Command Palette
Search for a command to run...
GigaBrain-0.5M*:一种基于世界模型强化学习的VLA
GigaBrain-0.5M*:一种基于世界模型强化学习的VLA
摘要
能够直接从当前观测中预测多步动作片段的视觉-语言-动作(Vision-Language-Action, VLA)模型,由于场景理解能力受限以及未来预测能力较弱,存在固有的局限性。相比之下,基于网络规模视频语料库预训练的视频世界模型展现出强大的时空推理能力和精准的未来预测性能,因而成为提升VLA学习能力的天然基础。为此,我们提出GigaBrain-0.5M,一种基于世界模型的强化学习训练的VLA模型。该模型以GigaBrain-0.5为基础,后者在超过10,000小时的机器人操作数据上完成预训练,其当前中间版本在国际RoboChallenge基准测试中排名第一。GigaBrain-0.5M进一步通过RAMP(Reinforcement leArning via world Model-conditioned Policy)机制,引入基于世界模型的强化学习,从而实现强大的跨任务适应能力。实验结果表明,RAMP在性能上显著优于RECAP基线方法,在洗衣折叠(Laundry Folding)、盒子打包(Box Packing)和意式浓缩咖啡制作(Espresso Preparation)等高难度任务上实现了约30%的性能提升。尤为重要的是,GigaBrain-0.5M*展现出可靠的长周期执行能力,在真实场景部署视频中持续完成复杂操作任务而未出现失败,相关验证视频可于项目主页 https://gigabrain05m.github.io 查阅。
一句话总结
GigaBrain 团队提出了 GigaBrain-0.5M*,这是一种通过 RAMP 强化学习训练的、由世界模型增强的 VLA 模型,能够在洗衣折叠和咖啡制作等复杂机器人任务中实现稳健的跨任务适应能力,并在实际部署中验证了其性能比 RECAP 基线高出 30%。
主要贡献
- GigaBrain-0.5M* 通过整合在网页规模和机器人操作数据上训练的视频世界模型,解决了标准 VLA 模型场景理解有限和未来预判能力弱的问题,从而在长视野任务中实现更稳健的时空推理。
- 该模型引入了 RAMP(基于世界模型条件策略的强化学习),这是一种新颖的训练框架,其策略学习以世界模型预测为条件,通过人机协同的 rollout 实现自我改进,并在不依赖模仿学习或策略梯度的情况下增强跨任务适应能力。
- 在洗衣折叠和咖啡制作等具有挑战性的现实任务中评估,GigaBrain-0.5M* 相比 RECAP 基线提升约 30%,并展示了可靠的长视野执行能力,经现实部署视频和 RoboChallenge 基准测试验证表现优异。
引言
作者利用基于世界模型的强化学习,解决视觉-语言-动作(VLA)模型在时序推理能力上的不足——这类模型通常仅依据即时观测生成动作,从而限制了其在长视野机器人任务中的表现。先前方法依赖模仿学习或策略梯度,存在误差累积、样本效率低或大规模训练不稳定等问题。其主要贡献是 GigaBrain-0.5M*,该模型基于 GigaBrain-0.5 构建,集成了 RAMP——一种以世界模型预测为条件的强化学习框架——通过人机协同 rollout 实现自我改进。这使其在洗衣折叠和咖啡制作等复杂任务中比 RECAP 基线提升约 30%,并实现可靠的现实世界执行。
方法
作者采用统一的端到端视觉-语言-动作(VLA)架构 GigaBrain-0.5 作为基础策略模型,将多模态输入——视觉观测和自然语言指令——映射为机器人动作序列。该模型采用混合 Transformer 主干,集成预训练的 PaliGemma-2 视觉语言编码器用于输入表征,并使用带流匹配的动作扩散 Transformer(DiT)预测动作块。为增强推理能力,GigaBrain-0.5 生成具身思维链(Embodied CoT),包括自回归子目标语言、离散动作标记和二维操作轨迹 t1:10。语言和离散标记通过 VLM 头解码,二维轨迹则通过轻量级 GRU 解码器从可学习标记回归。深度和二维轨迹信息作为可选状态处理,支持对异构传感器模态的适应。所有组件在统一目标下联合优化,平衡 CoT 标记预测、基于扩散的动作去噪和轨迹回归:
L=EP,τ,ϵ[−j=1∑n−1MCoT,jlogpθ(xj+1∣x1:j)+∥ϵ−achunk−fθ(achunkτ,ϵ)∥2+λGRU(t^1:10)−t1:102],其中 MCoT,j 用于遮蔽 CoT 标记,τ 是流匹配时间步,ϵ 是高斯噪声,λ 平衡轨迹损失。知识隔离确保语言和动作预测项的优化解耦。
为进一步优化策略行为,作者引入 RAMP(基于世界模型条件策略的强化学习),这是一种四阶段迭代训练框架,通过整合世界模型预测,借助经验与纠正反馈指导策略学习。如下图所示,RAMP 从世界模型预训练开始,训练潜在动力学模型 Wϕ,以根据当前观测和动作预测未来视觉状态和价值估计。该世界模型采用 Wan2.2 DiT 主干,基于 4000 小时真实机器人操作数据通过流匹配训练。未来视觉状态编码为时空潜在变量 zt,而标量信号(价值 vt、本体感知 pt)空间平铺并拼接,形成统一潜在状态 st=[zt;Ψ(vt);Ψ(pt)]。训练目标最小化模型去噪输出与真实潜在状态之间的平方误差:
LWM=ED,τ,ϵ[∥Wϕ(sfutureτ,ϵ)−(sfuture−ϵ)∥2].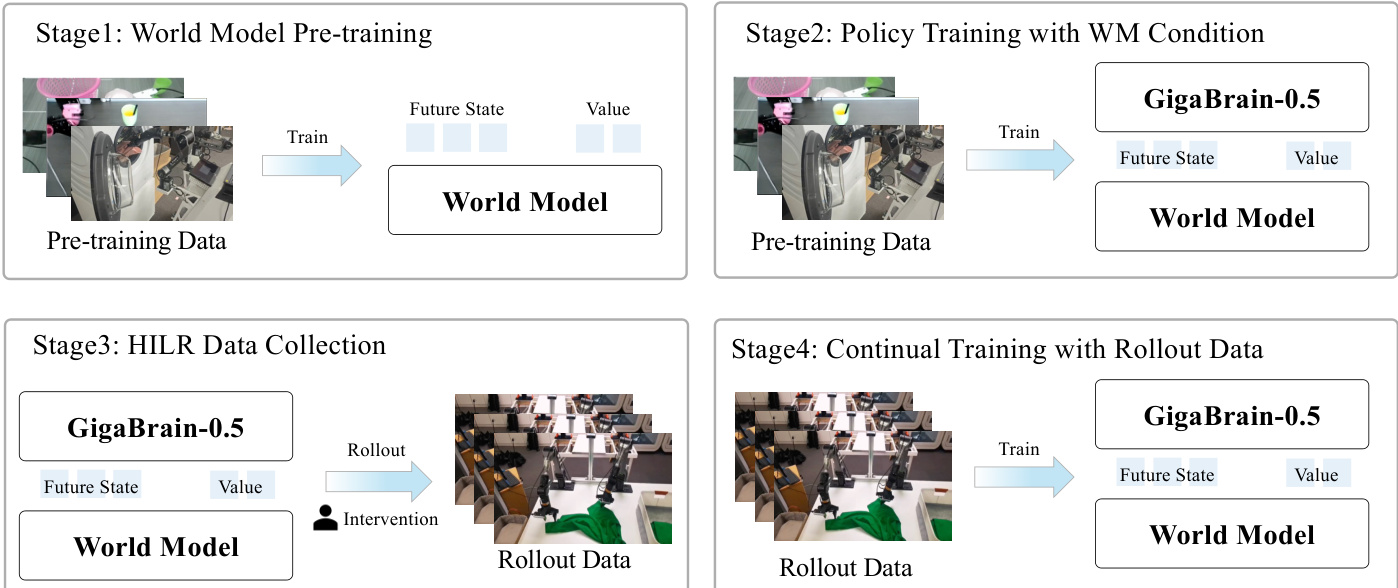
第二阶段,GigaBrain-0.5 策略在世界模型条件下进行微调。策略接收未来状态标记 zfuture 和价值估计 vt,通过 n 步时序差分估计将其投影并转换为二进制优势指示器 I=1(A(st,at)>ϵ):
A(st,at)=k=0∑n−1γkrt+k+γnvt+n−vt.策略训练目标为最小化在 (I,z) 条件下动作生成的加权负对数似然,定义如下 RAMP 目标:
L(θ)=ED[−logπθ(a∣o,z,l)−αlogπθ(a∣I,o,zt,l)].为确保鲁棒性,训练期间随机以 20% 概率屏蔽世界模型标记,防止过度依赖合成信号。
第三阶段部署策略进行人机协同 rollout(HILR)数据收集,其中自主执行与专家干预交替进行。平滑机制消除干预边界处的时间伪影,保持轨迹连贯性。生成的数据集结合原始策略动作与专家修正,相比远程操作减少了动作分布差距。
第四阶段,策略在 HILR 数据集上持续微调,同时联合更新世界模型以防止优势崩溃。维持随机屏蔽以确保训练与推理一致性。迭代的 rollout-标注-训练循环实现策略渐进改进:随着策略能力提升,其自主 rollout 生成更高质量数据用于后续训练周期。
推理阶段,作者通过固定 I=1 实施乐观控制策略。支持两种执行模式:高效模式绕过世界模型以实现最大推理频率,标准模式则利用预测的未来状态 z 进行长视野规划。这种由随机屏蔽支持的架构解耦,确保在不同计算约束下灵活部署。
实验
- GigaBrain-0.5 在盒子打包和咖啡制作等复杂长视野机器人任务中表现优异,优于包括 π₀.5 和 GigaBrain-0 在内的先前模型,在内部评估和 RoboChallenge 基准测试中均领先。
- RAMP(基于世界模型的强化学习方法)相比 AWR 和 RECAP 等基线展现出更优的样本效率和多任务泛化能力,在具有挑战性的现实任务中实现近乎完美的成功率。
- 消融研究证实世界模型中联合预测价值与未来状态的关键作用,在保持高效推理的同时提升策略准确性和任务成功率。
- 世界模型条件显著提升单任务和多任务场景下的性能,多任务训练中增益最大,表明强大的跨任务知识迁移能力。
- 在 PiPER 机械臂和 G1 人形机器人上的现实部署验证了其在果汁准备、洗衣折叠和餐桌清理等多样化操作任务中的稳健可靠执行能力。
作者比较了价值预测方法,发现其基于世界模型的方法(联合预测未来状态和价值)在准确性和速度之间取得最佳平衡。仅预测价值的世界模型变体虽更快,但牺牲预测质量;基于 VLM 的方法虽准确度相当,但速度更慢。结果表明,引入未来状态上下文显著提升了价值估计的可靠性。
