向关键帧条件视频生成综合评估的基准

BadWAM:当世界-行动模型想象正确却行动错误时

SearchOS-V1:迈向稳健的开放域信息搜索智能体协作

SEED:面向智能体强化学习的自进化在线策略蒸馏

VideoChat3:面向高效通用视频理解的全开源视频多模态大语言模型

LongStraw:固定GPU预算下超越200万Token的长上下文强化学习

遥感中的深度学习:综述

基于深度神经网络的语音增强回归方法

语音识别中声学建模的深度神经网络

RoboTTT:机器人策略的上下文扩展

SWE-agent:智能体-计算机接口实现自动化软件工程

向量空间中词表示的高效估计

使用多尺度深度网络从单张图像预测深度图

TabNet:专注可解释的表格学习

AudioPaLM:一个能说会听的大型语言模型

SQuAD:面向文本机器理解的十万余问答数据集

DeepPose:基于深度神经网络的人体姿态估计

现代智能体系统中的自我改进:综述

面向智能体强化学习的单次异步优化方法
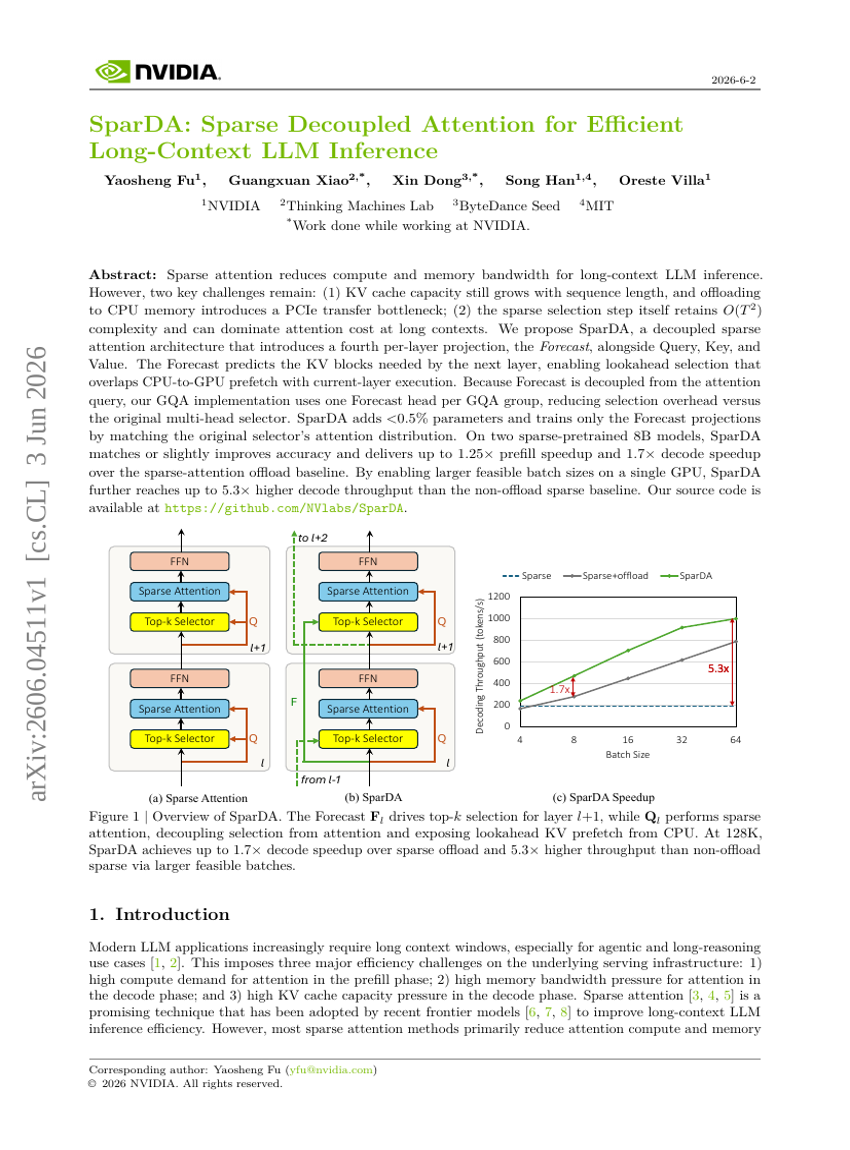
SparDA:面向高效长上下文大语言模型推理的稀疏解耦注意力机制

MetaView:基于尺度感知隐式几何先验的单目新视角合成

PolicyShiftGuard:政策自适应图像护栏的基准测试与改进

KnowAct-GUIClaw:知深行远,具备自进化记忆与技能的个人GUI助手
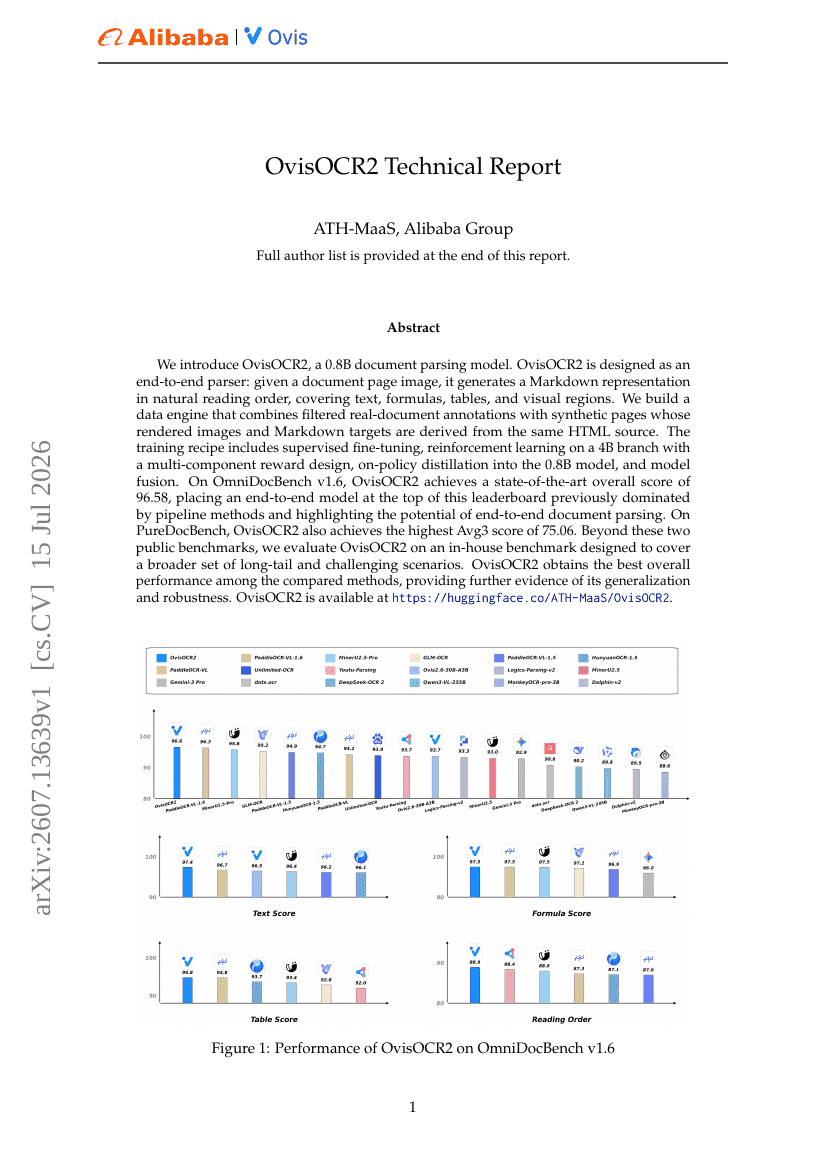
OvisOCR2 技术报告
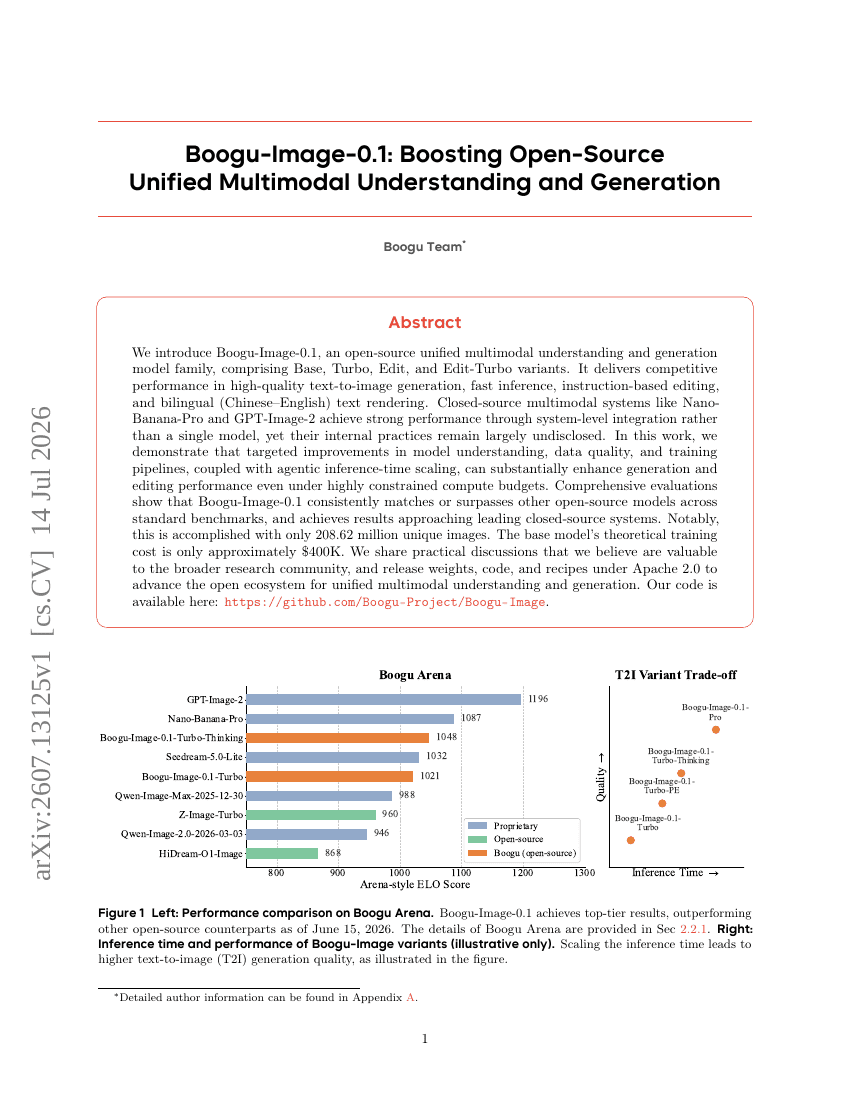
Boogu-Image-0.1:推动开源统一多模态理解与生成

Harness Handbook:让不断演进的智能体框架变得可读、可导航、可编辑

Qwen-Music 技术报告

用于探索、净化与模型合并的谱重连
迈向可预测、对齐且可扩展的机器人学习
特征空间流匹配用于随机世界建模
MiMo-V2.5系列全流程推理优化:将混合滑动窗口注意力效率推向极限
TRACE:基于贡献估计的轮次级奖励分配方法用于长程智能体
KeyFrame-Compass:面向关键帧条件视频生成综合评估的基准
BadWAM:当世界-行动模型想象正确却行动错误时
SearchOS-V1:迈向稳健的开放域信息搜索智能体协作
SEED:面向智能体强化学习的自进化在线策略蒸馏
VideoChat3:面向高效通用视频理解的全开源视频多模态大语言模型
LongStraw:固定GPU预算下超越200万Token的长上下文强化学习
遥感中的深度学习:综述
基于深度神经网络的语音增强回归方法
语音识别中声学建模的深度神经网络
RoboTTT:机器人策略的上下文扩展
SWE-agent:智能体-计算机接口实现自动化软件工程
向量空间中词表示的高效估计
使用多尺度深度网络从单张图像预测深度图
TabNet:专注可解释的表格学习
AudioPaLM:一个能说会听的大型语言模型
SQuAD:面向文本机器理解的十万余问答数据集
DeepPose:基于深度神经网络的人体姿态估计
现代智能体系统中的自我改进:综述
面向智能体强化学习的单次异步优化方法
SparDA:面向高效长上下文大语言模型推理的稀疏解耦注意力机制
MetaView:基于尺度感知隐式几何先验的单目新视角合成
PolicyShiftGuard:政策自适应图像护栏的基准测试与改进
KnowAct-GUIClaw:知深行远,具备自进化记忆与技能的个人GUI助手
OvisOCR2 技术报告
Boogu-Image-0.1:推动开源统一多模态理解与生成
Harness Handbook:让不断演进的智能体框架变得可读、可导航、可编辑
Qwen-Music 技术报告
用于探索、净化与模型合并的谱重连