Command Palette
Search for a command to run...
查询作为锚点:基于大语言模型的场景自适应用户表征
查询作为锚点:基于大语言模型的场景自适应用户表征
摘要
工业级用户表征学习需在强普适性与高任务敏感性之间取得平衡。然而,现有范式通常生成静态、任务无关的嵌入表示,难以在统一向量空间中协调下游场景的多样化需求。此外,异构多源数据固有的噪声与模态冲突进一步削弱了表征质量。为此,我们提出 Query-as-Anchor 框架,将用户建模从静态编码转向动态、查询感知的融合生成。为赋予大语言模型(LLM)深层次的用户理解能力,我们首先构建了 UserU——一个工业规模的预训练数据集,其将多模态行为序列与用户理解语义进行对齐;在此基础上,Q-Anchor 嵌入架构通过联合对比-自回归优化机制,将分层的粗粒度至细粒度编码器融入双塔式 LLM 架构,实现查询感知的用户表征。为弥合通用预训练与特定业务逻辑之间的差距,我们进一步引入基于聚类的软提示调优(Cluster-based Soft Prompt Tuning),以强制模型学习具有判别性的潜在结构,有效引导模型注意力聚焦于场景特定的模态特征。在部署层面,将锚定查询置于序列末端,可实现基于 KV 缓存加速的推理,带来可忽略的额外延迟。在支付宝的10项工业级基准测试中,该方法展现出持续领先的性能表现、优异的可扩展性以及高效的部署能力。在支付宝生产系统中针对两个真实业务场景开展的大规模在线 A/B 测试,进一步验证了其实际应用效果。相关代码已准备就绪,即将公开发布,地址为:https://github.com/JhCircle/Q-Anchor。
一句话总结
蚂蚁集团与浙江大学的研究人员提出了 Q-Anchor,一种动态查询感知的用户表征框架,通过分层编码器与软提示调优将多模态行为数据与大语言模型(LLM)结合,超越静态嵌入,在 10 个支付宝基准测试和真实 A/B 测试中验证了其高效、可扩展的部署能力。
主要贡献
- 我们引入了 UserU,一个工业级预训练数据集,通过未来行为预测与问答监督将多模态用户行为与语义理解对齐,使 LLM 能够在稀疏异构数据下学习鲁棒、泛化性强的用户表征。
- 我们提出 Query-as-Anchor,一个动态框架,通过基于自然语言查询条件化 LLM 双塔编码器生成场景特定的用户嵌入,使单一模型无需重训练即可自适应服务于多样下游任务。
- 我们实现了基于聚类的软提示调优与 KV 缓存加速推理,以强制区分性潜在结构并维持低延迟部署,经 10 个支付宝基准测试与线上 A/B 测试验证达到 SOTA 结果。
引言
作者利用大语言模型解决静态、任务无关用户嵌入在跨场景适应性与噪声稀疏行为数据方面的局限。先前方法要么生成不适合多样下游任务的固定表征,要么未能弥合以语言为中心的 LLM 预训练与符号化用户日志之间的模态鸿沟。其主要贡献是 Query-as-Anchor 框架,通过自然语言查询条件化 LLM 动态生成场景特定用户嵌入,辅以 UserU —— 一个包含行为预测与问答监督的大规模预训练数据集 —— 并通过基于聚类的软提示调优优化,实现高效低延迟推理。这使得无需重训练即可在营销、风控与用户参与等任务中实现统一、自适应的用户建模。
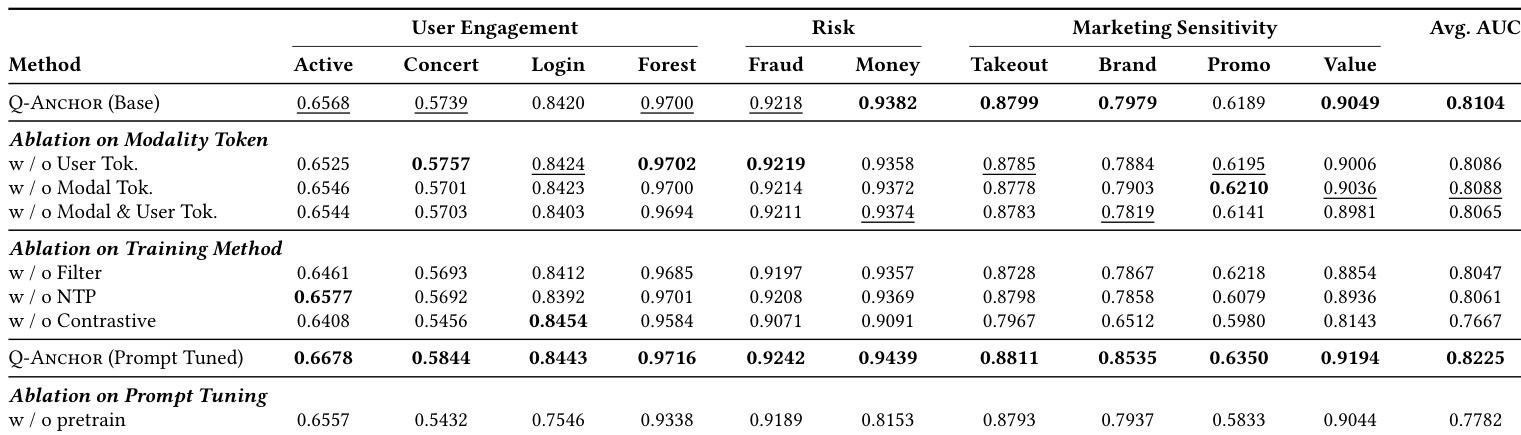
数据集
- 作者使用 UserU 预训练数据集,通过结合行为预测与合成问答数据,提升用户嵌入在多样任务中的表现。
- 数据集包含两个主要子集:D_future(行为预测)与 D_uqa(LLM 生成的用户查询与答案)。
- D_future 包含从三个月用户行为画像中导出的 N 个样本,通过频率与多样性感知选择聚合为未来行为摘要;每个样本将用户画像 + 固定模板查询与预测未来行为配对。
- D_uqa 包含 M 个由 LLM 生成的合成样本:对每个用户画像,模型检索 10 个相关生活主题,生成基于事实的查询,并通过生成后反思步骤确保答案忠实性与上下文有效性。
- 输入数据包括异构来源如账单交易、小程序日志、应用列表与搜索查询,编码为分层用户标记,后接可选指令与 <USER_EMB> 标记以指示嵌入提取。
- 作者使用两个子集混合训练,未明确比例,但强调预训练与下游任务解耦以提升泛化能力。
- 未进行裁剪;相反,用户画像通过与查询拼接实现上下文化,所有数据均匿名化或合成以保障隐私。
- 下游评估使用 10 个真实二元分类任务,每任务约 50 万测试样本,标签根据用户是否在预测窗口内触发目标事件分配。
方法
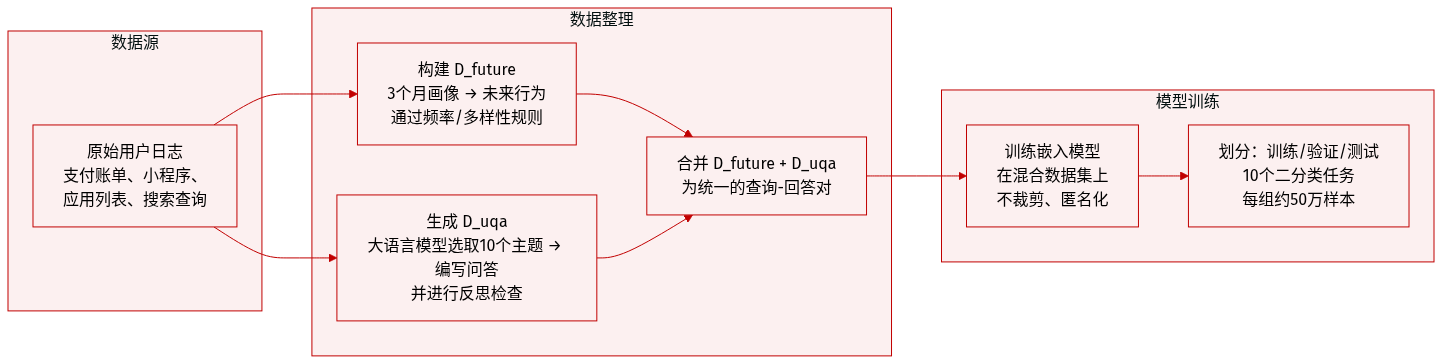
作者利用一种分层、查询驱动的框架 Q-Anchor Embedding,将多模态用户行为统一到语义基础、任务自适应的表征空间。架构围绕三个核心组件:粗到细用户编码器、双塔预训练机制、用于下游适配的软提示调优模块 —— 均设计为工业规模高效运行。
分层用户编码器处理来自六个模态(Bill、Mini、SPM、App、Search、Tabular)的原始行为信号,每个模态以 90 天窗口内事件序列表示。对于每个模态 m,事件级嵌入 hm,t 首先通过模态特定 MLP 投影为精炼事件标记 zm,t(evt)。这些再通过平均池化聚合为模态级摘要 zˉm(evt),并经共享模态适配器转换为 zm(mdl)。全局用户表征 z(usr) 通过专用用户适配器整合所有模态嵌入获得。最终输入标记序列 ei 通过拼接用户、模态与事件三级表征构建,使 LLM 可根据查询上下文动态关注细粒度行为或高层摘要。
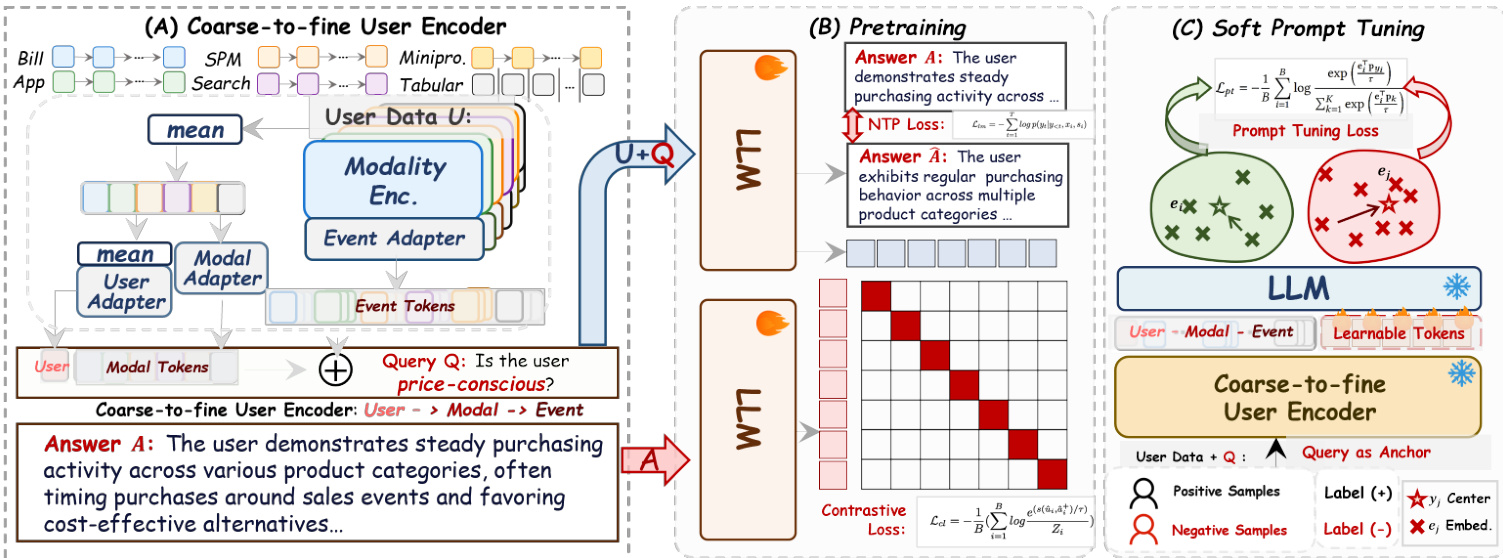
预训练阶段采用双塔架构对齐用户行为与语义意图。Anchor 塔接收分层用户标记 ei 并附加自然语言查询 qi 作为尾部锚点,生成查询条件嵌入 ui,q=LLManc(ei,qi)。Semantic 塔将目标答案 ai 编码为 vai=LLMsem(ai),使用相同 LLM 主干确保在共享潜在空间中对齐。训练由联合目标驱动:对比损失 Lcl 将正样本对 (ui,q,vai) 拉近,同时通过基于边距的掩码 mij 推远负样本;生成式下一标记预测损失 Lntp 自回归重建答案序列。总损失 Ltotal=Lcl+Lntp 确保嵌入兼具区分性与语义密度。
为在无需全量微调的情况下适配预训练模型至下游任务,作者引入软提示调优机制。可学习提示标记插入 LLM 输入空间以调节潜在表征 ui,q,同时通过原型对比损失 Lpt 优化类别原型 {pk},将用户嵌入拉近其分配的类别中心。这实现任务特定对齐(如区分高风险与低风险用户),同时保留预训练中学到的基础多模态对齐。
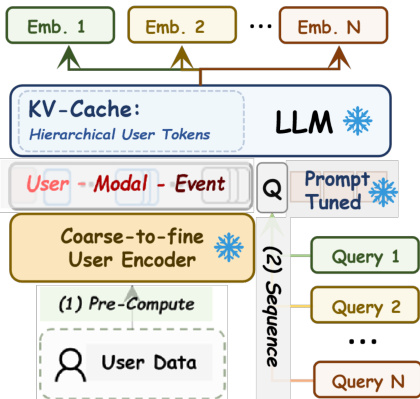
部署时,系统利用 KV 缓存优化解耦用户编码与查询处理。分层前缀 ei 仅编码一次并缓存,允许多个下游查询 {q1,…,qn} 顺序处理,仅需对查询标记进行增量计算。这将成本摊薄至每查询 O(Lqj),支持高吞吐、多场景推理。每日更新增量执行:仅重新编码含新事件的模态,并在滚动缓冲区中刷新其摘要标记,确保大规模下新鲜、有界且成本高效的表征。
实验
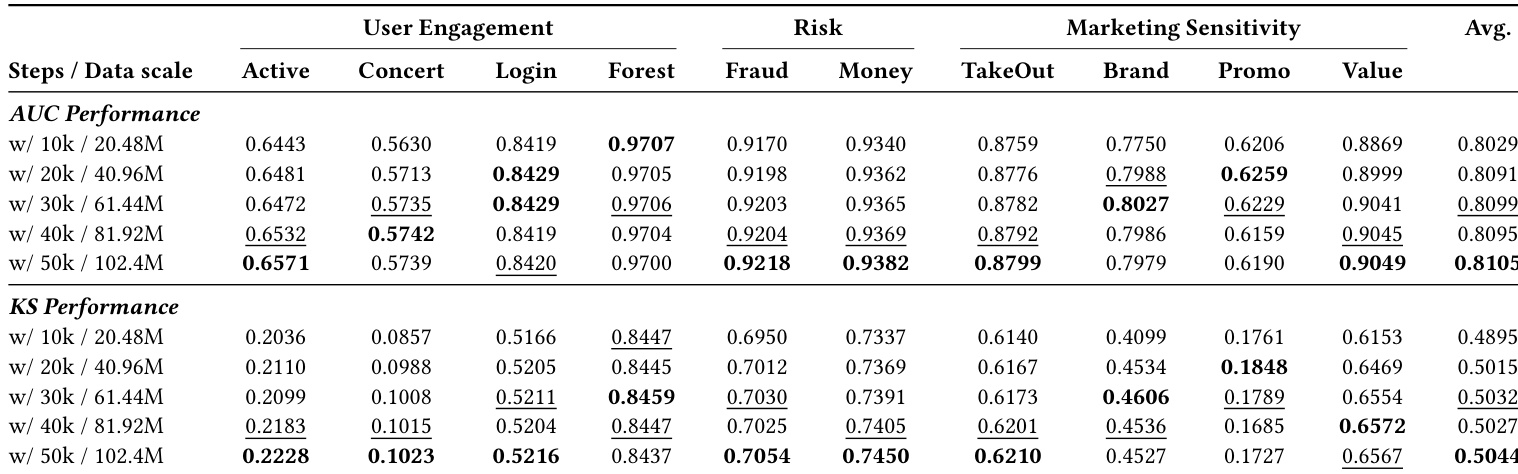
- Q-Anchor 在 10 个真实二元分类任务中持续优于通用与用户特定基线,展示更优 AUC 与 KS 分数,尤其在风控与营销领域,验证表征对齐比语义容量更重要。
- 模型在参与度、风控与营销领域稳健泛化,无需任务特定架构,支持由查询条件锚定实现的“一模型多任务”范式。
- 更大数据集预训练带来稳定增益,而模型规模超过 0.5B 参数未显示一致提升甚至出现退化,确认数据规模比参数规模对嵌入质量更关键。
- 仅 6 个可学习标记与 500 步提示调优即获得大部分性能增益,快速饱和,通过注意力转移至场景相关模态实现高效可解释专业化。
- 消融实验证实对比对齐对嵌入结构至关重要,模态与用户标记提供关键归纳偏置;预训练是捕捉行为先验的基础,非可选。
- 线上 A/B 测试显示实际业务影响:提升现金储备触达参与度与信贷逾期检测,验证真实世界有效性。
- 大规模部署利用共享前缀计算,支持多场景服务且每场景增量成本极低。
- PCA 与 t-SNE 可视化确认提示调优增强聚类分离,使表征对齐下游决策边界,无需架构变更。
作者使用轻量级 0.5B LLM 主干、模态特定编码器与对比预训练生成用户表征,再应用软提示调优实现场景适配。结果表明,其 Q-Anchor 方法在所有 10 项任务中持续优于通用文本嵌入与专用用户表征模型,提示调优在维持效率的同时显著提升 AUC 与 KS。该方法在各领域表现稳健,随数据与提示标记规模有效扩展,但不随模型规模扩展,凸显表征质量更依赖训练信号对齐而非参数数量。
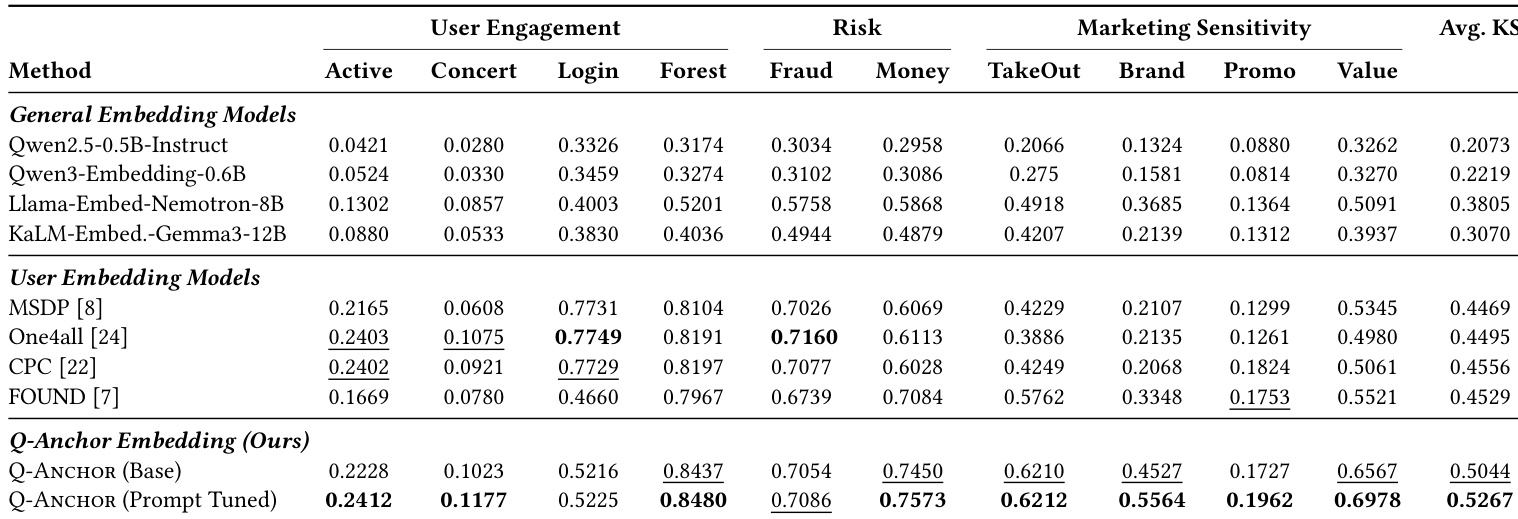
结果表明,可学习提示标记数从 1 增至 6 在所有评估场景中持续提升 AUC 与 KS,性能在 6 个标记后趋于平稳。6 标记配置达到最高平均 AUC 与 KS,表明少量参数更新足以将通用表征特化至多样下游任务。此效率支持可扩展部署,因进一步增加标记收益递减且偶有性能下降。
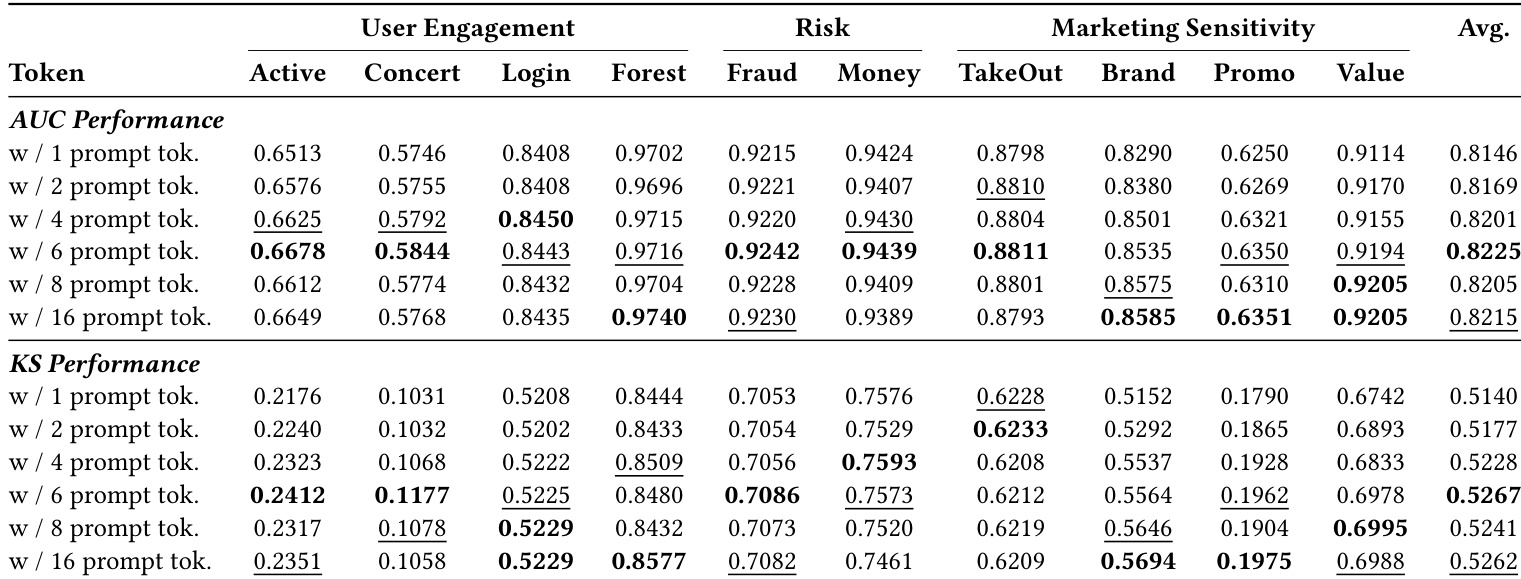
作者使用 Q-Anchor 嵌入在两个关键支付宝场景中超越现有业务特定模型,提示调优通过最小参数更新带来额外增益。结果在 AUC 与 KS 指标上均显示一致提升,确认通用表征结合轻量场景条件可超越手工特征并保持计算效率。该方法即使无任务特定架构也有效,支持跨多样业务目标的可扩展部署。
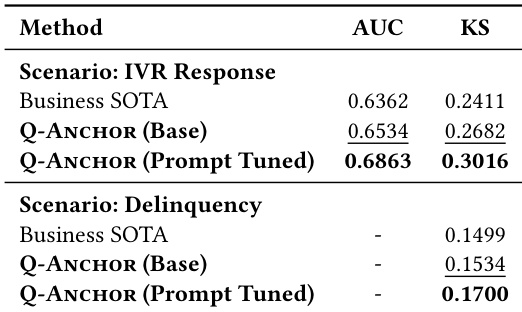
作者使用 0.5B 参数 LLM 主干与固定用户表征,将预训练数据从 20.5M 扩展至 102.4M 样本,观察到所有 10 项任务中 AUC 与 KS 随数据增加持续提升。结果表明性能随预训练数据稳步提升,50k 步时达到最高平均 AUC(0.8105)与 KS(0.5044),而相同训练预算下更大模型规模未带来一致提升。这表明对于用户表征学习,数据规模比模型规模更可靠地贡献性能。
作者通过结构化消融研究分离模态标记、训练目标与提示调优在 Q-Anchor 框架中的贡献。结果表明,移除模态或用户标记仅导致轻微性能下降,而消除对比学习导致最大退化,确认其在塑造嵌入空间中的作用。提示调优持续提升性能,但省略预训练导致系统性崩溃,强调预训练提供有效下游适配所需的关键行为先验。