Command Palette
Search for a command to run...
MOSS-Audio-Tokenizer:面向未来音频基础模型的音频分词器扩展
MOSS-Audio-Tokenizer:面向未来音频基础模型的音频分词器扩展
摘要
离散音频分词器是赋予大型语言模型原生音频处理与生成能力的核心基础。尽管近期取得进展,现有方法通常依赖预训练编码器、语义蒸馏或异构的CNN架构,这些设计引入了固定的归纳偏置,限制了重建保真度,并阻碍了有效扩展。本文主张,离散音频分词应通过统一且可扩展的架构实现完全端到端的学习。为此,我们首先提出CAT(基于Transformer的因果音频分词器,Causal Audio Tokenizer with Transformer),一种完全基于Transformer的架构,从零开始联合优化编码器、量化器与解码器,以实现高保真重建。基于CAT架构,我们进一步构建了MOSS-Audio-Tokenizer,这是一个大规模音频分词器,参数量达16亿,基于300万小时多样化通用音频数据进行预训练。实验表明,这一由同质因果Transformer模块构成的简单、完全端到端的方法能够实现平稳扩展,在多种音频领域均支持高保真重建。在语音、声音与音乐任务中,MOSS-Audio-Tokenizer在广泛比特率范围内持续优于以往各类编码器,且随着模型规模扩大表现出可预测的性能提升。尤为关键的是,利用本模型生成的离散音频标记,我们实现了首个完全自回归的文本到语音(TTS)系统,其性能超越了此前的非自回归及级联式系统。此外,MOSS-Audio-Tokenizer无需额外编码器即可实现具备竞争力的自动语音识别(ASR)性能。我们的研究结果表明,CAT架构有望成为下一代原生音频基础模型的统一、可扩展接口。
一句话总结
MOSI.AI 研究人员提出 CAT,一种端到端、基于 Transformer 的音频分词器,支持高保真重建和可扩展的音频基础模型;其 16 亿参数的 MOSS-Audio-Tokenizer 在语音、音乐和声音上均优于先前的编解码器,并在无需辅助编码器的情况下驱动最先进的自回归 TTS 和 ASR。
主要贡献
- 我们引入 CAT,一种端到端、同构的基于 Transformer 的离散音频分词架构,从零开始联合优化编码器、量化器和解码器,无需依赖预训练组件或异构 CNN 设计,从而提升重建保真度和可扩展性。
- 我们将 CAT 扩展为 MOSS-Audio-Tokenizer,一个在 300 万小时多样化音频上训练的 16 亿参数模型,在所有比特率下于语音、声音和音乐上均达到最先进的重建效果,并展现出随规模增长的可预测性能提升。
- 借助 MOSS-Audio-Tokenizer 的分词,我们构建了首个纯自回归 TTS 系统,其性能优于非自回归和级联基线,并在无需辅助编码器的情况下展示出有竞争力的 ASR 性能,验证了 CAT 作为音频基础模型统一接口的有效性。
引言
作者利用端到端、同构的 Transformer 架构——CAT——构建了 MOSS-Audio-Tokenizer,一个在 300 万小时多样化音频上训练的 16 亿参数可扩展音频分词器。先前的分词器通常依赖预训练编码器、混合 CNN-Transformer 设计或多阶段训练,这些方法引入了固定的归纳偏置,限制了重建保真度并阻碍了扩展性。MOSS-Audio-Tokenizer 通过在因果、流式友好的框架下从零开始联合优化编码器、量化器和解码器克服了这些问题,在所有比特率下于语音、声音和音乐上均实现最先进的重建效果。其离散分词支持首个纯自回归 TTS 系统,性能优于非自回归和级联基线,并在无需辅助编码器的情况下支持有竞争力的 ASR——确立了 CAT 作为可扩展、原生音频语言模型的统一基础。
数据集

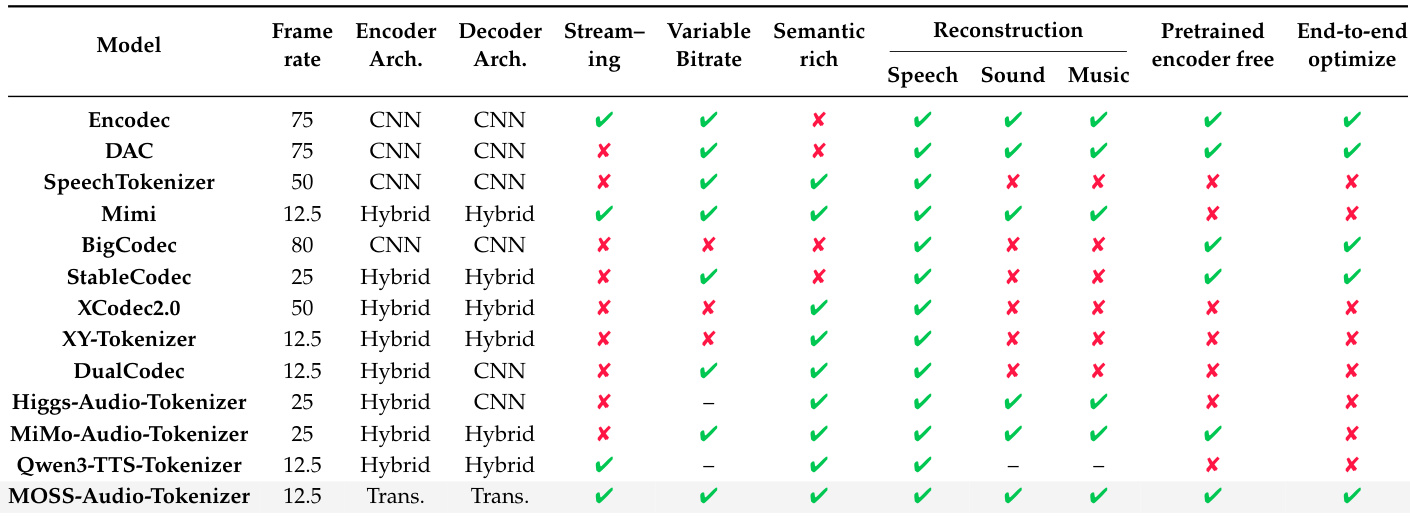
作者使用 12 种基线音频分词器进行评估,每个分词器均来自官方发布版本,并配置为单声道音频,采样率分别为 16 kHz 或 24 kHz。关键细节如下:
- Encodec:官方因果模型,24 kHz;约 1400 万参数。通过评估时截断 RVQ 层控制比特率。
- DAC:24 kHz 单声道模型;约 7400 万参数。使用工程化判别器和改进的 VQ。
- SpeechTokenizer:在 16 kHz 语音上训练;约 1.0367 亿参数。通过第一层 RVQ 蒸馏 HuBERT 以实现语音解耦。
- Mimi:24 kHz;输出 12.5 Hz 的分词。支持流式编码/解码。
- BigCodec:16 kHz;单 VQ 码本(大小 8192);80 Hz 帧率;约 1.59 亿参数。
- Stable Codec:16 kHz 语音;使用 RFSQ 瓶颈;约 9.53 亿参数。评估使用 1x46656_400bps 和 2x15625_700bps 预设。
- XCodec2.0:16 kHz;集成预训练语音编码器;50 Hz 帧率;约 8.22 亿参数。
- XY-Tokenizer:16 kHz;通过双编码器联合建模语义/声学信息;12.5 Hz,8 层 RVQ(码本 1024);约 5.19 亿参数。量化器丢弃已禁用。
- Higgs Audio Tokenizer:24 kHz;约 2.01 亿参数。
- MiMo Audio Tokenizer:在超过 1100 万小时上训练;支持波形重建和语言建模;约 12 亿参数。
- Qwen3 TTS Tokenizer:24 kHz;12.5 Hz 帧率;约 1.7 亿参数。专为流式 TTS 设计。
在训练期间,作者应用渐进式序列丢弃(Progressive Sequence Dropout)随机截断活跃的 RVQ 层。在推理时,解码仅使用每时间步的前 k 个 RVQ 分词,深度 Transformer 仅自回归预测这 k 个分词,省略更细粒度的层。所有模型均在其默认或推荐配置下评估,未进行额外过滤或数据集组合。
方法
作者利用纯 Transformer 架构 CAT(Causal Audio Tokenizer with Transformer),在不依赖卷积归纳偏置的情况下实现可扩展、高保真的离散音频分词。该框架直接处理原始波形,设计为端到端训练,同时支持语义对齐和声学重建。请参考框架图以了解编码器-解码器结构及辅助组件概览。
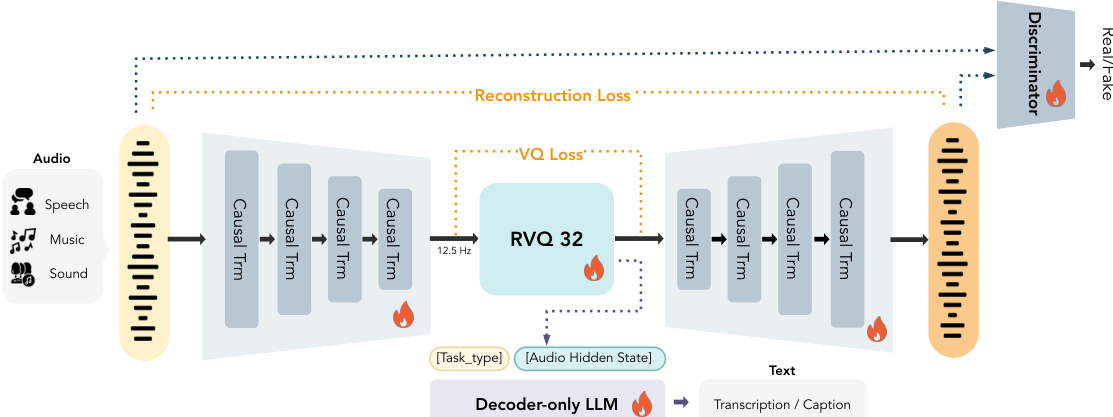
编码器首先将 24 kHz 原始音频波形分块为固定维度向量,然后应用堆叠的因果 Transformer 块。为逐步压缩时间分辨率,在特定 Transformer 层后插入分块操作,减少序列长度,最终将输入映射为 12.5 Hz 的离散分词序列。解码器以相反结构重建波形,完全因果地从离散分词中恢复。离散化由 32 层残差向量量化器(RVQ)处理,支持通过训练期间的量化器丢弃实现可变比特率分词。每层量化采用因子化向量量化和 L2 归一化码本,码本条目直接通过梯度下降优化。
为鼓励语义丰富的表示,作者附加了一个 5 亿参数的仅解码器因果语言模型(LLM),其以量化器的隐藏状态为条件。LLM 在多样化的音频到文本任务上训练——包括 ASR、多说话人 ASR 和音频字幕——使用任务特定提示标记前置输入。语义损失计算如下:
Lsem=−t=1∑∣s∣logpθLLM(st∣T,q,s<t),其中 s 是目标文本序列,q 是量化音频表示,T 是任务标签。
声学保真度通过多尺度梅尔频谱损失确保:
Lrec=i=5∑11∥S2i(x)−S2i(x^)∥1,其中 S2i(⋅) 表示使用窗口大小 2i 和步长 2i−2 计算的梅尔频谱。多判别器的对抗训练进一步提升感知质量,遵循 XY-Tokenizer 的损失公式。整体生成器目标结合语义、重建、承诺、码本、对抗和特征匹配损失,并带有可学习权重:
LG=λsemLsem+λrecLrec+λcmtLcmt+λcodeLcode+λadvLadv+λfeatLfeat.所有组件——编码器、量化器、解码器、LLM 和判别器——均以端到端方式联合优化。
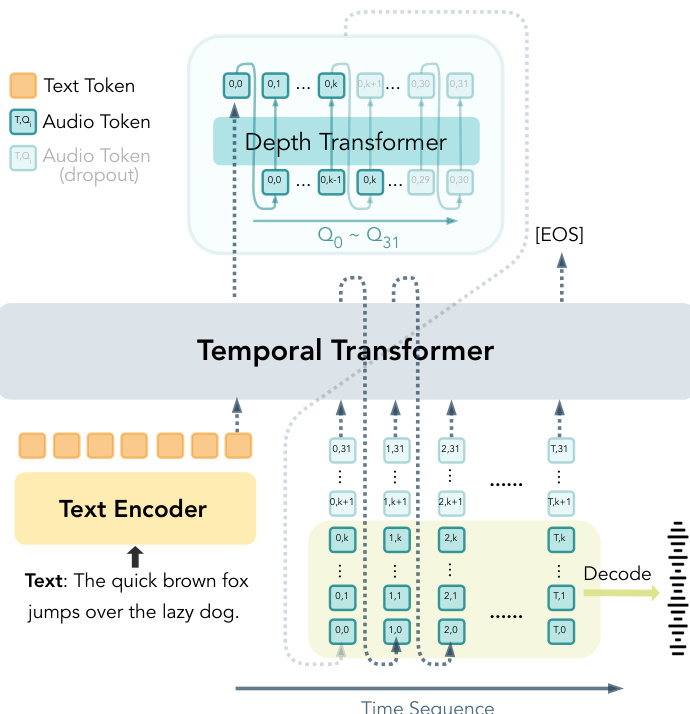
为实现端到端自回归语音生成,作者构建了 CAT-TTS,直接从文本和说话人提示预测 CAT 的 RVQ 分词。该模型采用时间 Transformer 捕捉跨时间的长距离依赖,并使用深度 Transformer 建模每个时间步内的粗到细结构。深度 Transformer 仅根据前一时间步和当前步骤的前几层自回归预测 RVQ 分词,保持严格的因果性。
为在单个模型内支持可变比特率合成,作者引入渐进式序列丢弃。在训练期间,以概率 p 采样随机前缀长度 K∈{1,…,Nq−1},并丢弃第 K+1 到 Nq 层的 RVQ 分词。有效活跃层数定义为:
K^=(1−z)Na+zK,其中 z∼Bernoulli(p)。时间 Transformer 在每个时间步接收前 K^ 层的聚合嵌入:
e~t=k=1∑K^Embk(qt,k).训练损失仅在保留的前缀上计算:
L=−t=1∑Tk=1∑K^logpθ(qt,k∣x,q<t,qt,<k).在推理时,合成比特率通过选择推理深度 Kinfer 控制。时间 Transformer 处理前 Kinfer 个 RVQ 流,深度 Transformer 仅预测这些层。结果分词使用 CAT 解码器解码为波形,由于训练期间的量化器丢弃,该解码器对可变比特率具有固有鲁棒性。
如下图所示,时间 Transformer 随时间处理文本和聚合音频分词嵌入,而深度 Transformer 在各层自回归预测 RVQ 分词,丢弃机制支持可变深度生成。
实验
- MOSS-Audio-Tokenizer 在所有比特率下语音重建表现优异,在低比特率下优于先前方法,在中高比特率下达到最先进水平;在通用音频和音乐上保持有竞争力的表现,质量随比特率增加而提升。
- 渐进式序列丢弃显著增强 TTS 系统在降低比特率下的鲁棒性,支持在不同丢弃率下稳定性能,同时减少训练内存占用;采用 p=1.0 以实现最优效率且无质量损失。
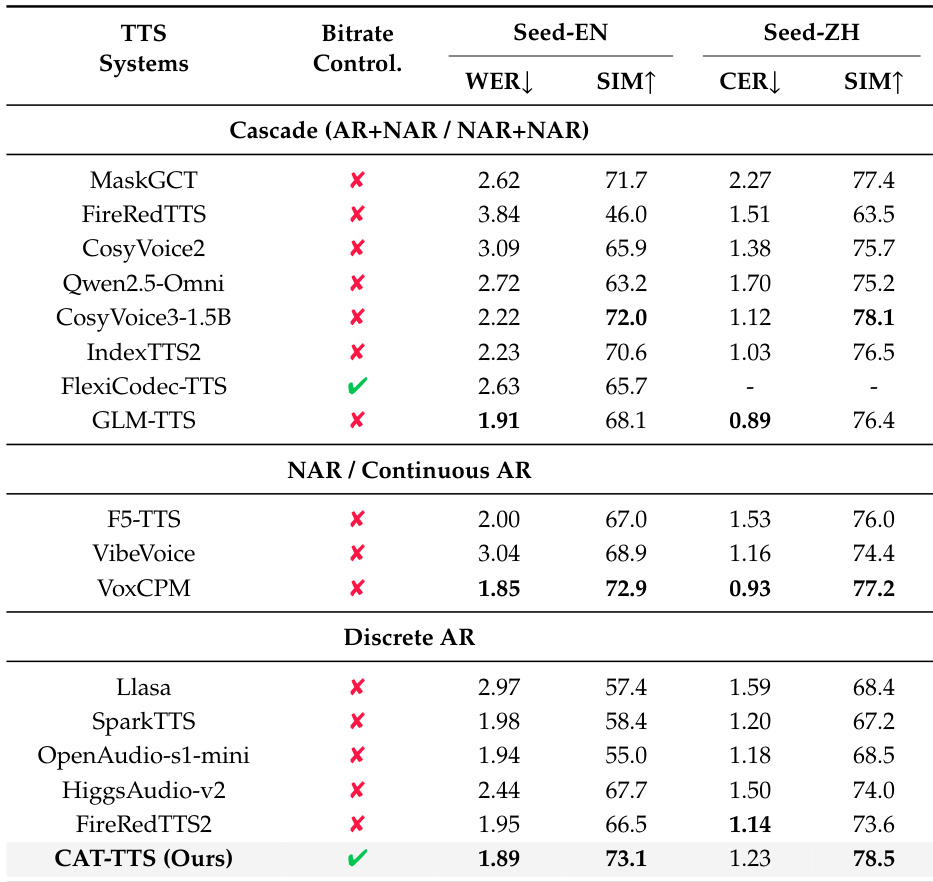
- CAT-TTS 在说话人相似度上超越先前的离散自回归 TTS 模型,在词错误率上匹配 IndexTTS2 和 VoxCPM 等顶级系统,在 Seed-TTS-Eval 上对英语和中文均取得最高说话人相似度分数,验证其在零样本生成中的有效性。
- 端到端优化对 CAT 的可扩展性至关重要,支持随训练持续提升重建质量,而部分优化因冻结组件早期即达到平台期。
- 模型参数和量化容量必须同步扩展;大模型在高比特率下受益,但在低比特率下表现不佳,揭示比特率是主要瓶颈——最优扩展需同步扩大两者。
- 重建保真度随训练批量大小增加而持续提升,表现出可预测的扩展行为,更高吞吐量直接转化为相同训练步数下的更高质量。
- 主观评估确认 MOSS-Audio-Tokenizer 在所有比特率下提供高感知质量,在低比特率下优于可变比特率分词器,在目标比特率下匹配专用分词器。
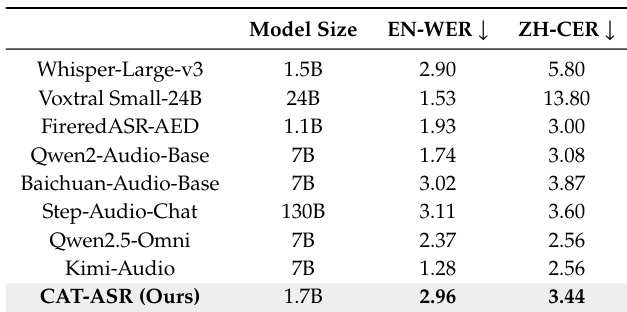
- CAT 分词支持有效的语音理解:CAT-ASR 在直接输入 LLM 时,在英语和中文基准上实现有竞争力的 WER 和 CER,展示其与文本的良好对齐和足够的语言内容保留。
作者使用 CAT-TTS——一种完全自回归的离散分词系统——在英语和中文基准上实现最先进的说话人相似度分数,同时保持低词错误率。结果表明 CAT-TTS 超越先前的离散自回归模型,并匹配或超过近期级联和非自回归系统的性能,证明其统一离散接口在高质量零样本语音生成中的有效性。该系统还支持可变比特率控制,实现灵活合成而不牺牲保真度。
作者使用 MOSS-Audio-Tokenizer 在多个比特率下实现语音、声音和音乐的强重建效果,尤其在低和中比特率下优于先前方法,同时通过端到端优化保持可扩展性。结果表明,其基于 Transformer 的架构、可变比特率支持和语义丰富性有助于在不依赖预训练编码器的情况下实现持续高质量重建。该模型设计使其在不同领域和比特率下均表现稳健,区别于其他缺乏端到端训练或无法有效扩展的分词器。
作者将 CAT 分词直接作为大型语言模型的输入用于自动语音识别,在英语和中文基准上实现有竞争力的词和字符错误率。结果表明 CAT 分词保留了足够的语言内容并与文本良好对齐,无需额外对齐或辅助监督即可实现有效语音理解。
MOSS-Audio-Tokenizer 在语音、通用音频和音乐基准上,在低、中、高比特率下始终优于或匹配其他开源音频分词器,且性能随比特率增加而提升。该模型通过端到端优化展现出强可扩展性,即使在可变比特率条件下仍保持高重建保真度。其设计使其在不同音频类型下均表现稳健,无需为不同比特率或领域使用单独模型。
