Command Palette
Search for a command to run...
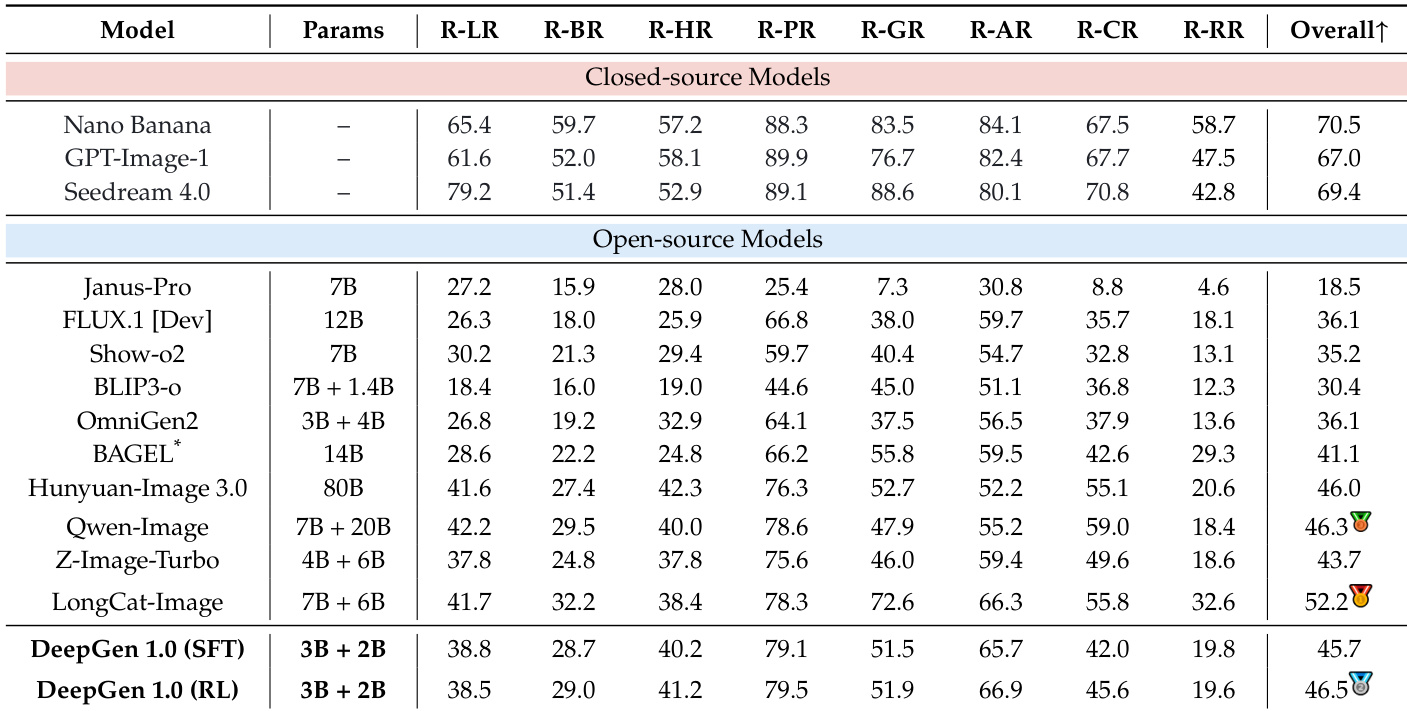
DeepGen 1.0:一种轻量级统一多模态模型,用于推进图像生成与编辑
DeepGen 1.0:一种轻量级统一多模态模型,用于推进图像生成与编辑
摘要
当前主流的统一多模态图像生成与编辑模型通常依赖于庞大的参数规模(例如超过100亿),导致训练成本高昂且部署开销巨大。在本工作中,我们提出DeepGen 1.0——一个轻量级的50亿参数统一模型,其综合能力在多项指标上达到或超越远大于它的同类模型。为克服小型模型在语义理解与细粒度控制方面的局限性,我们引入了堆叠通道桥接(Stacked Channel Bridging, SCB)机制,这是一种深度对齐框架,能够从多个视觉语言模型(VLM)层级中提取分层特征,并通过可学习的“思考令牌”(think tokens)进行融合,从而为生成主干网络提供结构化、富含推理能力的引导。此外,我们设计了一种以数据为中心的三阶段渐进式训练策略:(1)在大规模图像-文本对及编辑三元组上进行对齐预训练,以同步VLM与扩散模型(DiT)的表征;(2)在高质量生成、编辑与推理任务混合数据集上进行联合监督微调,以培养模型的全能力特性;(3)采用基于多奖励函数与监督信号混合的强化学习方法MR-GRPO,显著提升生成质量与人类偏好对齐程度,同时保持训练过程稳定,有效避免视觉伪影。尽管仅在约5000万样本上进行训练,DeepGen 1.0在多个基准测试中均展现出领先性能:在WISE基准上超越800亿参数的HunyuanImage模型达28%,在UniREditBench上领先270亿参数的Qwen-Image-Edit模型达37%。通过开源训练代码、模型权重及数据集,我们为推动统一多模态研究的普惠化,提供了一种高效且高性能的替代方案。
一句话总结
来自上海创新研究院、复旦大学、中国科学技术大学等机构的研究人员提出了 DeepGen 1.0,这是一个采用堆叠通道桥接(Stacked Channel Bridging)和分阶段训练的 50 亿参数轻量级多模态模型,在生成与编辑任务上超越更大规模模型,取得最先进成果,并通过开源代码与数据集推动技术普惠。
主要贡献
- DeepGen 1.0 引入了一个 50 亿参数的统一轻量级模型,用于图像生成与编辑,挑战了“必须使用超大规模模型(>100 亿参数)才能获得高性能”的假设,仅使用约 5000 万样本训练即达到最先进水平。
- 提出堆叠通道桥接(SCB)——一种新颖的对齐框架,将分层视觉语言模型(VLM)特征与可学习的“思考标记”融合,为 DiT 主干提供结构化、富含推理能力的引导,在不增加模型规模的前提下增强语义理解与细粒度控制。
- 通过三阶段数据驱动训练流程——包括对齐预训练、联合监督微调和基于 MR-GRPO 的强化学习——DeepGen 1.0 在多个基准测试中超越更大模型:在 WISE 上优于 800 亿参数的 HunyuanImage(28%),在 UniREditBench 上优于 270 亿参数的 Qwen-Image-Edit(37%),同时避免视觉伪影并保持训练稳定性。
引言
作者利用统一的 VLM-DiT 架构构建了 DeepGen 1.0——一个 50 亿参数的模型,可处理图像生成、编辑和推理任务,挑战了“只有超大规模模型(100 亿+参数)才能输出高质量、语义准确视觉内容”的传统观念。以往工作依赖昂贵的多模型系统或大规模训练数据,而小型模型因跨模态对齐能力弱、推理支持不足而性能受限。DeepGen 1.0 通过堆叠通道桥接(SCB)克服这些限制:该框架融合多层 VLM 特征与可学习“思考标记”,引导 DiT 实现结构化、分层语义;再配合强调数据效率和人类偏好对齐的三阶段训练流程(含 MR-GRPO),最终产出紧凑模型,在推理与编辑基准测试中超越 800 亿与 270 亿参数基线模型,仅使用 5000 万样本训练,并完全开源以促进更广泛采用。
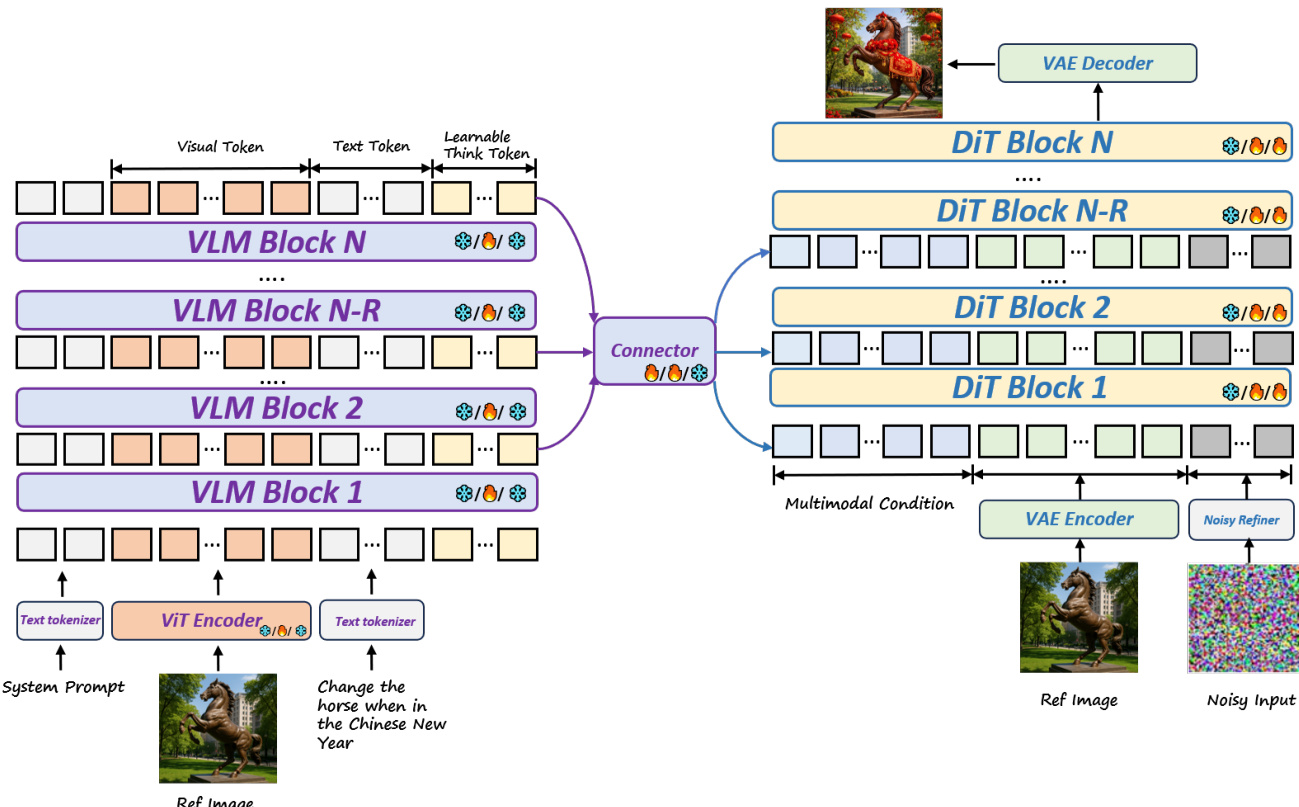
数据集
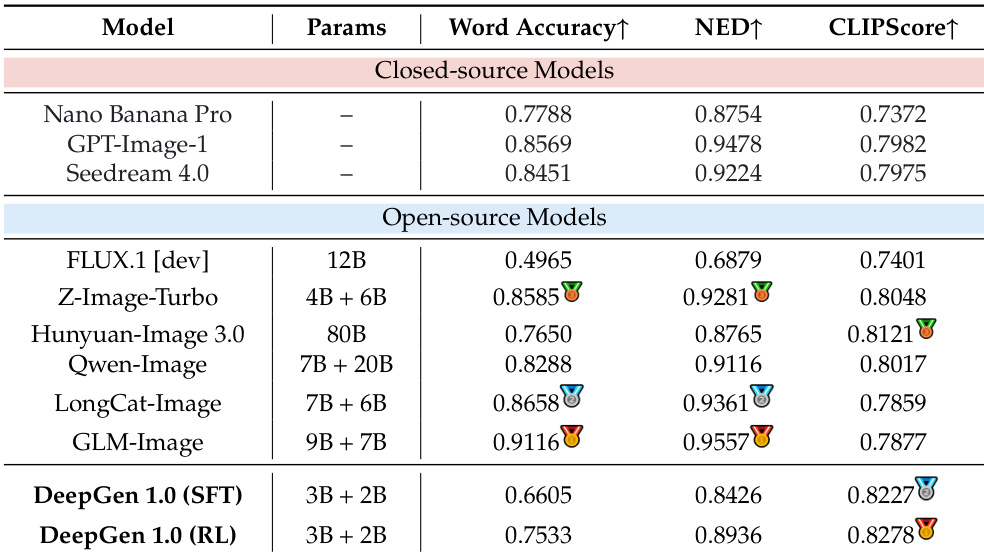
作者使用多样化、多源训练数据集,结合真实世界、合成和精选开源数据,支持通用生成、编辑、推理、文本渲染及特定应用场景任务。
-
通用生成:
- 来源:Text-to-image-2M、LAION-Aesthetic-6M、Megalith-10M、RedCaps-5M、CC-12M。
- 指令微调:BLIP-3o(6 万)、ShareGPT-4o-Image(4.5 万)、Echo-4o-Image(10 万)、OpenGPT4o-Image(4 万),外加 1000 万内部样本(长/短提示比例 3:1)。
- 增强约 5 万张通过 Nano Banana 生成的合成写实图像,搭配中英文细粒度提示。
-
通用编辑:
- 来源:NHR-Edit(72 万)、GPT-Image-Edit(150 万)、ShareGPT-4o-Image-Edit(5 万)、OpenGPT4o-Image-Edit(4 万)、Nano-banana-consist(15 万)、Pico-Banana(25 万)、X2I2(160 万)、Uniworld-Edit(120 万),外加 110 万内部编辑样本(中英文)。
-
基于推理的生成与编辑:
- 来源:UniReason(15 万生成、10 万编辑样本),涵盖文化常识、自然科学、空间、时间与逻辑推理。
-
文本渲染与应用场景:
- 来源:多模态问答数据集用于字幕;Gemini 2.5 Pro 生成多样渲染属性(字体、布局、颜色);Qwen-Image 合成 50 万张文本渲染图像。
- 扩展 6 万应用场景样本(如中文诗歌、海报设计)。
-
处理与使用:
- 数据集按训练阶段混合,详见附录 A 表 8。
- 未明确提及裁剪策略;元数据通过提示工程与合成图像生成流程构建。
- 所有子集均对齐支持多语言(中/英)与多模态指令遵循。
方法
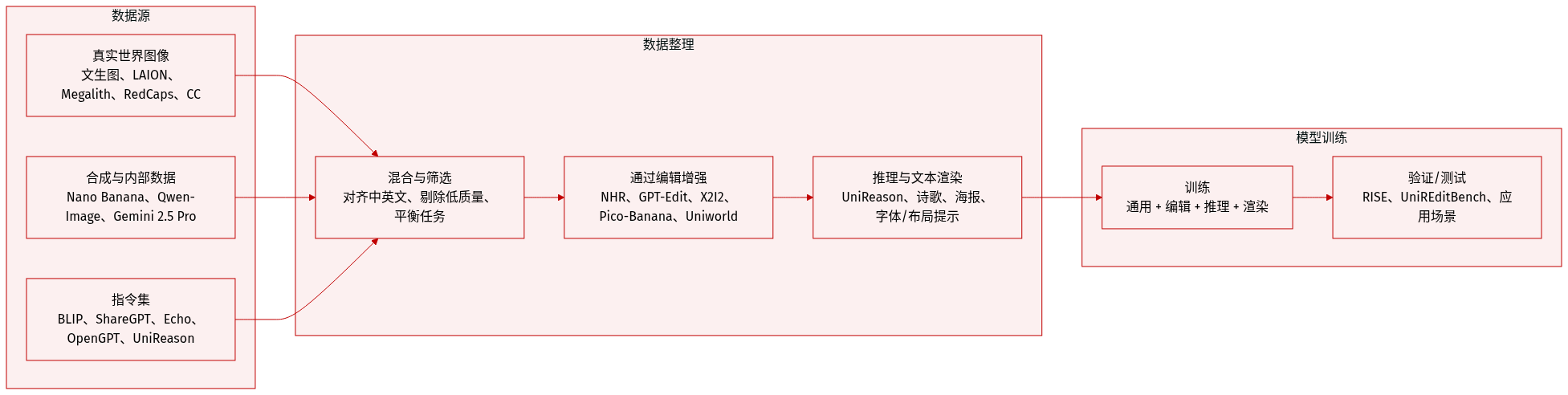
作者利用 VLM-DiT 架构统一多模态理解与高保真图像生成,框架如图所示。系统始于预训练视觉语言模型(VLM),即 Qwen-2.5-VL(30 亿参数),通过其 Transformer 块处理交错的视觉与文本输入(包含系统提示、参考图像和用户指令)。为增强推理能力,向输入序列注入一组固定的可学习“思考标记”,通过自注意力机制在所有 VLM 层中实现隐式思维链行为。这些标记逐步总结隐藏表示,增强模型提取与保留知识的能力。
作者未依赖单层 VLM 输出,而是引入堆叠通道桥接(SCB)框架聚合多层特征。在低、中、高层 VLM 块中均匀采样六个隐藏状态,保留细粒度视觉细节与语义抽象。这些选中的状态(含思考标记表示)沿通道维度堆叠,经轻量 MLP 投影以匹配 DiT 输入宽度。随后,Transformer 编码器将这些多层特征融合为强健的条件输入 c∈RL×dDiT,形式化为:
c=Encoder(MLP(Concatch(x1,…,xn))).该条件信号输入 DiT 解码器——初始化自 SD3.5-Medium(20 亿参数)——通过一系列 DiT 块,结合多模态上下文与噪声潜在输入生成图像。DiT 进一步由 VAE 编码器引导以实现潜在空间对齐,并由噪声精炼器进行迭代优化。整个流程通过基于 SigLIP 和六层 Transformer 的精简连接模块连接,保持 50 亿参数的紧凑规模。
训练分两个主要阶段。第二阶段,作者在涵盖通用文生图、推理生成、文本渲染与图像编辑的多样化多任务数据集上进行 40 万步联合监督微调。为保留 VLM 预训练能力,采用 LoRA 进行参数高效适配。图像以 512×512 分辨率处理,动态保持宽高比,优化使用 5×10−5 学习率与 2 万预热步数。
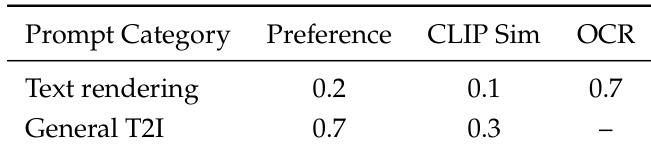
第三阶段,通过 MR-GRPO 框架应用强化学习,使输出对齐人类偏好。模型每条提示采样 G=8 张图像,使用保持噪声水平的随机采样器确保奖励信号稳定。每张生成图像由三个互补奖励函数评估:基于 VLM 的成对偏好模型评估语义与视觉质量,OCR 奖励评估文本渲染准确性,CLIP 相似度评分评估整体对齐。奖励按组归一化,并按类别加权聚合——文本渲染提示优先 OCR,通用生成优先偏好奖励。
策略优化目标结合 GRPO 与辅助监督扩散损失,防止能力退化:
Ltotal=(1−λ)LGRPO+λLSFT,其中 LGRPO 包含在速度空间中计算的裁剪优势项与 KL 正则化:
DKL(πθ∣∣πref)=∣∣v^θ(xt,t)−v^ref(xt,t)∣∣2.训练运行 1500 步,学习率 2×10−6,每样本使用 50 步去噪,批内优势归一化以保持多奖励粒度。
实验
- 对齐预训练成功仅用连接模块与思考标记桥接 VLM 与 DiT,无需完整模型微调即可实现基础文生图与编辑能力。
- DeepGen 1.0 在通用生成与编辑基准测试中表现优异,尽管仅 50 亿参数,仍匹配或超越更大模型,展示强大的语义对齐与指令遵循能力。
- 模型在世界知识任务上取得顶级推理性能,超越开源同行,并在文化、科学与逻辑领域缩小与闭源系统的差距。
- 基于推理的编辑在真实与游戏世界场景中表现稳健,在关键基准测试中领先,部分超越闭源模型整体性能。
- 强化学习训练显著提升文本渲染,提高词准确率与可读性,同时保持语义对齐,验证强化学习框架的有效性。
- 消融研究确认堆叠通道桥接、思考标记与 VLM 激活对性能至关重要,尤其在推理任务中,通过丰富多模态条件与知识蒸馏提升效果。
- 强化学习训练的稳定性与有效性依赖辅助 SFT 损失、KL 正则化与奖励级优势归一化,共同防止能力漂移并确保多目标优化平衡。
作者在 T2I-CoREBench 基准测试上评估 DeepGen 1.0 的推理型文生图能力,涵盖八个不同推理类别。结果显示,仅 50 亿参数的 DeepGen 1.0 在多数推理类型中匹配或略超更大开源模型,整体得分具有竞争力,展示其紧凑规模下的广泛推理能力。
作者采用多目标奖励框架平衡文本渲染与通用图像生成,对通用 T2I 任务赋予更高偏好权重,同时依赖 OCR 准确率专门引导文本合成。结果表明,该方法在生成时优先整体图像质量,同时通过定向信号对齐实现精确文本渲染。
作者通过消融关键组件评估 DeepGen 1.0 的架构,发现移除堆叠通道桥接、思考标记或 VLM 激活时,生成、编辑与推理基准测试性能均一致下降。结果表明,思考标记对推理任务贡献最大,而堆叠通道桥接与 VLM 激活支持更广泛的多模态对齐。这些发现确认每个组件在维持模型整体能力中扮演独特且必要的角色。

作者通过消融辅助 SFT 损失、KL 正则化与奖励级优势归一化,评估 DeepGen 1.0 中关键强化学习组件的影响。结果表明,移除任一组件均导致生成与编辑基准测试性能明显下降,其中辅助 SFT 损失对保持训练稳定性与防止能力退化尤为关键。完整 RL 配置始终优于消融变体,证实这些组件协同优化多目标学习。

作者在 CVTG-2K 基准测试上评估 DeepGen 1.0 的文本渲染能力,对比闭源与开源模型。结果表明,尽管仅 50 亿参数,DeepGen 1.0 仍取得有竞争力的 CLIPScore,并在强化学习训练后显著提升词准确率,超越多个更大开源模型,同时保持强语义对齐。