Command Palette
Search for a command to run...
字节跳动:基于二进制标记的自回归生成模型扩展
字节跳动:基于二进制标记的自回归生成模型扩展
Yuang Ai Jiaming Han Shaobin Zhuang Weijia Mao Xuefeng Hu Ziyan Yang Zhenheng Yang Huaibo Huang Xiangyu Yue Hao Chen
摘要
我们提出 BitDance,一种可扩展的自回归(Autoregressive, AR)图像生成模型,该模型直接预测二进制视觉标记(binary visual tokens),而非传统的码本索引(codebook indices)。通过采用高熵的二进制潜在表示,BitDance 使得每个标记最多可表示 2256 种状态,从而实现紧凑但极具表达力的离散化图像表征。然而,如此庞大的标记空间使得传统的分类方式难以高效采样。为解决这一难题,BitDance 引入了二进制扩散头(binary diffusion head):与使用 softmax 预测索引不同,该方法在连续空间中通过扩散过程生成二进制标记。此外,我们提出了一种新的解码方法——逐块并行扩散(next-patch diffusion),该方法能够高精度地并行预测多个标记,显著加速推理过程。在 ImageNet 256×256 数据集上,BitDance 达到了 1.24 的 FID 分数,是当前自回归模型中的最优表现。结合 next-patch diffusion 技术,BitDance 在仅使用 260M 参数(仅为 1.4B 参数的 5.4 倍)的情况下,超越了当前最先进的并行自回归模型,并实现了 8.7 倍的推理速度提升。在文本到图像生成任务中,BitDance 在大规模多模态标记上进行训练,能够高效生成高分辨率、逼真的图像,展现出优异的性能与良好的可扩展性。当生成 1024×1024 分辨率图像时,其推理速度相比以往自回归模型提升了超过 30 倍。为推动自回归基础模型的进一步研究,我们已公开项目代码与预训练模型。相关资源请访问:https://github.com/shallowdream204/BitDance。
一句话总结
来自字节跳动、香港中文大学和中科院的研究人员提出了 BitDance,这是一种使用二进制 token 和扩散头的 AR 图像生成器,采样效率高,参数减少 5.4 倍,速度提升 8.7 倍,在高分辨率文本到图像生成任务中表现优异,FID 达到当前最优水平。
主要贡献
- BitDance 引入了一种可扩展的自回归图像生成器,通过每个 token 最多 2256 个状态的二进制视觉 token 进行预测,实现高保真重建,同时避免了离散 VQ 方法中常见的码本坍塌和量化误差。
- 为高效采样如此庞大的 token 空间,BitDance 用二进制扩散头替代 softmax 分类,并引入“下一块扩散”,允许并行多 token 预测,相比先前的并行 AR 模型参数减少、推理加速高达 8.7 倍。
- 在 ImageNet 256×256 和文本到图像任务上评估,BitDance 在 AR 模型中实现 1.24 的最优 FID,生成 1024×1024 图像时速度提升超过 30 倍,同时参数比竞争的 14 亿参数模型少 5.4 倍。
引言
作者采用二进制视觉 token(而非离散码本索引)构建 BitDance,这是一种高度可扩展的自回归图像生成器,可实现紧凑且高熵的表示,每个 token 最多编码 2256 个状态。先前的离散分词器存在量化误差和内存密集型熵损失,而 AR 模型中的连续 token 方法在长序列生成过程中面临误差累积和漂移。BitDance 通过引入二进制扩散头进行 token 生成、以及“下一块扩散”实现并行多 token 预测,克服了这些问题,相比先前的并行 AR 模型推理速度提升 8.7 倍,参数减少 5.4 倍,并实现最优 FID 分数。它还能高效扩展到 1024×1024 文本到图像生成,速度提升超过 30 倍,使高保真自回归生成在大规模应用中变得可行。
方法
作者提出了一种新颖的自回归架构 BitDance,旨在扩展 token 熵以实现高保真视觉生成,同时保持计算效率。核心创新在于用连续空间的基于扩散的预测机制替代传统的离散分类头,从而实现精确且可扩展的二进制视觉 token 采样。
框架始于基于查找自由量化(LFQ)的二进制视觉分词器,将连续潜在向量 x∈Rd 通过 xq=sign(x) 映射为二进制 token。为防止码本坍塌并最大化熵,应用分组熵损失,将 d 个通道划分为 g 组以实现可计算性。这允许码本大小扩展至 2256,实现与连续 VAE 相当的重建保真度。
对于 token 预测,BitDance 引入二进制扩散头,在连续空间中建模二进制 token 的联合分布。模型不预测离散索引,而是将每个 d 位 token 视为 d 维超立方体上的一个点。给定隐藏状态 z∈Rh,扩散头通过优化速度匹配损失来预测目标 token x∈Rd:
L(z,x)=Et,x,ϵ∥vθ(xt,t,z)−vt∥2,其中 xt=tx+(1−t)ϵ 且 vt=x−ϵ。在推理时,模型初始化 x0∼N(0,I),并通过欧拉求解器在 N 步内积分速度场,随后通过硬二值化 x1=sign(x1) 将输出投影回超立方体顶点。这种几何约束增强了稳定性和收敛性。
请参阅框架图,该图展示了在多模态 token 上训练的 BitDance 架构。输入图像被编码为二进制潜在变量,通过块式光栅扫描展平为一维序列,并由自回归 Transformer 处理。二进制扩散头支持每步高效并行预测多个 token。
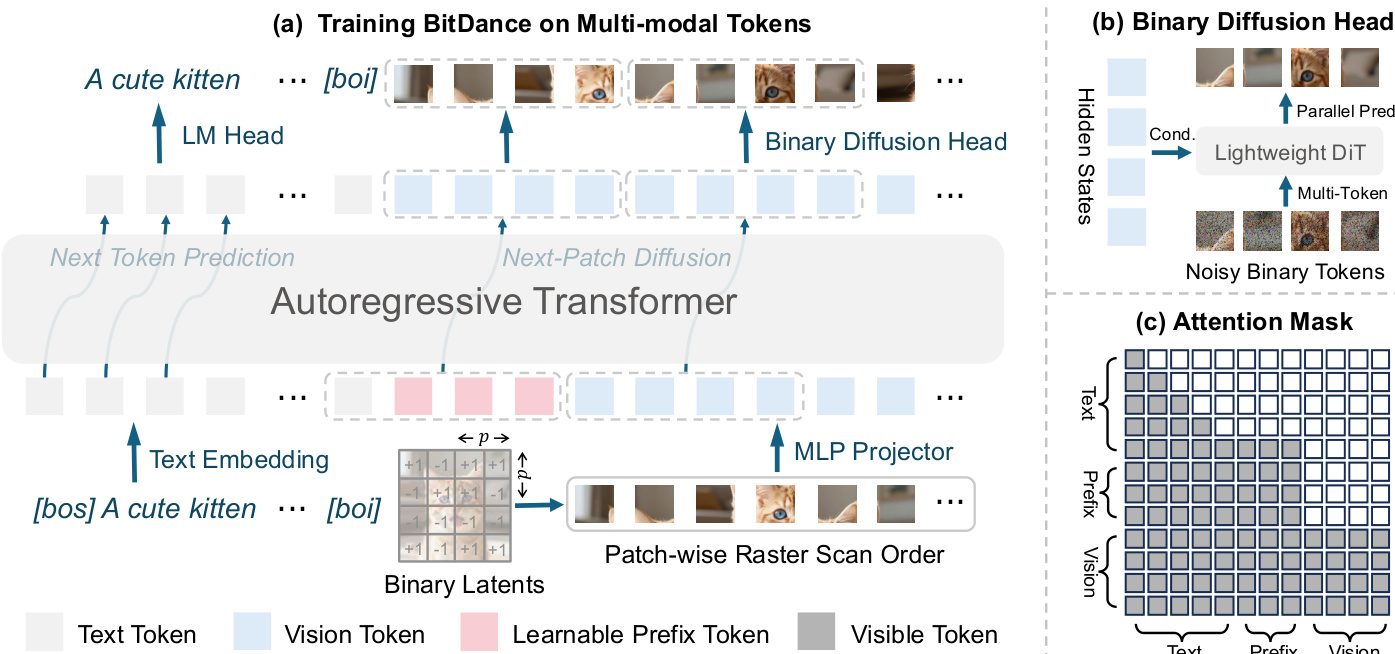
为加速生成,BitDance 采用“下一块扩散”范式。模型不逐个预测 token,而是将序列划分为 M 个 p×p token 的块,并联合预测每个块。这通过块式因果注意力掩码实现,允许块内 token 相互关注,同时保持块间的自回归依赖。为此,视觉序列前添加了 p2−1 个可学习前缀 token。
二进制扩散头通过将速度匹配损失扩展至以隐藏状态 Z∈Rp2×h 为条件的 token 块 X∈Rp2×d 来支持多 token 预测:
Lparallel=Et,X,ϵ∥vθ(Xt,t,Z)−vt∥2.预测网络 fθ 实现为轻量级 DiT,以高效建模 p2 个 token 的联合分布。该设计弥合了先前并行 AR 模型中存在的训练-推理差距,这些模型尽管建模联合分布,却依赖独立 token 采样。
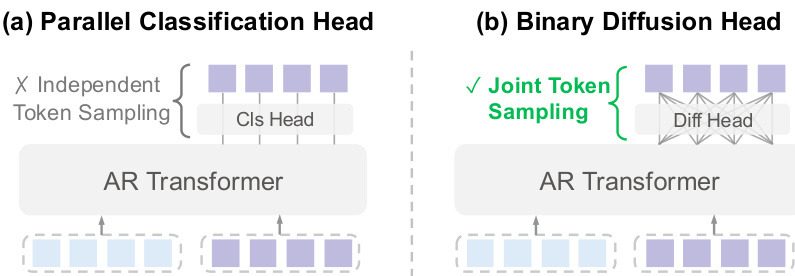
如下图所示,二进制扩散头支持联合 token 采样,而并行分类头则独立采样 token,违反了所需的联合分布。
对于文本到图像生成,BitDance 基于预训练 LLM(Qwen3-14B)构建,同时作为文本编码器和图像生成器。模型通过三阶段管道训练:预训练、持续训练和监督微调,使用混合分辨率训练(256px、512px、1024px)以确保稳定性和泛化能力。蒸馏阶段进一步将并行性从 16 提升至每步 64 个 token。训练损失结合了扩散头的视觉损失和文本损失(交叉熵),权重为 1:0.01,并通过 10% token 丢弃启用无分类器引导。
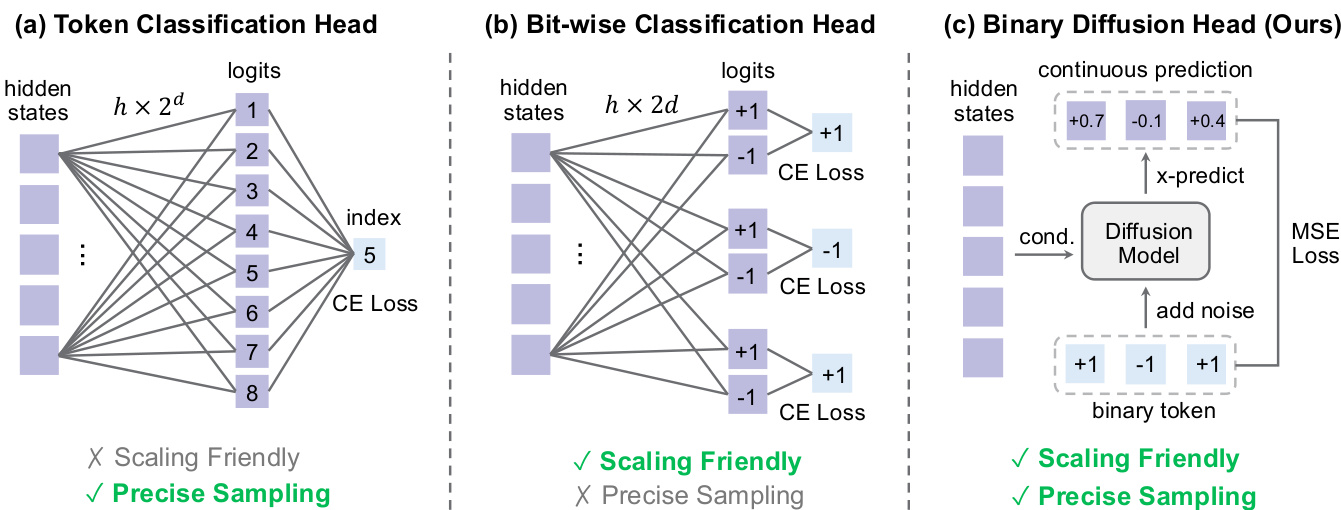
二进制扩散头的有效性源于二进制 token 作为超立方体顶点的几何结构。这种有限且方向受限的空间提供了强正则化,相比无约束连续潜在空间降低了优化复杂性并提高了采样稳定性。如二进制 token 采样范式比较所示,扩散头实现了高效扩展和精确采样,克服了基于索引和按位分类方法的局限性。
实验
- 扩展 token 熵可提升离散分词器的重建效果,匹配或超越连续模型,尤其在较大码本和下采样比例下表现更优。
- 更大的自回归 Transformer 能更好利用增加的词汇量,表明模型规模需随 token 熵增长以实现最佳生成性能。
- BitDance 在 ImageNet 和文本到图像基准测试中达到或接近最优水平,优于更大的并行 AR 模型,同时使用更少参数和更少训练数据。
- 二进制扩散头支持高效并行 token 生成,使用少量采样步数即可保持高质量,并隐式学习离散分布,无需显式约束。
- 消融实验证实二进制分词优于连续 VAE,块式光栅扫描和块因果掩码有效,且其他采样头存在局限。
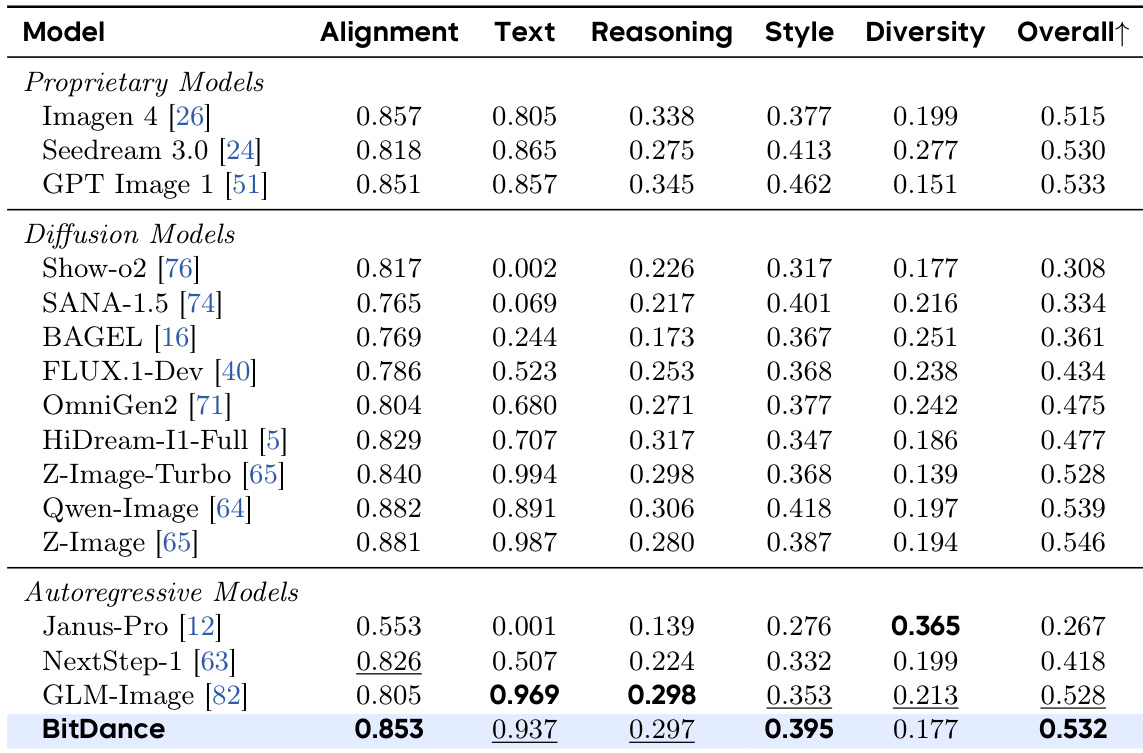
- BitDance 展示出强大的数据效率,尽管训练数据量级更少,仍能匹配专有模型,并在提示遵循、文本保真度和推理速度方面表现优异。
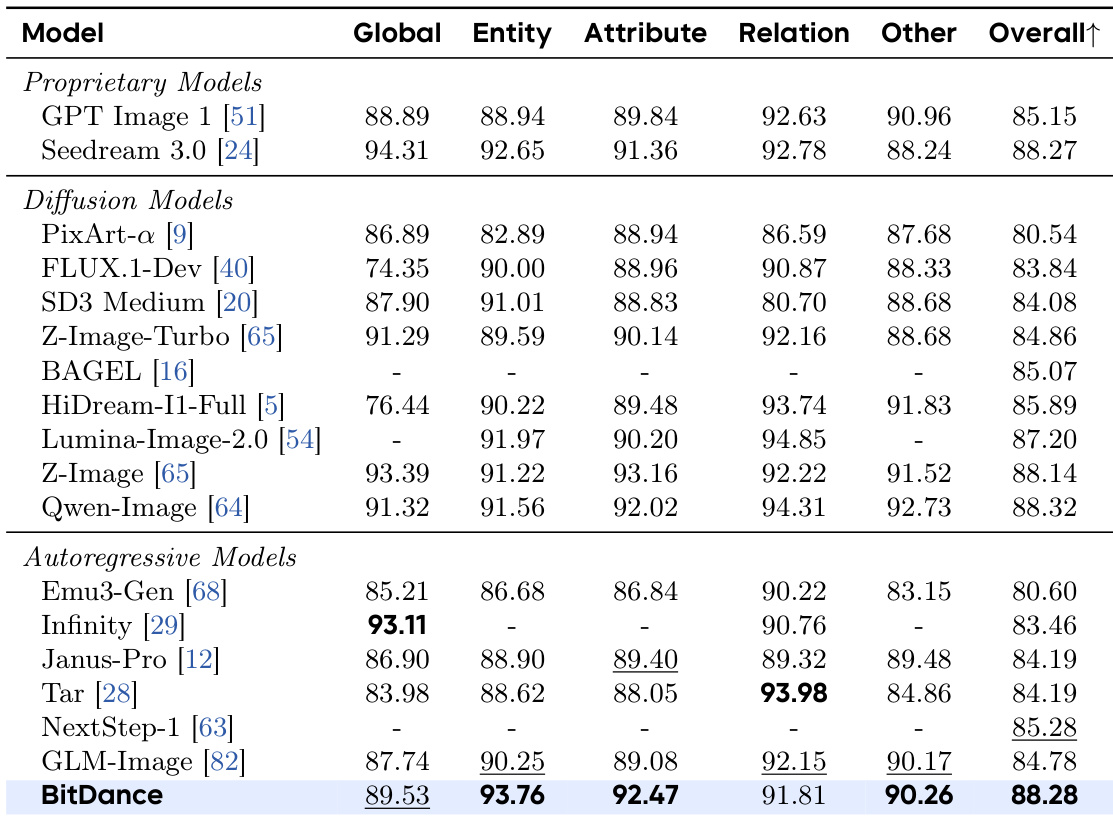
结果表明,BitDance 在文本到图像生成基准测试中达到自回归模型中的最优性能,尽管训练数据显著更少,仍能匹配或超越许多专有和基于扩散的系统。模型在提示遵循、文本渲染和跨多个评估维度的推理方面表现出强大能力。其效率和可扩展性使其在保持更快推理速度的同时,缩小了开源与商业模型之间的性能差距。
作者评估了不同采样头用于自回归图像生成,发现二进制扩散头在 FID 和 Inception Score 上均显著优于其他方法。虽然 token 分类因内存限制失败,按位分类因假设过于简化而表现不佳,但二进制扩散头通过有效建模离散 token 分布实现了更优质量。结果证实该设计能在最少采样步数下实现稳健、高保真生成。

作者在基准指标上评估了其文本到图像模型的两个变体——SFT 和蒸馏版,结果显示蒸馏版(每步并行生成 64 个 token)在 DPG-Bench 分数上略高,同时保持相当的 GenEval 性能。这表明蒸馏在通过增加并行性实现更快推理的同时,保留了生成质量。

结果表明,BitDance 在文本到图像生成基准测试中达到自回归模型中的最优性能,在提示对齐和文本渲染等关键能力上匹配或超越领先的专有和扩散模型。尽管训练数据显著更少,模型仍能达到这些结果,突显其效率和强泛化能力。其在多个评估维度上的表现强调了其架构在弥合开源与商业系统差距方面的有效性。
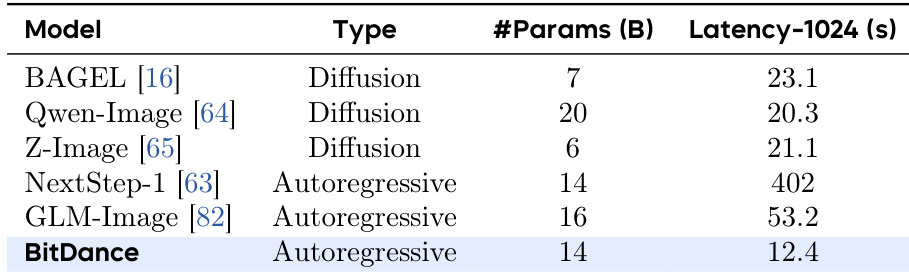
作者将 BitDance 与其他图像生成模型对比,发现其在匹配更大自回归模型参数规模的同时显著降低延迟。结果表明 BitDance 生成 1024×1024 图像的速度快于扩散和自回归基线,突显其推理速度效率。该性能在不牺牲生成质量的情况下实现,如先前基准测试所示。