Command Palette
Search for a command to run...
Mobile-Agent-v3.5:多平台基础GUI Agent
Mobile-Agent-v3.5:多平台基础GUI Agent
摘要
本文介绍了最新推出的原生GUI智能体模型GUI-Owl-1.5,该模型支持多种尺寸(2B/4B/8B/32B/235B),并提供指令(instruct)与思维(thinking)两种变体,可适配桌面、移动设备、浏览器等多种平台,实现云端与边缘端的协同工作以及实时交互。GUI-Owl-1.5在超过20项开源GUI基准测试中取得了当前最优性能,具体表现如下:(1)在GUI自动化任务方面,其在OSWorld上取得56.5分,在AndroidWorld上达到71.6分,在WebArena上获得48.4分;(2)在视觉定位任务中,在ScreenSpotPro基准上取得80.3分;(3)在工具调用任务中,在OSWorld-MCP上获得47.6分,在MobileWorld上取得46.8分;(4)在记忆与知识理解任务方面,在GUI-Knowledge Bench基准上达到75.5分。GUI-Owl-1.5引入了多项关键技术革新:(1)混合数据飞轮(Hybrid Data Flywheel):构建了融合仿真环境与云端沙箱环境的数据流水线,用于提升UI理解与操作轨迹生成的数据采集效率与质量;(2)智能体能力统一增强机制:采用统一的“思维-合成”(thought-synthesis)流水线,系统性提升模型的推理能力,并重点强化关键智能体能力,包括工具/MCP调用、记忆机制以及多智能体协同适应能力;(3)多平台环境强化学习扩展方法:提出一种新型环境强化学习算法MRPO,有效应对多平台间环境冲突问题,并显著提升长时序任务的训练效率。目前,GUI-Owl-1.5模型已开源,用户可通过以下链接体验在线云端沙箱演示:https://github.com/X-PLUG/MobileAgent。
一句话摘要
通义实验室与阿里巴巴集团的研究人员提出了 GUI-Owl-1.5,这是一种可扩展的原生 GUI 代理模型,参数规模涵盖 2B 至 235B,通过混合数据飞轮、统一推理和 MRPO 强化学习等创新,实现云端-边缘实时交互,在 20 多项自动化、定位和工具使用基准测试中超越开源模型。
主要贡献
- GUI-Owl-1.5 引入了一个可扩展的原生 GUI 代理模型系列(2B 至 235B 参数),支持桌面、移动端和浏览器平台,实现云端-边缘实时协作,在包括 OSWorld(56.5)、AndroidWorld(71.6)和 ScreenSpotPro(80.3)在内的 20 多项基准测试中取得当前最优结果。
- 该模型集成了三项核心创新:结合模拟与云端沙盒环境的混合数据飞轮,用于生成高质量轨迹数据;统一思维合成管道,提升推理与工具/记忆能力;以及新型 RL 算法 MRPO,提高多平台、长视野任务的训练效率。
- 基于 Qwen3-VL 构建,并通过扩展动作空间、分层上下文压缩和多智能体协作支持进行增强,GUI-Owl-1.5 在自动化、定位、工具调用和知识任务中展现出强大的现实世界性能,所有模型及云端沙盒演示均已开源。
引言
作者利用 GUI-Owl-1.5 —— 一款参数规模从 2B 到 235B 的原生多模态 GUI 代理模型,实现跨移动、桌面和浏览器界面的自动化,满足日益增长的实时云端-边缘协作代理需求。以往的 GUI 代理在平台支持碎片化、动作空间受限、长视野推理能力差和数据收集效率低等方面存在挑战。为解决这些问题,作者引入了混合数据飞轮以生成高质量合成数据、统一思维合成管道以增强工具使用与记忆能力,以及新型 RL 算法 MRPO 以提升多平台训练效率。该模型在 20 多项基准测试中达到当前最优,并已开源以加速现实世界应用。
数据集
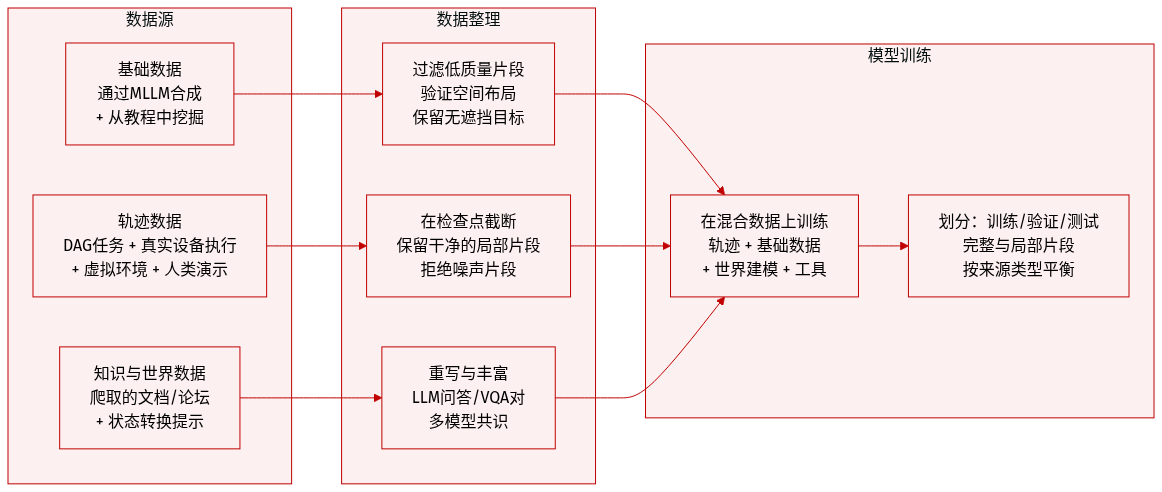
作者使用统一的多源数据集训练 GUI-Owl-1.5,结合真实与模拟环境中的轨迹和定位数据。构建与使用方式如下:
-
数据集组成与来源:
- 定位数据:通过 MLLM 合成复杂应用界面与多窗口布局;通过轨迹挖掘、教程解析和不可行查询生成扩展。
- 轨迹数据:通过基于 DAG 的任务合成、真实设备自动化运行、人类演示和虚拟环境收集,以获取细粒度动作。
- 知识数据:从官方文档、论坛和网络数据集中爬取,重写为 QA/VQA 对,以丰富 GUI 理解。
- 世界建模数据:通过提示模型描述每次动作后的状态转换,教导代理预测 UI 变化。
-
关键子集详情:
- 困难定位数据:使用标注的 UI 元素和 MLLM 合成,通过迭代验证;多窗口场景通过空间约束构建以避免遮挡。
- 扩展定位数据:轨迹挖掘使用判别模型进行质量控制;教程解析提取空间语义 QA 对;不可行查询通过随机配对 + 多模型共识过滤生成。
- 轨迹数据:
- 基于 DAG:任务采样为有向无环图中的路径;模板实例化以支持多样实体。
- 自动化运行:在最后一个有效检查点截断;剩余子任务作为部分轨迹存储,用于干净监督。
- 人类演示:通过云端标注在真实设备上收集未解决任务。
- 虚拟环境:基于网页渲染的模拟器支持滚动/拖拽动作和高频任务;支持 LLM 驱动分解和 RPA 脚本,以生成可扩展、高保真轨迹。
-
训练使用与混合:
- 预训练结合轨迹数据、定位对、QA/VQA 知识、世界建模转换和工具调用数据。
- 轨迹根据检查点验证拆分为完整或部分片段。
- 定位数据混合合成、挖掘和增强来源,覆盖可行与不可行查询。
-
处理与裁剪:
- 定位合成包括空间验证,确保目标元素可见。
- 轨迹在验证检查点截断,避免噪声标签。
- 虚拟环境提供精确反馈,支持基于脚本的运行以生成标准动作。
- 所有数据均经 LLM 重写或过滤(如判别模型、多模型共识),确保保真度与相关性。
方法
作者采用多阶段训练范式开发 GUI-Owl-1.5,该多平台 GUI 代理具备长视野推理、工具调用和跨设备编排能力。系统初始化自 Qwen3-VL,经历监督微调后进行强化学习,架构增强旨在支持复杂现实世界代理行为。
代理决策的核心是多轮交互框架,将 GUI 控制视为闭环决策过程。在每一步 t,代理接收视觉观察 It 和自然语言指令 Lt,生成动作结论 Ct 和结构化工具调用 Ar。动作空间显著扩展,超越原始 GUI 操作,包括外部工具调用和 API 调用,支持与数据库和第三方服务等异构系统集成。参见框架图,该图说明系统消息定义可用动作空间,用户消息包含任务指令和压缩历史,响应消息包含代理推理、动作摘要和最终输出。
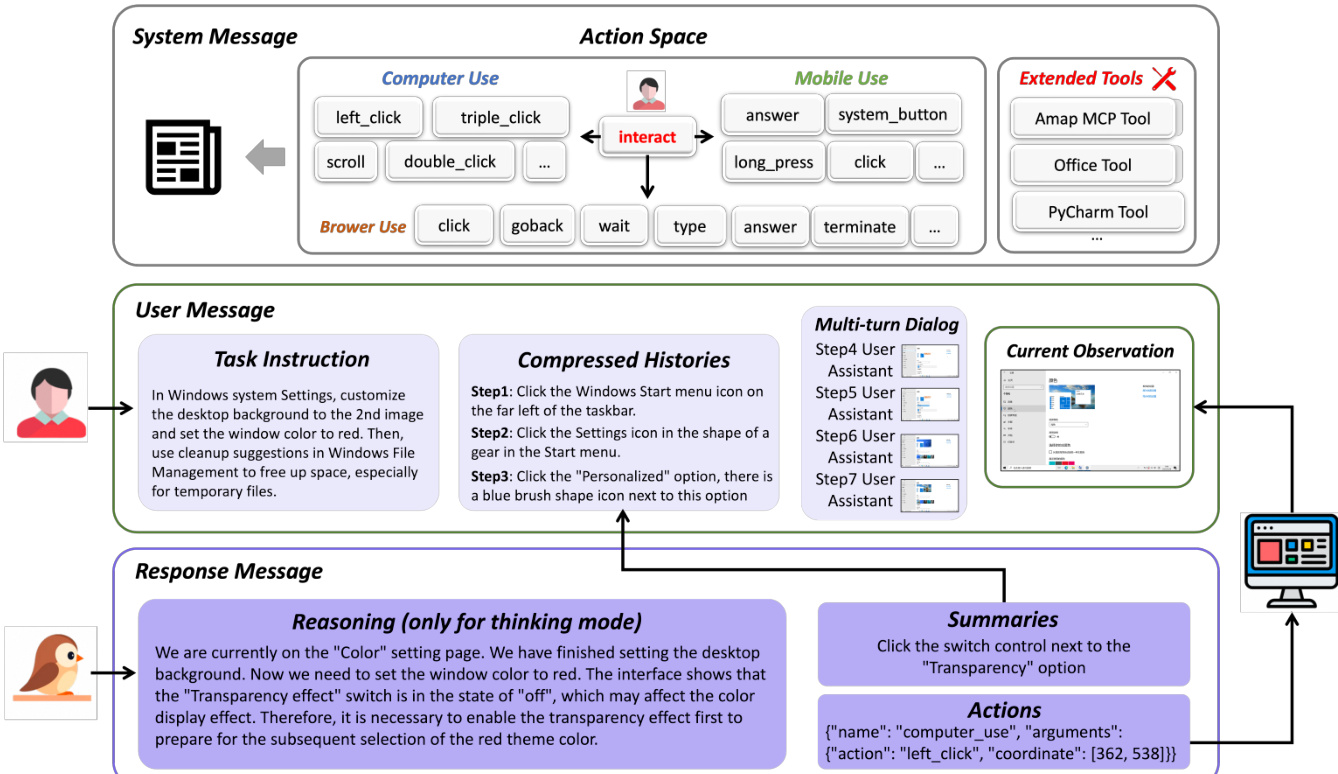
为高效管理长视野任务,代理采用分层上下文压缩机制。最近 N 轮对话完整保留,以保持多模态保真度,而更早交互压缩为文本摘要 S1:t−N−1,通过拼接先前动作结论形成。此设计在即时决策精度与长期任务意识间取得平衡。
三种互补策略增强代理能力:GUI 知识注入、统一 CoT 合成和多智能体协作。统一 CoT 合成管道通过逐步推理、记忆和反思增强轨迹数据。对于每个轨迹步骤,视觉语言模型(VLM)提取与查询相关的屏幕内容,并通过比较动作前后截图评估执行动作是否符合预期。若结果一致,则更新任务进度;否则生成错误修正。这些观察、反思和记忆更新输入 LLM,合成思维(模拟代理推理)和结论(简洁动作决策)。若涉及工具调用,工具定义也提供给 LLM 以指导工具选择。
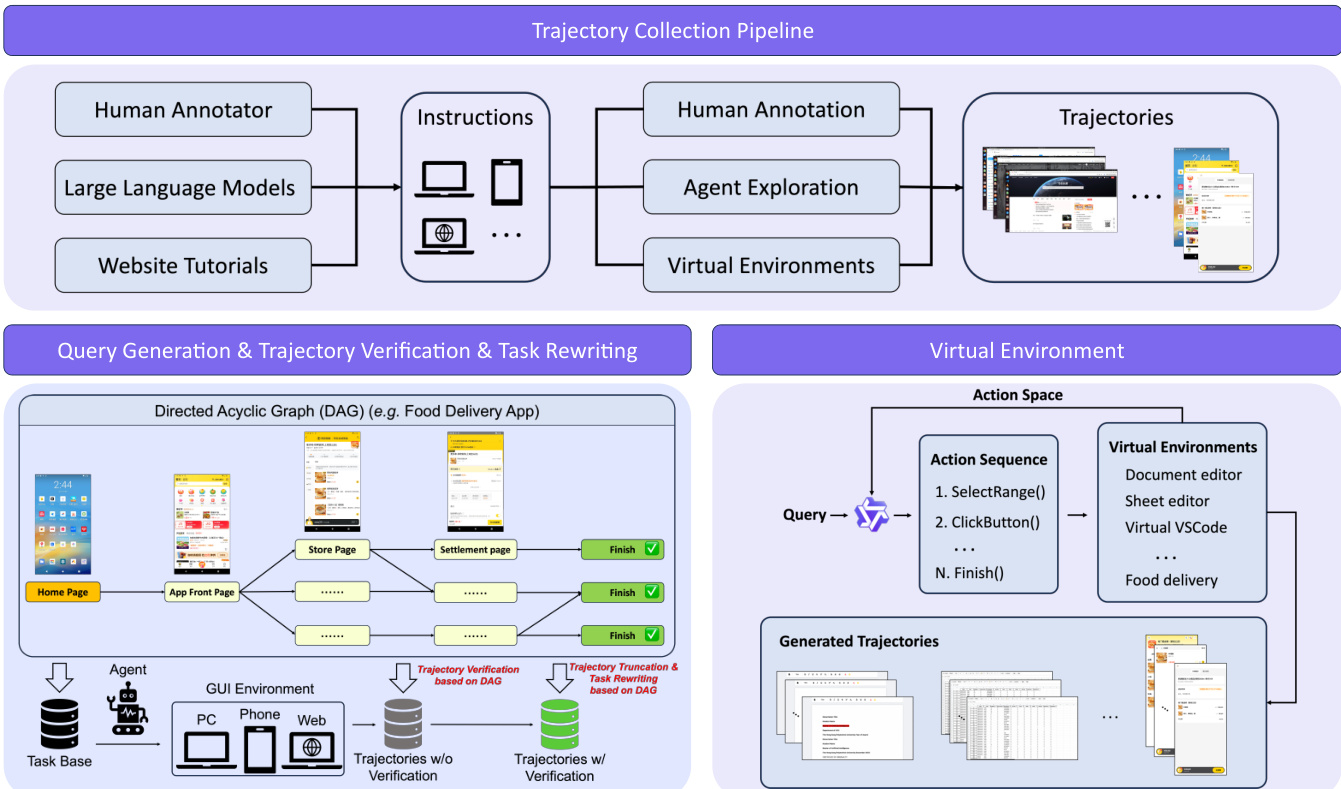
基于 Mobile-Agent-v3.5 的多智能体协作框架将代理功能分解为四个专业角色:管理者(规划者)、工作者(执行者)、反思者(验证者)和记录者(记忆者)。管理者将用户指令分解为子目标,并使用可选检索的外部知识 KRAG 动态更新。工作者在当前上下文(包括子目标、反馈和持久笔记)条件下生成动作。反思者在每次动作后评估转换并提供诊断反馈 Ft=(jt,ϕt),其中 jt∈{SUCCESS,FAILURE}。记录者仅在成功转换时更新持久记忆 Nt,确保关键信息保留以供后续步骤使用。系统循环此流程,直至所有子目标完成或满足终止条件。
训练过程始于监督微调(SFT),使用标注 CoT 的多样化轨迹数据、增强定位数据、结构化工具调用监督和浏览器交互数据。此阶段使预训练模型对齐多设备 GUI 操作、工具调用和浏览器自动化。随后的强化学习阶段称为 MRPO(多平台强化策略优化),进一步优化代理在异构设备上进行长视野、工具增强控制的能力。为解决分组运行中的结果崩溃和跨设备梯度干扰等挑战,作者引入在线运行缓冲区,过采样轨迹并子采样以保持策略多样性,以及交替优化调度,每阶段仅训练一个设备家族以隔离梯度冲突。
为确保训练与推理一致性,作者实施 token-id 传输:环境不仅返回文本动作负载,还返回推理期间使用的精确 token ID,使训练过程可在执行的相同离散事件上计算对数概率。这保持了 KL 正则化和策略梯度估计器的完整性。

轨迹收集管道整合人类标注、代理探索和虚拟环境以生成多样化训练数据。虚拟环境模拟复杂应用(如文档编辑器和外卖应用),支持生成结构化动作序列和验证轨迹。定位数据通过多窗口、高分辨率管道合成,确保元素无重叠和布局多样性,同时生成不可行定位数据以提升鲁棒性。作者还注入来自官方文档、软件论坛和网络数据集的外部知识,以增强代理的世界建模和任务分解能力。
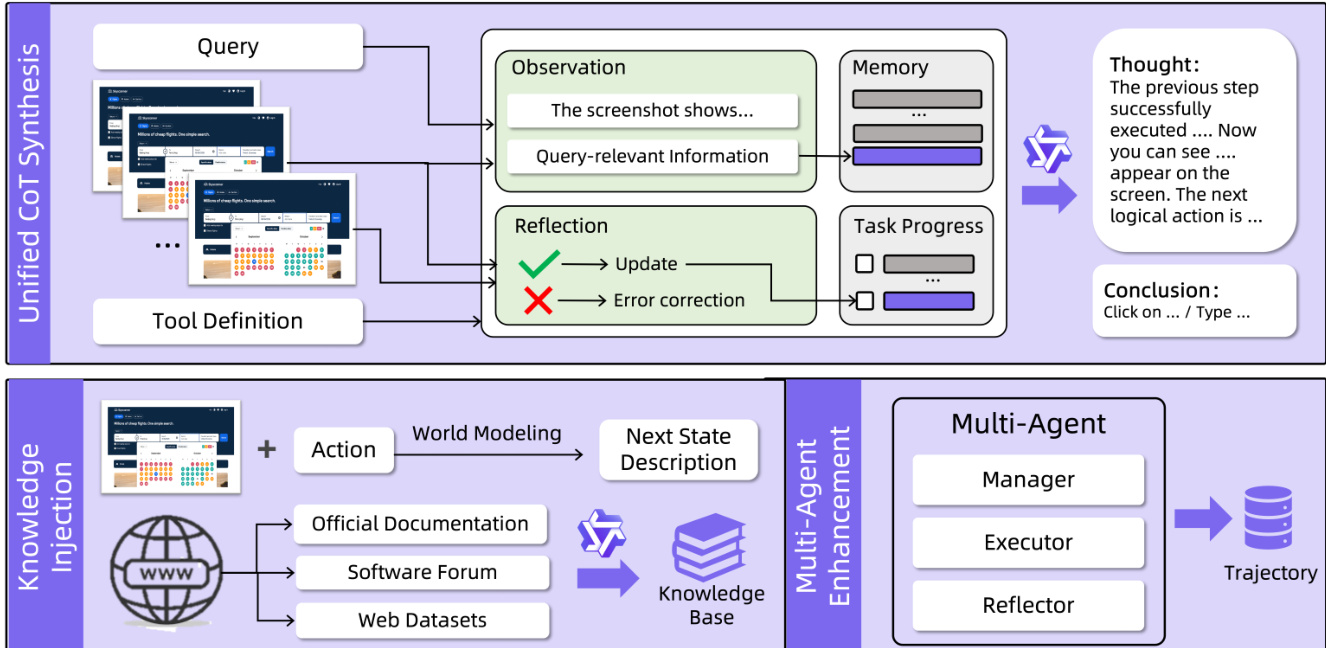
最终架构使 GUI-Owl-1.5 既能作为端到端代理,也能作为多智能体框架中的组件,支持 PC、移动和网页平台的统一控制,优化延迟并实现实时交互。
实验
- GUI-Owl-1.5 在多设备 GUI 自动化中展现当前最优性能,在移动、计算机和浏览器平台的实时环境中,擅长端到端任务执行和多智能体协调。
- 该模型在高分辨率和复杂界面中表现出强大的定位能力,结合裁剪和放大两阶段细化策略时进一步提升。
- 在全面 GUI 理解方面(包括界面感知、交互预测和指令解释)取得顶级结果,同时在长视野记忆保留方面优于先前原生代理。
- 思维变体持续优于指令变体,尤其在需要扩展规划的任务中,验证了基于思维训练的价值。
- 消融研究确认虚拟环境生成的轨迹和统一 CoT 合成在实现稳健推理和多步任务执行中的关键作用。
- 强化学习策略——特别是不稳定任务优先和交错多平台训练——被证明可加速收敛并保持稳定的跨平台性能。
- 案例研究展示了模型处理复杂现实工作流的能力,包括跨应用导航、工具调用、记忆保留和跨设备多步规划。
作者在多个平台上评估 GUI-Owl-1.5,发现其在定位和多平台任务执行方面持续优于通用和专用 GUI 模型。结果表明,更大规模和思维模式变体表现更优,32B-Thinking 模型取得最高综合得分。通过消融研究进一步验证,虚拟环境训练和统一 CoT 合成对其强大的端到端和跨平台能力至关重要。
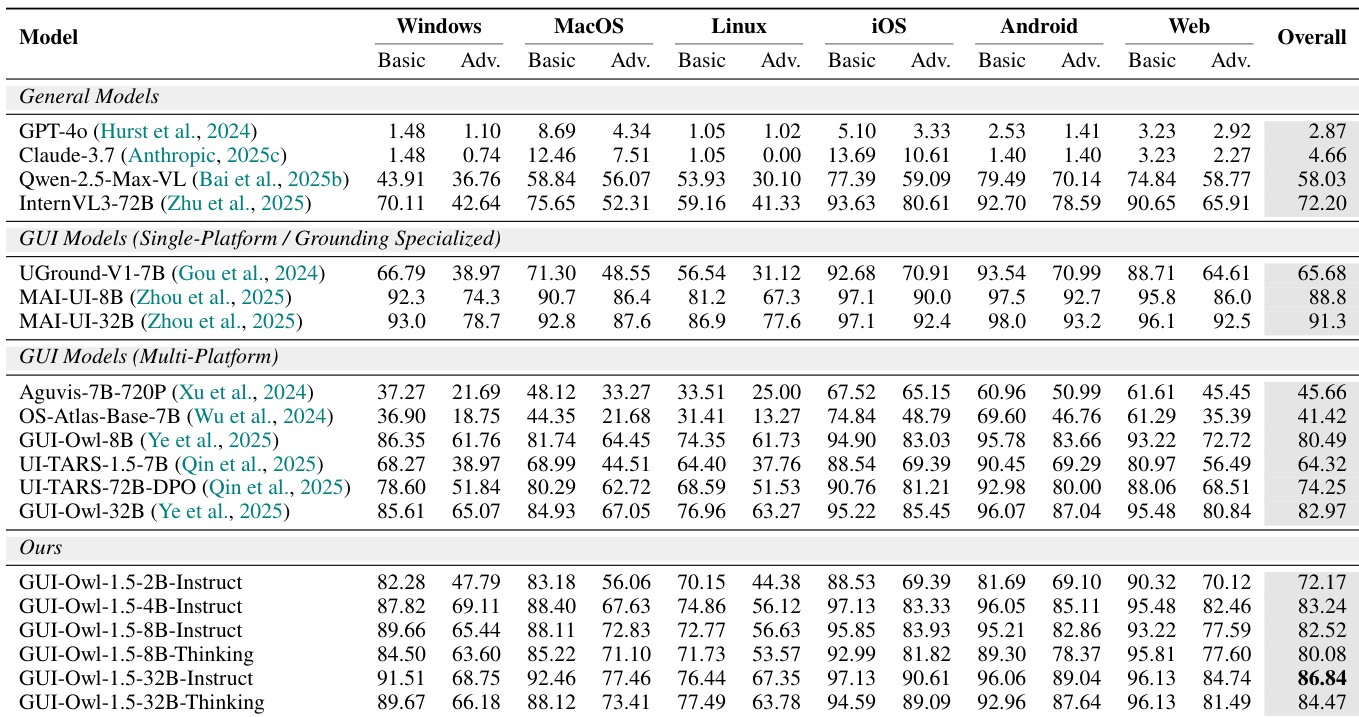
作者在多个平台上评估 GUI-Owl-1.5,发现其在定位任务中持续优于先前的多平台和单平台 GUI 模型,尤其在移动、桌面和网页界面的文本与图标定位方面。结果表明,GUI-Owl-1.5 的更大规模和思维模式变体获得最高综合得分,32B-Thinking 模型达到 95.3,显示强大的跨平台泛化能力和精细感知能力。性能提升突显其训练方法在统一不同界面类型 GUI 理解方面的有效性。

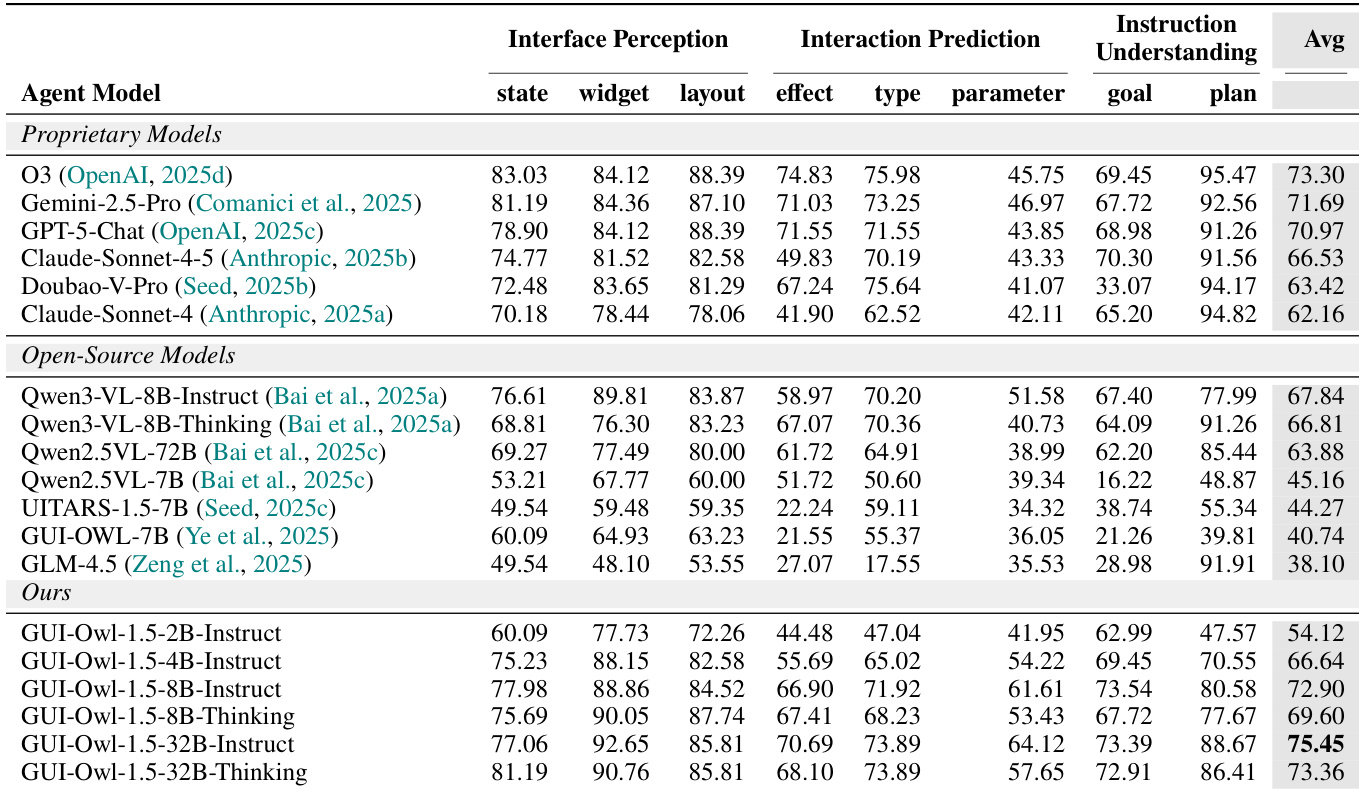
作者从多个维度评估 GUI-Owl-1.5 的 GUI 理解能力,发现其更大规模变体(尤其是 32B 模型)在全面 GUI 知识基准测试中达到当前最优,优于专有和开源同类模型。结果表明,随着模型规模增加和思维变体使用,性能持续提升,表明增强推理监督可提升界面感知、交互预测和指令理解的表现。模型在所有子类别中的强劲表现确认其整合深度 UI 理解与任务规划执行的能力。
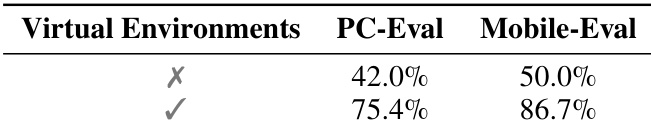
作者使用虚拟环境生成高质量训练轨迹,显著提升桌面和移动端评估基准的性能。移除该组件导致准确率大幅下降,证实其在克服现实世界探索限制和实现可扩展有效训练中的关键作用。
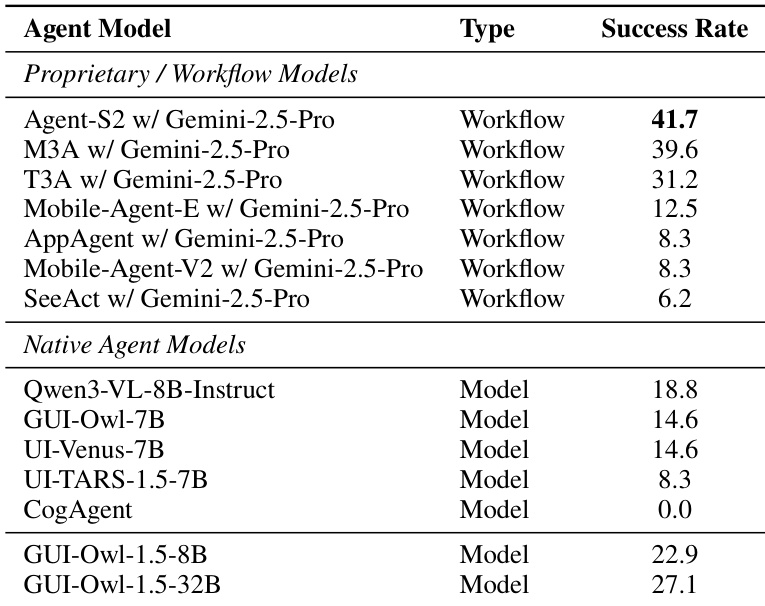
作者在多个基准测试中评估 GUI-Owl-1.5,发现其原生代理变体显著优于专有工作流系统和其他开源模型,32B 版本在 27.1 的成功率上达到最高。结果表明,更大参数量与更强性能相关,GUI-Owl-1.5 的架构使其超越依赖外部编排或小规模训练的模型。这些发现确认其端到端训练方法在处理复杂多步 GUI 自动化任务中的有效性。