Command Palette
Search for a command to run...
Composition-RL:为大语言模型强化学习构建可验证的提示词组合
Composition-RL:为大语言模型强化学习构建可验证的提示词组合
Xin Xu Clive Bai Kai Yang Tianhao Chen Yangkun Chen Weijie Liu Hao Chen Yang Wang Saiyong Yang Can Yang
摘要
大规模可验证提示是强化学习结合可验证奖励(Reinforcement Learning with Verifiable Rewards, RLVR)成功的关键基础,但这类提示往往包含大量信息量低的示例,且进一步扩展成本高昂。近期研究致力于更高效地利用有限的训练数据,通过优先选择回放通过率(pass rate)为0的“难提示”来提升效率。然而,随着训练进程的推进,通过率高达1的“易提示”也日益增多,导致有效数据规模被稀释。为缓解这一问题,我们提出Composition-RL——一种简单而有效的策略,旨在更充分地利用有限的可验证提示,尤其聚焦于通过率等于1的提示。具体而言,Composition-RL能够自动将多个问题组合成一个新的可验证问题,并利用这些组合式提示进行强化学习训练。在模型规模从4B到30B的广泛实验中,Composition-RL在所有规模下均显著优于仅基于原始数据集训练的强化学习方法,持续提升模型的推理能力。此外,引入一种课程学习(curriculum)变体的Composition-RL,通过在训练过程中逐步增加组合深度,可进一步提升性能。更重要的是,Composition-RL还能有效支持跨领域强化学习,通过融合来自不同领域的提示实现知识迁移。相关代码、数据集及模型已开源,地址为:https://github.com/XinXU-USTC/Composition-RL。
一句话总结
中国科学技术大学及合作者提出 Composition-RL 方法,通过将通过率已达 1 的提示自动组合为新的可验证问题,提升强化学习训练效率,在 4B–30B 参数规模模型上均优于先前方法,并通过基于课程的组合深度扩展实现跨领域适应。
主要贡献
- Composition-RL 解决了 RLVR 中可验证提示有效性递减的问题:自动将多个简单提示(通过率为 1)组合为更难、新颖的问题,从而在无需新数据采集的前提下扩展有效训练信号。
- 在 4B 至 30B 参数规模模型上评估,Composition-RL 始终优于标准 RLVR,配合课程变体(训练中逐步增加组合深度)可进一步提升推理性能。
- 该方法通过组合不同领域提示(如数学与物理)实现更有效的跨领域强化学习,优于简单混合策略,展现更广的泛化潜力。
引言
作者利用“带可验证奖励的强化学习”(RLVR)增强大语言模型的推理能力,但面临一个关键瓶颈:随着训练推进,许多提示变得过于简单(通过率 1),无法提供有效梯度信号。先前工作聚焦于困难提示(通过率 0),通过优势塑造或采样解决,却忽视了日益增长的“平凡提示”池。为此,他们引入 Composition-RL,自动将多个简单提示组合为更难、可验证的复合问题,有效刷新训练信号。该方法在 4B 至 30B 模型上持续提升性能,尤其配合逐步增加组合深度的课程策略时效果更佳,并通过混合数学与物理等不同学科提示实现更强的跨领域学习。
数据集

- 作者使用三种数据集配置对候选集 𝒟₁ 和 𝒟₂ 进行消融研究,均源自包含 12,000 条提示的基底池 𝒟。
- 默认 Composition-RL:𝒟₂ = 𝒟(12,000 条提示),𝒟₁ = 随机子集(20 条提示)。过滤后最终数据集大小:199K。
- 变体 A:𝒟₁ 和 𝒟₂ 均为随机子集(各 500 条提示)。经三步过滤,规模由 240K → 202K → 200K。
- 变体 B:𝒟₁ = 完整 𝒟(12,000 条提示),𝒟₂ = 随机子集(20 条提示)。过滤后规模由 231K → 201K → 200K。
- 所有变体设计目标为生成大致等量的最终数据集(~200K),以确保公平比较。
- 过滤遵循第 D.1 节流程,分三步顺序剪枝组合数据集。
方法
作者采用结构化流程,通过带组合提示的强化学习训练大语言模型,称为 Composition-RL。核心创新在于“顺序提示组合”(SPC)模块,该模块从简单提示算法生成复杂多步提示,从而诱导出组合深度递增的课程。此框架旨在增强模型解决需链式推理步骤问题的能力。
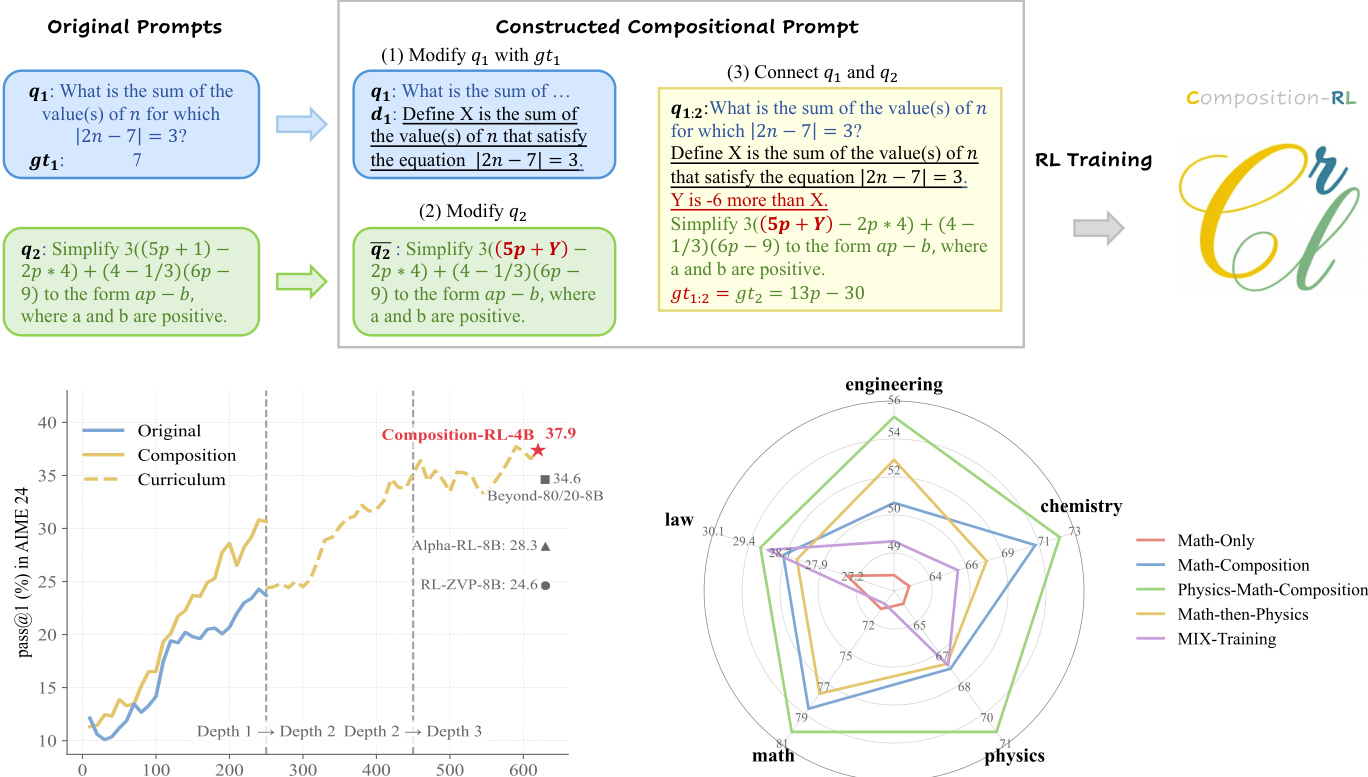
SPC 过程首先选取两个基础提示 q1 和 q2,其各自有已知真实答案 gt1 和 gt2。组合操作符首先修改 q1:从 gt1 中提取数值 v1,嵌入自然语言定义 d1,形成 qˉ1=q1⊕d1。例如,若 q1 询问满足 ∣2n−7∣=3 的值之和,且 gt1=7,系统将定义 X 为该和。接着,修改 q2:将数值常量替换为变量 v2,得到 qˉ2。最后,通过关系语句 r(如“Y 比 X 小 6”)连接两个修改后的提示,形成组合提示 q1:2=qˉ1⊕r⊕qˉ2。组合提示的真实答案继承自 q2。此过程可递归扩展至组合 K 个提示,求解 q1:K 需按序求解所有组成提示。
参见框架图,其展示 SPC 三阶段流程:修改 q1 并嵌入其真实答案、修改 q2 通过变量替换、用关系约束连接二者形成最终组合提示。图中亦展示这些提示如何输入 Composition-RL 范式下的 RL 训练。
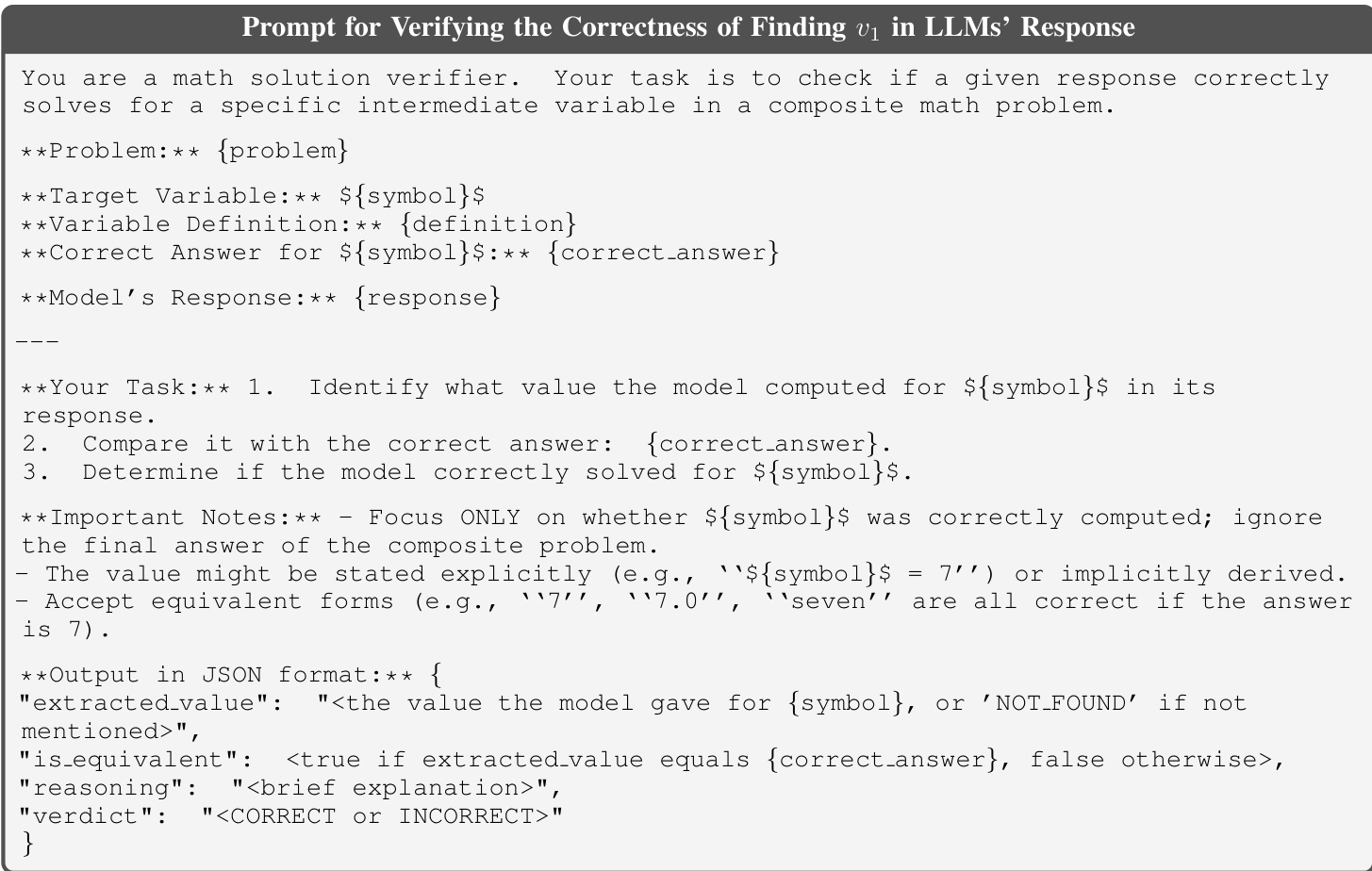
为确保自动生成组合提示的可靠性,作者采用多阶段验证协议,使用相同 LLM 作为自检代理。SPC 每一步中,模型被提示验证自身修改。第一步(修改 q1 与 gt1):LLM 被要求根据修改后提示计算新定义变量 v1 的值,并与原提取值比对。若不匹配,则丢弃该组合。类似验证应用于 q2 修改,确保替换变量 v2 与原问题一致。最终连接步骤验证语法和语义一致性,如变量名冲突。
如下图所示,第一步验证提示指令 LLM 提取新变量值、从修改后问题计算该值,并返回结构化 JSON 判定结果,表明计算值是否匹配预期值。此自验证机制将组合提示错误率降至 2% 以下,确保高质量训练数据。
为确保数值和符号一致性,作者进一步采用基于 Python 的验证步骤。LLM 被提示生成使用 sympy 库的 Python 脚本,符号化比较提取值 v1 与真实答案,处理无理常数和等价表达式。脚本必须输出带框的最终比较结果,确保机器可验证正确性。此双层验证(自然语言 + 代码)增强了组合数据生成流程的鲁棒性。

训练期间,Composition-RL 在生成的组合数据集 DCK 上优化 RLVR 目标,使用“组相对策略优化”(GRPO)算法。策略梯度通过从旧策略采样的 G 个响应组估计,优势按组均值和标准差归一化。为避免无信息提示(全对或全错)导致梯度消失,采用动态采样:从较大候选批次 B^ 中过滤,仅保留成功率居中的提示,确保非零优势信号。因此,训练目标在精选提示集上计算,这些提示提供有意义的学习信号,实现稳定有效的策略更新。
实验
- 元实验表明,不仅“全错”提示,连“全对”提示也严重限制 RL 训练效果;SPC 通过将简单提示变难、降低“全对”率缓解此问题。
- Composition-RL 在领域内数学和跨领域基准上持续优于标准 RL,增益随模型规模显著增长,尤其对大模型更明显。
- 基于课程的 Composition-RL(从深度 1 到深度 3 提示逐步推进)带来持续性能提升,即使使用更小模型和更少训练提示,仍超越基线。
- 跨领域 Composition-RL(如物理 + 数学)优于混合或顺序训练,在法律、工程、化学等领域展现更广泛泛化能力。
- 消融研究证实,第二提示(q2)使用多样化候选集对性能至关重要,因其使模型接触更广范围的可验证答案。
- Composition-RL 通过促进组合泛化(习得可复用推理技能)起效,并通过鼓励正确中间推理步骤提供隐式过程监督。
作者使用组合提示增强 RL 训练,发现该方法在领域内数学和跨领域多任务基准上持续提升性能。结果显示,大模型受益更显著,最大模型在数学任务上增益高达 14% 以上。逐步增加组合深度的课程训练进一步提升性能,表明结构化提示组合可有效缓解因提示过于简单导致的饱和问题。

作者使用组合提示构建增强 RL 训练,发现从少量随机子集采样第一提示、从完整数据集采样第二提示,在数学和多任务基准上表现最佳。结果表明,该配置显著提升整体准确率,尤其在 AIME24 和 MMLU-Pro 等具挑战性数学任务上,表明第二提示组件的答案多样性对有效训练至关重要。

结果表明,相比单领域或混合数据集,跨领域组合提示训练显著提升领域内数学任务和跨领域多任务基准表现。Physics-MATH-Composition-141K 数据集增益最高,尤其在 AIME24、AIME25 和 MMLU-Pro 上,表明需多领域推理的组合提示增强跨学科泛化能力。这表明,结构化组合现有提示可有效扩展训练信号多样性,无需新数据采集。
