Command Palette
Search for a command to run...
GLM-5:从Vibe Coding到Agentic Engineering
GLM-5:从Vibe Coding到Agentic Engineering
摘要
我们提出 GLM-5,这是一个下一代基础模型,旨在推动“氛围编程”(vibe coding)范式向自主工程(agentic engineering)的演进。在继承前代模型 GLM-5 所具备的自主性、推理与编程(ARC)能力的基础上,GLM-5 采用动态稀疏架构(DSA, Dynamic Sparse Architecture),在显著降低训练与推理成本的同时,有效保持了长上下文处理的准确性与一致性。为提升模型对齐性与自主性,我们构建了一套全新的异步强化学习(asynchronous reinforcement learning)基础设施,通过解耦生成过程与训练过程,大幅提升了后训练阶段的效率。此外,我们提出了一类新型的异步智能体强化学习算法,进一步优化了强化学习的质量,使模型能够更高效地从复杂且长周期的交互中学习。得益于上述创新,GLM-5 在多个主流开源基准测试中均达到当前最先进水平。尤为重要的是,GLM-5 在真实世界编码任务中展现出前所未有的能力,显著超越以往基线模型,在端到端软件工程挑战中表现出卓越的综合解决能力。代码、模型及相关信息详见:https://github.com/zai-org/GLM-5。
一句话总结
由智谱AI与清华大学联合开发的GLM-5,通过DSA与异步强化学习推进“智能体工程”,在降低训练成本的同时,在长上下文编程任务中表现卓越,并在真实软件基准测试中超越顶级模型,标志着自主、推理驱动型AI发展的重大飞跃。
主要贡献
- GLM-5引入了一种新型基础模型,从“感觉式编程”转向“智能体工程”,借助DSA降低训练与推理成本,同时保持长上下文性能,继承并扩展了前代模型的ARC能力。
- 部署了异步强化学习基础设施与新颖的智能体RL算法,解耦生成与训练过程,提升从复杂长程交互中学习的能力,增强后训练效率与对齐效果。
- GLM-5在8项主要智能体、推理与编程基准测试中取得当前最优成绩,在真实端到端软件工程任务中超越先前模型,开源代码与模型供社区使用。
引言
作者利用GLM-5从“感觉式编程”——即模型仅模仿模式而无深层推理——转向“智能体工程”,实现自主端到端软件开发。先前模型在强化学习中面临高计算成本与有限长程推理能力,常在真实编码工作流中难以高效扩展。GLM-5引入DSA以实现低成本训练与推理,并采用异步RL基础设施解耦生成与训练,从而更好地从复杂多步交互中学习。结果是在智能体与编程基准测试中达到当前最优性能,具备媲美顶级专有模型的真实工程能力——同时开源以加速社区驱动的高效自主AI智能体发展。
数据集
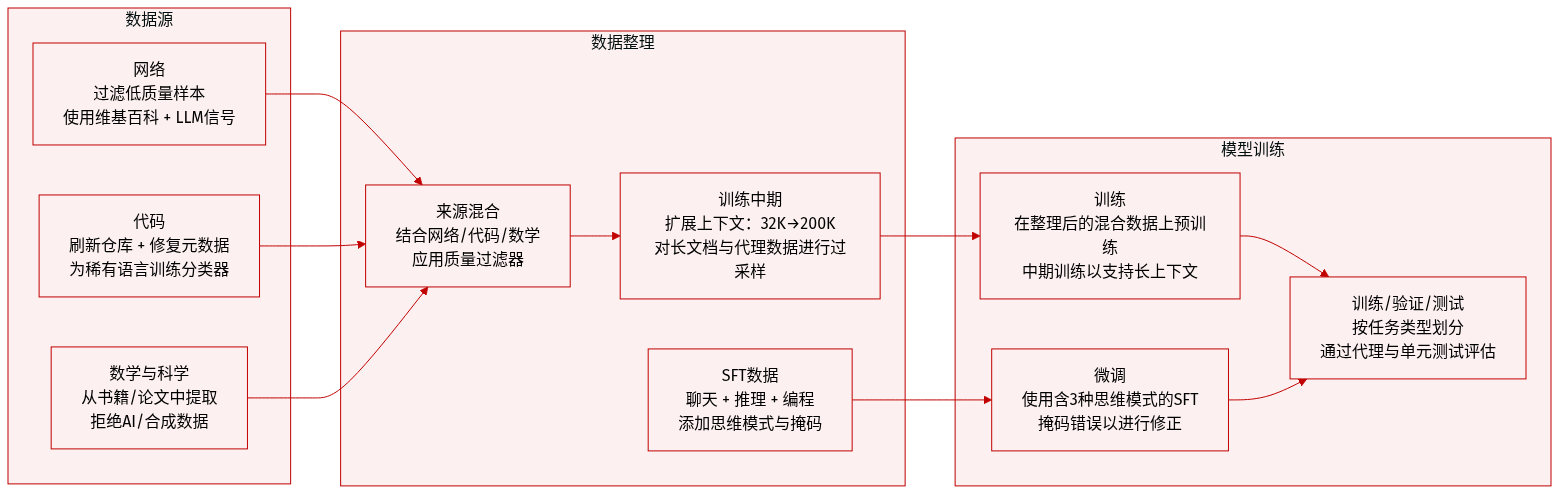
作者使用多阶段高度精选的数据集训练与评估GLM-5,预训练、中段训练与监督微调阶段采用不同构成与处理流程。
-
预训练数据:
- 网络数据:基于GLM-4.5流程构建,增强DCLM分类器进行句子级质量过滤,以及世界知识分类器利用维基百科与LLM标注信号提取中低质量数据价值。
- 代码数据:新增代码托管平台与富含代码网页快照,提升唯一词元数28%。修复元数据对齐与语言分类。为低资源语言(如Scala、Swift、Lua等)训练专用分类器以提升采样效果。
- 数学与科学数据:来源于网页、书籍与论文。增强提取流程与LLM评分筛选教育内容。长文档采用分块聚合评分。严格排除合成、AI生成或模板化数据。
-
中段训练数据:
- 扩展上下文:三阶段:32K(1T词元)、128K(500B词元)、200K(50B词元)。后期阶段上采样长文档与合成智能体轨迹。
- 软件工程:保留仓库级拼接(代码、差异、问题、PR、源文件)。仓库级过滤放宽但问题级收紧,过滤后获得约1000万问题-PR对与约1600亿词元。
- 长上下文数据:混合自然(书籍、论文,按PPL、去重、长度筛选)与合成数据。合成数据使用交错打包与MRCR类似变体强化多轮对话中的回忆能力。逐步提升多样性以增强长上下文性能。
-
监督微调(SFT)数据:
- 覆盖三类:通用对话(问答、写作、角色扮演、翻译、多轮)、推理(数学、科学、逻辑)、编程与智能体(前后端代码、工具调用、智能体)。
- 上下文扩展至202,752词元。支持三种思维模式:交错式(每轮响应前思考)、保留式(跨轮次保留推理)、轮次级(按轮控制推理)。
- 通用对话:优化逻辑与简洁性;角色扮演数据扩展至多语言与多配置,经人工与自动化筛选。
- 推理:通过拒绝采样合成可验证问题;数学/科学问题按难度筛选(对GLM-4.7具挑战性)。
- 编程与智能体:使用真实执行环境。轨迹包含掩码错误以教授错误纠正。增强专家RL与拒绝采样。
-
智能体环境构建:
- 软件工程:通过RepoLaunch构建超1万个可验证环境,覆盖9种语言。使用LLM解析测试日志并提取F2P/P2P案例。
- 终端环境:通过两条管线构建:种子任务(LLM头脑风暴→Harbor实例化→精炼智能体)与网络语料(质量筛选网页→LLM构建并自验证Harbor格式任务)。
- 搜索任务:基于200万+网页构建。LLM构建网络知识图谱,生成多跳问答,并经三阶段过滤:移除易答问题,过滤基础智能体可解问题,双向验证答案一致性。
-
评估基准:
- 前端:CC-Bench-V2使用Agent-as-a-Judge(Playwright + bash)模拟用户交互。指标:BSR(构建成功)、ISR(任务完成)、CSR(检查项通过率)。覆盖7种场景与3种技术栈共220项任务。
- 后端:6种语言共85项真实任务。通过Docker化单元测试评估;要求Pass@1。
- 长程:测试多步PR链中的上下文保持能力,通过单元测试+Agent-as-a-Judge评估。
- 翻译:ZMultiTransBench(1220样本,7种语言对)与MENT-SNS(753对)通过GPT-4.1成对比较评估。
- 对话:LMArena(社区Elo评分)与ZMultiDialBench(141个人工评分多语言样本)。
- 指令遵循:IF-Badcase(450个真实用户失败案例)、IF-Bench(客观约束)、MultiChallenge(多轮推理)。
- 世界知识:SimpleQA(英文)与中文SimpleQA(6领域,99子主题)用于事实性评估。
- 工具调用:ToolCall-Badcase(200个精选案例)评估工具选择与参数正确性。
方法
作者采用多阶段训练流水线开发GLM-5,从28.5万亿词元预算的基座模型预训练开始,最终完成针对智能体、推理与人类交互风格的后训练对齐。整体框架分为两大阶段:基座模型构建与后训练精炼,如框架图所示。
在基座模型阶段,训练包括预训练与中段训练。预训练首先让模型接触18万亿词元通用语料,随后是9万亿词元代码与推理语料,均使用4K上下文窗口处理。中段训练则使用1万亿词元长代码与推理数据(32K上下文)及5000亿词元长上下文与智能体数据(128K/200K上下文)。此阶段后,通过200亿词元在200K上下文长度上进行稀疏注意力适配,为高效长上下文推理做准备。
后训练阶段采用渐进式对齐策略。首先进行整体监督微调(SFT)阶段,引入交错式思维模式,如下图所示。随后是专项强化学习(RL)阶段:推理RL,针对数学、科学、编程与工具集成推理;智能体RL,优化软件工程、终端与搜索智能体任务;通用RL,精炼基础正确性、情商与任务特定质量。最终阶段采用策略内跨阶段蒸馏,利用先前阶段的logits与权重恢复并巩固能力,避免退化。
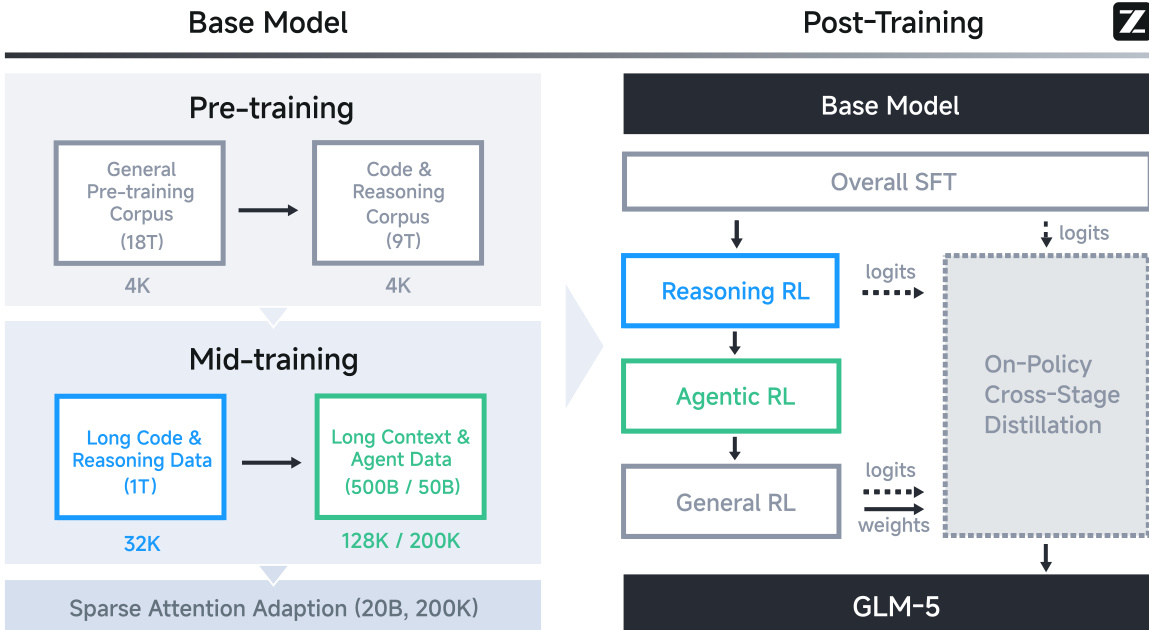
GLM-5架构扩展至256个专家与80层,形成7440亿参数模型,活跃参数400亿。为管理专家并行通信开销,作者采用多隐式注意力(MLA),在长上下文处理中降低键值向量维度以节省内存与提升速度。但MLA初始表现逊于分组查询注意力(GQA-8)。为弥合差距,作者引入Muon Split——一种Muon优化器变体,对每个头的投影矩阵而非全局矩阵应用矩阵正交化,实现头特定更新尺度。此调整结合头维度增至256与头数减少,得到MLA-256变体,在保持GQA-8性能的同时降低解码计算量。
对于多词元预测(MTP),GLM-5在训练中共享三个MTP层参数以保持内存效率,同时提升推理接受率。此设计使模型每步预测两个词元而不增加内存占用,在相同推测步骤下,接受长度优于DeepSeek-V3.2。
后训练基础设施“slime”支持大规模端到端RL。它通过基于服务器的HTTP API支持灵活rollout定制,通过FP8推理与MTP优化尾延迟,并通过心跳驱动容错增强鲁棒性。对于智能体RL,作者实现全异步框架,配备多任务rollout编排器,解耦推理与训练引擎。此设计缓解长程rollout中的GPU空闲,并通过标准化轨迹为统一消息列表格式支持异构任务联合训练。
为稳定异步RL,作者引入Token-in-Token-out(TITO)网关,保持rollout与训练间精确词元级对应,避免重新分词不匹配。同时采用直接双向重要性采样,将词元级重要性比裁剪至[1−εℓ, 1+εh]以控制离策略偏差,无需追踪历史策略。此外,DP感知路由在数据并行下确保KV缓存局部性,通过一致哈希将rollout ID映射至固定DP秩,减少多轮智能体工作负载的预填充开销。
在通用RL阶段,作者将优化分解为三个维度:基础正确性、情商与任务特定质量。混合奖励系统整合基于规则函数、结果奖励模型(ORMs)与生成式奖励模型(GRMs),平衡精度、效率与鲁棒性。人工撰写的响应明确作为风格锚点,引导模型趋向自然、符合人类对齐的输出模式。
对于幻灯片生成,自改进流水线结合监督微调与多级奖励系统引导的强化学习。一级奖励强制有效HTML标记并抑制幻觉图像;二级评估运行时渲染属性如元素几何;三级整合感知特征如空白模式。拒绝采样与掩码精炼进一步提升数据质量与训练效率,实现92%的16:9宽高比合规率,并在内容、布局与美学方面获得显著人工评估提升。
最后,为在中国芯片基础设施上部署GLM-5,作者实现混合精度W4A8量化、高性能融合内核(Lightning Indexer、Sparse Flash Attention、MLAPO)及专用推理引擎优化,包括异步调度、上下文管理与多词元预测。这些协同优化使单节点性能媲美双GPU国际集群,同时将长序列部署成本降低50%。
实验
- DSA训练成功将密集基座模型适配至稀疏注意力,无性能损失,验证90%长上下文注意力条目冗余,同时将GPU成本减半。
- GLM-5在推理、编程与智能体基准测试中超越其他开源模型,缩小与Claude Opus、Gemini等顶级专有模型的差距。
- 在长上下文推理(LongBench v2)与工具使用任务(MCP-Atlas、Tool-Decathlon)中,GLM-5匹配或超越专有模型,展现强大智能体与多步规划能力。
- 在长程编程任务中,GLM-5显著优于前代,但仍落后于Claude Opus,因错误累积,凸显需更好上下文一致性与自纠错能力。
- 真实评估显示在机器翻译、多语言对话、指令遵循、世界知识与工具调用方面持续提升,与用户感知质量改善一致。
- 匿名发布“Pony Alpha”验证GLM-5在编程与智能体工作流中的前沿性能,赢得社区认可,消除对中国LLM竞争力的质疑。
作者采用稀疏注意力机制,在显著降低计算成本的同时保持强长上下文性能。结果表明,该方法在较短上下文下保持与全注意力近似精度,长上下文下优于其他稀疏模式,验证内容感知词元选择的效率。这使处理128K词元的模型得以实用部署,GPU资源约减半。

作者采用稀疏注意力机制,在降低计算成本的同时保持长上下文性能,表明扩展序列中大部分注意力条目冗余。结果表明,使用动态稀疏注意力训练的模型在基准精度上匹配密集模型,同时GPU使用量减半。此效率使处理128K上下文长度的推理密集型智能体得以实用部署。

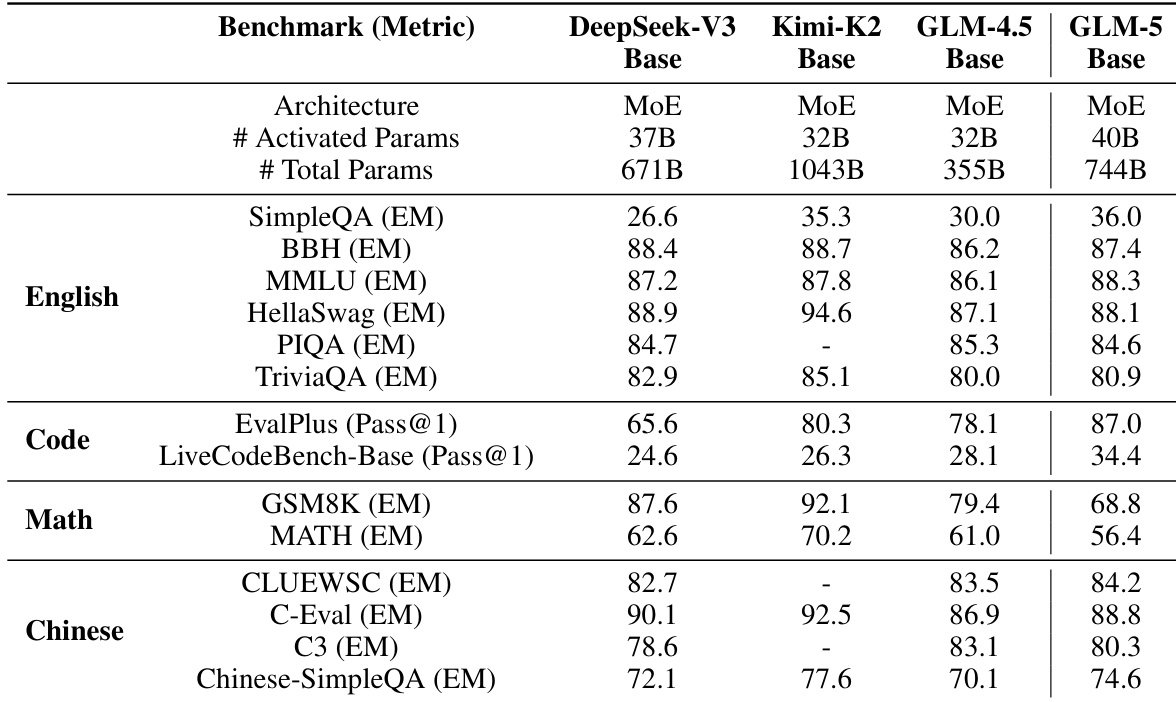
作者在英语、代码、数学与中文基准测试中评估GLM-5基座模型与其他大型开源模型,显示相较GLM-4.5持续改进,与DeepSeek-V3和Kimi-K2相比具竞争力。结果表明,GLM-5基座模型在多数类别中得分更高,尤其在代码与中文任务,同时保持更大参数量。这些发现表明模型架构与训练方法有效增强通用能力而不牺牲效率。
作者使用DeepSeek稀疏注意力(DSA)将密集基座模型适配长上下文任务,实现与原模型相当性能,同时将注意力计算减少1.5-2倍。结果表明,DSA在长达128K上下文长度保持强准确性,验证长序列中大部分注意力条目冗余。此效率使推理密集型智能体得以低成本部署而不牺牲基准性能。

作者采用稀疏注意力机制,在降低计算成本的同时保持长上下文性能,表明长序列中大部分注意力条目冗余。结果表明,适配模型在显著降低GPU使用量下仍匹配密集基线的基准性能。此效率使处理128K上下文长度的推理密集型智能体得以实用部署。
