Command Palette
Search for a command to run...
SpargeAttention2:通过混合Top-k+Top-p掩码与蒸馏微调实现可训练的稀疏注意力
SpargeAttention2:通过混合Top-k+Top-p掩码与蒸馏微调实现可训练的稀疏注意力
Jintao Zhang Kai Jiang Chendong Xiang Weiqi Feng Yuezhou Hu Haocheng Xi Jianfei Chen Jun Zhu
摘要
许多无需训练的稀疏注意力方法在加速扩散模型方面表现有效。近期,多项研究指出,将稀疏注意力机制设计为可训练形式,可在保持生成质量的同时进一步提升稀疏度。本文围绕三个核心问题展开研究:(1)两种常见的掩码规则——Top-k 与 Top-p——在何种情况下会失效?如何避免这些失效?(2)为何可训练的稀疏注意力能够实现比无训练方法更高的稀疏度?(3)使用扩散损失对稀疏注意力进行微调存在哪些局限性?又该如何克服?基于上述分析,本文提出 SpargeAttention2,一种可训练的稀疏注意力方法,能够在不损害生成质量的前提下实现高稀疏度。SpargeAttention2 包含三个关键组件:(i)一种融合 Top-k 与 Top-p 的混合掩码策略,以在高稀疏度下提升掩码的鲁棒性;(ii)一种高效的可训练稀疏注意力实现方式;(iii)一种受知识蒸馏启发的微调目标函数,以在使用稀疏注意力进行微调过程中更有效地保持生成质量。在视频扩散模型上的实验表明,SpargeAttention2 可实现 95% 的注意力稀疏度,并带来 16.2 倍的注意力计算加速,同时在生成质量上持续优于现有稀疏注意力方法。
一句话总结
清华大学与字节跳动的研究人员提出 SpargeAttention2,这是一种可训练的稀疏注意力方法,结合了 Top-k 与 Top-p 掩码策略及基于蒸馏的微调,可在视频扩散模型中实现 95% 的稀疏度和 16.2 倍加速,同时保持生成质量,超越先前无需训练的稀疏方法。
主要贡献
- SpargeAttention2 引入了一种混合 Top-k 与 Top-p 掩码规则,可在高稀疏度下稳健保留关键注意力模式,解决了当注意力权重分布均匀或高度偏斜时,单一掩码策略失效的问题。
- 它实现了高效的可训练稀疏注意力内核,并在微调阶段采用速度级蒸馏损失,使稀疏注意力输出与冻结的全注意力模型对齐,从而在微调数据分布不匹配的情况下仍保持生成质量。
- 在视频扩散模型上评估,SpargeAttention2 实现了 95% 的注意力稀疏度和 16.2 倍的注意力加速,同时保持视觉质量和时序一致性,优于先前的无需训练及可训练稀疏注意力方法。
引言
作者利用可训练稀疏注意力加速视频扩散模型,这类模型因长序列和二次方注意力复杂度而面临高昂计算成本。先前方法要么使用固定掩码规则(如 Top-k 或 Top-p),在高稀疏度下失效——在均匀分布中遗漏上下文,或在偏斜分布中过度依赖注意力“汇点”;要么依赖扩散损失进行微调,当微调数据与预训练数据分布不匹配时会降低质量。他们的主要贡献 SpargeAttention2 引入混合 Top-k+Top-p 掩码器以实现稳健的标记选择、高效的可训练稀疏注意力内核,以及基于蒸馏的微调目标,通过与冻结的全注意力模型对齐来保持生成质量。这使得在不牺牲输出保真度的前提下,实现 95% 稀疏度和 16.2 倍注意力加速。

数据集
- 作者使用四个不同的图像提示生成图 1 的视觉内容,每个提示旨在测试图像合成中的风格与构图多样性。
- 第一个提示描绘一只北极熊在北极海岸弹吉他,结合真实野生动物摄影与奇幻叙事元素,在金色日光下呈现。
- 第二个提示为卡通风格的 3D 动画泰迪熊在时代广场打鼓,强调充满活力的城市氛围、动态镜头运动和高细节动画。
- 第三个提示描述卡梅尔海岸的宁静景观,以真实细节渲染,自然光照、广角构图及环境运动(如轻柔海浪与微风)。
- 第四个提示展示小丑鱼在珊瑚礁中游动,以广角水下视角拍摄,自然光线穿透水面,突出生物多样性和流体运动。
- 未显式构建或引用外部数据集;所有内容均由这些手工设计的提示生成。
- 作者未提及训练划分、混合比例或裁剪策略——提示仅作为视觉生成的独立创意规范,而非训练数据。
- 除提示规范外,未描述元数据或处理步骤;重点在于视觉输出保真度和风格控制。
方法
作者在扩散模型中采用结构化稀疏注意力方法,结合架构创新与定制训练目标,实现高稀疏度而不牺牲生成质量。其方法核心 SparseAttention2 包含两个关键组件:用于精确稀疏度控制的混合掩码策略,以及用于保留生成行为的基于蒸馏的微调协议。
在架构层面,SparseAttention2 采用块稀疏注意力范式,使稀疏模式与 GPU 友好的分块对齐,从而实现实际加速。注意力计算始于标准查询、键和值矩阵 Q,K,V∈RN×d,从中推导出得分矩阵 S=QK⊤/d。SparseAttention2 不计算完整注意力矩阵,而是应用二值掩码 M∈{0,1}N×N 仅保留部分注意力权重,将计算成本从 O(N2d) 降至稀疏等效值。为确保硬件效率,掩码在块级别应用:张量被划分为块 Qi,Kj,Vj,每对块 (i,j) 根据块级掩码 Mij 完全保留或丢弃。此块级门控允许内核跳过被掩码块的整个矩阵乘法和 softmax 运算,形式化为 Mij[:,:]=0⇒skip QiKj⊤ and PijVj。
为确定保留哪些块,作者引入混合 Top-k 和 Top-p 掩码策略。不同于单独依赖任一方法——在均匀或偏斜注意力分布下可能失效——混合方法通过对每块内查询和键进行平均池化,计算池化注意力图 Pˉ∈RN/bq×N/bkv。若块 (i,j) 被 Top-k(保留每行前 k% 权重)或 Top-p(保留累积概率达 p% 的最小块集)选中,则掩码 Mˉij 设为 1。形式上,Mˉij=1 当且仅当 j∈Top-k(Pˉi,:,k%)∪Top-p(Pˉi,:,p%)。此双重标准确保在多样注意力模式下稳健,避免固定计数或固定阈值掩码的缺陷。
为模型适配,作者用速度蒸馏损失替代标准扩散损失,以缓解微调期间的行为漂移。在师生设置中,原始全注意力模型冻结为教师,稀疏注意力模型作为学生。两者接收相同输入:带噪潜变量 xt=tx1+(1−t)x0、时间步 t 和文本提示 ctxt。学生被训练以匹配教师预测的速度场 ufull(xt,ctxt,t),最小化均方误差 LVD=E[∥usparse−ufull∥2]。此蒸馏目标直接对齐两模型的采样动力学,避免使用标准扩散损失微调时因分布不匹配导致的问题。微调数据仅用于构建 xt;不从真实速度 vt=x1−x0 获取监督。
SparseAttention2 的实现基于 FlashAttention,配备自定义 CUDA 内核,在前向与反向传播中高效跳过掩码计算。适配过程包括将预训练扩散模型中所有注意力层替换为 SparseAttention2,并在速度蒸馏损失下微调学生模型。此端到端流程实现 95% 注意力稀疏度,带来 16.2 倍注意力计算加速和 4.7 倍端到端生成加速,同时保持视频生成质量。
实验
- Top-k 和 Top-p 掩码策略在不同注意力权重分布下表现不同:Top-p 在均匀分布下优于 Top-k,而 Top-k 在偏斜分布下更优;二者结合可平衡两种情况。
- 使用稀疏注意力微调导致注意力分布更集中,在固定稀疏度下通过降低丢弃和重归一化项减少稀疏注意力误差。
- 无论注意力类型如何,标准扩散损失微调均会降低模型性能,主要因微调数据与预训练数据不匹配,而非稀疏度本身。
- SpargeAttention2 在高稀疏度(85%–95%)下实现最先进的生成质量,同时带来显著效率增益,在速度和稳定性上优于先前方法。
- 消融实验确认 SpargeAttention2 的混合 Top-k+Top-p 掩码器、可训练适配和速度蒸馏损失在高稀疏度下对其成功至关重要。
- SpargeAttention2 实现最高达 16.2 倍注意力延迟加速和 4.7 倍端到端生成加速,同时保持质量,并在定性上明显优于基线。
结果显示,稀疏注意力微调后,注意力分布更集中,导致比微调前更高的稀疏度和更低的 L1 误差。这表明微调通过减少丢弃和重归一化误差,改善了稀疏与全注意力输出的对齐。
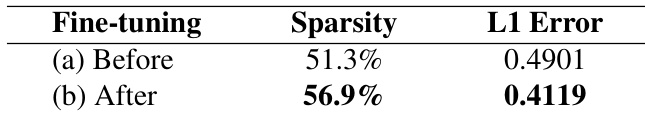
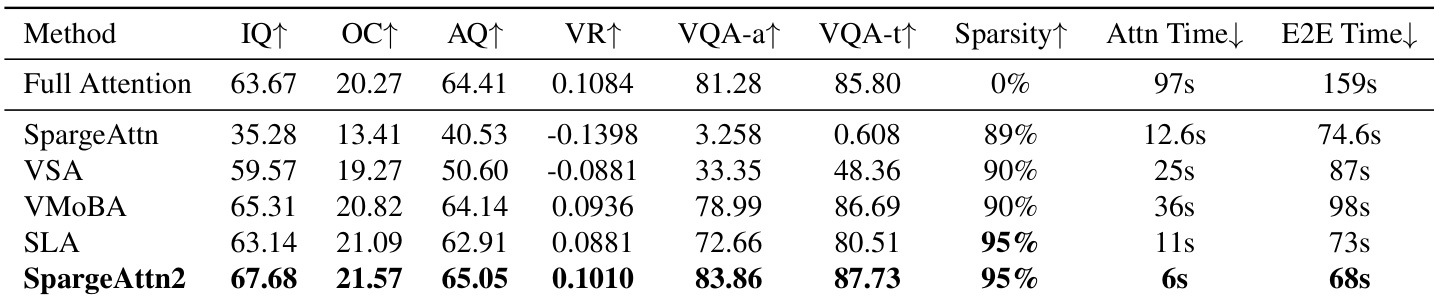
作者在高稀疏度下将 SpargeAttention2 与先前稀疏注意力方法对比,显示其在保持 95% 注意力稀疏度的同时实现最高的生成质量指标。它还提供最快的注意力延迟和端到端生成时间,在效率和输出保真度上优于基线。结果证实 SpargeAttention2 的混合掩码和训练设计使其在其他方法退化时仍保持稳健性能。
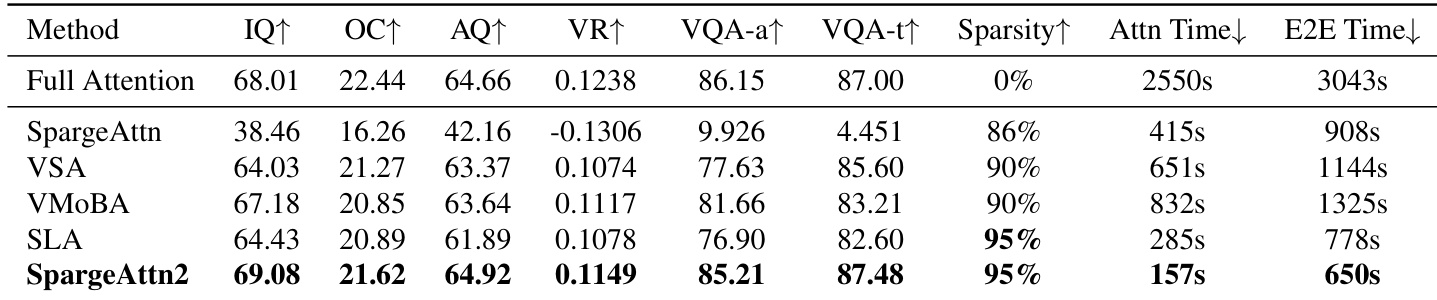
作者在高稀疏度下评估 SpargeAttention2 与先前稀疏注意力方法,显示其在保持 95% 注意力稀疏度的同时,实现最高的生成质量指标,并将注意力延迟最高降低 16.2 倍,端到端时间最高降低 4.7 倍。结果表明,即使在 95% 稀疏度下,SpargeAttention2 仍保持或超越全注意力性能,在效率和输出质量上优于基线。混合 Top-k+Top-p 掩码和速度蒸馏训练策略促成了其在不同模型规模下的稳健性和有效性。
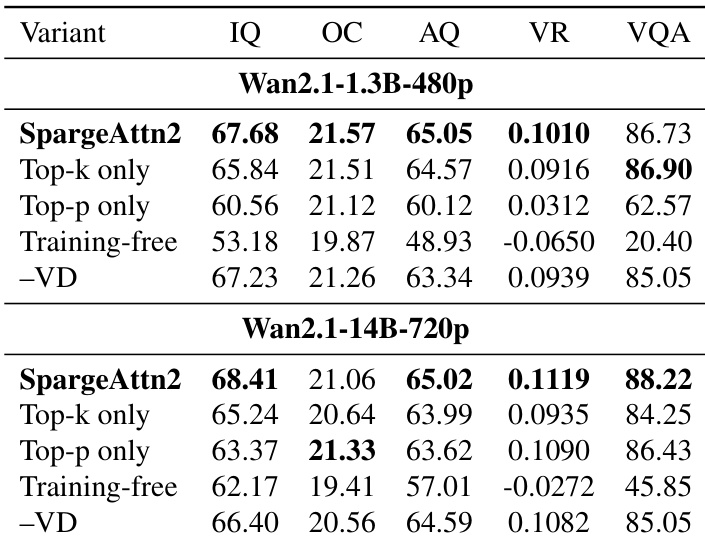
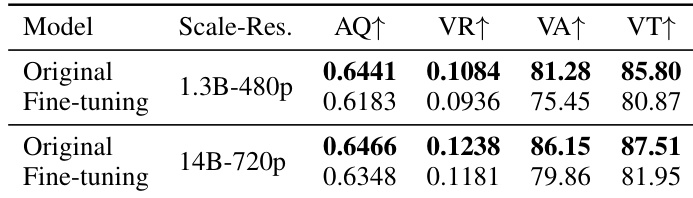
作者在扩散损失下评估两种模型规模的微调效果,观察到美学质量、视觉奖励和 VQA 准确率一致下降,相比原始预训练模型。即使在全注意力下也出现此退化,表明问题源于数据集不匹配而非注意力稀疏度。结果强调,当微调数据偏离预训练数据质量时,需采用替代训练目标。
作者将 SpargeAttention2 与消融变体对比,发现结合 Top-k 和 Top-p 掩码与可训练适配在不同模型规模下均获得最佳生成质量和对齐效果。禁用训练或仅使用单一掩码策略会导致显著性能下降,确认两个组件的必要性。用标准扩散损失替代速度蒸馏也会降低有效性,凸显所提训练目标的重要性。