Command Palette
Search for a command to run...
统一潜在表示(Unified Latents, UL):如何训练你的潜在表示
统一潜在表示(Unified Latents, UL):如何训练你的潜在表示
Jonathan Heek Emiel Hoogeboom Thomas Mensink Tim Salimans
摘要
我们提出统一隐变量(Unified Latents, UL),这是一种通过扩散先验联合正则化并由扩散模型解码的隐变量表示学习框架。通过将编码器输出的噪声水平与先验模型的最小噪声水平相联系,我们构建了一个简洁的训练目标,该目标能够为隐变量比特率提供紧致的上界。在 ImageNet-512 数据集上,我们的方法在保持高重建质量(PSNR)的同时,实现了具有竞争力的 FID 指标(1.4),且所需的训练浮点运算量(FLOPs)低于基于 Stable Diffusion 隐变量训练的模型。在 Kinetics-600 数据集上,我们取得了新的最先进 FVD 指标(1.3)。
一句话总结
Google DeepMind 阿姆斯特丹的研究人员提出了 Unified Latents(UL),这是一种基于扩散的框架,联合训练编码器、先验模型和解码器,以优化用于生成的潜在表示,在实现最先进的 FID 和 FVD 的同时,通过简单的超参数提供可解释的比特率控制。
主要贡献
- Unified Latents 引入了一种基于扩散的框架,联合训练编码器、扩散先验和扩散解码器,使用确定性编码器与固定噪声以简化训练,并提供潜在比特率的紧上界。
- 该方法将先验的最小噪声水平与编码器输出噪声对齐,将 KL 项简化为加权 MSE,从而通过简单超参数实现对重建-建模权衡的可解释控制。
- 在 ImageNet-512 和 Kinetics-600 上评估,UL 实现了具有竞争力的 FID(1.4)和最先进的 FVD(1.3),同时拥有更高的 PSNR 和比 Stable Diffusion 潜在表示更少的训练 FLOPs,展示了更高的效率和生成质量。
引言
作者利用一种称为 Unified Latents(UL)的统一框架训练潜在表示,该表示同时被编码、由扩散先验正则化,并由扩散模型解码。这种方法之所以重要,是因为高效且高质量的潜在表示对于扩展扩散模型至高分辨率图像和视频生成至关重要,但以往方法难以在信息密度与重建保真度之间取得平衡——通常为了更好的 FID 而牺牲 PSNR,或需要手动调整正则化权重。现有技术要么依赖固定瓶颈、不稳定的熵项,要么使用预训练语义编码器而丢失高频细节。作者的主要贡献是一个简单、稳定的训练目标,将编码器的噪声水平与扩散先验的最小噪声绑定,从而获得潜在比特率的紧界和可解释的超参数以控制重建-生成权衡——同时以更少的训练 FLOPs 实现最先进的 FID 和 FVD。
方法
作者利用一个统一的潜在扩散框架,整合确定性编码器、基于扩散的先验和条件扩散解码器,以建模图像数据。该架构旨在通过先验显式正则化潜在空间的信息内容,同时通过解码器实现高保真重建。
编码器 Eθ 将输入图像 x 映射到确定性潜在表示 zclean,避免了学习灵活后验分布带来的不稳定性。该干净潜在表示随后通过固定噪声调度前向加噪至时间 t=0,其中 λ(0)=5,生成轻微噪声的潜在 z0∼N(α0zclean,σ0),其中 α0≈1.0 且 σ0≈0.08。此步骤确保潜在空间由扩散先验正则化,该先验建模从纯噪声 z1∼N(0,I) 到 z0 的逆向过程。通过无加权 ELBO 最小化编码器路径与先验生成路径之间的 KL 散度,强制潜在编码仅包含先验能可靠重建的信息。
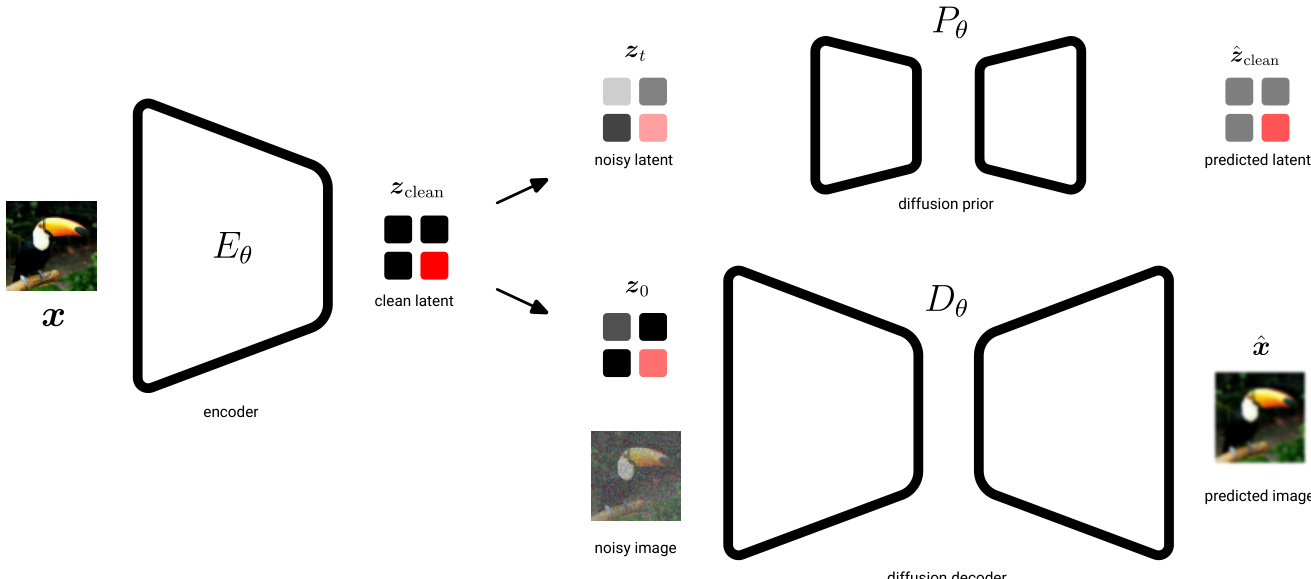
扩散解码器 Dθ 在图像空间中操作,以潜在 z0 为条件重建原始图像。它建模从噪声图像 xt 到干净图像 x 的逆向扩散过程,损失计算为加权 ELBO。权重函数 wx(λx(t))=sigmoid(λx(t)−b) 用于优先建模中间噪声水平下感知显著的特征。为防止后验坍塌并鼓励潜在携带有意义的信息,解码器损失被乘以因子 clf(通常为 1.3–1.7),从而有效降低整体目标中的 KL 项权重。
训练分两个阶段进行。第一阶段,编码器和解码器与先验联合优化,使用组合损失 L(θ)=Lz(θ)+Lx(θ),其中 Lz 是先验损失,Lx 是解码器损失。第二阶段,冻结编码器和解码器,使用 sigmoid 加权 ELBO 在固定潜在空间 z0 上训练更大、更具表达力的基础模型以提高样本质量。该基础模型使用与先验相同的最终 log-SNR λ(0),确保潜在噪声水平的一致性。

在架构上,编码器是一个具有下采样阶段和残差块的 ResNet,而先验和基础模型是具有不同深度和通道数的 Vision Transformer(ViT)。解码器实现为 UViT,结合卷积下采样/上采样与 Transformer 瓶颈,并使用 dropout 进行正则化。编码器和解码器中使用 2x2 块划分以降低计算成本而不牺牲性能。
实验
- Unified Latents 显著提升预训练效率,在 ImageNet-512 和 Kinetics-600 上优于 Stable Diffusion 等先前方法,在 FID/FVD 与训练成本权衡上表现更优。
- 潜在比特率调优至关重要:较低比特率有利于小型模型的生成质量,而大型模型受益于较高比特率;最佳设置取决于模型规模。
- 潜在形状(通道数和空间下采样)除极低通道数或极端下采样外,对性能影响极小。
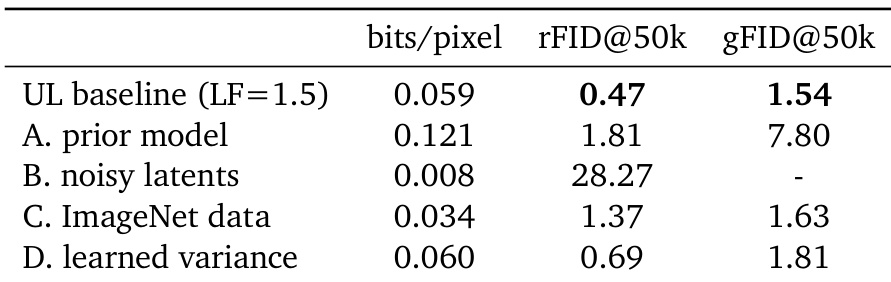
- L2 正则化或 VAE 风格先验会降低性能;固定方差噪声潜在提供更好的稳定性和生成质量。
- 消融实验证实关键组件——扩散先验、噪声潜在和固定编码器方差——对强性能至关重要。
- Unified Latents 在文本到图像和视频任务中泛化良好,在 Kinetics-600 上实现最先进的 FVD,且在最小引导下具有竞争力的文本对齐。
- 端到端训练可行,但结果劣于两阶段方法;与基于 GAN 的替代方案相比,解码器成本仍是实际限制。
作者使用基于扩散的先验和重建损失训练 Unified Latents,发现该组合相比其他方法产生最低的潜在比特率和最佳生成质量(gFID)。替换任一组件——如使用 MSE 重建损失或正态先验——会导致更高比特率和更差的生成性能,表明联合扩散设置对高效潜在建模至关重要。结果表明,仅当先验和重建均为扩散基时,才能在保持低潜在复杂度的同时保留生成保真度。

作者使用具有固定编码器方差和扩散先验的 Unified Latents 实现高效预训练,消融研究表明移除先验或使用噪声潜在会降低重建和生成质量。结果表明,在 ImageNet 数据上训练比在文本到图像数据上训练略微提升生成 FID,而学习方差在牺牲生成性能的同时提升重建保真度。基线配置在潜在比特率、重建精度和生成质量之间取得最佳平衡。
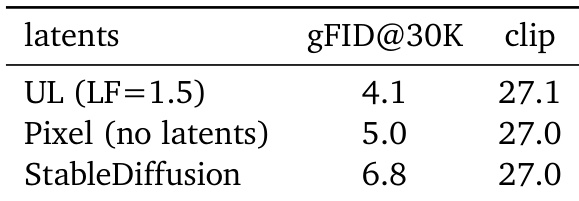
作者使用损失因子为 1.5 的 Unified Latents,在图像生成质量上优于基于像素的扩散和 Stable Diffusion 潜在表示,表现为更低的 gFID 分数。通过 CLIP 分数衡量的文本对齐在所有方法中保持可比,表明 Unified Latents 在不牺牲语义保真度的情况下提升感知质量。结果表明,Unified Latents 在训练成本与生成性能之间提供更高效的权衡。
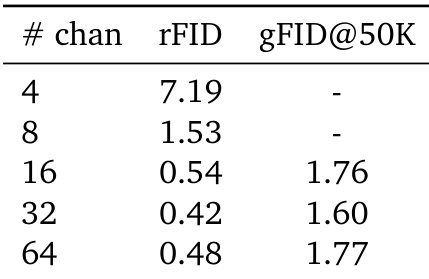
作者评估潜在通道数变化如何影响重建和生成质量,发现性能在 16 个通道后趋于稳定。虽然 4 个通道导致重建效果差,但 32 个通道在低 rFID 和有竞争力的 gFID 之间取得最佳平衡,64 个通道仅带来边际收益。结果表明,一旦达到最小阈值,Unified Latents 对通道数基本不敏感。
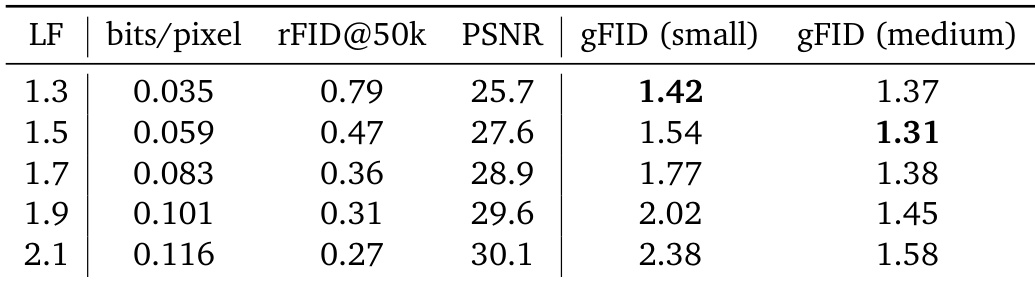
作者使用 Unified Latents 通过损失因子调优潜在比特率,发现较高损失因子可提升重建质量但增加比特率,可能损害小型模型的生成性能。结果表明,中型模型在中等损失因子下获得最佳生成 FID,而小型模型在较低比特率下表现最佳,尽管重建效果较差。这表明重建保真度与生成效率之间存在依赖于模型规模的权衡。