Command Palette
Search for a command to run...
REDSearcher:一种可扩展且成本高效的长时序搜索Agent框架
REDSearcher:一种可扩展且成本高效的长时序搜索Agent框架
摘要
大型语言模型正从通用知识引擎逐步转向真实世界问题求解器,然而在深度搜索任务中对其进行优化仍面临重大挑战。其核心瓶颈在于高质量搜索轨迹与奖励信号的极端稀疏性,这主要源于长时程任务构建的可扩展性难题,以及涉及外部工具调用的高交互成本的滚动仿真(rollout)开销。为应对这些挑战,我们提出 REDSearcher——一个统一框架,通过协同设计复杂任务生成、中期训练与后期训练,实现可扩展的搜索代理优化。具体而言,REDSearcher 引入以下关键改进:(1)我们将任务生成建模为双约束优化问题,通过图拓扑结构与证据分布两个维度精确调控任务难度,从而实现复杂、高质量任务的可扩展生成;(2)引入工具增强型查询(tool-augmented queries),激励模型主动使用工具,而非被动回忆信息;(3)在中期训练阶段,显著强化模型的核心原子能力——知识理解、规划推理与函数调用能力,大幅降低下游训练中高质量轨迹的收集成本;(4)构建本地模拟环境,支持强化学习实验的快速、低成本算法迭代。在纯文本与多模态搜索代理基准测试中,我们的方法均达到当前最优性能。为进一步推动长时程搜索代理的研究,我们将公开 10,000 条高质量复杂文本搜索轨迹、5,000 条多模态轨迹,以及 1,000 条文本强化学习查询数据集,并同步提供完整代码与模型检查点(checkpoints)。
一句话总结
REDSearcher 团队提出了一种统一框架,通过协同设计任务合成、中期训练和后期训练,利用图约束任务生成和工具增强查询,减少对昂贵真实世界 rollout 的依赖,在文本和多模态基准测试中实现 SOTA 表现,并公开发布 16K 条轨迹和代码。
主要贡献
- REDSearcher 通过双重约束(图树宽用于逻辑复杂度,证据分散度)合成复杂任务,解决高质量搜索轨迹稀缺问题,支持可扩展生成需迭代规划和跨文档综合的长视野推理问题。
- 引入工具增强查询和中期训练强化核心能力(知识、规划、函数调用),促进主动工具使用并降低高质量轨迹收集成本,同时本地模拟环境支持快速、低成本的强化学习实验。
- 在纯文本和多模态基准上评估,REDSearcher 实现最先进性能,并公开发布 10K 文本、5K 多模态搜索轨迹和 1K 强化学习查询,支持未来深度搜索代理研究。
引言
作者利用大语言模型解决长视野搜索任务——代理需跨多步骤和多来源规划、检索和综合信息——但指出先前工作受限于稀疏的高质量训练数据和昂贵的实时工具交互成本。现有数据集常缺乏结构复杂性,依赖简单线性推理,而真实搜索需处理循环或完全耦合约束,要求维持纠缠假设。REDSearcher 通过协同设计任务合成、中期训练和强化学习解决此问题:使用树宽引导图拓扑和证据分散生成复杂任务,注入工具增强查询促进主动工具使用,早期强化核心子技能以降低 rollout 成本,并部署模拟环境加速强化学习迭代。结果是一个可扩展、成本高效的框架,在文本和多模态搜索基准上实现最先进性能,附带公开 16K 高质量轨迹和训练素材。
数据集
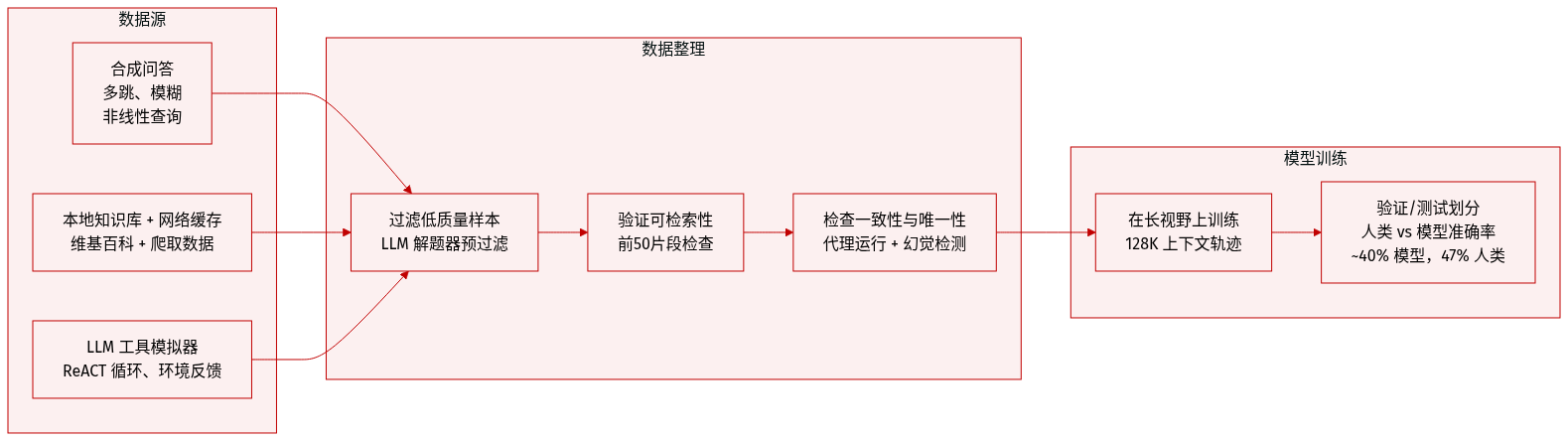
- 作者构建合成数据集,训练能处理多跳、模糊和非线性查询的深度搜索代理——此类任务需迭代工具使用和证据综合,而现有开源数据集缺乏。
- 数据集通过可扩展、可控合成流水线生成,结合本地知识库和缓存网页信号,通过模糊化和复杂约束有意增加难度。
- 为确保质量和挑战性,作者应用五阶段验证流水线:
- LLM 解题器预筛选:移除无需工具即可解决的实例。
- 可检索性检查:过滤答案未出现在前 50 条搜索片段中的问题。
- 幻觉/不一致性检查:使用 LLM 验证器检测证据与问答对之间的矛盾。
- 代理 rollout 验证:运行强工具使用代理进行多次 rollout;保留至少一次成功实例,并记录通过率作为置信度。
- 答案唯一性检查:丢弃存在合理替代答案的实例以减少歧义。
- 质量研究确认 500 个人工验证实例中 85%+ 逻辑一致且有依据;强模型(DeepSeek-V3.2)准确率约 40%,人类在 30 分钟内解决 47%——验证数据集真实难度。
- 训练时,作者生成多轮工具调用数据,模拟 ReACT 循环,使用 LLM 创建工具集、查询和环境反馈——避免昂贵真实 API 调用。
- 使用基于维基百科和网络爬取数据构建的本地模拟网络环境合成长视野交互轨迹(高达 128K 上下文),确保可解性并支持复杂多步搜索任务训练。
- 数据集包含高度复杂、现实启发的问题,需跨领域推理,如识别唱片压片厂、医疗机构、赛车赛事和历史遗址——均基于合成但合理的证据。
- 未裁剪;元数据通过合成流水线隐式构建,为每个实例嵌入依据信号(如 KB 三元组、缓存段落)和置信度指标(如代理通过率)。
方法
作者利用结构化多阶段训练框架开发 REDSearcher——一种能在文本和多模态领域进行深度长视野搜索的工具增强代理。架构基于可扩展任务合成流水线、两阶段中期训练和结合监督微调与强化学习的后期训练。每个组件旨在解决监督稀疏性和真实世界交互的计算成本。
方法核心始于可扩展任务合成流水线,通过构建具有可控结构和分布复杂度的推理图生成复杂、可验证的问答对。如下图所示,流水线从维基百科抽取种子实体集,构建有向无环图(DAG),结合结构化 Wikidata 关系和基于网络的超链接遍历。随后由 LLM 驱动代理引入循环和互锁约束,增加树宽,迫使解题器维持多个假设。子图采样从每个主图提取多个推理上下文,LLM 生成基于这些拓扑的自然语言问题。关键创新是工具强制查询演化:静态实体被替换为需外部工具调用的操作约束(如路由查询或基于引用的查找),确保成功完成依赖工具使用。
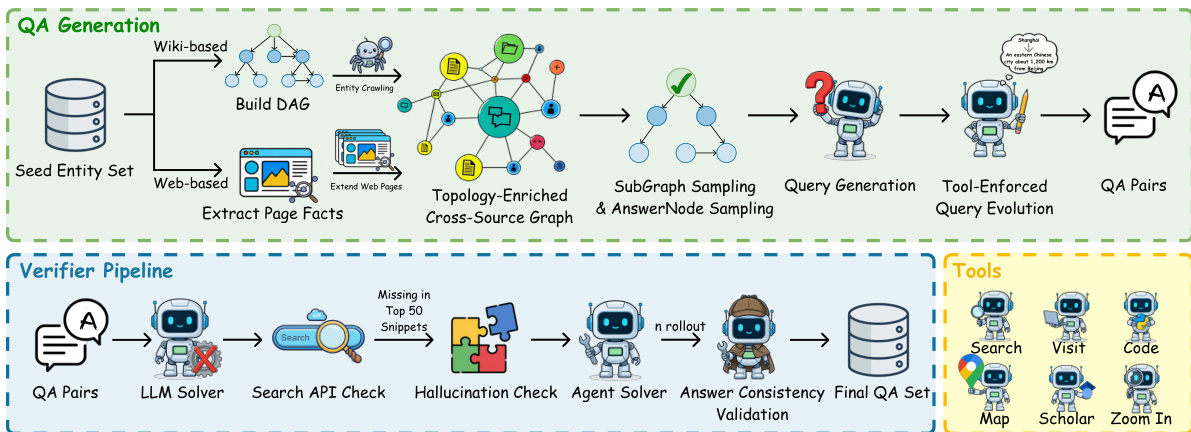
为确保质量和难度,验证流水线过滤可解实例。LLM 解题器检查幻觉和 API 可检索性,代理解题器执行 n-rollout 验证答案一致性。仅通过多阶段过滤的问答对保留用于训练。对于多模态任务,流水线通过将中间节点锚定到图像并强制跨模态依赖注入视觉约束,确保视觉理解对任务完成必要。
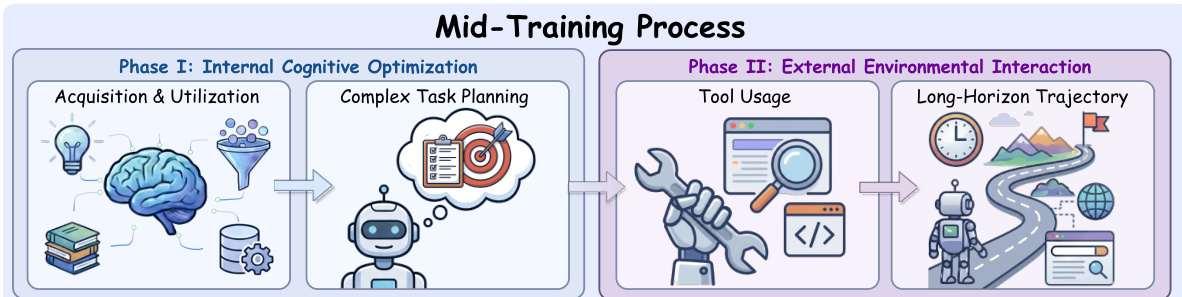
训练过程分为两个主要阶段:中期训练和后期训练。如框架图所示,模型从开源 LLM 检查点开始,中期训练经历原子能力获取(第 1 阶段,32K 上下文)和复合能力开发(第 2 阶段,128K 上下文)。随后是代理监督微调(SFT)和强化学习(RL)后期训练阶段。

中期训练进一步分解为两个阶段。第 I 阶段聚焦内部认知优化:意图锚定接地,教导模型在特定查询意图下从嘈杂网页提取相关事实;分层规划,支持将模糊目标分解为具体子任务。第 II 阶段引入外部环境交互,模型学习执行工具调用并在长视野轨迹中维持状态。此分阶段方法允许模型在必要前以基础技能热启动,避免昂贵真实世界 rollout。
后期训练中,模型在真实环境生成的高质量 ReAct 风格轨迹上进行监督微调,使用五种工具接口:搜索、访问、Python 解释器、Google Scholar 和 Google 地图。SFT 目标屏蔽环境观察以防止梯度污染。随后应用基于 GRPO 的代理强化学习,奖励为二元(0/1)基于答案正确性,优势在每题的 rollout 组内标准化以稳定训练。为加速实验,RL 期间使用功能等价模拟环境,模拟真实 API 同时确保证据完整性并注入真实噪声。模拟环境基于缓存网页数据构建,包含 URL 混淆以防止模型偏见。异步 rollout 和双层负载均衡策略用于处理长轨迹的计算需求。
整个框架设计为高效扩展:任务合成重用图以摊销 LLM 成本,中期训练避免必要前的真实世界交互,RL 利用经代理验证的查询集确保干净学习信号。结果是一个能迭代获取证据、维持假设并在多源多模态间综合信息的深度搜索代理。
实验
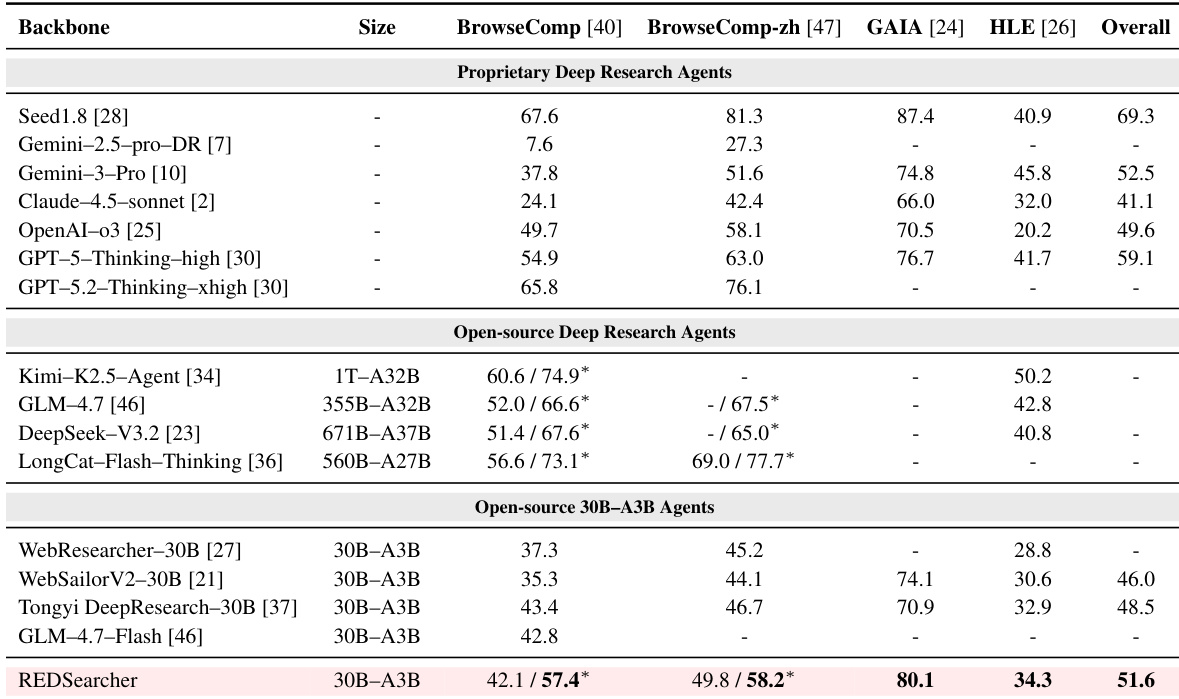
- REDSearcher 在开源 30B 参数代理中树立新 SOTA,超越开源和专有模型在 GAIA 等复杂基准的表现,展示卓越参数效率和深度研究能力。
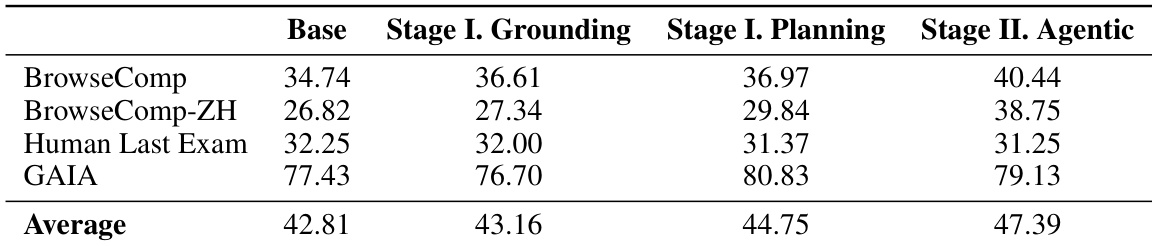
- 中期训练阶段逐步提升性能:第 I 阶段改善接地和规划,尤其在 GAIA 上;第 II 阶段实现稳健工具使用和长视野执行,显著提升 BrowseComp-ZH 表现。
- 强化学习进一步精炼能力,提升整体分数并减少 10.4% 工具使用而不牺牲准确率,表明更高效、更策略的搜索行为。
- 工具使用分析显示 REDSearcher 极少依赖参数化知识,仅在启用工具时表现优异——凸显强规划、证据综合和迭代推理优于记忆。
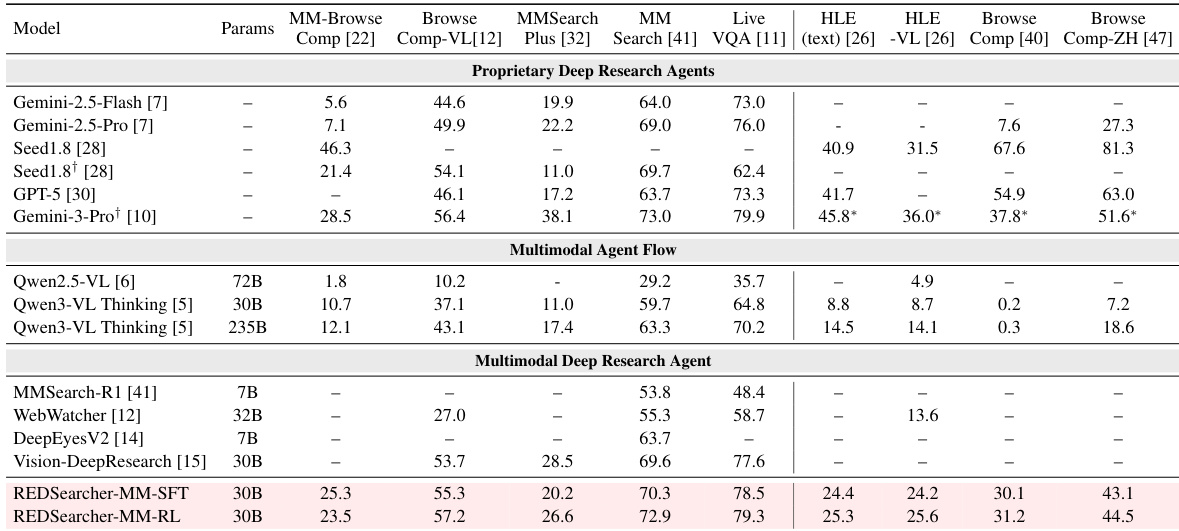
- 多模态实验在视觉-语言基准上表现强劲,超越大型专有模型和 Qwen3-VL 基线,能力良好迁移至纯文本任务。
- 工具使用模式分析显示自适应行为:简单任务需更少轮次,复杂任务涉及更多分解、反思和验证;RL 训练减少不必要搜索步骤,尤其在较易基准上。
作者采用分阶段中期训练方法逐步增强模型代理能力,每阶段建立在前一阶段基础上,提升多基准表现。结果显示,模型在接地、规划和代理交互阶段进展中平均分数持续提升,尤其在 GAIA 和 BrowseComp-ZH 等复杂任务上。此结构化训练策略有效弥合理解与行动差距,支持深度搜索场景中更稳健、目标一致的行为。
作者评估其多模态搜索代理 REDSearcher-MM,在多样基准上表现超越专有和开源基线,尤其在需视觉接地和长视野推理的复杂任务上。结果显示强化学习后持续提升,工具使用效率提高,在 MM-BrowseComp 和 LiveVQA 等具挑战性多模态基准上表现更强。模型也展示强迁移能力,尽管针对多模态输入优化,仍保持纯文本任务强表现。
作者使用 30B 参数模型结合上下文管理,在开源代理中实现 SOTA 表现,超越更大专有模型在 GAIA 等关键基准上的表现。结果显示,其方法通过高效工具使用和多模态推理实现卓越深度研究能力,即使与显著更大的基线相比。强化学习进一步提升表现,通过精炼搜索效率和减少冗余工具调用而不牺牲准确率。
作者使用 30B 参数模型结合上下文管理,在开源代理中实现 SOTA 表现,超越更大专有模型在 GAIA 等复杂推理基准上的表现。结果显示,渐进式中期训练阶段和强化学习显著提升长视野搜索效率,减少工具调用同时维持或提高准确率。模型也展示强多模态搜索能力,有效整合视觉和文本证据跨多样基准。
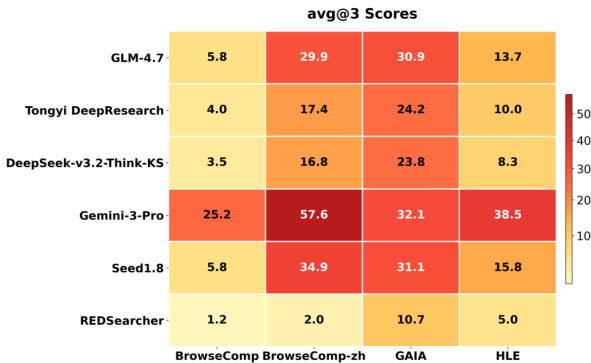
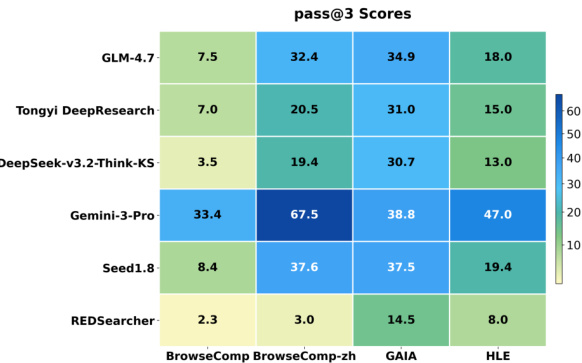
作者使用 REDSearcher 评估在 BrowseComp、GAIA 和 HLE 等多个具挑战基准上的表现,与开源和专有模型比较。结果显示 REDSearcher 在竞争性或更优分数上超越更大专有系统,尤其在测试复杂代理推理的 GAIA 上表现优异。模型强表现归因于其架构和训练方法,包括上下文管理和强化学习,提升效率和长视野任务执行。