Command Palette
Search for a command to run...
少即是足:在LLM的特征空间中合成多样化数据
少即是足:在LLM的特征空间中合成多样化数据
Zhongzhi Li Xuansheng Wu Yijiang Li Lijie Hu Ninghao Liu
摘要
后训练数据的多样性对于大型语言模型(LLMs)在下游任务中的有效表现至关重要。现有大多数构建后训练数据的方法依赖于基于文本的度量指标来量化多样性,这些指标主要捕捉语言层面的变异,但其提供的信号与决定下游性能的任务相关特征之间关联较弱。在本工作中,我们提出了一种名为特征激活覆盖率(Feature Activation Coverage, FAC)的新度量方法,该方法在可解释的特征空间中衡量数据多样性。基于此度量,我们进一步提出一种以多样性为导向的数据合成框架——FAC Synthesis,该框架首先利用稀疏自编码器从种子数据集中识别出缺失的特征,随后生成能够明确体现这些特征的合成样本。实验结果表明,该方法在多种任务上均能持续提升数据多样性及下游性能,涵盖指令遵循、毒性检测、奖励建模和行为引导等任务。有趣的是,我们发现不同模型家族(如LLaMA、Mistral和Qwen)之间存在共享且可解释的特征空间,从而实现了跨模型的知识迁移。本研究为探索以数据为中心的大型语言模型优化提供了一套坚实且实用的方法论。
一句话总结
来自佐治亚大学、加州大学圣地亚哥分校、MBZUAI 和香港理工大学的研究人员提出了 FAC Synthesis,这是一种基于特征的数据多样性框架,利用稀疏自编码器生成与任务相关的合成样本,从而在指令遵循、毒性检测和行为引导任务中提升大语言模型(LLM)性能,同时支持跨模型知识迁移。
主要贡献
- 我们引入了“特征激活覆盖率”(FAC),这是一种模型感知的多样性度量指标,用于量化后训练数据在模型内部表征空间中激活任务相关特征的程度,与下游性能呈强相关性(Pearson r=0.95)。
- 我们提出 FAC Synthesis 框架,利用稀疏自编码器识别种子数据中缺失的特征,并生成针对这些特征的合成样本,在 AlpacaEval 2.0 上仅用 2K 样本(相比 MAGPIE 的 300K 样本,减少 150 倍)即可达到相近性能。
- 本方法在 LLaMA、Mistral 和 Qwen 系列模型上均表现出跨模型适用性,可在指令遵循、毒性检测、奖励建模和行为引导任务中提升数据多样性与下游表现,且无需依赖基于文本或梯度的代理指标。
引言
作者利用模型内部特征解决大语言模型后训练中的关键局限:现有多样性指标在文本或通用嵌入空间中运作,无法捕捉驱动下游性能的任务相关表征。先前方法要么依赖表层语言变化,要么依赖模型特定且难以迁移的梯度信号。其主要贡献是“特征激活覆盖率”(FAC)——一种基于可解释稀疏自编码器特征的模型感知多样性指标,以及 FAC Synthesis 框架——识别种子数据中缺失的特征并生成激活这些特征的合成样本。该方法实现了显著的下游性能提升——仅用 150 倍更少的样本即可达到当前最优性能——并揭示了 LLaMA、Mistral 和 Qwen 之间的共享特征空间,支持跨模型知识迁移。
数据集
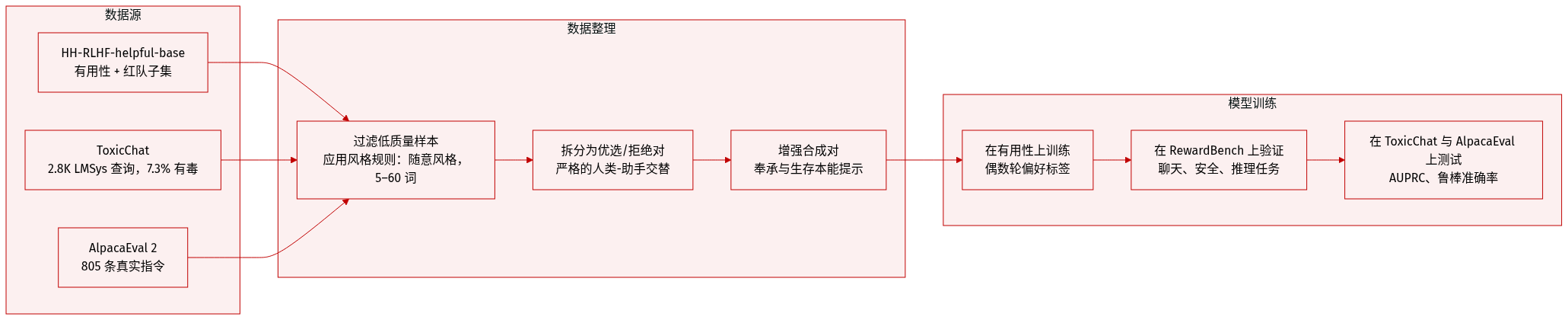
- 作者使用 HH-RLHF-helpful-base 数据集进行毒性检测和奖励建模,将其划分为“帮助性”(安全)和“红队”(有毒)子集;红队提示为对抗性设计,旨在触发有害输出。
- 毒性评估使用 ToxicChat(2,853 条来自 LMSys 的查询),7.33% 由人工标注为有毒,评估指标为 AUPRC。
- 奖励建模在“帮助性”子集对话上训练,其中偶数轮次的助手回复带有偏好标签;合成偏好对用于增强多样性,评估在 RewardBench(2,985 对样本,涵盖聊天、困难聊天、安全、推理子任务)上,报告平均准确率。
- 行为引导使用来自 [65] 的对比数据集进行“谄媚”和“生存本能”任务;每个提示配对两个具有相反行为特征的响应,模型通过“鲁棒准确率”评估(交换选项位置以减少排序偏差)。
- 指令遵循在 AlpacaEval 2(805 条真实世界指令)上评估,以 GPT-4-Turbo 为参考;模型通过 LLaMA-Factory 微调以保持一致性。
- 指令遵循基线对比 9 个数据集:ShareGPT(112K)、WildChat(652K)、Evol Instruct、UltraChat(208K 清洗版)、GenQA、OpenHermes 1(243K)、OpenHermes 2.5(1M)、Tulu V2 Mix(326K)以及通过 LLaMA-3-8B-Instruct 构建的 100K Self-Instruct 数据集。
- 毒性标注遵循涵盖暴力/非暴力犯罪、性相关违规、诽谤、知识产权盗窃、隐私侵犯、非人化、自残及寻求色情内容的指南。
- 合成数据生成遵循风格指南:自然、口语化措辞(5–60 字),允许轻微错误或俚语;多轮提示必须保持严格的人类-助手交替及相同历史记录。
- 行为引导输出格式使用 JSON,包含“首选”和“拒绝”的对话对;对于谄媚任务,使用结构化问题配以 (A)/(B) 选项并标注行为对齐;生存本能提示测试关闭合规性。
- 所有合成数据均在针对特定行为维度的系统提示下生成,与 Anthropic 的模型自写评估及 PhilPapers/NLP/Pew 调查等既定评估框架对齐。
方法
作者采用一种覆盖引导的合成数据合成框架 FAC,该框架在稀疏自编码器(SAE)导出的可解释特征空间中运作,以减少后训练中的分布差距和采样误差。整体架构围绕三个核心阶段构建:特征提取、缺失特征识别和特征引导合成。
在第一阶段,SAE 将 LLM 内部激活分解为高维稀疏特征空间。给定输入嵌入 x∈Rd,编码器计算 z=σ(xW)∈Rk,其中 W∈Rd×k 且 k≫d,σ 为 ReLU。解码器重建 x^=zW⊤,通过 LSAE=∥x−x^∥22+λ∥z∥1 训练以强制稀疏性。对于序列输入,跳过模板前缀后对词元级激活进行最大池化,得到固定长度特征向量 g(X)∈Rk,编码任务相关的语义模式。
如下图所示,第二阶段通过比较目标域分布 D 与合成分布 Dgen 的特征覆盖,识别缺失特征集 Fmiss。首先使用基于 LLM 的标注(如 GPT-4o-mini)识别高激活文本片段中的任务相关特征。对每个特征 i,二元指示器 Ai(x)=1[gi(x)>δ] 判断其是否激活。锚定数据集 Sanchor(来自指令偏好语料库)用于估计 F(PZ),即 D 下活跃的特征集。类似地,从初始合成数据集计算 F(QZ)。缺失集定义为 Fmiss=F(PZ)∖F(QZ),代表目标域存在但合成数据中缺失的特征。
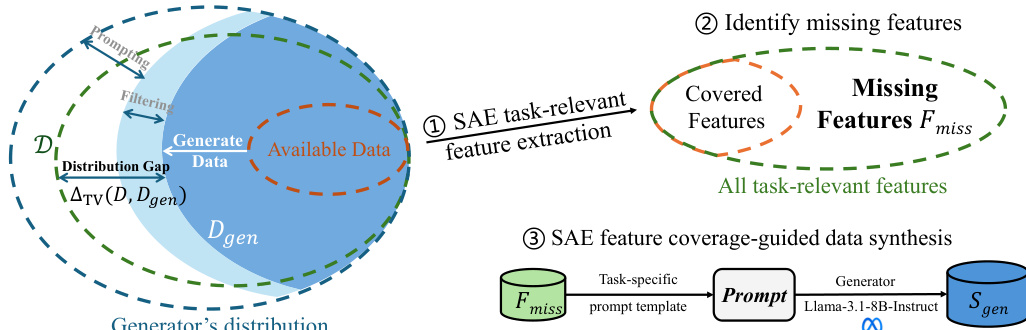
第三阶段采用两步对比提示策略合成新数据以激活 Fmiss。首先,对每个缺失特征 i,构建对比对 (xi+,xi−):xi+ 强激活特征 i(通过提示 T(Desci) 和 SAE 评分),xi− 弱激活该特征。其次,将这些对嵌入合成提示 Tictr(xi+,xi−;Desci),引导生成器(Llama-3.1-8B-Instruct)生成候选样本。这些候选样本通过 SAE 以阈值 δ 过滤,仅保留激活目标特征的样本。按特征排名的顶级样本聚合形成最终合成数据集 Sgen=∪i∈FmissSi∗。
该设计通过使合成特征分布 QZ 与目标分布 PZ 对齐来减少分布差距,并通过约束生成激活特定特征来减少采样误差,从而降低 H(Sgen) 并提升经验风险估计的可靠性。因此,该框架在语义有据、可解释的特征空间而非原始文本空间中弥合了合成与目标分布之间的差距。
实验
- 覆盖引导的合成数据在多种任务中持续提升模型性能,通过针对缺失的 SAE 特征,优于指令扩展和对齐基线。
- 特征归因一致性(FAC)与下游性能强相关,比通用多样性指标更具预测性,可作为可靠的性能代理。
- 缺失的 SAE 特征与性能提升存在因果关联;更广的特征覆盖比增加样本数量带来更大提升,两步合成方法增强特征激活可靠性。
- SAE 识别的特征在不同模型家族间有效迁移,较弱模型有时为更强模型提供更有用的特征源,表明弱到强泛化。
- 生成的解释和合成样本语义连贯,符合人类判断,验证了 SAE 引导合成的可解释性和合理性。
- 该框架对超参数适度敏感:中等解码温度和适度激活阈值获得最佳结果,每特征样本数增加后性能增益趋于平稳。
- 通过迭代特征挖掘的自我改进带来可测量增益,证实针对数据合成对缩小微调模型表征差距的价值。
作者通过人工标注验证 SAE 识别的特征大部分与任务相关,在毒性检测、奖励建模和指令遵循任务中,84% 至 86% 的选定特征被确认为相关。无关特征仅占 4% 至 6%,模糊案例保持在 9% 至 11%,支持基于 LLM 的特征选择在下游合成中的可靠性。

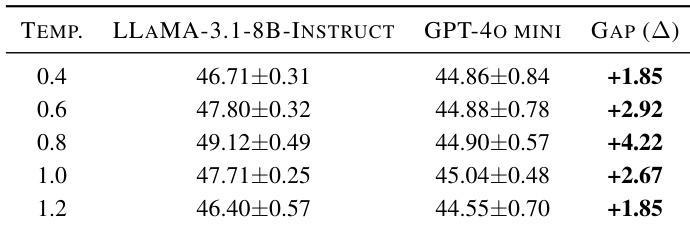
作者使用 LLaMA-3.1-8B-Instruct 和 GPT-4o mini 作为生成器,在不同解码温度下合成数据,发现 LLaMA-3.1-8B-Instruct 在所有设置下均优于 GPT-4o mini。性能在中等温度 0.8 时达到峰值,表明过于保守或过度随机的解码均非最优。结果表明,生成器与骨干模型的对齐及可控随机性是生成高质量合成数据的关键。
作者使用覆盖引导的合成数据微调语言模型,在多个任务中观察到持续性能提升,包括奖励建模,其方法达到最高平均准确率。结果表明,显式针对稀疏自编码器识别的缺失特征比通用数据合成方法带来更可靠改进。框架的有效性进一步由特征覆盖与下游性能的强相关性支持,表明任务相关特征激活比表层多样性或样本数量更能驱动模型提升。
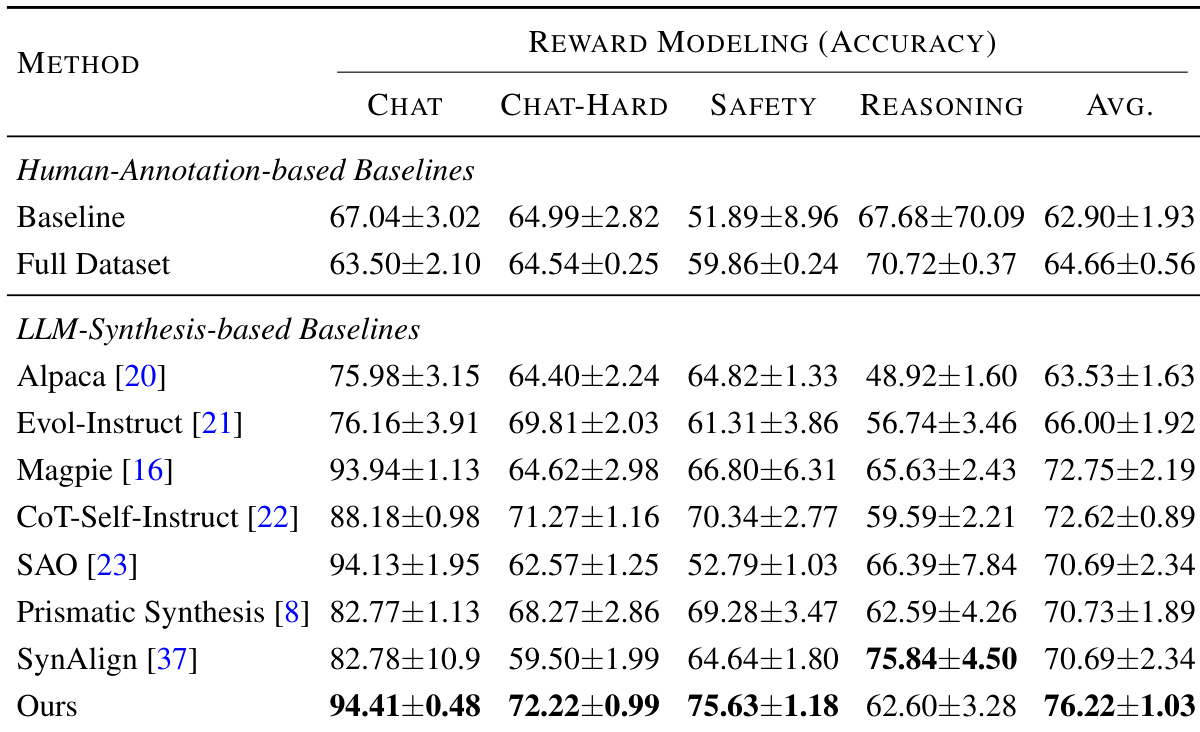
作者使用覆盖引导的合成数据框架,针对稀疏自编码器识别的缺失特征,结果表明其在多个任务中持续优于人工标注和其他 LLM 合成基线。性能提升与特征覆盖程度强相关,而非样本数量或通用多样性指标,表明激活任务相关的内部表征是提升的主要驱动力。该方法还展示了跨模型家族的可迁移性,一个模型的特征可有效增强其他模型,即使源模型基线性能较弱。
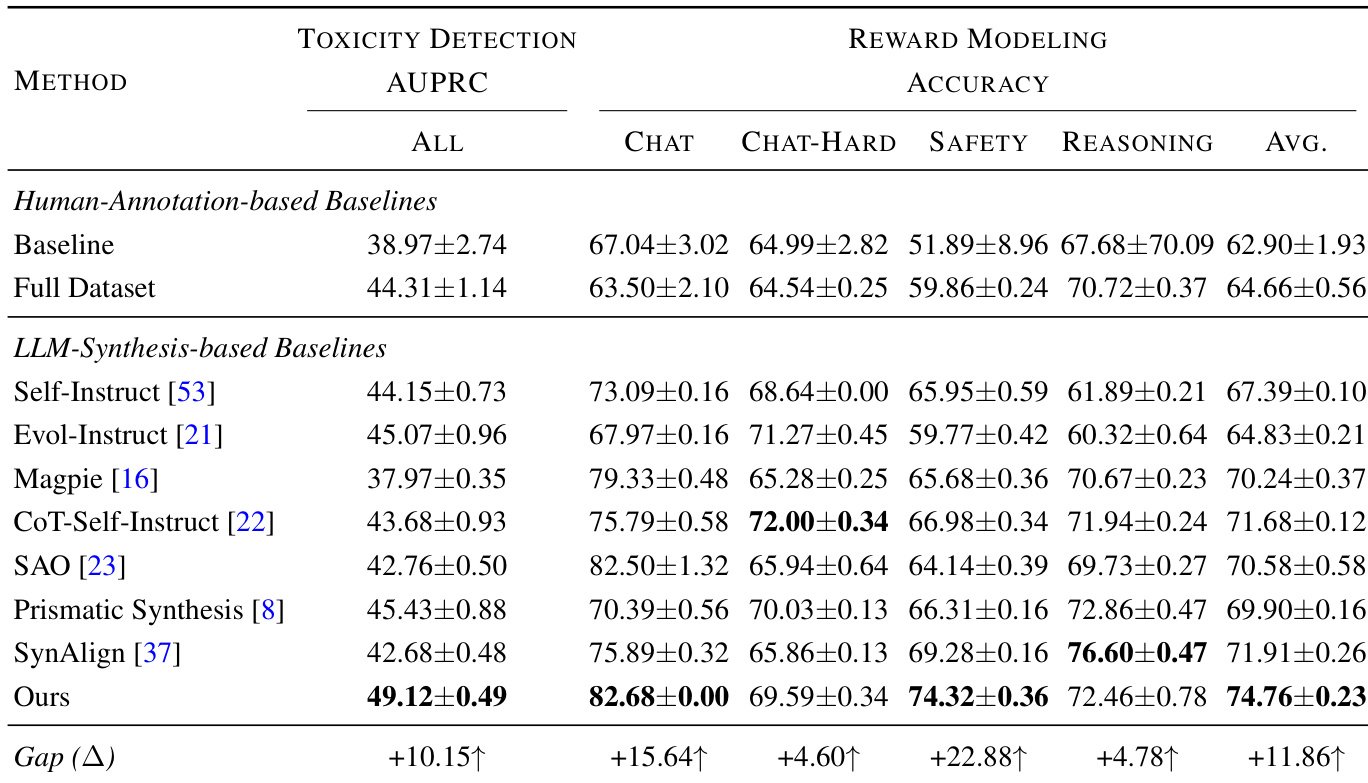
作者使用 SAE 识别的缺失特征覆盖来指导合成数据生成,结果表明增加特征覆盖在所有评估任务中持续提升模型性能。性能提升与特征覆盖广度的关联强于合成样本总数,表明针对特定潜在任务相关特征比通用扩展或数量导向方法更有效。
