Command Palette
Search for a command to run...
HyTRec:一种用于长行为序列推荐的混合时序感知注意力架构
HyTRec:一种用于长行为序列推荐的混合时序感知注意力架构
Lei Xin Yuhao Zheng Ke Cheng Changjiang Jiang Zifan Zhang Fanhu Zeng
摘要
建模用户行为的长序列已成为生成式推荐领域的一项关键前沿课题。然而,现有方法面临两难困境:线性注意力机制虽具备高效性,但因状态容量有限而牺牲了召回精度;而Softmax注意力机制虽能实现高精度,却伴随着难以承受的计算开销。为应对这一挑战,我们提出HyTRec模型,其核心为一种混合注意力(Hybrid Attention)架构,能够显式地将长期稳定的偏好与短期的意图波动分离开来。通过将海量历史行为序列分配至线性注意力分支,同时保留专用的Softmax注意力分支用于处理近期交互,该方法在包含数万次交互的工业级场景下,有效恢复了精准召回能力。为进一步缓解线性层在捕捉快速兴趣漂移方面的滞后问题,我们设计了时序感知的增量网络(Temporal-Aware Delta Network, TADN),可动态增强新近行为信号的权重,同时有效抑制历史噪声的影响。在工业级数据集上的实证结果表明,本模型在保持线性推理速度的同时,显著优于多个强基线方法,尤其在超长序列用户上,命中率(Hit Rate)提升超过8%,展现出卓越的效率与性能平衡。
一句话总结
来自得物、武汉大学、中国科学技术大学和北京航空航天大学的研究人员提出了 HyTRec,这是一种混合注意力模型,通过线性与 softmax 分支解耦长期偏好与短期意图,并结合 TADN 实现动态信号加权,在超长序列上实现 8% 以上的命中率提升,同时保持线性推理速度。
主要贡献
- HyTRec 引入了一种混合注意力架构,将长期历史序列分配给线性注意力,近期交互分配给 softmax 注意力,解决了效率与精度的权衡问题,同时可处理长达万次交互的序列。
- 时序感知差分网络(TADN)通过指数门控机制动态放大新鲜行为信号,减少捕捉快速兴趣漂移的延迟,并抑制过时交互带来的噪声。
- 在工业级电商数据集上评估,HyTRec 在超长序列用户上实现超过 8% 的更高命中率,同时保持线性推理速度,在效率和准确性上均优于强基线模型。
引言
作者利用生成式推荐系统中对建模超长用户行为序列日益增长的需求,其中同时捕捉长期偏好与短期意图变化对准确预测下一项至关重要。以往方法面临权衡:线性注意力模型可高效扩展但损失检索精度,而 softmax 注意力虽保持保真度但计算成本高昂,且两者均难以良好处理快速兴趣漂移。HyTRec 通过引入混合注意力架构解决此问题:将长期历史通过线性注意力处理,近期交互通过 softmax 注意力处理,在保持线性复杂度的同时恢复精度。作者进一步提出时序感知差分网络,动态强调新鲜信号并抑制陈旧噪声,提升对意图变化的响应能力。实证表明,HyTRec 在长序列用户上比基线模型命中率高出 8% 以上,且不牺牲推理速度。
数据集

- 作者使用公开数据集,不含敏感信息,仅用于研究,无商业意图。
- 数据按用户 ID 合并分区,重建从注册起的完整行为历史,支持更丰富的长序列建模。
- 用户行为序列使用广告归因 ID 作为数值标识符,追踪漏斗各阶段状态(点击、跳转、激活、唤醒、商品点击、停留、收藏、加购、支付)。
- 行为按与支付的相关性强度排序,构建分层长周期序列,优先选择最具转化预测力的信号。
- 数据集排除或处理问题案例:冷启动用户(稀疏/无交互)、长期不活跃用户(记录老旧/有限)、黄牛账户(交互量高但商业价值低),避免误导模型训练。
- 这些过滤与结构化策略确保训练数据支持高效、准确的长用户序列建模,避免边缘案例导致偏差。
方法
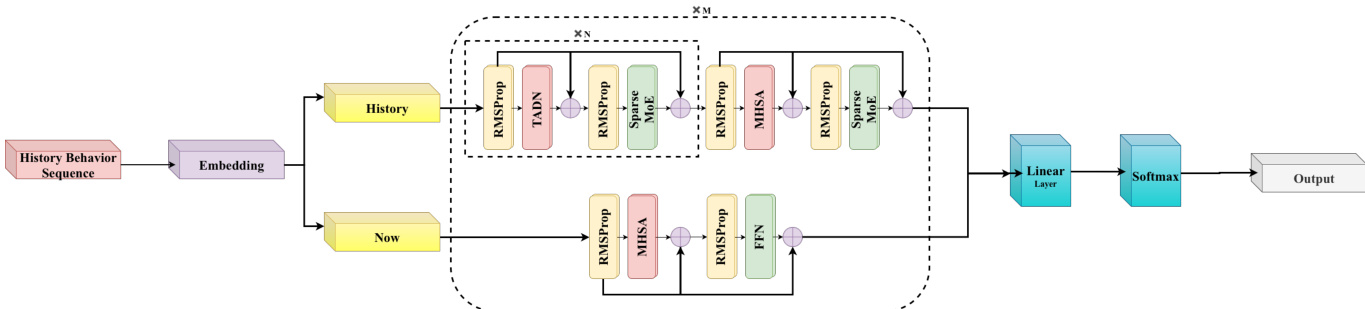
作者采用双分支架构建模长用户行为序列,明确解耦短期意图峰值与长期稳定偏好。这种分层始于序列分解:完整历史序列 Su 被划分为固定长度 K 的短期子序列 Sushort(捕捉近期行为)和长度 n−K 的长期子序列 Sulong(编码稳定消费模式)。每个子序列独立通过专用分支处理后融合。
短期分支采用标准多头自注意力(MHSA),保留细粒度时间动态并确保近期交互的高精度。相比之下,长期分支基于新颖的混合注意力架构构建,旨在打破 O(n2) 复杂度瓶颈,同时保留全局上下文感知能力。该分支包含 N 个编码器层,主要使用所提出的时序感知差分网络(TADN)实现线性复杂度,稀疏交错标准 softmax 注意力层(如 7:1 比例)以保持检索保真度。
请参考框架图,了解此双路径处理与融合机制的可视化表示。
长期分支核心是 TADN,它引入时序感知门控机制,根据历史行为与目标动作的时间邻近性动态加权。时间衰减因子 τt 量化相关性:
τt=exp(−Ttcurrent−tbehaviort),其中 T 为衰减周期。该因子与特征相似性融合生成动态门控权重 gt:
gt=α⋅[σ(Wg⋅Concat(ht,Δht)+b)⊙τt]+(1−α)⋅gstatic,其中 Δht=ht−hˉ 表示短期偏差,gstatic 编码长期偏好。融合表示 h~t 计算如下:
h~t=qt⊙Δht+(1−qt)⊙ht.该门控机制通过状态更新规则集成到线性注意力递归中:
St=St−1(I−gtβtktkt⊤)+βtvtkt⊤,展开为带时序感知衰减掩码 D(t,i) 的线性注意力公式:
ot=i=1∑tβi(viki⊤)qt⋅D(t,i),其中 D(t,i)=∏j=i+1t(I−gjβjkjkj⊤)。gj 中包含 τj 确保近期交互被优先处理,同时保留长期模式。
两个分支的输出融合后通过线性层和 softmax 生成最终推荐预测。这种混合设计使模型能高效处理长序列,同时不牺牲准确意图建模所需的语义丰富性。
实验
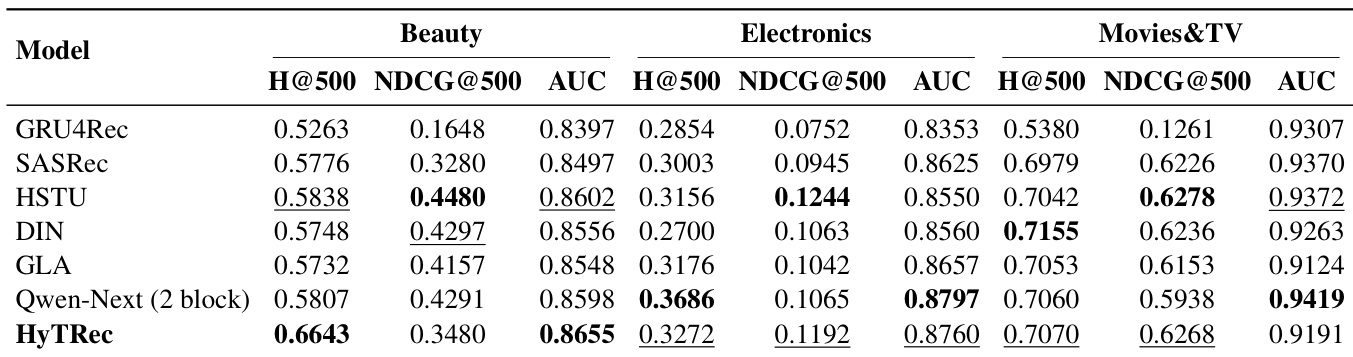
- HyTRec 在建模长用户行为序列方面优于最先进的基线模型,在多个数据集上达到最优或接近最优性能,尤其擅长捕捉用户兴趣并适应稀疏或分散的行为模式。
- 由于其线性注意力机制,模型可高效扩展至超长序列,在序列长度达 12k 时仍保持高吞吐量,而基于 Transformer 的模型在超过 1k 后效率急剧下降。
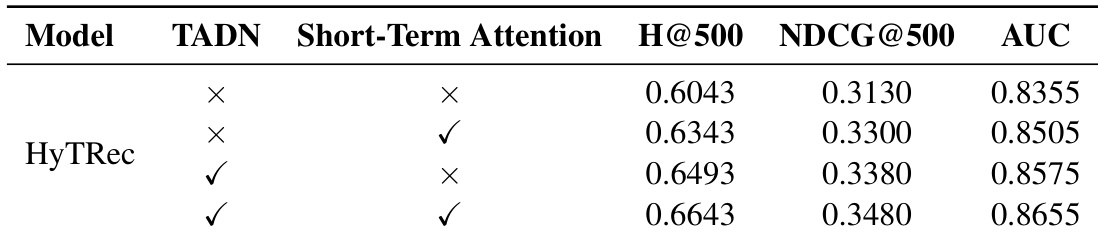
- 消融研究证实,TADN 分支(用于长期依赖)和短期注意力分支(用于即时兴趣漂移)均不可或缺,二者结合通过互补建模实现最佳整体性能。
- 线性与短期注意力 3:1 的混合注意力比例在推荐准确性和推理效率间提供最佳平衡,在性能与延迟权衡上优于其他比例。
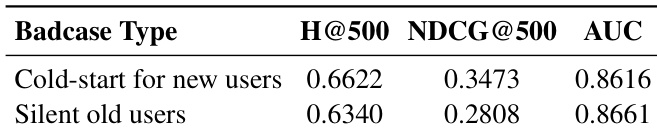
- HyTRec 在冷启动和稀疏交互场景中表现出鲁棒性,通过利用相似用户行为模式展现强泛化能力与对挑战性用户案例的适应性。
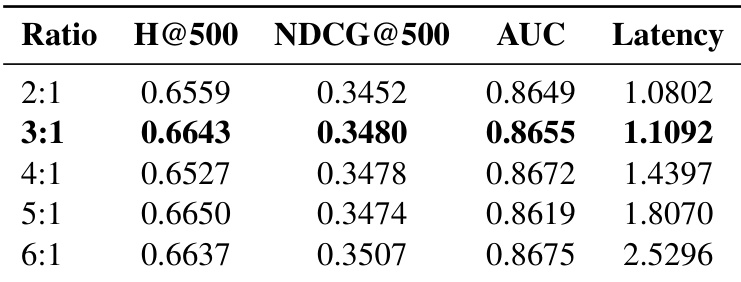
- 额外参数研究表明,2 个注意力头和 4 个专家在性能与效率间提供最优权衡,符合用户群体异质性与计算约束。
- 模型还展示出强大的跨域迁移能力,表明其在处理领域转移方面具有结构优势,激励未来在更广泛泛化与抗噪性上的研究。
作者使用 HyTRec 通过结合线性与短期注意力机制解决长用户行为建模问题,在多个数据集上相比 Transformer 和线性注意力基线实现具有竞争力或更优的性能。结果表明,HyTRec 在超长序列长度下保持高效率,同时提供强大的推荐准确性,尤其在捕捉长期模式与短期兴趣漂移方面。消融与比例研究确认,混合架构的双分支设计与 3:1 注意力比例在性能与计算成本间提供最佳平衡。
作者使用消融实验分离 HyTRec 两个关键组件的贡献:用于长期序列建模的 TADN 分支与用于捕捉即时兴趣漂移的短期注意力分支。结果表明,每个组件独立优于基线,但二者结合在所有指标上得分最高,确认其互补作用。该设计使模型能有效平衡长距离依赖建模与对近期用户行为的响应能力。
作者评估推荐模型中专家数量变化的影响,发现性能在 4 个专家时达到峰值,当数量增至 6 或 8 时,推荐准确性和推理效率均下降。结果表明,更高专家数量引入不必要的计算开销,未在 H@500、NDCG@500 或 AUC 等关键指标上带来有意义提升。这支持专家数量与用户群体异质性对齐的设计选择,以在有效性与效率间取得最优平衡。
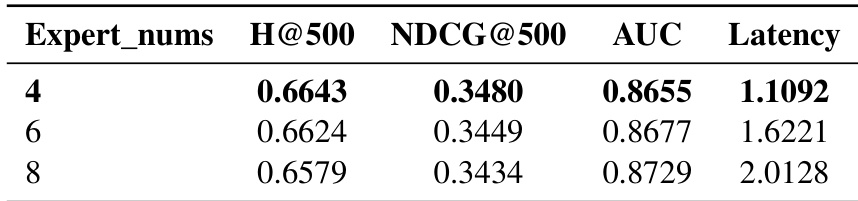
作者评估不同混合注意力比例对推荐准确性和推理延迟的影响,发现 3:1 比例在性能增益与计算成本间提供最佳平衡。虽然更高比例如 6:1 实现边际更好的指标,但会显著增加延迟,实用性较低。结果确认中等混合配置在长序列建模中优化了有效性与效率。
作者在包括冷启动新用户和沉默老用户等挑战性用户场景下评估 HyTRec,表明模型在两种情况下均保持强大的检索与排序性能。结果表明 AUC 分数持续高于 0.86,H@500 值具有竞争力,证明模型通过有效用户相似性增强与泛化能力,在处理稀疏交互数据时具有鲁棒性。