Command Palette
Search for a command to run...
InnoEval:将研究创意评估视为一种基于知识的多视角推理问题
InnoEval:将研究创意评估视为一种基于知识的多视角推理问题
摘要
大型语言模型(Large Language Models, LLMs)的迅猛发展极大地推动了科学创意的生成,然而这一飞跃并未伴随相应的创意评估能力的同步提升。科学评价的本质要求具备深厚的专业知识基础、集体协商机制以及多维度决策能力。然而,现有的创意评估方法普遍存在知识视野狭窄、评价维度单一,以及“以大模型为裁判”(LLM-as-a-Judge)固有的偏见等问题。针对上述挑战,本文将创意评估视为一个基于知识、多视角推理的问题,提出InnoEval——一种旨在模拟人类水平创意评估的深度创新评价框架。InnoEval采用异构深度知识搜索引擎,从多样化的在线来源中动态检索并锚定证据,确保评估过程具备充分的知识支撑。同时,通过构建由不同学术背景评审员组成的创新评审委员会,实现多维度、解耦式的综合评估,有效达成评审共识。为全面验证该框架的性能,我们基于权威同行评审的学术投稿构建了综合性数据集,用于基准测试。实验结果表明,InnoEval在点级、成对及群体级评估任务中均能持续超越现有基线方法,其判断模式与评审共识高度契合人类专家的决策逻辑,展现出卓越的评估一致性与可信度。
一句话总结
浙江大学与阿姆斯特丹大学的研究人员提出了 InnoEval,这是一种基于知识的多视角框架,通过动态证据检索和多样化评审委员会来克服大语言模型在科学创意评估中的偏见,在多个基准任务中实现了与人类一致的共识。
主要贡献
- InnoEval 通过将评估框架化为基于知识、多视角的推理任务,填补了评估大语言模型生成科学创意的关键空白;它通过异构深度知识搜索引擎从文献、网络和代码来源中检索动态证据,以应对知识视野狭窄和“大语言模型作为裁判”的偏见。
- 该框架通过模拟由具有不同学术背景的角色评审员组成的创新评审委员会,模拟人类评审共识;每位评审员独立从五个解耦维度——清晰性、新颖性、可行性、有效性与重要性——评估创意,以保留多标准决策并减轻单裁判偏见。
- 在源自同行评审提交数据集上的评估显示,InnoEval 在点式预测中 F1 提升 16.18%,成对准确率提升 5%,组式排序提升 7.56%,人工评估确认其判断模式与共识高度一致。
引言
作者利用大语言模型应对科学研发中自动化创意生成与人类级创意评估之间日益扩大的差距。现有方法受限于静态论文构成的狭窄知识库、有偏的单裁判评估以及忽略创新多维特性的扁平化指标。为此,他们提出了 InnoEval——一种将创意评估视为基于知识、多视角推理问题的框架。该框架结合异构深度知识搜索引擎(从文献、网络和代码来源提取动态证据)与模拟创新评审委员会(由多样化学术角色组成),生成跨清晰性、新颖性、可行性、有效性与重要性的共识驱动型多维评估。该方法在点式、成对与组式任务中优于基线方法,同时与人类专家判断高度对齐。
数据集

作者使用从 NeurIPS 2025 和 ICLR 2025 论文(通过 OpenReview 获取)构建的多层级数据集,过滤掉撤回或占位提交。他们构建了三个核心子集:
-
点式数据集 (D_point, 217 个样本):
- 包含 136 个 ICLR 2025 和 81 个 NeurIPS 2025 创意。
- 按最终决策分层:138 个拒绝、66 个海报、9 个亮点、4 个口头报告(拒绝:61.3%,海报:29.3%,亮点:9.4%)。
- 每个创意通过代理 M_e 提取,再经人工验证。
- 任务:二元分类(拒绝 vs. 接受)和三元分类(拒绝、海报、亮点)。
- 指标:准确率和宏 F1。
-
组式数据集 (D_group, 172 个实例):
- 以每个 D_point 创意的摘要作为查询,通过 bge-base-en-v1.5 检索相似论文(前 800 篇),再用 bge-reranker-base 重排序至前 120 篇。
- 每个决策层级取一篇最相似论文组成一组,实现基于标签的排序。
- 任务:最佳创意选择(准确率)和完整排序(LIS 分数 + 准确率)。
- LIS 衡量预测排名与真实排名的对齐程度,计算方式为最长递增子序列长度除以组大小。
-
成对数据集 (D_pair, 372 个样本):
- 源自 D_group:172 个简单对(如拒绝 vs. 亮点)和 200 个困难对(如海报 vs. 亮点)。
- 任务:二元比较,按难度级别分别评估准确率。
所有数据集仅用于评估——不用于训练。作者还部署了基于角色的评审系统(附录 F. 创新评审委员会)以减轻大语言模型偏见,其中合成评审员根据其专长分数按比例屏蔽证据(例如,文献熟悉度 = 8 时屏蔽 20%)。这些角色由 DeepSeek-V3.2 生成,并嵌入提示词中供维度特异性代理使用。
方法
作者采用多阶段、代理驱动的架构 InnoEval,通过将创意锚定于动态异构知识源并综合多视角评估,系统性评估研究创意。框架始于提取代理,将原始文本输入解析为结构化的六元组表示——包括 TLDR、动机、研究问题、方法、实验设置和预期结果——以支持精确的下游处理。该结构化创意随后输入异构深度知识搜索引擎,该引擎通过快速与慢速搜索阶段、查询优化和知识排序的迭代循环运行。
请参阅框架图,其展示端到端流水线。流程从查询生成开始,为每个创意组件构建定制查询,并分发至多个搜索工具——包括 Google、arXiv、Semantic Scholar 和 GitHub——图中以不同图标表示。这些查询通过同义词扩展丰富,以应对跨领域的术语差异。快速搜索阶段从这些工具中检索简要结果,然后使用结合语义相似度(Ssem)和大语言模型评分(Sllm)的混合评分函数(权重系数为 α)进行排序和过滤。每类知识(文献、网络、代码)保留前 m 个结果用于后续丰富。
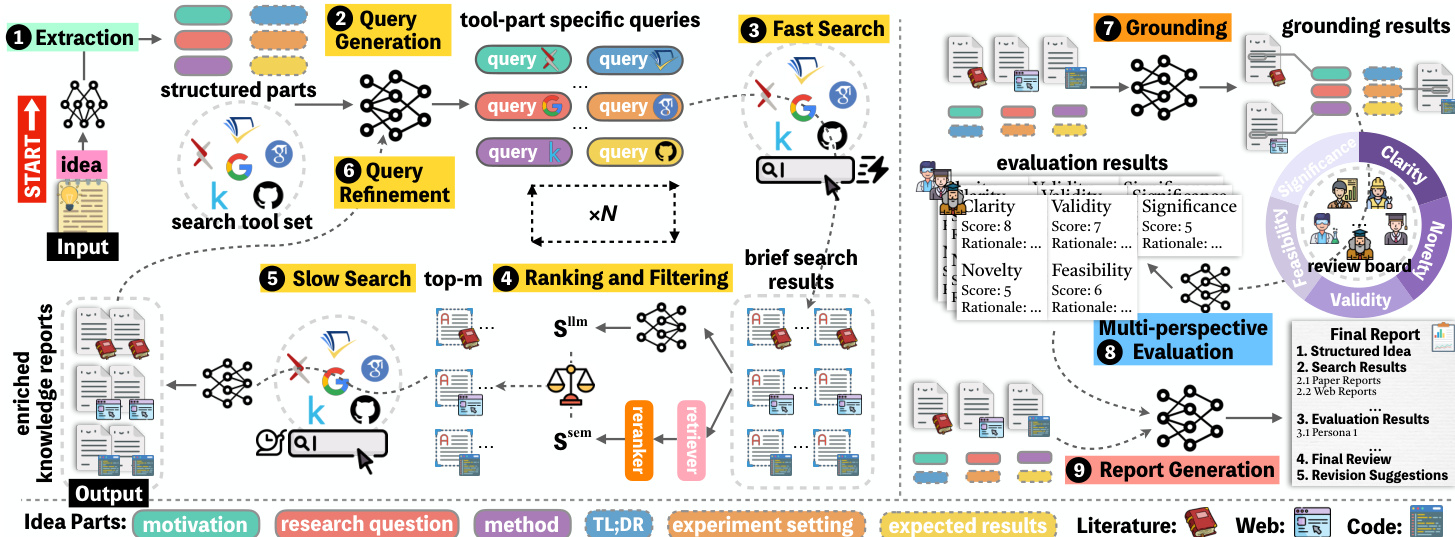
慢速搜索阶段丰富过滤结果:对文献,解析完整 PDF 为结构化文本;对网页内容,生成摘要;对代码仓库,分析调用图和 README 以生成可执行上下文。丰富后的知识随后进入迭代查询优化,搜索代理基于先前检索结果重写、泛化或具体化查询,以发现更深入或更相关的背景材料。此循环重复 N 次,逐步扩展知识库。
检索后,锚定代理将每个创意组件与检索到的知识中的特定证据对齐,生成细粒度相关性分析,明确支持或反驳创意主张。这些锚定结果作为多维度多视角评估的基础,由基于角色的评审员小组执行。每个角色来自创新评审委员会,根据其模拟熟悉度分配部分知识,并使用专用代理评估器 Mψ 从五个维度——清晰性、有效性、新颖性、可行性与重要性——评估创意。每次评估生成分数与叙述性理由,聚合为元评审。
最后,报告代理将丰富知识、锚定结果与评估输出合成为结构化最终报告。对于点式评估,包括背景知识、基于前瞻性知识的修改建议及含最终决策的元评审。对于组式评估,系统跨维度比较所有创意并生成排序列表及对比分析。整个架构设计为模块化、可扩展且锚定于实时、多样化知识源,确保评估的时效性与深度。
实验
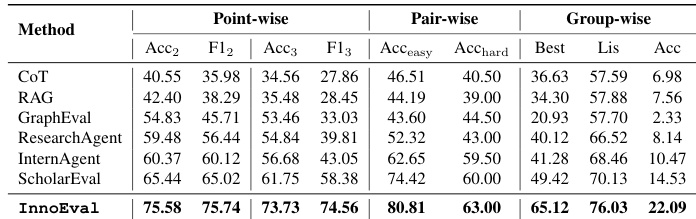
- InnoEval 在点式、成对与组式评估任务中通过多源检索、多视角评审与锚定分析超越多个基线方法,实现更高 F1 分数与更优标签分布。
- 定性评估显示,InnoEval 的报告比基线方法更具理性、支持性、深度与建设性,在五个维度上与人类及同行评审判断高度一致。
- 消融研究确认,锚定、个性化评审员角色与多样化检索源(包括网络与代码)对性能至关重要,移除它们会导致结果下降。
- InnoEval 的多视角测试时扩展随角色增加而提升,表明真实评审员多样性优于合成意见生成。
- 系统的深度知识搜索引擎在相关性、覆盖范围与多样性上优于基线搜索模块。
- InnoEval 的反馈提升了创意生成流程,比 ScholarEval 或原始基线方法产生更精炼的问题表述、方法论与实验设计。
- 新颖性是创意接受的最强预测因子,而可行性对获得亮点状态至关重要,表明需要全面评估。
- 维度相关性揭示清晰性与重要性是基础,而新颖性与有效性、可行性略有权衡,符合学术直觉。
- InnoEval 在不同骨干模型(DeepSeek-V3.2 和 o4-mini)上表现稳健,可通过全面多角度评审识别真实世界创新,缓解单视角偏见。
作者使用 InnoEval 在点式、成对与组式任务中评估科学创意,超越多个基线方法,包括 CoT、RAG、ResearchAgent 和 ScholarEval。结果显示,InnoEval 通过多维度、多视角评估与丰富证据锚定实现最先进性能,缓解标签坍塌并提升与人类判断的一致性。消融研究证实,个性化角色、多样化检索源与锚定是其稳健性与有效性的关键。
作者使用大语言模型作为裁判,在五个定性维度上比较 InnoEval 与多个基线方法,发现 InnoEval 在理性、支持性、深度与建设性上始终优于它们。结果表明,InnoEval 的多源搜索与多视角评估显著提高胜率,尤其在深度与整体质量上,而 ScholarEval 在部分维度仍具竞争力但建设性不足。研究凸显整合多样化证据与结构化评审角色可增强评估稳健性与可操作反馈。
