Command Palette
Search for a command to run...
SemanticMoments:通过三阶矩特征实现无需训练的动作相似性计算
SemanticMoments:通过三阶矩特征实现无需训练的动作相似性计算
Saar Huberman Kfir Goldberg Or Patashnik Sagie Benaim Ron Mokady
摘要
基于语义运动的视频检索是一个基础性 yet 尚未解决的问题。现有的视频表征方法过度依赖静态外观和场景上下文,而非运动动态,这种偏差源于其训练数据和目标函数的固有倾向。相反,传统的以运动为中心的输入方式(如光流)又缺乏语义基础,难以理解高层级的运动语义。为揭示这一内在偏差,我们提出了SimMotion基准测试,该基准结合了受控的合成数据与全新的人工标注真实世界数据集。实验表明,现有模型在该基准上表现不佳,往往无法有效分离运动与外观信息。为弥补这一差距,我们提出SemanticMoments——一种简单且无需训练的方法,通过在预训练语义模型提取的特征上计算时间统计量(特别是高阶矩),实现对运动的建模。在我们的多个基准测试中,SemanticMoments始终优于现有的RGB、光流及文本监督方法。结果表明,语义特征空间中的时间统计量为以运动为中心的视频理解提供了可扩展且具感知基础的建模范式。
一句话总结
来自 BRIA AI、特拉维夫大学和希伯来大学的研究人员提出了 SemanticMoments,这是一种无需训练的方法,通过语义特征上的高阶时间统计量分离运动与外观,从而在先前模型失败的场景中实现精确的以运动为中心的视频检索。
主要贡献
- 我们识别出当前视频表示方法中一个关键偏见:优先考虑静态外观而非运动动态,揭示其在检索任务中无法分离运动与视觉上下文的问题。
- 我们引入 SimMotion 基准测试集——结合合成数据与人工标注的真实世界数据集——以严格评估以运动为中心的视频相似性,并揭示当前方法的局限性。
- 我们提出 SemanticMoments,一种无需训练的方法,通过语义特征计算高阶时间统计量,在无需光流或标注运动数据的前提下,实现运动检索的最先进性能。
引言
作者致力于解决基于语义运动而非静态外观或场景上下文的视频检索问题——这一能力对于运动感知视频编辑、生成建模和数据集整理等应用至关重要。先前方法,无论是监督式、自监督式或基于光流的方法,都继承了优先考虑视觉一致性而非时间动态性的偏见,即使运动完全相同,也常无法分离运动与外观。为此,他们提出 SemanticMoments,一种无需训练的方法,通过预训练语义模型(如 DINO)的块级嵌入计算高阶时间矩(方差、偏度),生成紧凑且对运动敏感的描述符,在合成和真实世界基准测试中优于现有方法,无需光流、标注数据或额外训练。
数据集
-
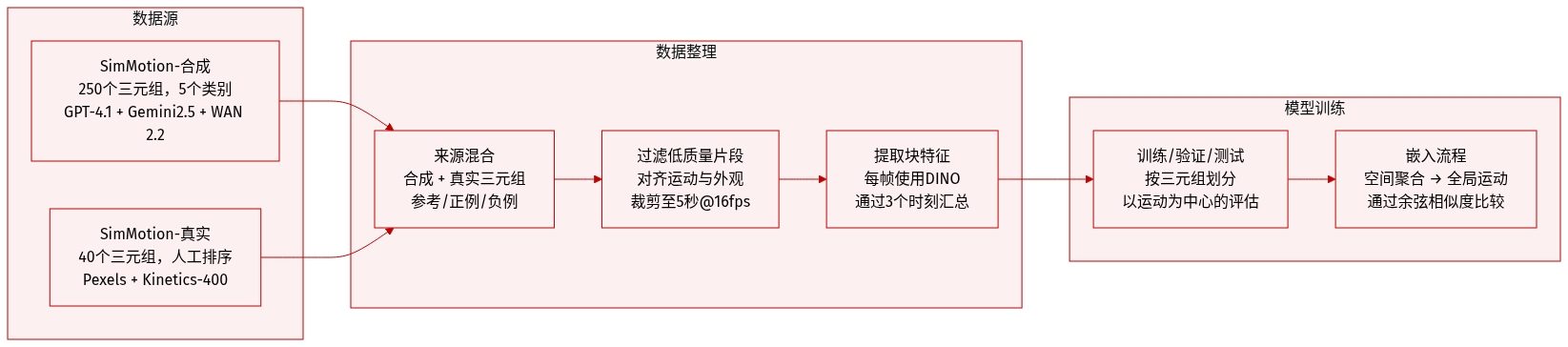
作者使用两个基准测试集——SimMotion-Synthetic 和 SimMotion-Real——评估超越类别标签的运动相似性,聚焦于通过相对比较体现的结构与动态特性。
-
SimMotion-Synthetic 包含 250 个三元组(共 750 个视频),每个三元组包含一个参考视频、一个保持运动的正样本,以及一个外观相同但运动不同的困难负样本。视频长度为 5 秒,采样率为 16 fps,分辨率为 512x512。三元组分为五类:静态物体、动态物体、动态外观、场景风格和视角——每类隔离特定视觉变化,同时保持运动一致。
-
视频由 GPT-4.1 生成提示,再通过 Gemini2.5-Flash 生成图像,WAN 2.2 生成时间同步视频。困难负样本从同一基础图像出发,使用不同运动提示生成,确保运动精确对齐,同时变化外观、主体或视角。
-
SimMotion-Real 包含 40 个从真实视频中整理的参考-正-负三元组。正样本通过文本查询从 Pexels 获取,并由人工标注者按运动相似性排序(忽略外观)。负样本来自同一源视频但运动不同,另加 Kinetics-400 中的随机片段以增加检索难度。
-
两个基准测试集均用于检验模型是否捕捉运动结构而非视觉线索。作者从每帧提取块级特征(如使用 DINO),通过前三阶矩(均值、方差、偏度)随时间汇总,再空间聚合形成全局运动中心嵌入用于评估。
方法
作者采用一种参数化矩表示方法 M+,通过保留结构化统计描述符而非将时间信息压缩为单一池化向量,编码视频数据中的时间动态。该框架始于块级嵌入阶段,视频每帧通过预训练主干网络(如 DINOv2、Video-MAE 或 VideoPrism)提取空间块特征。随后,针对每个空间块独立计算时间矩。
参考框架图:流程始于输入视频帧序列,经块级嵌入器输出时空块特征张量。对每个块 p,第一阶时间矩 μp(1) 为时间平均特征向量,捕捉平均外观。更高阶矩 μp(k)(k>1)计算为中心矩,编码时间变化的幅度(k=2)和方向不对称性(k=3)。这些块级矩随后通过平均空间聚合,生成每阶 k 的全局矩描述符 M(k)∈Rd。
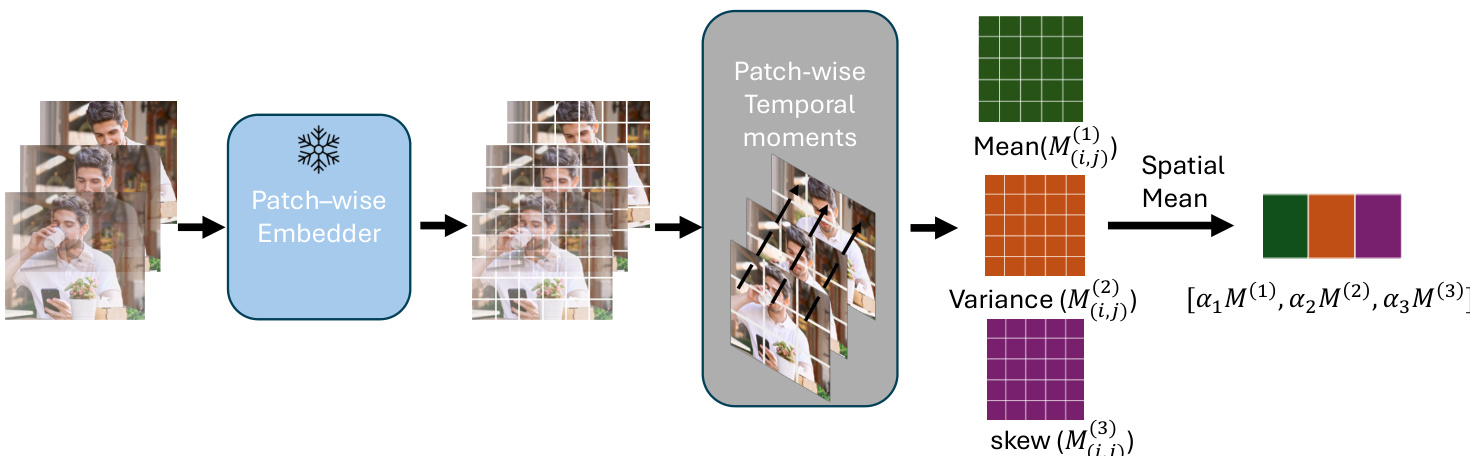
最终视频级表示 ϕvideo 通过拼接前三阶矩描述符(均值、方差、偏度)构建,每阶乘以可学习或固定权重 αk。实践中,作者固定 α1=1,α2=8,α3=4 以强调运动相关统计量。所得嵌入 ϕvideo∈R3d 无需额外训练,仅依赖预训练主干网络和矩聚合,可在大型视频数据集上高效可扩展部署。
实验
- 现有自监督和外观导向的视频嵌入方法无法一致捕捉细粒度运动相似性,常将运动与风格或背景混淆。
- 受控合成基准测试表明,先前方法对保持运动的变体聚类效果差,而所提 SemanticMoments 方法通过语义特征的时间统计汇总成功分离运动。
- 在真实世界运动检索任务中,SemanticMoments 在应对外观变化、相机运动和不同步时间方面优于基线方法(包括基于光流、CLIP 和动作训练的模型)。
- 应用于手势分类时,SemanticMoments 在无需额外训练的情况下增强嵌入空间的可分性,提升多个主干网络的 kNN 准确率。
- 消融研究证实,高阶矩、块级粒度和加性融合可实现最优运动对齐,性能在均匀采样 32 帧时达到峰值。
- 局限性包括对细微或缺失定义运动的处理困难、依赖上游主干网络质量,以及无法在无针对性训练下适应罕见运动类型。
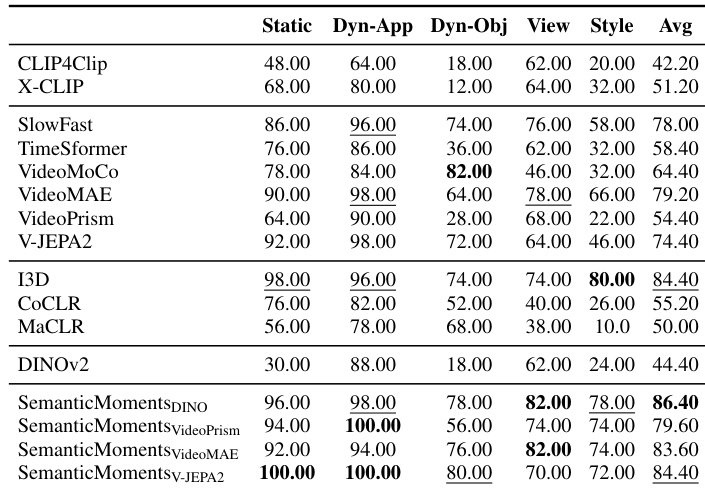
作者在合成基准测试中评估对运动敏感的视频表示,这些测试隔离外观变化同时保持运动。结果表明,现有方法(包括基于 CLIP、RGB 监督和光流模型)在风格、物体或视角变化下难以一致捕捉运动相似性,而所提 SemanticMoments 方法通过语义特征的高阶时间统计汇总实现更优或具竞争力的性能。这表明,无需显式运动监督或训练,即可通过语义帧表示的时间矩有效推导运动感知嵌入。
作者评估时间采样密度对运动检索性能的影响,发现准确率随帧数增加至 32 帧时提升,之后性能趋于平稳或下降。这表明中等时间分辨率足以捕捉运动动态,避免冗余或噪声。

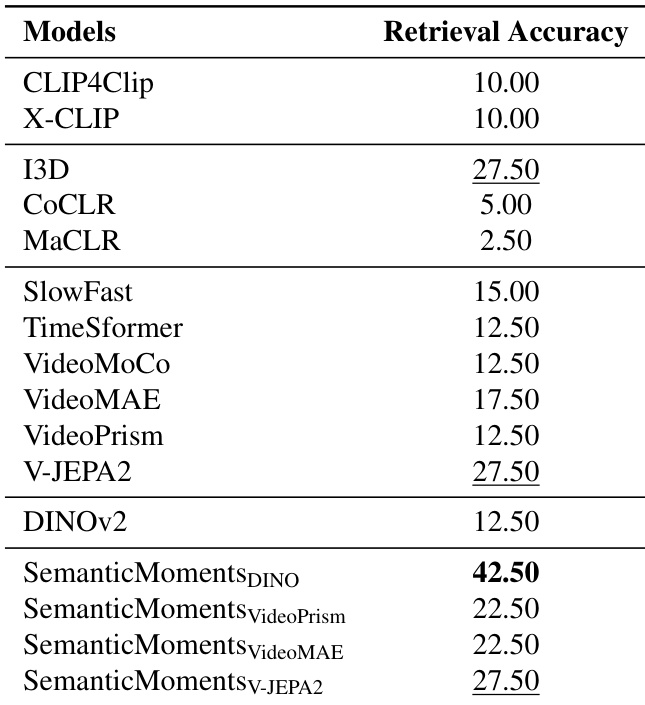
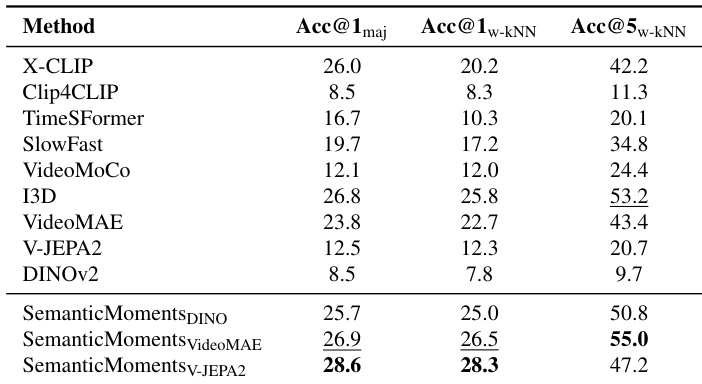
作者在 SimMotion-Real 上评估不同矩表示配置,发现块级结合多阶时间矩(均值、方差、偏度)并拼接可获得最高检索准确率。结果表明,高阶矩与局部块特征显著优于单矩或帧级方法。表现最佳的变体 DINO(1,8,4)-patch-concat 达到 42.50% 准确率,证明更丰富的时间统计与空间粒度在捕捉运动相似性中的价值。
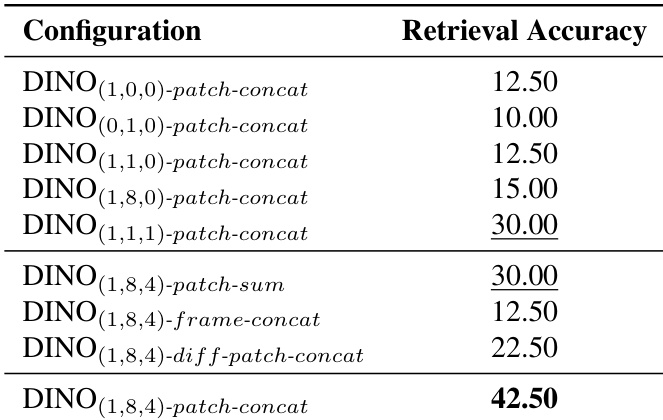
作者使用 SemanticMoments 通过将时间统计应用于预训练编码器的语义特征,增强对运动敏感的视频表示。结果表明,该方法在多个评估指标上持续优于基线方法,尤其使用 V-JEPA2 为主干时,表明无需额外训练即可实现更强的手势级可分性。增益突显高阶时间矩在捕捉超越外观或粗粒度语义的运动结构中的有效性。
作者使用合成基准测试评估运动相似性检索,该测试隔离运动与外观变化。结果表明,现有方法(包括基于 CLIP、光流和自监督模型)难以在风格变化下一致捕捉运动等价性。相比之下,他们的 SemanticMoments 方法通过聚合语义特征的时间统计,实现显著更高的检索准确率,展现出在保持运动结构的同时对变化外观更强的鲁棒性。