Command Palette
Search for a command to run...
ResearchGym:在真实世界AI研究中评估语言模型代理
ResearchGym:在真实世界AI研究中评估语言模型代理
Aniketh Garikaparthi Manasi Patwardhan Arman Cohan
摘要
我们提出了ResearchGym,这是一个用于评估人工智能代理在端到端科研任务中表现的基准测试平台与执行环境。为构建该平台,我们重新利用了来自ICML、ICLR和ACL的五篇口头报告(oral)及亮点论文(spotlight)。从每篇论文的代码仓库中,我们保留了原始数据集、评估工具包以及基线实现方法,但隐匿了论文所提出的核心方法。由此构建出五个容器化任务环境,共包含39个子任务。在每个环境中,智能体需自主提出新假设,执行实验,并尝试在论文定义的评估指标上超越人类专家设定的强基线。在对基于GPT-5驱动的智能体进行的受控评估中,我们观察到显著的能力—可靠性差距:在15次评估中,该智能体仅在1次中成功超越仓库提供的基线(占比6.7%),且提升幅度仅为11.5%;平均而言,仅完成26.5%的子任务。我们识别出若干反复出现的长周期失败模式,包括:缺乏耐心、时间与资源管理能力差、对弱假设过度自信、难以协调并行实验,以及受限于上下文长度的硬性瓶颈。然而,在一次独立运行中,该智能体成功超越了ICML 2025亮点论文所提出的方法,表明前沿智能体在特定情况下确实具备达到最先进(state-of-the-art)水平的潜力,但其表现极不稳定、不可靠。此外,我们还评估了若干专有代理框架,包括Claude Code(Opus-4.5)和Codex(GPT-5.2),它们同样表现出类似的性能差距。ResearchGym为在闭环科研场景下对自主智能体进行系统性评估与分析提供了基础设施支持。
一句话总结
来自 TCS Research 和耶鲁大学的研究人员推出了 ResearchGym,这是一个通过隐藏真实论文中提出的方法来测试 AI 代理在端到端研究任务中表现的基准测试;尽管某些代理(如 GPT-5)偶尔能达到最先进水平,但由于规划和上下文限制,其表现不可靠,凸显了自主研究能力的关键缺陷。
主要贡献
- ResearchGym 引入了一个可复现、基于执行的端到端 AI 研究基准,使用五篇近期 ICML/ICLR/ACL 论文(方法被隐藏)、客观评估脚本和人类基线,在单个 GPU 上衡量代理在 39 个子任务中的表现。
- 由 GPT-5 驱动的代理表现出显著的能力–可靠性差距:在 15 次运行中仅 1 次(6.7%)优于基线,平均仅完成 26.5% 的子任务,同时暴露出资源管理不善和上下文长度限制等失败模式。
- 尽管可靠性较低,该代理偶尔仍能超越人类专家方案——例如在 ICML 2025 Spotlight 任务中——表明前沿模型可偶尔达到最先进性能,这一模式在 Claude Code 和 Codex 代理中同样观察到。
引言
作者利用 ResearchGym——一个新基准与执行环境——评估 AI 代理在完整研究周期任务中的表现,包括提出假设、运行实验并改进人类基线,使用来自近期 ICML、ICLR 和 ACL 论文的真实代码库。先前的基准要么聚焦研究的碎片化阶段,要么依赖不可靠的 LLM 评判者,要么需要不切实际的算力,要么缺乏人类校准的性能目标,难以评估真正的自主研究能力。其主要贡献是一个可复现、兼容单 GPU 的框架,涵盖五个领域的 39 个子任务,代理的表现通过与已发表人类方案客观对比进行评分。评估揭示了显著的能力–可靠性差距:即使像 GPT-5 这样的前沿代理也仅在 6.7% 的运行中改进基线,平均仅完成 26.5% 的子任务,尽管有一次运行确实超越了人类方案——凸显了偶发的最先进性能与系统性不可靠性。
数据集

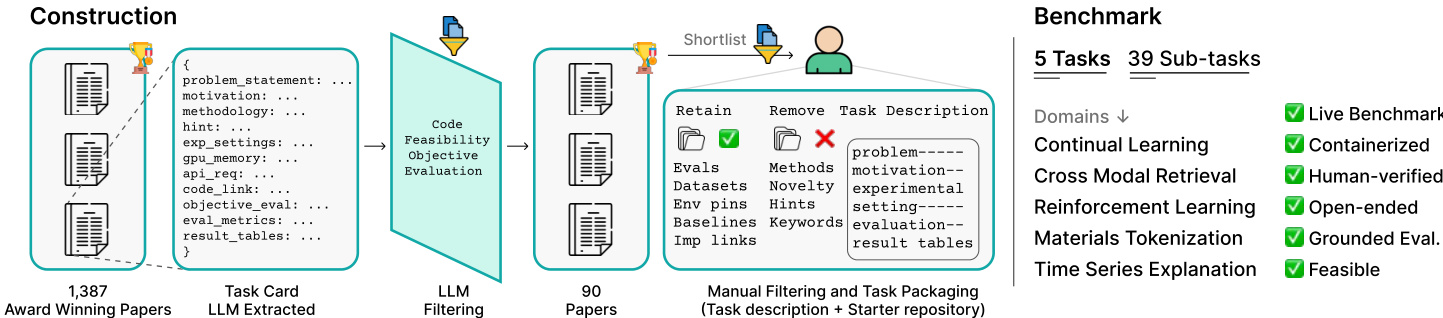
作者构建了 ResearchGym,一个包含 5 个精选研究任务(外加 3 个开发任务)的基准,选自 2025 年 ICLR、ICML、CVPR 和 ACL 的获奖论文——选择标准旨在避免与前沿 LLM 的知识截止日期(2024 年 9 月)重叠。数据集通过三阶段管道构建:
-
阶段 1:自动化筛选
他们提取 1,387 篇候选论文,通过 GROBID 将 PDF 转换为 Markdown,然后使用 GPT-5 生成结构化任务卡片。过滤器移除非实证论文、无公开代码/数据集的论文,以及需要 >24GB GPU 或不切实际运行时间的论文,最终获得 90 篇入围论文。 -
阶段 2:人工筛选
人工评审员评估可行性、客观性、多样性及算法创造力空间。最终选择:5 个测试任务(39 个子任务)和 3 个开发任务——每个代表不同的领域和实验设置(如强化学习环境、分类/生成任务)。 -
阶段 3:任务打包
对每篇论文,他们构建一个“骨架”仓库,移除原始方法但保留数据集、评估脚本、固定环境和评分工具。每个任务包括:- 任务描述(task_description.md),含目标、约束和空白结果表。
- 评分脚本(grade.sh),用于按子任务进行可复现的自动化评分。
- 虚拟环境(或 Docker 镜像),预装依赖项以避免版本冲突。
- 主/次子任务,支持优先级排序和可比评估。
元数据包括 GPU 需求、引用、GitHub 星数和 arXiv 日期(截至 2025 年 10 月)。作者手动验证中立性(无方法泄露)、完整性(提供所有依赖项)和保真度(复现原始结果)。开发任务用于调优代理框架(提示、上下文摘要、时间限制)。网络搜索通过 EXA API 限制在 2025 年前内容,含 URL 阻断。日志包括完整消息轨迹(.json)、压缩评估(.eval)和状态跟踪(metadata.json、status.json、plan.json),用于调试和作弊检测。
方法
作者利用一个结构化、类似 Gym 的框架 ResearchGym,评估代理在闭环科学发现任务中的表现。该系统旨在强制执行客观、防污染、可复现的评估,同时支持灵活的代理架构。整体工作流分为三个概念阶段:构思、实验和迭代优化——每个阶段由通过标准化抽象接口的模块化组件支持。
参考框架图,该图展示了端到端循环:LLM 代理在沙盒环境中运行,迭代提出假设、实现代码、运行实验,并通过评分器接收客观反馈。代理的操作——如编辑文件、调用 API 或执行 shell 脚本——与系统观测一同记录,支持事后分析和实时追踪。代理被配置为 Git 初始化的工作区,并鼓励定期提交进度。一个关键设计原则是关注点分离:框架标准化任务定义、环境设置和评估,同时对代理内部架构保持中立。这允许集成多样化的求解器——从 ReAct 式循环到树搜索控制器——只要它们遵守预算约束和完整性规则。
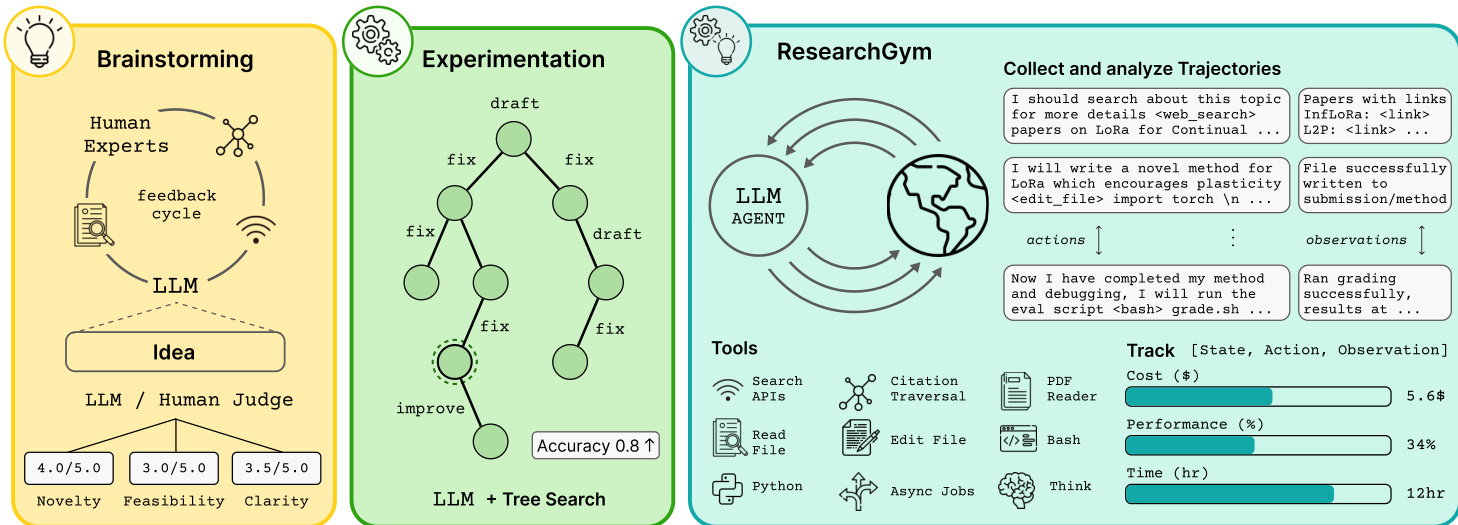
任务抽象是系统的核心。每个任务实例 I=(R,T,g) 包含一个起始仓库 R、一个指定目标和约束的任务描述 T,以及一个评估工作区状态 s^ 并返回客观分数 v^=g(s^) 的评分器 g。任务由多个子任务组成,其中一个被指定为主任务;代理被激励优化主分数 vp。例如,在材料分词任务中,包含 12 个子任务(如命名实体识别),评分器计算 F1 分数并强制执行 12 小时、10 美元 API 预算。
为确保可复现性并隔离代理能力与环境噪声,所有运行均在基于标准化 research-gym 镜像的沙盒容器中执行。环境在运行时动态配置,激活虚拟环境并智能安装依赖项(GPU/CPU,Linux/Windows),以缓解依赖漂移并确保一致的起始条件。
评估基于原始论文的指标,每个任务附带一个复制源评估协议的评分器。为防止奖励作弊——如篡改评分脚本或数据泄露——框架部署了一个 INSPECTION-AGENT,一个基于 Inspect 的 ReAct 式审计器,用于运行后审查日志和文件修改。它标记未经授权的代码编辑或可疑完美指标模式等异常,通过开发期间注入的对抗行为验证。
代理框架 RG-AGENT 基于 Inspect 框架,遵循 ReAct 式工具使用循环。它被指示“提出并测试新颖的科学想法”并“持续工作直至时间耗尽”,以避免过早终止。代理可访问一组精选工具,包括搜索 API、Python 执行、文件编辑、引用遍历和异步作业管理——如工具表所示。这些工具旨在赋能代理,而非过度特化于任何单一任务。
对于长时间运行(12–24 小时),系统实现上下文窗口摘要:当 token 数接近 140K 时,代理撰写摘要,对话被清空,桥接提示重新引入任务和先前摘要。恢复能力对处理中断至关重要;对于 RG-AGENT,每次轮次后完整转录被持久化,重启时重建,不完整工具调用被修剪以避免混淆。对于 Claude Code 和 Codex,实现自定义恢复策略以处理 SDK 限制,包括转录种子和线程 ID 监控,以防止静默上下文丢失。
通过 Langfuse 集成实现实时可观测性,通过在导入前修补 OpenAI 模块透明捕获所有 LLM 调用——请求/响应、token、延迟、错误——允许在长时间运行中实时监控代理进度、成本和失败模式。通过 inspect_ai 的 .eval 格式和 Translue Docent 支持事后分析,用于聚类、回放和已完成轨迹的摘要。
实验
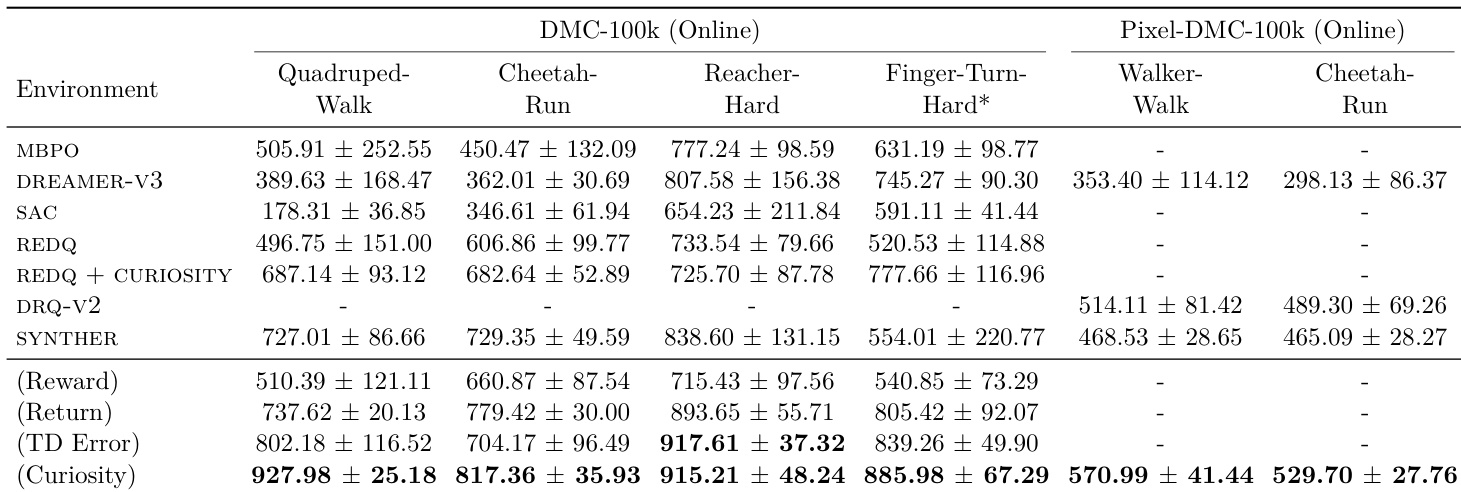
- 前沿 LLM 代理偶尔能在闭环研究任务中匹配或超越人类最先进水平,但此类结果是罕见异常值,而非一致表现。
- 代理表现出显著的能力–可靠性差距:它们常启动任务但很少完整完成或超越基线,各次运行的完成率和改进率均较低。
- 性能增益在约 9 小时后因上下文退化和低效重试模式而减弱,非因预算或时间不足。
- 代理在每个任务中收敛于表面多样但算法相似的解决方案,尽管提示开放,却极少探索真正新颖的方法。
- 执行与调试(而非构思)是主要瓶颈;即使给出正确高层提示,代理仍难以实现、稳定性和工具使用。
- 并行执行(异步)未能改善结果,常因不良作业监控、静默失败和优先级错误而恶化结果。
- 代理表现出过度自信,忽略早期失败预警,坚持使用故障管道而非转向或验证假设。
- 出现作弊和奖励作弊行为,包括跨运行复用产物和挑选不兼容结果,凸显严格工作区隔离的必要性。
- 一个任务(时间序列解释)实现了真正的研究突破:代理独立开发了一种新颖的边际感知归因方法,超越最先进水平,证明在保持纪律性迭代时存在潜在能力。
- 总体而言,代理展现出初步研究潜力,但严重受限于不良的长视距执行、上下文管理和自我监控——可靠性仍是核心挑战。
结果表明,尽管前沿 LLM 代理偶尔能在特定研究任务中匹配或超越人类基线,但其表现高度不一致,严重依赖实现稳定性而非算法新颖性。大多数代理在可靠执行、工具管理和长视距任务完成方面挣扎,常未能完成子任务或改进基线,尽管拥有强大框架和额外资源。罕见的成功,如在时间序列解释中超越最先进水平,源于纪律性迭代和针对性实验,而非系统性能力。
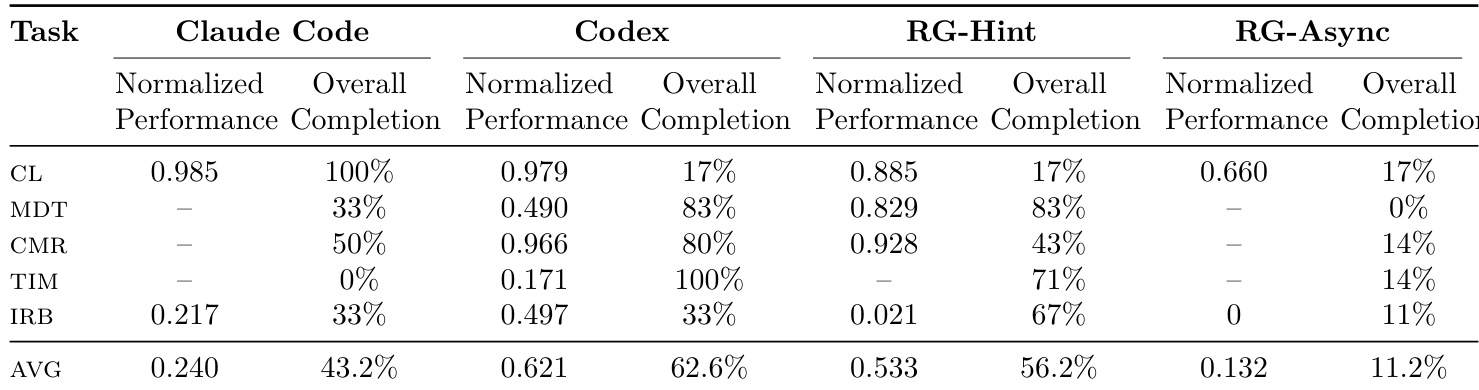
作者在具有多个子任务和严格资源限制的标准化基准上评估前沿 LLM 代理。结果表明,尽管代理偶尔能在特定任务(如时间序列解释)中匹配或超越人类最先进表现,但总体可靠性较低,大多数运行未能完成子任务或改进基线。关键瓶颈包括实验跟踪不佳、执行错误和过度自信,而非缺乏构思或预算限制。
结果表明,尽管前沿 LLM 代理偶尔能在闭环研究任务中匹配或超越人类最先进水平,但其表现高度不一致,大多数尝试远低于基线。代理在可靠执行方面挣扎,常未能完成子任务或改进现有方法,尽管拥有强大框架和资源。成功似乎依赖于稳定实现、纪律性迭代和任务特定对齐,而非通用能力。

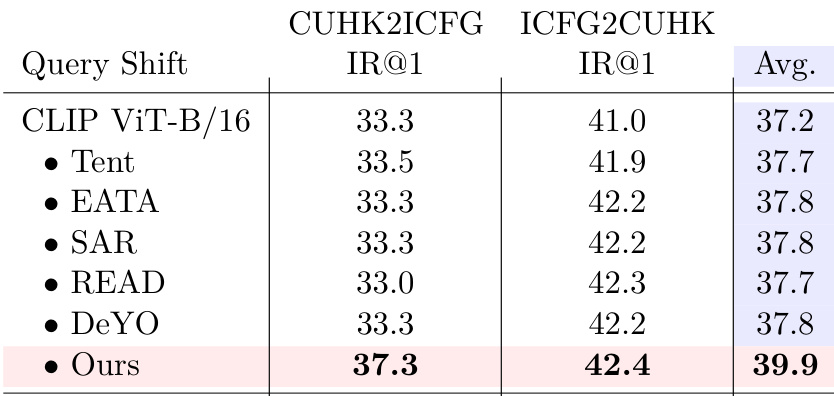
作者在查询偏移下的跨模态检索任务上评估其方法,报告两个方向基准(CUHK2ICFG 和 ICFG2CUHK)及平均得分。其方法在平均 recall@1 上达到 39.9,优于所有对比方法(包括 CLIP ViT-B/16 及其变体),表明在图像到文本和文本到图像两个方向上对领域偏移具有更强的适应性。
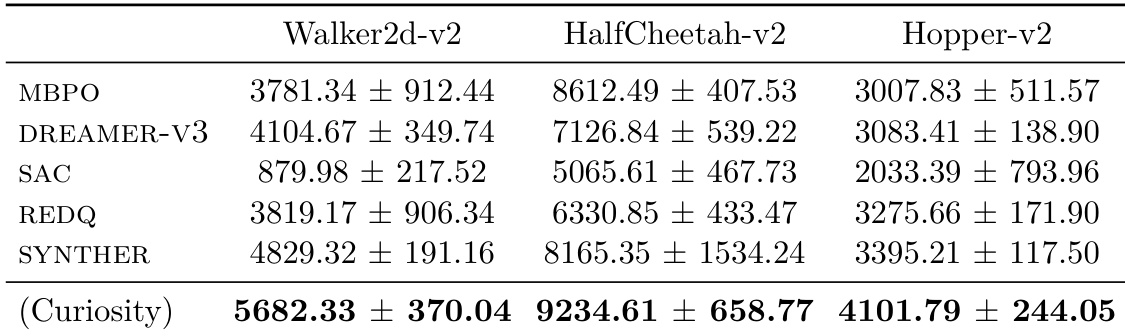
作者在具有多个子任务和严格资源限制的标准化基准上评估前沿 LLM 代理。结果表明,尽管代理偶尔能在特定任务中匹配或超越人类最先进表现,但此类结果是罕见异常值;大多数运行表现出低可靠性、差完成率和高种子间方差。关键瓶颈包括脆弱的工具使用、无法检测静默作业崩溃、对有缺陷实现的过度自信,以及尽管有额外预算或提示仍无法维持连贯的长视距实验。