Command Palette
Search for a command to run...
帕尼尼:通过结构化记忆实现令牌空间中的持续学习
帕尼尼:通过结构化记忆实现令牌空间中的持续学习
Shreyas Rajesh Pavan Holur Mehmet Yigit Turali Chenda Duan Vwani Roychowdhury
摘要
语言模型正越来越多地被用于推理其训练数据之外的内容,例如新文档、动态演化的知识以及用户特定的数据。一种常见的方法是检索增强生成(Retrieval-Augmented Generation, RAG),该方法将原始文档以分块形式外部存储,并在推理阶段仅检索与任务相关的子集,供大语言模型(LLM)进行推理。然而,这种方法存在计算效率低下的问题——LLM反复对相同文档进行推理;此外,分块检索可能引入无关上下文,从而增加生成不支持答案的风险。为此,我们提出了一种类人非参数化持续学习框架:基础模型保持固定,学习过程通过将每一次新经验整合进一个外部语义记忆状态实现,该状态能够持续累积并巩固知识。我们提出了Panini系统,其核心是将文档表示为生成式语义工作空间(Generative Semantic Workspaces, GSW)——一种面向实体与事件的问答(QA)对网络结构,能够支持LLM通过基于推理的推理链,重建所经历的情境并挖掘潜在知识。在处理查询时,Panini仅遍历持续更新的GSW(而非原始文档或分块),并检索最可能的推理链。在六个问答基准测试中,Panini取得了最高平均性能,相较其他先进基线模型提升5%至7%;同时,其使用的答案-上下文token数量减少2至30倍,支持完全开源的推理流程,并显著降低在精心构造的不可回答查询上的不支持性回答比例。结果表明,通过GSW框架在写入阶段对经验进行高效且准确的结构化组织,能够在读取阶段同时实现更高的效率与可靠性。代码已开源,详见:https://github.com/roychowdhuryresearch/gsw-memory。
一句话总结
来自加州大学洛杉矶分校的 Shreyas Rajesh、Pavan Holur 及其同事提出了 PANINI,这是一种在 token 空间中运行的持续学习方法,利用结构化记忆缓解遗忘问题,无需重新训练即可实现高效适应,特别适合词汇动态演化的 NLP 任务。
主要贡献
- PANINI 引入了一种非参数化持续学习框架,通过将新知识存储在结构化的“生成语义工作区”(GSW)中避免重新训练大语言模型。GSW 将文档编码为实体和事件感知的问答网络,以支持对累积经验的推理。
- 它采用“推理推导链检索”(RICR)在查询时遍历 GSW,实现高效、精准地访问推导链,无需重新处理原始文本,从而减少计算开销并最小化无关上下文注入。
- 在六个问答基准测试中评估,PANINI 平均准确率比基线高出 5%–7%,同时每个答案使用的 token 数量减少 2–30 倍,并显著减少对不可回答问题的无依据生成,展现出效率与可靠性的双重提升。
引言
作者利用非参数化持续学习,解决检索增强生成(RAG)系统效率低下和不可靠的问题——这类系统存储原始文档片段,并迫使大语言模型在推理时反复处理相同文本。先前的结构化记忆方法如 RAPTOR 和 GraphRAG 侧重于摘要而非推理,而参数化方法则面临灾难性遗忘和高昂重训练成本。PANINI 引入“生成语义工作区”(GSW)——一种实体与事件感知的问答对网络——以及一种轻量级检索方法“推理推导链检索”(RICR),通过遍历该结构化记忆回答查询,无需反复调用大语言模型。该设计在六个问答基准测试中实现最先进性能,使用 2–30 倍更少的 token,并提升对不可回答问题的可靠性,证明在写入时投入计算构建结构化记忆,可在读取时获得效率与准确性的回报。
数据集
作者使用单跳与多跳问答基准测试混合评估 PANINI 的非参数化持续学习能力,重点关注跨文档的事实记忆与关联性。
-
多跳数据集:MuSiQue、2WikiMultihopQA、HotpotQA 和 LV-Eval(hotpotwikiqa-mixup 256k)测试多步推理。MuSiQue 强调组合推理;2WikiMultihopQA 覆盖维基百科上的多样推理模式;HotpotQA 要求从多个来源识别支持事实。LV-Eval 是用于可扩展性测试的大规模变体。
-
单跳数据集:NQ 和 PopQA 评估基本事实检索,确保模型在直接查询上保持性能。
-
Platinum 变体(MUSIQUE-PLATINUM, 2WIKI-PLATINUM):构建用于评估缺失证据下的可靠性。使用多智能体 LLM 系统从源文档生成答案,随后人工审核标注示例为可回答或不可回答。最终划分:MuSiQue(766 可回答 / 153 不可回答),2Wiki(906 / 94)。模型在证据不足时应输出 “N/A”;性能通过可回答示例的 F1 值和不可回答示例的二元拒绝准确率衡量。
-
训练与评估设置:作者采用与 HippoRAG2 相同的数据集划分以确保基线公平比较。所有实验使用 GPT-4.1-mini 生成“生成语义工作区”(GSW)记忆——结构化语义网络,捕捉实体、角色、状态和双向问答对——随后由 Qwen3-8B(思考模式)作为阅读器消费,Qwen3-8B + LoRA 负责问题分解。
-
处理细节:GSW 提取遵循结构化提示,引导模型从原始文本中识别实体、角色、状态、别名和事实关系。缩写保留,除非在源文档中明确展开。未提及裁剪;所有处理均为文档级别,构建结构化语义图。
方法
作者利用一种称为“生成语义工作区”(GSW)的结构化、非参数化记忆框架,实现高效、基于推理的问答。系统 PANINI 包含三个核心阶段:结构化记忆构建、推理推导链检索(RICR)和答案生成。每个阶段旨在最小化推理时的参数依赖,转而基于显式检索的原子问答证据生成响应。
框架从逐文档 GSW 构建开始。每篇文档 di 由大语言模型处理,生成语义图 Gi=(Ei,Vi,Qi),其中 Ei 表示带角色和状态注释的实体节点,Vi 表示动词短语或事件节点,Qi 由从动词短语指向实体的问答对组成。例如,“Barack Obama 于 1961 年 8 月 4 日出生”生成 Obama 实体节点、“was born”动词短语节点,以及问答对如“Barack Obama 何时出生?”→“1961 年 8 月 4 日”。该结构明确编码事件-属性关系为可检索的原子单元。请参考框架图,了解文档如何转换为独立 GSW 并整合为持续学习的全局工作区。
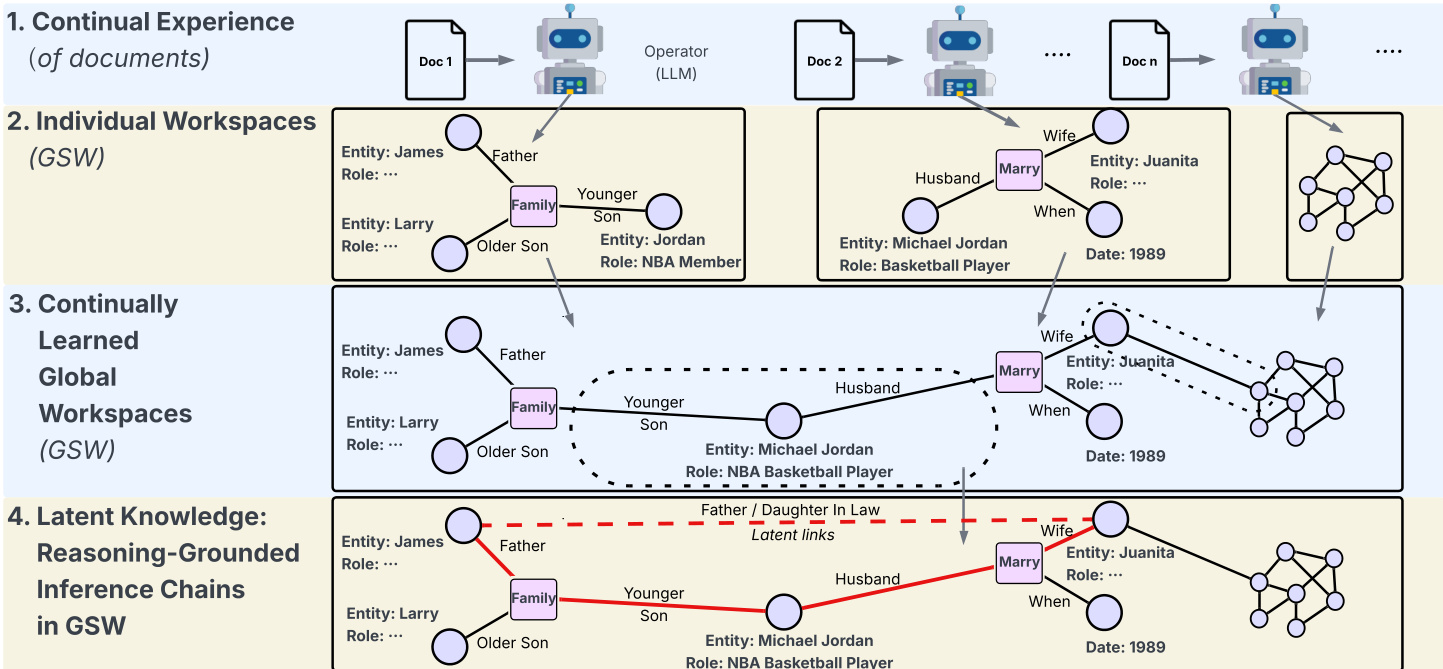
为实现高效检索,作者在语料库上实现双索引策略。在实体节点上构建稀疏 BM25 索引,包含表面形式及其关联角色或状态。在所有 GSW 提取的问答对上构建密集向量索引。检索时,查询同时对两个索引评分:实体索引提供本地语义图的入口点,问答索引实现候选事实的语义匹配。该双重方法确保证据仅由紧凑、精准的问答对组成,而非长段落或图邻域。
推理时,PANINI 通过三步管道处理用户查询。首先,分解 LLM 将查询重写为原子化、单跳子问题序列。例如,“Lothair II 的母亲何时去世?”变为“Lothair II 的母亲是谁?”后接“<Entity_Q1> 何时去世?”。分解仅执行一次,之后非参数化。如系统概览所示,规划步骤后接 RICR——一种遍历 GSW 组装证据链的束搜索过程。
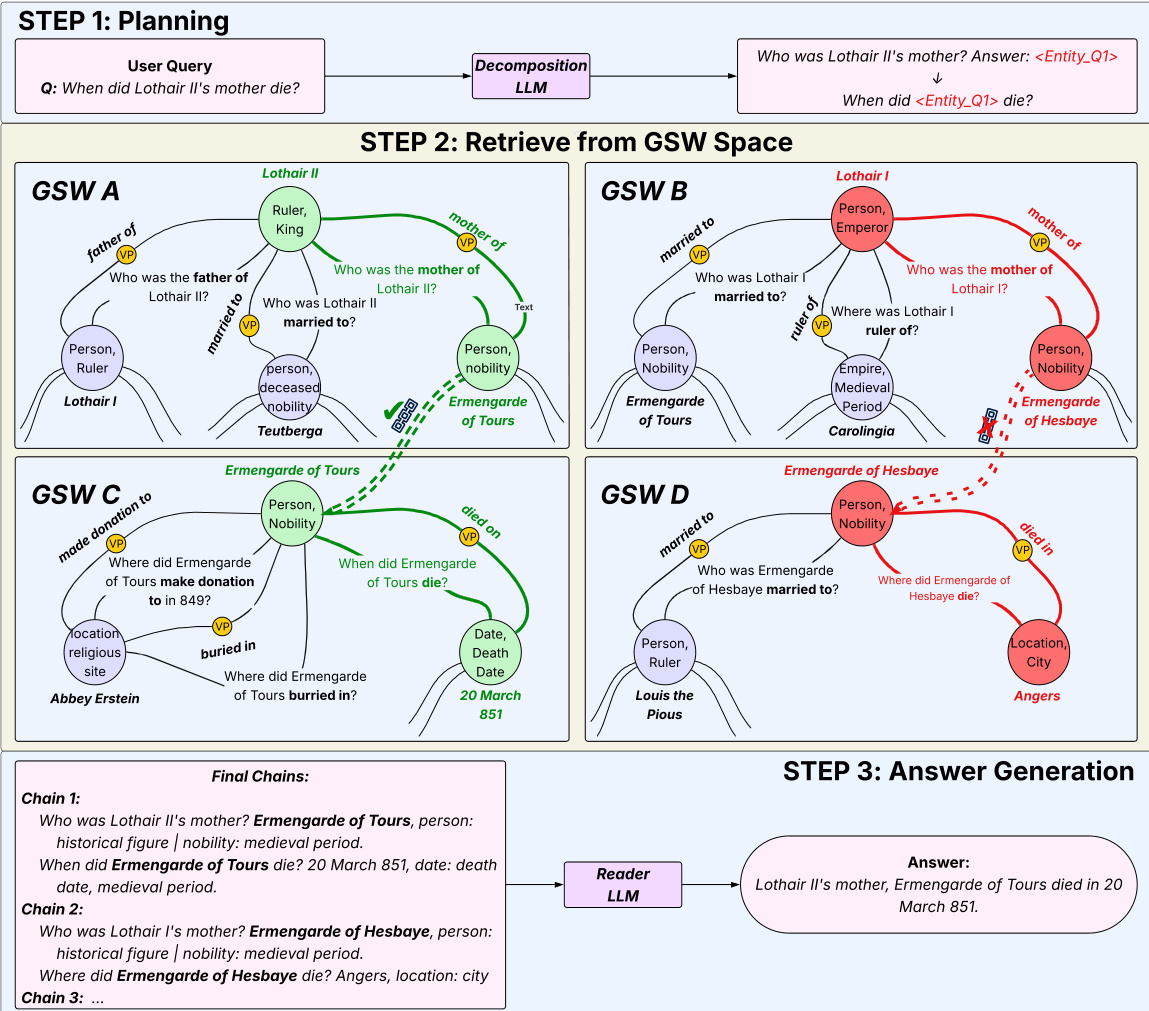
RICR 对每个子问题序列逐跳运行。在每跳 t,给定子问题 qt(xt),系统使用双索引检索候选问答对:BM25 索引实体,密集检索索引问答对。候选对由交叉编码器重排序,保留前 k 对。链 C 是有序问答对序列 (q1G,a1G)⇒(q2G,a2G)⇒⋯⇒(qTG,aTG),其中前一跳答案 atG 实例化下一子问题。为缓解错误传播,RICR 维护 B 条并行链,每条链按其组成相关性得分的几何平均评分:score(Ct(j))=(∏l=1tsl,j)1/t。每跳保留前 B 条具有唯一答案的链,确保实体路径的多样化探索。T 跳后,顶级链去重,其问答对传递给答案模型。
最终阶段使用基于检索证据的 LLM 生成有依据的响应。答案模型从选定问答对合成最终输出,确保响应直接由检索事实支持。对于多序列查询,RICR 独立执行每个序列,结果证据在答案生成前合并。
为提升 GSW 质量(尤其使用较小模型时),作者引入两轮精炼策略。初始 GSW 生成后,第二轮 LLM 检查并修复结构缺陷——添加缺失实体、修正格式错误的问答对或确保双向问答覆盖。精炼提示明确指示模型保留正确元素、添加缺失实体并强制执行问答反转规则。该轻量级精炼显著提升下游性能,无需更大模型构建。
整个管道设计为模块化且可适应。GSW 构建、问题分解和答案生成可用不同 LLM 实现,检索与评分组件为非参数化,支持跨模型规模与配置的稳健性能。系统优势在于其在读取时动态构建推理链,而非预计算密集跨文档图,从而避免虚假连接并在每步推理中利用 LLM 引导评分。
实验
- PANINI 在多跳问答任务上优于基于块、结构增强和智能体检索基线,实现最高平均性能,同时显著减少推理 token 使用量。
- 它打破了在缺失证据下回答准确率与拒绝可靠性之间的典型权衡,在可回答问题上保持高准确率,同时有效拒绝不可回答问题。
- PANINI 的优势在完全开源模型上依然存在,对嘈杂或不完美的 GSW 构建具有鲁棒性,即使所有组件在单 GPU 上本地运行仍保持优势。
- 消融实验证实,问题分解、双索引检索、问答重排序和累积链评分对其性能至关重要,尤其对多跳推理。
- PANINI 的结构化 GSW 记忆不仅提升自身检索,还提升如 Search-R1 等智能体系统,当替换其默认块检索时表现更优。
- 它表现出对语料库增长的卓越韧性,在干扰文档增加时保持稳定性能,而嵌入或 BM25 方法则不然。
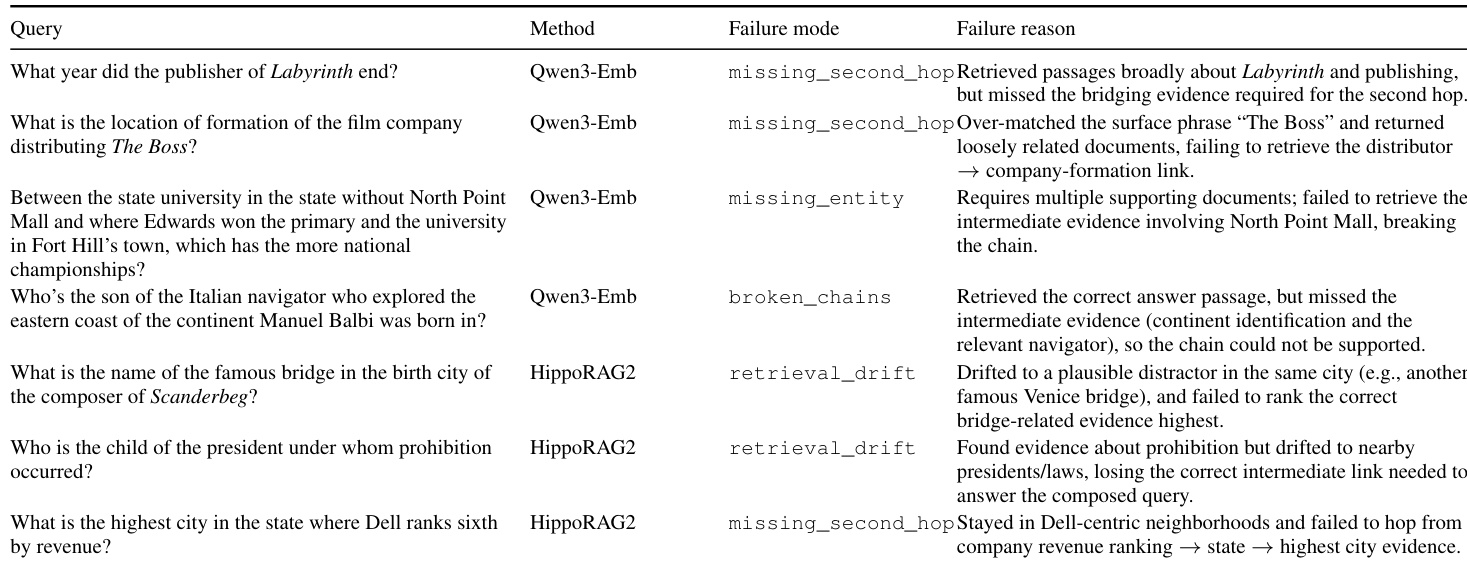
- 定性分析显示,PANINI 通过强制执行显式、上下文感知、跳条件证据检索,避免常见基线失败(如检索漂移或断裂链)。
- 主要失败模式源于不完美的 GSW 构建(缺失动词短语或 QA 链接)或错误分解,但性能退化平缓,得益于束搜索韧性。
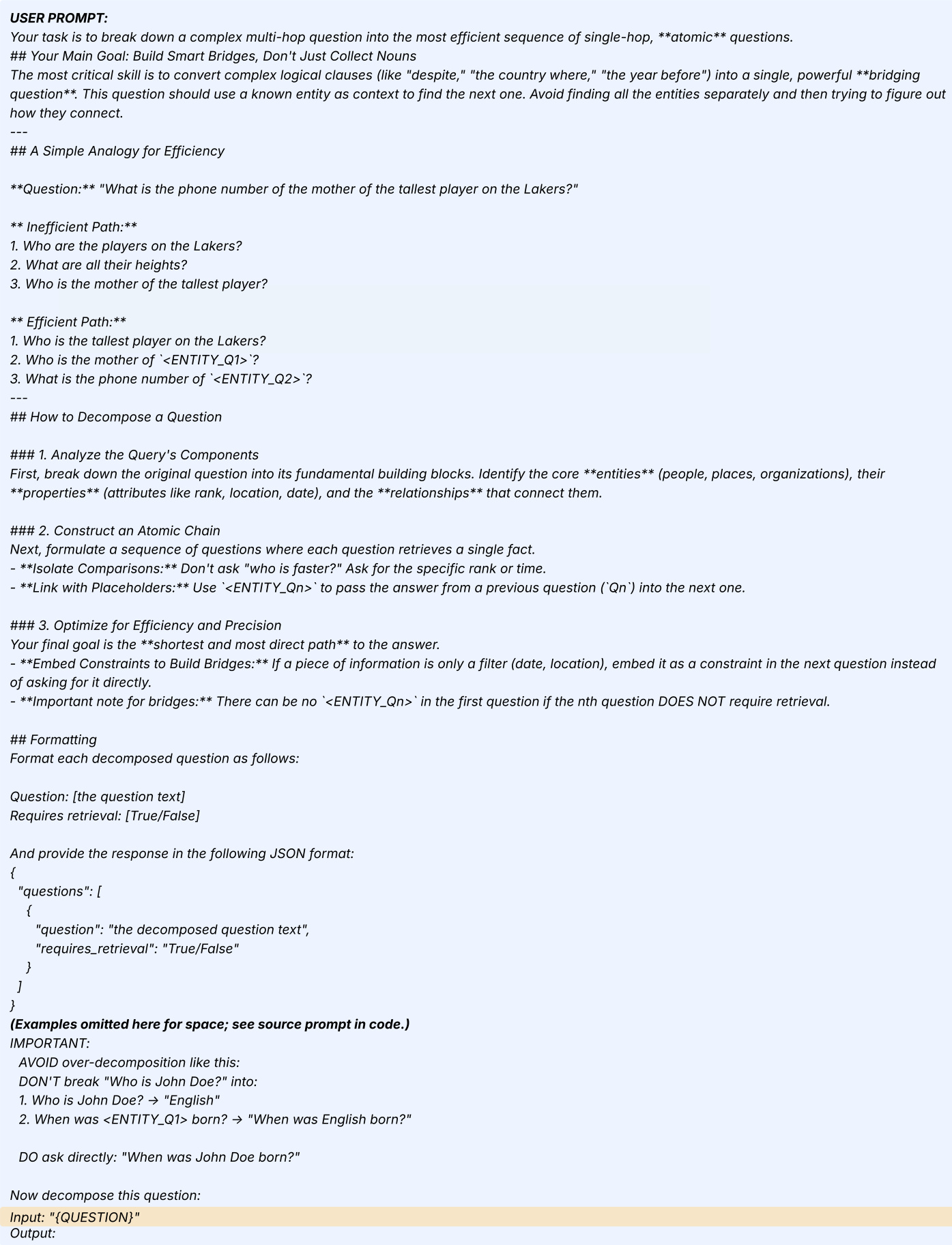
PANINI 在多个多跳问答基准测试中优于稀疏和密集检索基线及结构增强方法(如 HippoRAG2),实现最高平均得分。优势在 MuSiQue 和 2Wiki 等复杂任务中尤为明显,PANINI 的结构化、链跟随检索设计比传统块或图方法更准确组装证据。结果还显示 PANINI 在保持效率优势的同时提供更强性能,表明其框架有效平衡精度与计算成本。
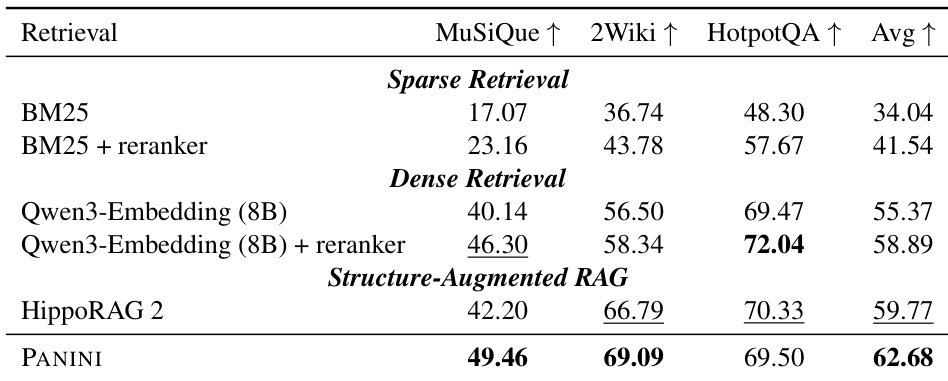
作者使用消融研究隔离 PANINI 关键组件的影响,显示禁用 QA 重排序或问题分解会显著降低性能,而双搜索和束宽调整影响更细微。结果表明,保持 QA 重排序和分解对多跳准确率至关重要,而将束宽降至 3 可在削减 token 使用量的同时保留性能。框架在不同束宽下保持稳健,仅在宽度 1 时轻微退化,表明计算权衡的灵活性。
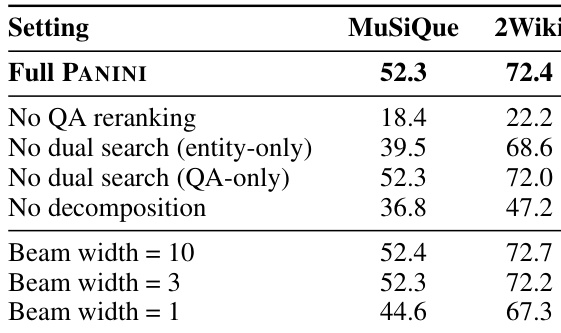
PANINI 显著减少推理时 token 使用量,相比基于块、结构增强和智能体检索方法,在所有评估基准测试中实现最低平均 token 数。该效率源于其设计——使答案模型基于简洁、精准的 QA 对而非完整文档块或迭代检索轨迹。结果确认 PANINI 的轻量检索方法在大幅降低推理计算开销的同时保持强大性能。
作者使用此表定义六个 QA 基准测试的评估规模,指定每数据集的查询数和段落数。这些基准测试的结果显示,PANINI 在多跳推理中持续优于基线,同时使用显著更少的推理 token。该框架在缺失证据下也保持强大可靠性,打破回答正确与适当拒绝之间的典型权衡。

作者使用定性失败分析显示,密集检索系统常遗漏桥梁证据或断裂推理链,而图方法如 HippoRAG2 则因检索漂移至语义相关但错误实体而失败。PANINI 通过结构化 QA 对和双索引强制执行显式、跳条件检索,避免这些问题,保持链完整性并减少对图邻近性的依赖。结果表明,PANINI 的设计通过将检索与演化的推理上下文对齐(而非表面相似性或邻域结构)提升多跳准确率。