Command Palette
Search for a command to run...
RLinf-Co:基于强化学习的模拟-现实协同训练用于视觉-语言-动作模型
RLinf-Co:基于强化学习的模拟-现实协同训练用于视觉-语言-动作模型
Liangzhi Shi Shuaihang Chen Feng Gao Yinuo Chen Kang Chen Tonghe Zhang Hongzhi Zhang Weinan Zhang Chao Yu Yu Wang
摘要
仿真为视觉-语言-动作(VLA)模型的训练提供了一种可扩展且低成本的途径,有助于减少对昂贵的真实机器人示范数据的依赖。然而,现有的大多数仿真-现实联合训练方法依赖于监督微调(SFT),将仿真视为静态的示范数据源,未能充分利用大规模闭环交互的优势,因而导致真实世界性能提升和泛化能力受限。本文提出一种基于强化学习(RL)的仿真-现实联合训练框架(RL-Co),在保留真实世界能力的同时,充分利用交互式仿真的潜力。我们的方法采用通用的两阶段设计:首先,利用真实与仿真示范数据的混合数据集对策略进行监督微调以实现热启动;随后,在仿真环境中通过强化学习进一步微调策略,并在真实世界数据上引入辅助监督损失,以锚定策略并缓解灾难性遗忘问题。我们在两个具有代表性的VLA架构(OpenVLA 和 π_{0.5})上,针对四项真实世界桌面操作任务对所提框架进行了评估,结果表明,相比仅使用真实数据的微调以及基于SFT的联合训练方法,本方法在各项任务中均实现了稳定提升,其中OpenVLA在真实世界成功率上提升了24%,π_{0.5}提升了20%。除更高的成功率外,RL联合训练还展现出更强的对未见任务变化的泛化能力,并显著提升了真实世界数据的利用效率。该方法为通过仿真有效增强真实机器人部署提供了一条切实可行且可扩展的技术路径。
一句话总结
来自清华大学、哈工大、北京大学、卡内基梅隆大学和上海人工智能实验室的研究人员提出了 RL-Co,这是一种基于强化学习的仿真-现实协同训练框架,适用于 OpenVLA 和 π₀.₅ 等视觉-语言-动作(VLA)模型。该框架通过交互式仿真结合真实数据正则化,将现实世界成功率提升高达 24%,增强泛化能力并减少对真实数据的需求。
主要贡献
- RLinf-Co 提出了一种面向 VLA 模型的两阶段仿真-现实协同训练框架,结合在混合真实/仿真数据上的监督微调与仿真环境中的强化学习,利用真实世界数据作为辅助损失,防止灾难性遗忘并维持真实机器人能力。
- 该方法通过利用仿真中可扩展的闭环交互,克服了基于静态演示的协同训练的局限性,在保持对现实任务变化泛化能力的同时实现更稳健的策略优化。
- 在 OpenVLA 和 π₀.₅ 上评估四个现实桌面任务,RLinf-Co 相比基于 SFT 的协同训练,现实世界成功率分别提高 +24% 和 +20%,同时提升数据效率和对未见场景的泛化能力。
引言
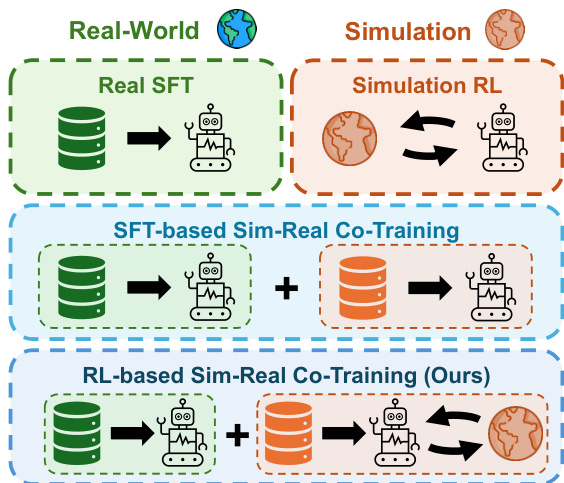
作者利用强化学习,通过仿真-现实协同训练框架提升视觉-语言-动作(VLA)模型,主动利用仿真的交互潜力,与先前将仿真视为静态演示来源的方法不同。尽管现有协同训练方法通过在监督微调下混合真实与仿真数据提升性能,但它们未能解决累积误差问题,也缺乏闭环策略优化——限制了现实世界的泛化能力和数据效率。作者的主要贡献是 RL-Co,一种两阶段方法:首先用混合真实-仿真 SFT 预热策略,然后在仿真中通过 RL 微调,同时使用真实世界数据作为辅助监督信号,防止灾难性遗忘。这带来了现实世界成功率的持续提升、对新任务变体更强的泛化能力,以及显著降低对真实世界演示的依赖——为在物理机器人上部署 VLA 模型提供了一条可扩展且实用的路径。
数据集
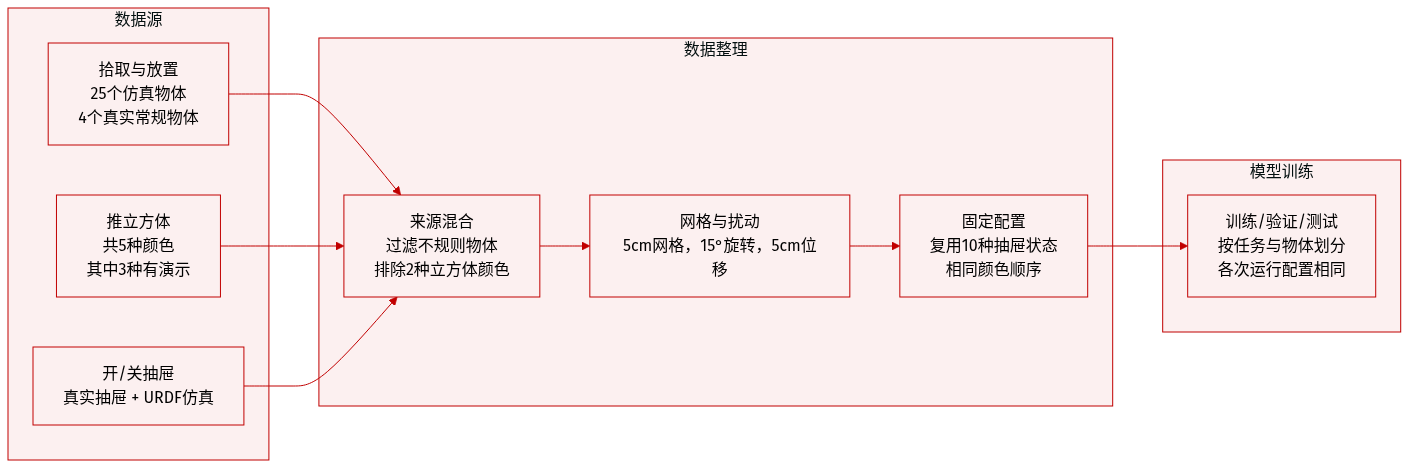
作者使用的数据集包含四个桌面操作任务——拾取放置、推动立方体、打开抽屉和关闭抽屉——在仿真和现实环境中均进行评估。各子集的关键细节如下:
-
拾取放置:
- 仿真:来自 Liu 等人 [42] 的 25 个物体。
- 真实世界:两类物体——规则形状(玩具水果/蔬菜)和不规则形状(碗、手套)。不规则物体被排除在专家演示之外。对于分布内测试,选择四个规则形状物体。
- 初始状态:碗放置在 10×20 cm 区域内;物体放置在 20×25 cm 区域内。两者均离散为 5 cm 网格;相同配置在不同方法间复用。
-
推动立方体:
- 仿真与真实世界:五个彩色立方体。专家演示仅收集了其中三个(紫色、黄色、粉色);橙色和绿色被排除。
- 评估:从五个颜色中随机选择三个。立方体间距 15 cm,然后在 5×5 cm 区域内扰动。所有实验使用相同的颜色排列和空间配置。
-
打开/关闭抽屉:
- 真实世界:图 10 中展示的物理抽屉。
- 仿真:匹配真实抽屉几何结构的 URDF 模型。
- 初始状态:抽屉前缘置于橙色区域(图 11),最多 15° 旋转扰动。打开抽屉时起始约 10 cm 开口。十个预定义配置在评估中共享。
-
机器人初始状态:
- 默认:Franka Panda 初始化为固定姿态(图 8)。
- 泛化(仅限拾取放置):四个物体位置固定。TCP 通过 ±30° 旋转 + 5 cm 平移(前、后、左、右、上)扰动——每个物体五种扰动,如表 III 所示。其他环境设置不变。
数据用于训练和评估,采用固定初始配置以确保公平比较。不进行裁剪;元数据包括物体类型、任务特定区域、扰动和演示排除。所有真实世界物体在图 10 中有视觉记录,初始放置区域在图 11 中可视化。
方法
作者利用两阶段仿真-现实协同训练框架,调整视觉-语言-动作(VLA)策略以适应机器人操作任务。该方法旨在通过结合监督微调(SFT)与仿真中的强化学习(RL),弥合仿真到现实的差距,同时通过辅助监督保持真实世界行为保真度。
请参阅框架图,该图说明了整体架构。流程始于数字孪生设置:对于每个真实世界任务 Treal,构建相应的仿真任务 Tsim,共享相同的机器人形态、动作空间和语言指令,但在视觉纹理和动力学上有所不同。两个任务均建模为部分可观测马尔可夫决策过程(POMDP),VLA 策略 πθ 以 H 个观测历史和语言指令 l 为条件,预测 h 个未来动作序列:
at:t+h−1∼πθ(at:t+h−1∣oΩt−H+1:t,l).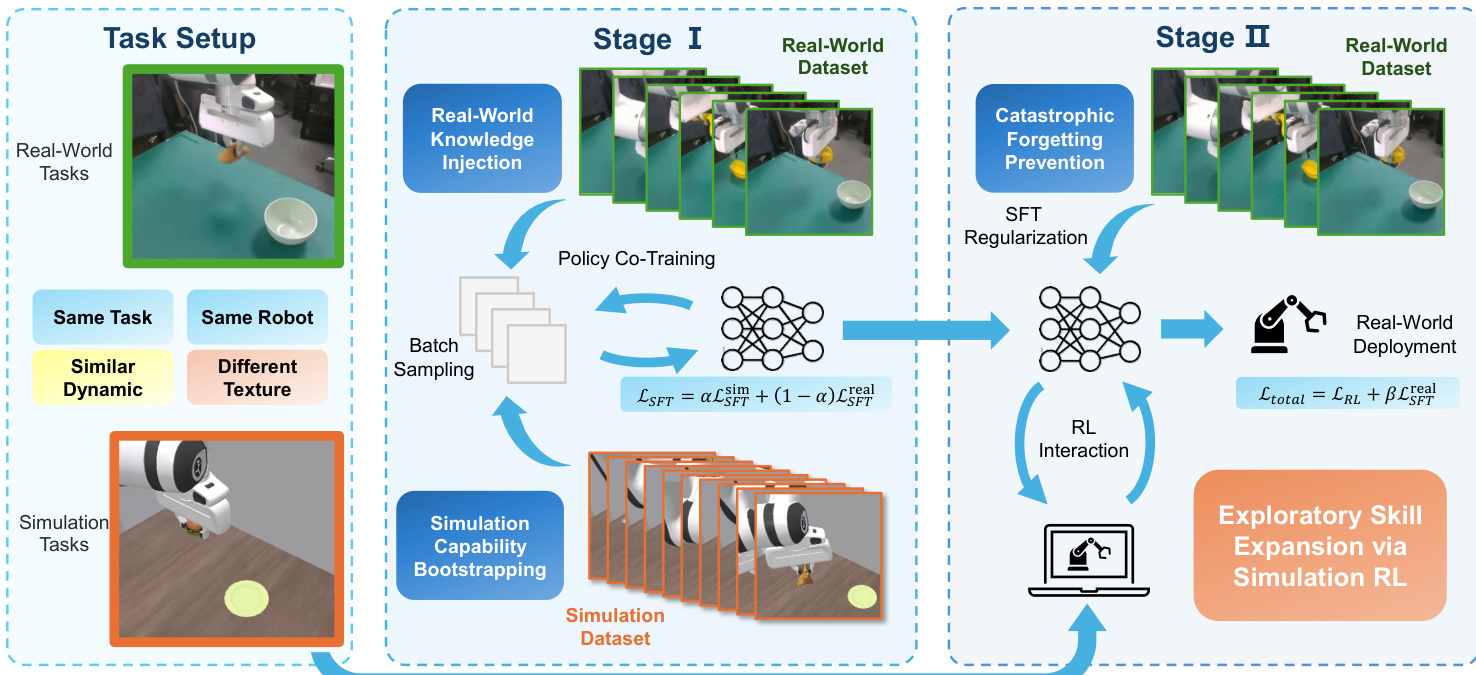
在第一阶段,作者通过基于 SFT 的协同训练初始化策略。从预训练的 VLA 策略 πθ 开始,他们在真实世界和仿真演示数据集 Dreal 和 Dsim 的混合数据上联合优化策略。损失函数是加权组合:
LSFT(θ)=αLSFT(θ;Dsim)+(1−α)LSFT(θ;Dreal),其中 α∈[0,1] 控制训练期间采样的仿真数据比例。此阶段具有双重目的:早期注入真实世界知识以确保可部署性,并引导仿真能力,以便在下一阶段有效进行 RL。
第二阶段引入核心创新:基于 RL 的仿真-现实协同训练,结合真实数据正则化。当策略在仿真环境中通过 RL 最大化期望折扣回报时,作者在标准 RL 损失 LRL 上增加一个在真实世界数据集上计算的辅助 SFT 损失:
Ltotal=LRL+βLSFT(θ;Dreal),其中 β 平衡仿真中的探索与真实世界行为的保持。此正则化防止 RL 微调期间的灾难性遗忘,确保策略在通过仿真交互扩展技能集的同时保留其真实世界能力。该框架对所使用的特定 RL 算法不敏感,可与广泛的策略更新策略集成。
如下图所示,整个流程从第一阶段的真实世界知识注入和仿真能力引导,过渡到第二阶段通过仿真 RL 的探索性技能扩展,最终目标为真实世界部署。作者强调,这种结构化方法在不牺牲真实世界性能的前提下实现可扩展的策略改进。
实验
- RL-Co 在多种操作任务中始终优于仅使用真实世界数据的 SFT 和基于 SFT 的仿真-现实协同训练,展现出更强的现实世界部署性能。
- 该方法通过利用 RL 开发更稳健和可迁移的行为,显著增强了在分布偏移下的泛化能力,包括未见物体和状态。
- 消融研究证实了 SFT 初始化(含仿真数据)和 RL 微调期间真实世界正则化的必要性;移除任一组件都会严重降低性能。
- RL-Co 实现了卓越的数据效率,在仅使用少量真实世界演示数据(通常仅为基线所需数据的 10%)的情况下,达到或超过基线性能。
- 超参数分析表明,协同训练比例和正则化权重显著影响结果,但无论调参如何,RL-Co 始终优于 SFT 基线。
- 仿真数据对于实现高效的 RL 优化至关重要,而真实世界监督锚定策略并防止仿真训练期间的灾难性遗忘。
结果表明,与仅使用真实数据训练和基于 SFT 的协同训练相比,RL-Co 在分布偏移下显著提升了泛化能力,在面对未见物体或初始状态时保持更高的成功率。该方法展现出更强的鲁棒性,在分布外设置中性能下降更小,表明强化学习增强了策略超越监督训练数据的迁移能力。

作者使用 RL-Co 结合仿真交互与真实世界监督,在多个操作任务中实现了一致高于仅使用真实数据训练或基于 SFT 的协同训练的现实世界成功率。结果表明,RL-Co 不仅提升了性能,还增强了在未见条件下的泛化能力,并显著减少了有效训练所需的真实世界数据量。消融研究证实,框架的两个阶段——SFT 初始化和真实世界正则化 RL 微调——对于稳定高效的学习至关重要。

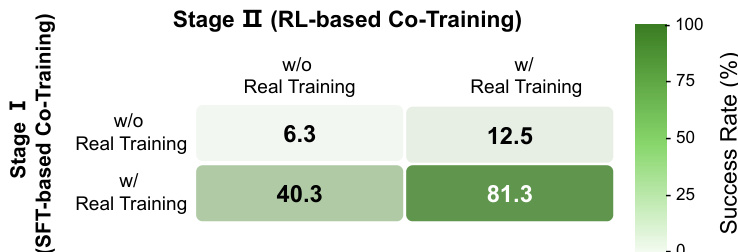
作者使用结合监督微调和强化学习的两阶段框架来提升现实世界机器人性能。结果表明,在两个阶段中包含真实世界数据至关重要,完整的 RL-Co 方法实现了 81.3% 的成功率,远超在任一阶段省略真实数据监督的变体。这突显了在整个训练过程中保持真实世界基础的必要性,以防止性能崩溃并实现有效的仿真到现实迁移。