Command Palette
Search for a command to run...
SkillsBench:跨多样化任务评估Agent技能的有效性
SkillsBench:跨多样化任务评估Agent技能的有效性
摘要
Agent Skills 是一类结构化的程序性知识模块,可在推理阶段增强大语言模型(LLM)代理的能力。尽管该技术迅速得到应用,目前尚缺乏统一的标准来衡量其实际效用。为此,我们提出了 SkillsBench——一个涵盖11个领域、共86项任务的基准测试体系,每项任务均配备经过精心筛选的 Skills 以及确定性验证器。每个任务在三种条件下进行评估:无 Skills、使用精选 Skills,以及使用模型自生成的 Skills。我们在7,308条推理轨迹上测试了7种不同的代理-模型配置。实验结果表明,使用精选 Skills 可使平均通过率提升16.2个百分点(pp),但其效果在不同领域间差异显著,从软件工程领域的+4.5 pp到医疗健康领域的+51.9 pp不等;在84项任务中,有16项反而出现负面效果(即性能下降)。值得注意的是,模型自动生成的 Skills 在平均意义上未能带来任何提升,表明模型无法可靠地生成其自身在使用时所依赖的程序性知识。此外,模块数量控制在2至3个的聚焦型 Skills 表现优于全面详尽的文档型 Skills;同时,小型模型在配备 Skills 后,其性能可与未使用 Skills 的大型模型相媲美。
一句话总结
来自多个机构的研究人员推出了 SKILLSBENCH,这是一个评估结构化代理技能如何影响大语言模型在86项任务中表现的基准;经人工筛选的技能平均使成功率提升16.2个百分点,而自动生成的技能则无任何增益,表明模型无法可靠地创建自身所需的程序性知识。
主要贡献
- SKILLSBENCH 引入了首个标准化基准,用于评估代理技能,通过确定性验证器和三种评估条件(无技能、人工筛选技能、自生成技能),在11个领域的84项任务中衡量技能的影响。
- 在7种代理-模型配置下,人工筛选技能平均使任务通过率提升16.2个百分点,但效果因领域差异显著——从软件工程的+4.5pp到医疗领域的+51.9pp不等,其中16项任务甚至出现性能下降。
- 自生成技能平均无净收益,表明模型无法可靠地撰写自身所需的程序性知识;而聚焦于2–3个模块的精简技能优于全面文档,可使小模型在无技能条件下匹敌大模型。
引言
作者利用代理技能——结构化的指令、代码与验证逻辑包——在推理时增强大语言模型,无需微调,以弥合通用基础模型与特定领域工作流之间的差距。此前的代理基准仅评估原始模型性能,未能分离技能如何改善结果或何种设计要素驱动成功,导致实践者缺乏基于证据的指导。作者推出 SkillsBench,首个将技能作为首要评估对象的基准,通过在11个领域的84项任务中测试三种条件(无技能、人工筛选技能、自生成技能)及7种代理-模型配置,发现人工筛选技能平均提升解决率16.2个百分点,而自生成技能几乎无益。
数据集
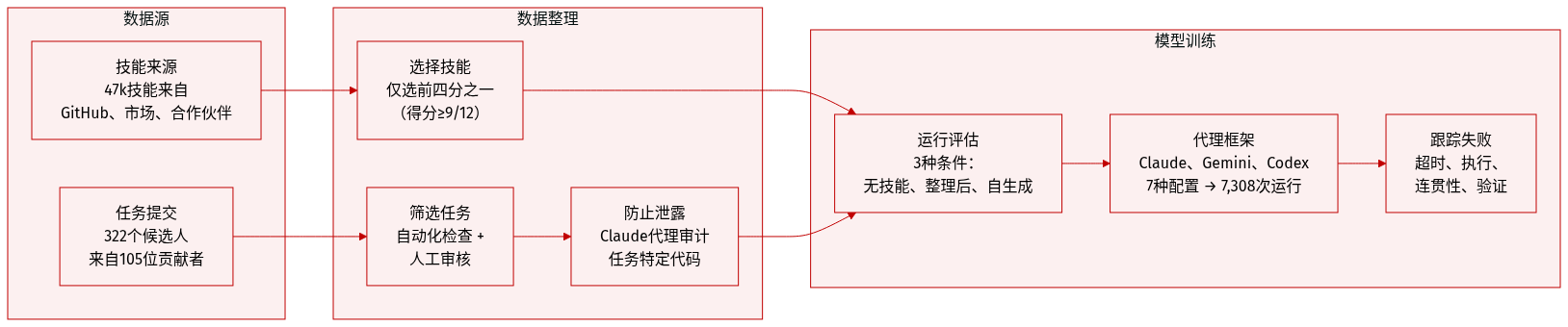
作者使用 SKILLSBENCH 基准评估技能增强如何提升基于大语言模型的代理性能。该数据集基于 Harbor 框架构建,包含从322个社区提交候选任务中筛选出的84项任务,覆盖11个领域。每项任务封装于 Docker 容器中,包含四个组件:人工编写的指令、隔离环境、参考解(oracle)和确定性验证器,以确保可复现评估。
各子集关键细节:
- 任务来源:来自学术界与工业界的105名贡献者提交322个候选任务;经自动化与人工审查后筛选出84个。
- 筛选规则:任务必须包含人工指令、通用技能(非任务特定)、确定性验证、通过自动化结构检查与 oracle 执行。人工评审员评估数据有效性、任务现实性、oracle 质量、技能实用性及反作弊措施。
- 技能来源:从 GitHub(12,847)、社区市场(28,412)及企业合作伙伴(5,891)收集47,150个唯一技能,按内容哈希去重。
- 技能选择:仅使用质量前四分之一(评分 ≥ 9/12)的技能,以隔离程序性知识与质量差异的影响。
- 任务难度:按人类完成时间估算分层,经领域专家审查。
论文如何使用数据:
- 任务在三种条件下评估:无技能、人工筛选技能、自生成技能。
- 三个商业代理框架(Claude Code、Gemini CLI、Codex CLI)运行7种代理-模型配置,产生7,308条轨迹。
- 人工筛选技能使平均通过率提升+12.66pp。
- 训练分割:不适用——SKILLSBENCH 仅用于评估,非训练。
- 混合比例:未使用;所有任务在受控条件下独立评估。
处理与元数据:
- 每个任务目录包含 TOML 配置(task.toml)、Dockerfile、skills/、solution/ 和 tests/(含 pytest 脚本)。
- 资源限制(CPU、内存、超时)在 task.toml 中按任务指定。
- 技能不得包含任务特定标识符、硬编码值或精确命令序列;必须提供适用于一类任务的程序性指导。
- 泄露预防:基于 Claude Code Agent SDK 的验证代理在 CI 中运行,检测技能-解泄露;失败任务被拒绝。
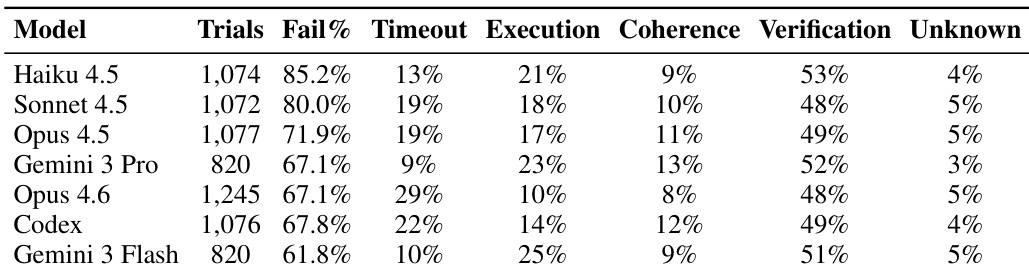
- 失败分类:代理失败按结构化测试输出程序化分为五类——超时、执行、连贯性、验证、未知——避免 LLM 作为评判者的变异性。
方法
作者采用三阶段流程构建、验证并评估技能增强代理基准,各阶段旨在确保程序保真度、结构完整性及可测量的性能提升。整体工作流始于从多样来源(以 GitHub、电商及企业系统图标表示)聚合候选技能,经去重后获得47,150个唯一技能。这些技能与来自105名贡献者的322个人工提交任务配对,形成初始基准语料库。
参见框架图:流程进入第二阶段“质量筛选”,自动化与人工审查机制构成双阶段漏斗。自动化检查验证结构合规性、确保100% oracle 执行、筛查AI生成内容、审计泄露或作弊。人工评审员随后评估数据有效性、任务现实性、技能质量及反作弊鲁棒性。此筛选将任务集缩减至84个高保真任务,覆盖11个领域。
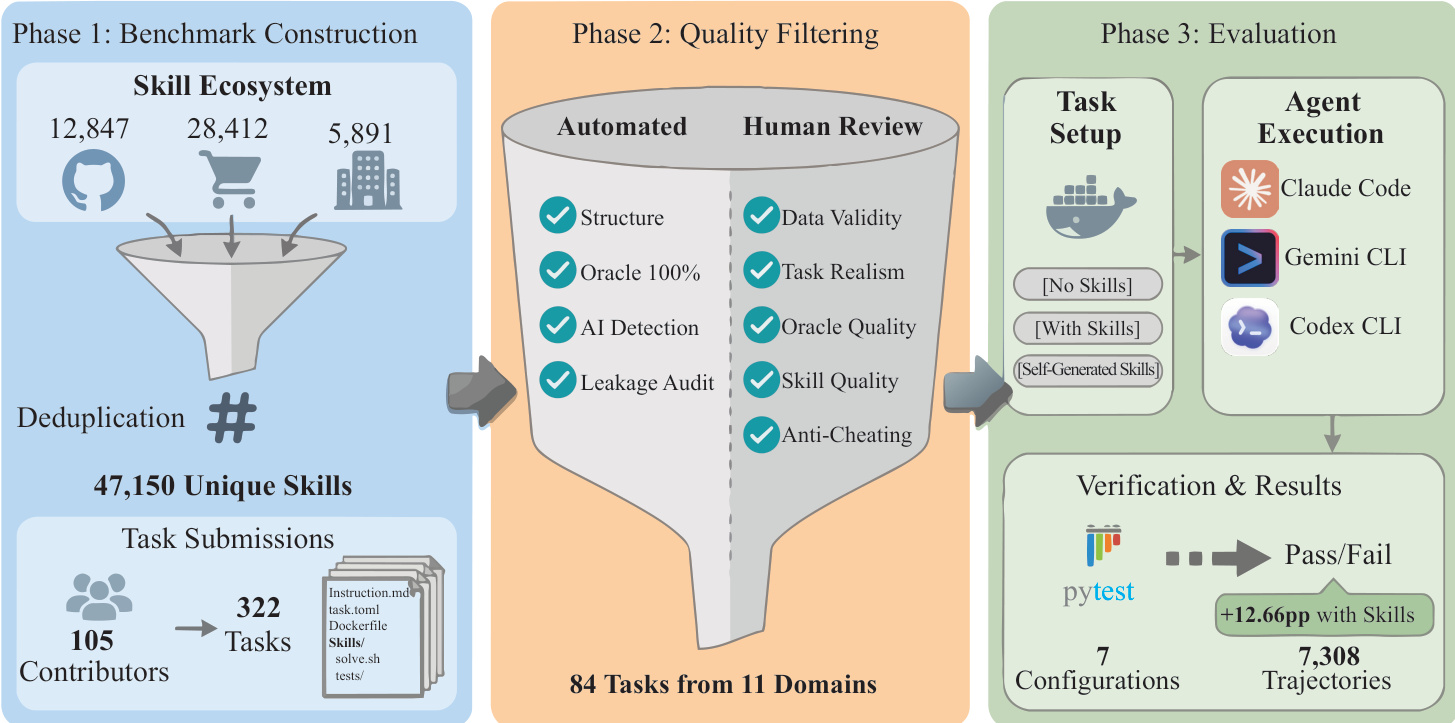
在第三阶段“评估”中,代理在容器化环境中以三种条件交互:无技能、预提供技能或自生成技能。代理接口通过抽象基类标准化,要求 step 方法将终端观测映射为动作。技能通过将 skills 目录复制到代理特定路径(如 /root/.claude/skills 或 /root/.agents/skills)注入每个容器,启用原生发现机制。Claude Code 与 Codex CLI 解析 SKILL.md 前置元数据以判断相关性,而 Gemini CLI 提供显式 activate_skill 工具。代理必须自主决定应用哪些技能,因指令从不指定它们。
每个技能结构为目录,包含必需的 SKILL.md 文件(含 YAML 前置元数据:名称与描述)及程序性正文,可选附带脚本或参考资料。执行期间,代理受时间或轮次限制,结果通过 pytest 确定性断言验证,输出二元通过/失败结果。评估报告7,308条轨迹,7种配置下技能可用时平均提升+12.66个百分点。
实验
- 人工筛选技能显著提升代理平均性能(+16.2pp),但效果因领域与代理-模型组合差异显著,医疗与制造领域增益最大。
- 自生成技能无净收益,常导致性能下降,揭示模型无法可靠生成所需程序性知识。
- 聚焦技能(2–3个模块)优于全面文档,表明简洁、模块化指导比详尽内容更有效。
- 配备技能的小模型可匹配或超越无技能的大模型,证明技能可部分弥补模型规模限制。
- 代理框架调节技能使用——某些框架可靠集成技能,而其他则忽略或未充分利用,凸显框架设计在实际部署中的重要性。
- 技能在需领域特定程序或脆弱格式的任务中最有效,若引入不必要复杂性或与现有模型先验冲突则适得其反。
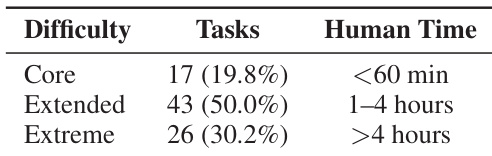
作者按难度与预估人力投入分类任务,显示多数任务属“扩展”级需1–4小时,核心任务少于60分钟,极端任务超4小时。此分布反映有意设计以覆盖广泛现实世界程序复杂度,多数任务需中等至大量人力投入。
作者使用结构化错误分类识别评估期间的基础设施级故障,发现2.3%的试验遭遇非代理错误(如验证器超时、Docker 设置问题或奖励文件缺失)。这些错误在评分中视为失败,但与代理能力限制不同,凸显在衡量代理性能时隔离系统级噪声的重要性。
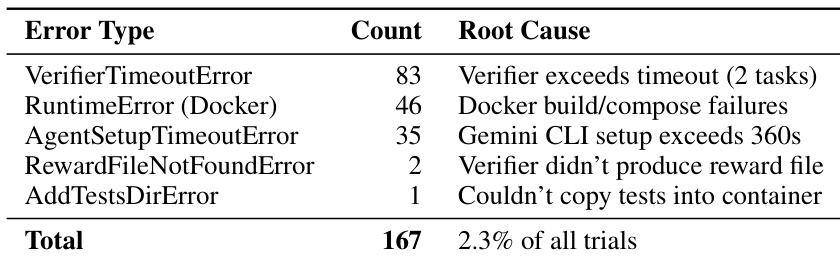
人工筛选技能在多数领域显著提升代理性能,增益范围从+4.5到+51.9个百分点,反映在预训练中程序性知识稀缺的领域具有强领域特定价值。但收益不均——医疗与制造领域显著改善,而软件工程与数学领域增益较温和,表明技能效果高度依赖任务对外部结构化指导的依赖程度。
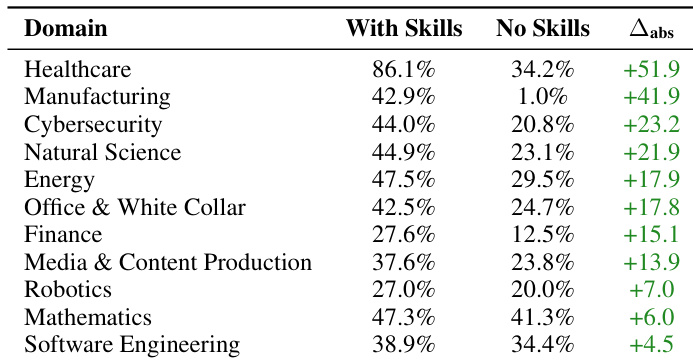
作者评估六种模型配置的失败模式,发现验证失败在所有模型中占主导,表明输出质量(非结构理解)是主要瓶颈。较小模型如 Haiku 4.5 整体失败率与执行错误更高,而较大模型如 Opus 4.6 超时率更高,暗示其追求更雄心勃勃但耗时的策略。Gemini 3 Flash 与 Pro 超时率较低但执行失败率更高,反映更快但可靠性较低的执行。
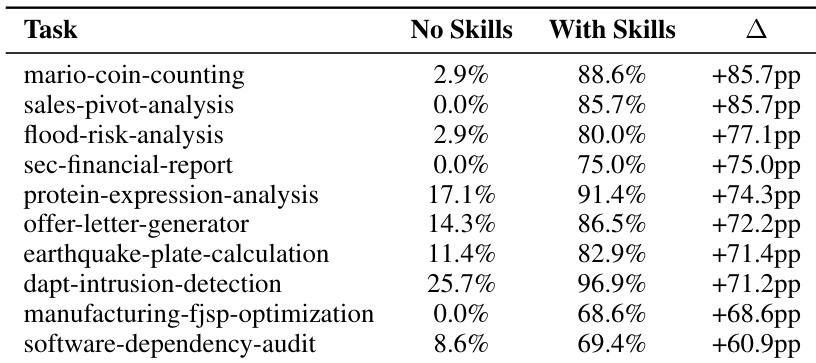
作者使用人工筛选的程序性技能评估其在多任务中对代理性能的影响,发现技能显著提升需特定工作流或API的领域特定任务成功率。结果表明,技能可将近乎零的性能转化为高通过率——如销售透视分析与洪水风险分析——通过提供模型无法可靠自生成的精确、可操作指导。然而收益非普适,部分任务无改善甚至退化,凸显技能在填补具体程序缺口时最有效,而非添加冗余或冲突信息。