Command Palette
Search for a command to run...
超越教师的学习:基于奖励外推的广义在线策略蒸馏
超越教师的学习:基于奖励外推的广义在线策略蒸馏
Wenkai Yang Weijie Liu Ruobing Xie Kai Yang Saiyong Yang Yankai Lin
摘要
在策略蒸馏(On-Policy Distillation, OPD)中,学生模型通过匹配教师模型在学生自身生成轨迹上的logit分布来优化自身性能,该方法在实践中展现出显著的性能提升,通常优于离策略蒸馏及传统的强化学习(Reinforcement Learning, RL)范式。本文首先从理论上证明,OPD可视为一种特殊的密集KL约束强化学习(dense KL-constrained RL)情形:在此框架下,奖励函数与KL正则化项始终以相等权重进行平衡,且参考模型可为任意模型。基于此理论洞察,我们提出了广义在策略蒸馏(Generalized On-Policy Distillation, G-OPD)框架,通过引入可灵活选择的参考模型以及一个控制奖励项与KL正则化相对权重的奖励缩放因子,对标准OPD目标函数进行扩展。在数学推理与代码生成任务上的大量实验中,我们得出两个新见解:(1)将奖励缩放因子设置为大于1(即奖励外推,Reward Extrapolation),我们称之为ExOPD,该方法在多种教师-学生模型规模组合下均能持续超越标准OPD。尤其在将不同领域专家知识(通过在相同学生模型上应用领域特定强化学习获得)融合回原始学生模型的场景中,ExOPD使学生模型不仅突破了教师模型的性能边界,甚至超越了各领域教师模型的性能表现。(2)在强到弱蒸馏设置中(即从较大教师模型蒸馏较小学生模型),若在强化学习前将参考模型设定为教师模型的基线版本(base model),可获得更精确的奖励信号,从而进一步提升蒸馏效果。然而,该策略依赖于对教师模型在强化学习前原始版本的访问,带来更高的计算开销。我们期望本工作能为未来在策略蒸馏领域的研究提供新的理论视角与实践启发。
一句话总结
中国人民大学与腾讯的研究人员提出了 G-OPD,一种具有奖励缩放和灵活参考模型的广义在线策略蒸馏框架,使学生模型能够通过奖励外推(ExOPD)超越教师模型,尤其在多专家合并和强→弱蒸馏场景中表现突出。
主要贡献
- 我们从理论上将在线策略蒸馏(OPD)与密集 KL 约束强化学习统一起来,表明 OPD 是奖励与 KL 项权重相等、参考模型任意的特例,从而支持一个具有灵活奖励缩放和参考模型选择的广义框架(G-OPD)。
- 我们引入了 ExOPD,即奖励缩放因子 >1 的 G-OPD 变体,它在各类师生配对中始终优于标准 OPD,并在合并多个 RL 微调专家时使学生模型超越领域特定教师,在 4 个数学和 3 个代码生成基准上得到验证。
- 在强→弱蒸馏中,我们表明在 ExOPD 中使用教师的预 RL 模型作为参考可提升奖励准确性和蒸馏性能,尽管这需要额外计算和访问教师的基础模型,进一步超越标准 OPD 的结果。
引言
作者利用在线策略蒸馏(OPD)——即学生模型从其自身生成轨迹上的教师 logits 学习——以改进大语言模型(LLM)的后训练,尤其在合并领域特定能力或将大型教师蒸馏为小型学生时。以往的 OPD 方法将奖励与 KL 正则化视为固定等权组件,限制了其灵活性和超越教师性能的潜力。作者的主要贡献是广义 OPD(G-OPD),它引入了奖励缩放因子和灵活的参考模型;他们表明,将奖励缩放至 1 以上(ExOPD)可使学生超越教师,尤其在多教师融合与强→弱蒸馏中,并通过使用教师的预 RL 模型作为参考进一步提升效果——尽管这会增加计算成本。
方法
作者采用了一种广义在线策略蒸馏(G-OPD)框架,通过引入密集的词元级奖励和灵活的正则化控制扩展了传统知识蒸馏。与离线策略蒸馏(训练学生模仿教师生成轨迹而不反馈自身动作)不同,G-OPD 是在线策略:学生生成自己的响应,训练信号源于其输出分布与教师分布之间的差异(以学生自身 rollout 为条件)。
G-OPD 的核心在于其使用参考模型 πref 和奖励缩放因子 λ 对在线策略蒸馏目标的重新表述。从标准 OPD 目标(在学生生成轨迹上最小化学生 πθ 与教师 π∗ 之间的逆 KL 散度)出发,作者将其重写为 KL 约束强化学习目标。具体而言,他们表明 OPD 等价于最大化奖励函数 r(x,y)=logπref(y∣x)π∗(y∣x),同时通过 KL 项惩罚对 πref 的偏离。这一等价性允许他们引入 λ 来调节奖励与正则化之间的相对权重,得到广义目标:
IG−OPD(θ)=θmax Ex∼D,y∼πθ(⋅∣x)[λlogπref(y∣x)π∗(y∣x)−DKL(πθ(y∣x)πref(y∣x))].该公式支持两种关键操作模式。当 0<λ<1 时,鼓励学生对数概率分布介于教师与参考模型之间——作者称此为“奖励插值”。当 λ>1 时,学生被推动超越教师分布,通过外推奖励信号实现——称为“奖励外推”。这种灵活性使实践者可调节学生行为,从保守模仿到激进优化。
在强→弱蒸馏场景(将大型教师蒸馏为小型学生)中,作者提出一种“奖励校正”机制。他们建议不使用学生的基础模型作为参考,而改用教师的预 RL 基础模型 πbaseteacher,从而获得更清晰、与教师 RL 训练轨迹对齐的隐式奖励信号。该校正将奖励从 logπbasestudentπ∗ 调整为 logπbaseteacherπ∗,有效补偿教师与学生基础模型在架构和容量上的不匹配。
训练动态由 G-OPD 目标导出的策略梯度估计器控制。为计算效率,采用零折扣因子近似梯度,其形式为:
∇θJG−OPD(θ)=Ex∼D,y∼πθ(⋅∣x)[t=1∑TAtG−OPD∇θlogπθ(yt∣x,y<t)],其中词元级优势定义为:
AtG−OPD=(logπθ(yt∣x,y<t)−logπ∗(yt∣x,y<t))+(λ−1)(logπref(yt∣x,y<t)−logπ∗(yt∣x,y<t)).该优势函数同时封装了学生-教师差异与参考模型诱导的奖励偏移,支持密集的逐词元信用分配,加速收敛并提升泛化能力。
实验
- 单教师蒸馏表明,标准 OPD 完全恢复教师行为,而奖励插值(0 < λ < 1)可实现性能与响应长度的可控权衡;奖励外推(λ = 1.25)始终超越教师,尽管 λ = 1.5 可能因奖励作弊引发不稳定。
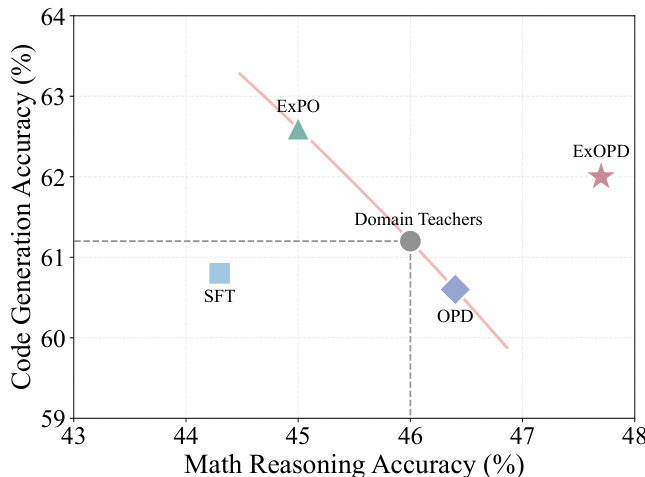
- 在多教师蒸馏中,λ = 1.25 的 ExOPD 优于 OPD 和 SFT,生成一个统一的学生模型,超越所有领域教师——与缺乏一致增益和可控性的权重外推(ExPO)不同。
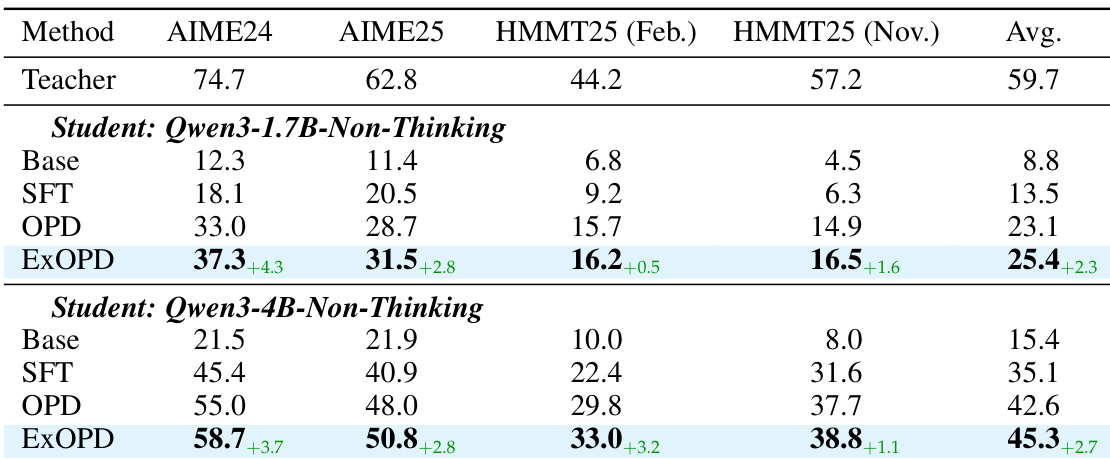
- 在强→弱蒸馏中,ExOPD 显著优于标准 OPD 和 SFT,表明奖励外推可克服大型与小型模型之间的知识差距。
- 奖励校正——使用教师的预 RL 变体作为参考——进一步提升 ExOPD 性能,尽管它带来更高计算成本并需访问额外模型变体。
- 在所有设置中,ExOPD 一致增加响应长度和熵,表明输出多样性更高,同时保持或超越教师级别的准确性。
作者使用 ExOPD 在强→弱设置中将更强教师模型的知识蒸馏到更小的学生模型,多个数学推理基准上始终优于标准 OPD 和 SFT。结果表明,ExOPD 不仅优于基线方法,且随学生模型规模有效扩展,对更小的学生模型带来更大收益。该方法对模型容量差距表现出鲁棒性,表明即使教师与学生规模显著不同,奖励外推仍可突破标准蒸馏的限制。
作者使用奖励缩放因子为 1.25 的 ExOPD,将领域特定教师的知识蒸馏到基础模型,在数学推理和代码生成任务中均持续优于标准 OPD 和原始教师。在多教师设置中,ExOPD 是唯一能产生统一学生模型超越所有个体领域教师的方法,而 SFT 和 ExPO 表现有限或不一致。结果还证实,ExOPD 的增益并非源于教师训练不足,因为继续对教师进行 RL 训练带来的提升小于 ExOPD 用更少步骤实现的效果。
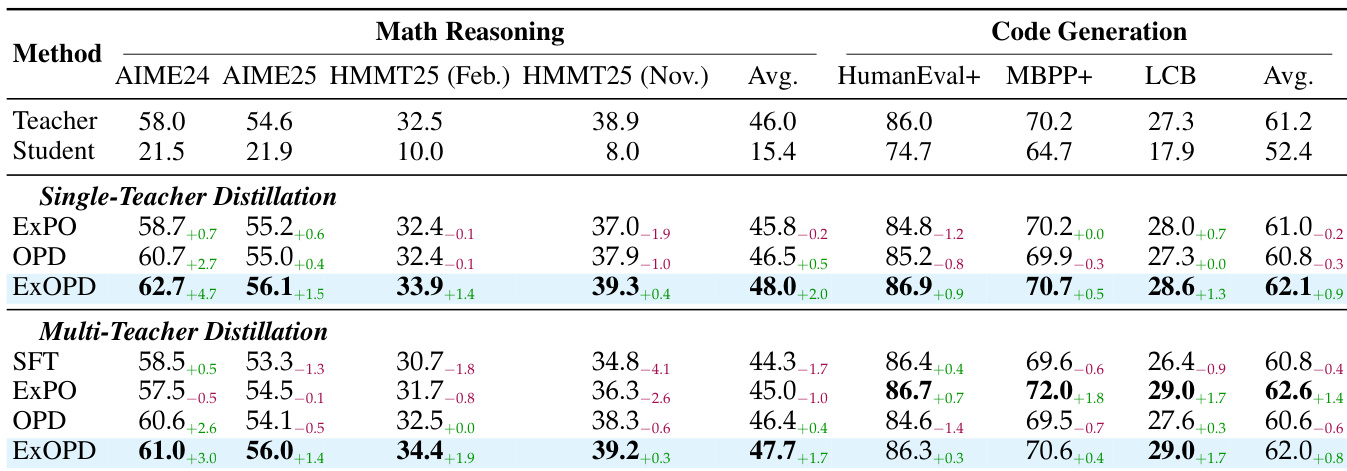
作者使用奖励缩放因子为 1.25 的 ExOPD,将领域特定教师的知识蒸馏到基础模型,性能超越原始教师和标准 OPD。结果表明,即使训练步数更少,ExOPD 在多个数学推理基准上始终优于教师模型,表明其有能力超越教师能力。该改进并非源于延长教师训练,因为对教师增加 RL 步数带来的增益小于 ExOPD。
